sklearn中的回归树(Regression Trees in sklearn)
章节大纲
-
使用 Scikit-learn 的回归树模型 (Using Scikit-learn's Regression Tree Model)
既然我们已经从零开始构建了一个回归树模型,接下来我们将使用 Scikit-learn (sklearn) 预打包的回归树模型
sklearn.tree.DecisionTreeRegressor。整个过程遵循 Scikit-learn 的通用 API,步骤一如既往:-
导入模型
-
模型参数化
-
数据预处理,创建描述性特征集和目标特征集
-
训练模型
-
预测新的查询实例
为了方便起见,我们将继续使用之前创建的训练和测试数据。
Python# 导入回归树模型 from sklearn.tree import DecisionTreeRegressor # 模型参数化 # 我们将使用均方误差(即方差)作为分裂标准,并将每个叶节点的最小实例数设置为 5 regression_model = DecisionTreeRegressor(criterion="mse", min_samples_leaf=5) # 训练模型 # training_data.iloc[:,:-1] 选择所有行和除最后一列外的所有列作为特征 # training_data.iloc[:,-1:] 选择所有行和最后一列作为目标 regression_model.fit(training_data.iloc[:,:-1], training_data.iloc[:,-1:]) # 预测未见的查询实例 predicted = regression_model.predict(testing_data.iloc[:,:-1]) # 计算并绘制 RMSE RMSE = np.sqrt(np.sum(((testing_data.iloc[:,-1]-predicted)**2)/len(testing_data.iloc[:,-1]))) print(RMSE)Output:
1592.7501629176463将每个叶节点的最小实例数设置为 5 时,我们得到的 RMSE 与上面我们自己构建的模型几乎相同。此外,对于这个模型,我们也将绘制 RMSE 随每个叶节点最小实例数的变化曲线,以评估哪个最小实例数参数能产生最小的 RMSE。
绘制 RMSE 随最小实例数的变化曲线 (Plotting RMSE with Respect to Minimum Instances)
Python""" 绘制 RMSE 随最小实例数的变化曲线 """ fig = plt.figure() ax0 = fig.add_subplot(111) RMSE_train = [] RMSE_test = [] for i in range(1,100): # 参数化模型,并让 i 作为每个叶节点的最小实例数 regression_model = DecisionTreeRegressor(criterion="mse", min_samples_leaf=i) # 训练模型 regression_model.fit(training_data.iloc[:,:-1], training_data.iloc[:,-1:]) # 预测查询实例 predicted_train = regression_model.predict(training_data.iloc[:,:-1]) predicted_test = regression_model.predict(testing_data.iloc[:,:-1]) # 计算并添加 RMSE 值 RMSE_train.append(np.sqrt(np.sum(((training_data.iloc[:,-1]-predicted_train)**2)/len(training_data.iloc[:,-1])))) RMSE_test.append(np.sqrt(np.sum(((testing_data.iloc[:,-1]-predicted_test)**2)/len(testing_data.iloc[:,-1])))) ax0.plot(range(1,100), RMSE_test, label='Test_Data') ax0.plot(range(1,100), RMSE_train, label='Train_Data') ax0.legend() ax0.set_title('RMSE with respect to the minimum number of instances per node') ax0.set_xlabel('#Instances') ax0.set_ylabel('RMSE') plt.show()
结果分析 (Results Analysis)
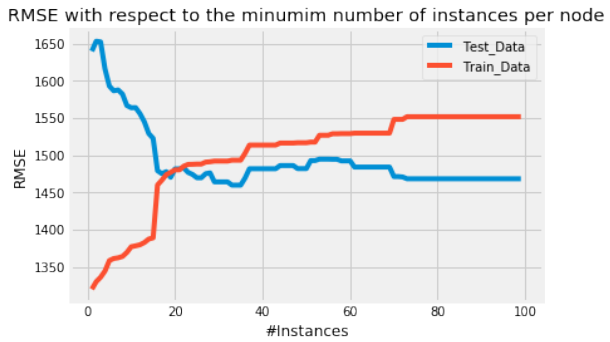
使用 Scikit-learn 预打包的回归树模型,当每个节点大约有 10 个实例时,RMSE 达到最小值。尽管如此,相对于实例数量的最小 RMSE 值与我们自己创建的模型计算出的值近似相同。此外,Scikit-learn 决策树模型的 RMSE 在每个节点的实例数量较大时也会趋于平稳。
参考文献 (References)
-
http://nbviewer.jupyter.org/gist/jwdink/9715a1a30e8c7f50a572
-
John D. Kelleher, Brian Mac Namee, Aoife D'Arcy, 2015. Machine Learning for Predictive Data Analytics. Cambridge, Massachusetts: The MIT Press.
-
Lior Rokach, Oded Maimon, 2015. Data Mining with Decision Trees. 2nd Ed. Ben-Gurion, Israel, Tel-Aviv, Israel: World Scientific.
-
Tom M. Mitchel, 1997. Machine Learning. New York, NY, USA: McGraw-Hill.
您对 Scikit-learn 的
DecisionTreeRegressor模型与我们自己实现的模型在性能上的相似性有什么看法?这是否符合您的预期?
Since we have now build a Regression Tree model from scratch we will use sklearn's prepackaged Regression
Tree model sklearn.tree.DecisionTreeRegressor. The procedure follows the general sklearn API and is as
always:
1.
2.
3.
4.
5.
Import the model
Parametrize the model
Preprocess the data and create a descriptive feature set as well as a target feature set
Train the model
Predict new query instances
For convenience we will use the training and testing data from above.
#Import the regression tree model
from sklearn.tree import DecisionTreeRegressor
#Parametrize the model
#We will use the mean squered error == varince as spliting criteri
a and set the minimum number
#of instances per leaf = 5
regression_model = DecisionTreeRegressor(criterion="mse",min_sampl
es_leaf=5)
#Fit the model
regression_model.fit(training_data.iloc[:,:-1],training_data.ilo
c[:,-1:])
#Predict unseen query instances
predicted = regression_model.predict(testing_data.iloc[:,:-1])
#Compute and plot the RMSE
RMSE = np.sqrt(np.sum(((testing_data.iloc[:,-1]-predicted)**2)/le
n(testing_data.iloc[:,-1])))
RMSE
Output:1592.7501629176463
With a parameterized minimum number of 5 instances per leaf node, we get nearly the same RMSE as with
434
our own built model above. Also for this model we will plot the RMSE against the minimum number of
instances per leaf node to evaluate the minimum number of instances parameter which yields the minimum
RMSE.
"""
Plot the RMSE with respect to the minimum number of instances
"""
fig = plt.figure()
ax0 = fig.add_subplot(111)
RMSE_train = []
RMSE_test = []
for i in range(1,100):
#Paramterize the model and let i be the number of minimum inst
ances per leaf node
regression_model = DecisionTreeRegressor(criterion="mse",min_s
amples_leaf=i)
#Train the model
regression_model.fit(training_data.iloc[:,:-1],training_data.i
loc[:,-1:])
#Predict query instances
predicted_train = regression_model.predict(training_data.ilo
c[:,:-1])
predicted_test = regression_model.predict(testing_data.ilo
c[:,:-1])
#Calculate and append the RMSEs
RMSE_train.append(np.sqrt(np.sum(((training_data.iloc[:,-1]-pr
edicted_train)**2)/len(training_data.iloc[:,-1]))))
RMSE_test.append(np.sqrt(np.sum(((testing_data.iloc[:,-1]-pred
icted_test)**2)/len(testing_data.iloc[:,-1]))))
ax0.plot(range(1,100),RMSE_test,label='Test_Data')
ax0.plot(range(1,100),RMSE_train,label='Train_Data')
ax0.legend()
ax0.set_title('RMSE with respect to the minumim number of instance
s per node')
ax0.set_xlabel('#Instances')
ax0.set_ylabel('RMSE')
plt.show()
435
Using sklearns prepackaged regression tree model yields a minimum RMSE with ≈ 10 instances per node.
Though, the values for the minimum RMSE with respect to the number of instances are ≈ the same as
computed with our own created model. Additionally, the RMSE of sklearns decision tree model also flattens
out for large numbers of instances per node.
References:
•••••https://www.analyticsvidhya.com/blog/2016/04/complete-tutorial-tree-based-modeling-scratch-
in-python/
http://nbviewer.jupyter.org/gist/jwdink/9715a1a30e8c7f50a572
John D. Kelleher, Brian Mac Namee, Aoife D'Arcy, 2015. Machine Learning for Predictiive
Data Analytics. Cambridge, Massachusetts: The MIT Press.
Lior Rokach, Oded Maimon, 2015. Data Mining with Decision Trees. 2nd Ed. Ben-Gurion,
Israel, Tel-Aviv, Israel: Wolrd Scientific.
Tom M. Mitchel, 1997. Machine Learning. New York, NY, USA: McGraw-Hill. -