MySQL数据库
MySQL 查询(SELECT)详解
1. SELECT 语句语法
SELECT [字段列表]
FROM [表名]
WHERE [条件]
GROUP BY [分组字段]
HAVING [分组条件]
ORDER BY [排序字段]
LIMIT [行数], [偏移量];
2. 字段列表
在 SELECT 子句中,必须指定需要检索的数据字段。您可以选择具体字段,也可以使用 SQL 表达式:
示例
-
执行简单计算:
SELECT 1+1; -- 返回 2 -
获取系统信息:
SELECT DATABASE(); -- 返回当前数据库名 SELECT CURRENT_USER(); -- 返回当前用户名 -
检索所有字段:
SELECT * FROM `stats`;优化建议:只选择必要的字段可提高查询效率。
3. 表名指定
指定表名通常在 FROM 子句中进行:
-
检索表中的字段:
SELECT id FROM `stats`; -
使用聚合函数:
SELECT MAX(id) FROM `stats`; -
使用数据库名和表名:
SELECT id FROM `sitedb`.`stats`; -
在
SELECT子句中指定表名:SELECT `stats`.`id` FROM `stats`; SELECT `sitedb`.`stats`.`id` FROM `sitedb`.`stats`;
4. 条件过滤(WHERE)
通过 WHERE 子句筛选记录:
-
选择特定记录:
SELECT * FROM `stats` WHERE `id` = 42; -
筛选不为空的字段:
SELECT * FROM `antiques` WHERE buyerid IS NOT NULL;
5. 分组(GROUP BY)
通过 GROUP BY 子句对记录进行分组,并对每组记录应用聚合函数。
示例
-
按
city字段分组,并计算每组的最大、最小、平均年龄:SELECT city, MAX(age), MIN(age), AVG(age) FROM `users` GROUP BY `city`; -
按
city和sex字段分组,计算每组的最大、最小、平均年龄:SELECT city, sex, MAX(age), MIN(age), AVG(age) FROM `users` GROUP BY `city`, `sex`;
6. 分组过滤(HAVING)
HAVING 子句用于筛选 GROUP BY 子句生成的分组记录。它与 WHERE 的区别在于:
WHERE:在分组前筛选记录。HAVING:在分组后筛选分组记录。
执行过程
- 先筛选符合
WHERE条件的记录。 - 对符合条件的记录进行分组计算。
- 筛选符合
HAVING条件的分组。
示例
-
正确使用
HAVING: 按城市分组,筛选最大年龄大于 80 的分组:SELECT city, MAX(age), MIN(age), AVG(age) FROM `users` GROUP BY `city` HAVING MAX(age) > 80; -
错误使用
HAVING: 直接使用HAVING筛选非聚合字段可能导致错误:SELECT city, sex, MAX(age), MIN(age), AVG(age) FROM `users` GROUP BY `city` HAVING sex = 'm'; -- 错误:聚合函数的结果中会包含所有性别的记录 -
优化建议:结合
WHERE和HAVING: 在分组前用WHERE筛选性别为男性的记录:SELECT city, sex, MAX(age), MIN(age), AVG(age) FROM `users` WHERE sex = 'm' GROUP BY `city`;
7. 排序和限制(ORDER BY 和 LIMIT)
排序
-
对记录按字段升序或降序排序:
SELECT * FROM `users` ORDER BY age ASC; -- 按年龄升序 -
按多个字段排序:
SELECT * FROM `users` ORDER BY city ASC, age DESC; -- 按城市升序,年龄降序
限制返回记录
-
限制返回记录的数量:
SELECT * FROM `users` LIMIT 10; -- 返回前 10 条记录 -
跳过前若干条记录后再返回结果:
SELECT * FROM `users` LIMIT 10 OFFSET 5; -- 跳过前 5 条记录,返回接下来的 10 条
总结
SELECT 是 MySQL 中最重要的查询语句,可以通过多种子句(如 WHERE、GROUP BY、HAVING、ORDER
BY 和 LIMIT)灵活实现数据的筛选、分组、排序和分页。合理使用这些子句,可以提高查询效率并满足复杂的数据需求。
MySQL 排序和限制(ORDER BY 和 LIMIT)
1. 排序(ORDER BY)
基本用法
ORDER BY 用于指定返回记录的排序顺序,可以按字母顺序或数值顺序排列。
-
默认升序排序:
SELECT * FROM `stats` ORDER BY `id`;等价于:
SELECT * FROM `stats` ORDER BY `id` ASC; -
降序排序:
SELECT * FROM `stats` ORDER BY `id` DESC;
特殊情况
- NULL 值的处理:
NULL值被认为小于任何其他值。 - 按字段位置排序:可以通过字段在
SELECT子句中的位置指定排序。SELECT `name`, `buyerid` FROM `antiques` ORDER BY 1; -- 按 name 排序 SELECT `name`, `buyerid` FROM `antiques` ORDER BY 2 DESC; -- 按 buyerid 降序排序
支持表达式排序
可以在 ORDER BY 中使用 SQL 表达式:
SELECT `name` FROM `antiques` ORDER BY REVERSE(`name`); -- 按名称的逆序排序
随机排序
如果需要随机顺序返回结果:
SELECT `name` FROM `antiques` ORDER BY RAND();
与 GROUP BY 一起使用
-
如果同时使用
GROUP BY,默认结果按GROUP BY的字段排序:SELECT city, sex, MAX(age) FROM `users` GROUP BY `city` ASC, `sex` DESC; -
如果不需要排序,可以显式取消:
SELECT city, sex, MAX(age) FROM `users` GROUP BY `city`, `sex` ORDER BY NULL;
2. 限制返回行数(LIMIT)
基本用法
-
限制返回的最大行数:
SELECT * FROM `antiques` ORDER BY `id` LIMIT 10;说明:返回最多 10 行,若不足 10 行则返回所有记录。
-
随机返回固定数量记录:
SELECT * FROM `antiques` ORDER BY RAND() LIMIT 1; -- 随机返回 1 行 SELECT * FROM `antiques` ORDER BY RAND() LIMIT 3; -- 随机返回 3 行
分页查询
-
从第几行开始返回数据:
SELECT * FROM `antiques` ORDER BY `id` LIMIT 10 OFFSET 10;或者:
SELECT * FROM `antiques` ORDER BY `id` LIMIT 10, 10; -- 从第 11 行开始返回 10 行 -
示例分页查询:
SELECT * FROM `antiques` ORDER BY `id` LIMIT 0, 10; -- 第 1 页 SELECT * FROM `antiques` ORDER BY `id` LIMIT 10, 10; -- 第 2 页 SELECT * FROM `antiques` ORDER BY `id` LIMIT 20, 10; -- 第 3 页
验证查询
- 可以使用
LIMIT 0检查查询语法,而无需返回结果:SELECT ... LIMIT 0;
3. 去重(DISTINCT)
基本用法
DISTINCT 用于删除结果集中所有重复的行。
-
删除重复行:
SELECT DISTINCT * FROM `stats`; -- 去除重复行 -
获取字段的唯一值列表:
SELECT DISTINCT `type` FROM `antiques` ORDER BY `type`; -
获取字段组合的唯一值:
SELECT DISTINCT `type`, `age` FROM `antiques` ORDER BY `type`;
注意事项
- 如果选择的字段中有主键(PRIMARY KEY)或唯一索引(UNIQUE),使用
DISTINCT是多余的。 - 在
GROUP BY子句中使用DISTINCT是没有意义的,因为分组操作本身已经去除了重复。
4. 优化建议
关于 LIMIT
LIMIT对使用ORDER BY、DISTINCT和GROUP BY的查询特别有用,可以减少不必要的计算。- 如果查询需要将结果复制到临时表,
LIMIT可以帮助 MySQL 提前计算所需的内存。
关于 ORDER BY
- 使用索引字段排序可以显著提升查询性能。
- 如果可能,避免在排序中使用表达式(如
ORDER BY RAND()),因为这会导致性能下降。
SQL_CALC_FOUND_ROWS
- 对分页查询,结合
SQL_CALC_FOUND_ROWS可以优化查询:SELECT SQL_CALC_FOUND_ROWS * FROM `antiques` LIMIT 10; SELECT FOUND_ROWS(); -- 返回查询的总记录数
总结
ORDER BY控制查询结果的顺序,支持字段名、字段位置、表达式等多种方式。LIMIT限制返回的记录行数,支持偏移量,常用于分页。DISTINCT用于去重,但与主键或唯一索引重复时没有意义。合理使用这些功能可以提升查询效率并满足实际业务需求。
MySQL 高级查询语句详解
1. IN 和 NOT IN
IN
IN 用于匹配一组值中的任意一个。
示例:
SELECT id
FROM stats
WHERE position IN ('Manager', 'Staff');
此查询返回 stats 表中 position 为 'Manager' 或 'Staff' 的记录。
NOT IN
NOT IN 用于排除一组值中的任意一个。
示例:
SELECT ownerid, 'is in both orders & antiques'
FROM orders, antiques
WHERE ownerid = buyerid
UNION
SELECT buyerid, 'is in antiques only'
FROM antiques
WHERE buyerid NOT IN (SELECT ownerid FROM orders);
- 第一部分查询返回同时出现在
orders和antiques表中的ownerid。 - 第二部分查询返回仅出现在
antiques表中的buyerid。
2. EXISTS 和 ALL
EXISTS
EXISTS 用于检查子查询是否返回至少一条记录。
示例:
SELECT ownerfirstname, ownerlastname
FROM owner
WHERE EXISTS (SELECT * FROM antiques WHERE item = 'chair');
此查询返回 owner 表中至少拥有一件 item='chair' 的记录。
ALL
ALL 用于比较某值与子查询返回的所有值。
示例:
SELECT buyerid, item
FROM antiques
WHERE price = ALL (SELECT price FROM antiques);
此查询返回 price 等于 antiques 表中所有价格的记录。
3. 查询优化提示
在 SELECT 中添加优化提示关键字可以提升查询性能。
优化关键字
SELECT [ALL | DISTINCT | DISTINCTROW]
[HIGH_PRIORITY] [STRAIGHT_JOIN]
[SQL_SMALL_RESULT | SQL_BIG_RESULT]
[SQL_BUFFER_RESULT]
[SQL_CACHE | SQL_NO_CACHE]
[SQL_CALC_FOUND_ROWS]
...
HIGH_PRIORITY:提高 SELECT 语句优先级,优先于 DML 操作(如INSERT、DELETE、UPDATE)。STRAIGHT_JOIN:强制按指定顺序连接表,从左到右进行连接。SQL_SMALL_RESULT:适用于DISTINCT或GROUP BY,表明查询返回的记录较少。SQL_BIG_RESULT:适用于DISTINCT或GROUP BY,表明查询返回的记录较多。SQL_BUFFER_RESULT:强制将结果复制到临时表中,尽早释放锁。SQL_CACHE:强制将查询结果存入查询缓存(需要query_cache_type设置为DEMAND或2)。SQL_NO_CACHE:不缓存查询结果,适用于查询结果变化频繁或很少使用的情况。SQL_CALC_FOUND_ROWS:结合LIMIT使用,计算未加限制时的总行数:SELECT SQL_CALC_FOUND_ROWS * FROM `stats` LIMIT 10 OFFSET 100; SELECT FOUND_ROWS(); -- 获取总行数
4. 索引提示(Index Hints)
索引提示类型
USE INDEX:优先使用指定索引。FORCE INDEX:强制使用指定索引。IGNORE INDEX:忽略指定索引。
示例:
-
使用索引优化查询:
SELECT * FROM table1 USE INDEX (date) WHERE date BETWEEN '20150101' AND '20150131'; -
忽略索引查询:
SELECT * FROM table1 IGNORE INDEX (date) WHERE id BETWEEN 100 AND 200;
5. UNION 和 UNION ALL
UNION
- 合并两个或多个查询的结果,并去除重复记录。
- 等价于
UNION DISTINCT。
示例:
SELECT * FROM english
UNION
SELECT * FROM hindi;
UNION ALL
- 合并结果集,不去除重复记录。
示例:
SELECT * FROM english
UNION ALL
SELECT * FROM hindi;
使用示例
-
合并字段:
SELECT word FROM word_table WHERE id = 1 UNION SELECT word FROM word_table WHERE id = 2; -
合并不同表的数据并排序:
(SELECT magazine FROM pages) UNION DISTINCT (SELECT magazine FROM pdflog) ORDER BY magazine; -
合并带条件的查询:
(SELECT ID_ENTRY FROM table WHERE ID_AGE = 1) UNION DISTINCT (SELECT ID_ENTRY FROM table WHERE ID_AGE = 2);
总结
IN和NOT IN:筛选值集合中的匹配项或排除项。EXISTS和ALL:用于子查询,EXISTS检查存在性,ALL用于比较所有值。- 优化提示:通过关键字优化查询性能(如
HIGH_PRIORITY、SQL_CALC_FOUND_ROWS)。 - 索引提示:显式控制查询使用的索引,提高查询效率。
UNION和UNION ALL:合并多个查询结果,UNION去重,UNION ALL保留重复。
通过以上功能,可以实现更灵活、高效的 MySQL 查询,同时充分利用数据库资源。
联结
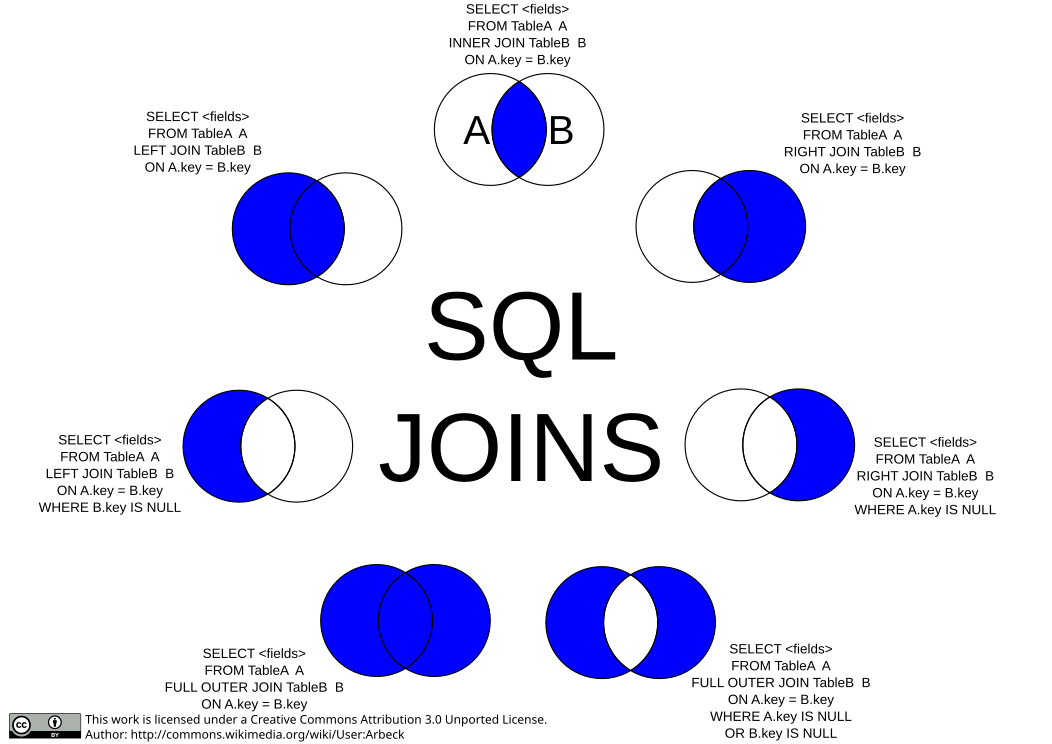
SQL 最重要的特性之一是其关系功能。通过 SQL,您可以查询、比较并计算两个完全不同结构的表。联结(Joins)和子查询(Subselects)是连接表的两种方法。这两种方法应产生相同的结果。在大多数 SQL 平台上,自然联结(Natural Join)的执行速度更快。
以下示例展示了一名学生试图学习数字在印地语中的表达方式:
-- 创建两个表
CREATE TABLE english (Tag INT, Inenglish VARCHAR(255));
CREATE TABLE hindi (Tag INT, Inhindi VARCHAR(255));
-- 插入数据
INSERT INTO english (Tag, Inenglish) VALUES (1, 'One');
INSERT INTO english (Tag, Inenglish) VALUES (2, 'Two');
INSERT INTO english (Tag, Inenglish) VALUES (3, 'Three');
INSERT INTO hindi (Tag, Inhindi) VALUES (2, 'Do');
INSERT INTO hindi (Tag, Inhindi) VALUES (3, 'Teen');
INSERT INTO hindi (Tag, Inhindi) VALUES (4, 'Char');
-- 查看表内容
SELECT * FROM english;
SELECT * FROM hindi;
结果:
| Tag | Inenglish |
|---|---|
| 1 | One |
| 2 | Two |
| 3 | Three |
| Tag | Inhindi |
|---|---|
| 2 | Do |
| 3 | Teen |
| 4 | Char |
1. 内联结(Inner Join)
内联结用于返回两个表中匹配的记录。
查询示例:
SELECT hindi.Tag, english.Inenglish, hindi.Inhindi
FROM english, hindi
WHERE english.Tag = hindi.Tag;
或等效的写法:
SELECT hindi.Tag, english.Inenglish, hindi.Inhindi
FROM english
INNER JOIN hindi ON english.Tag = hindi.Tag;
结果:
| Tag | Inenglish | Inhindi |
|---|---|---|
| 2 | Two | Do |
| 3 | Three | Teen |
2. 笛卡尔积(Cross Join)
笛卡尔积将一个表中的每一行与另一个表中的每一行组合。
查询示例:
SELECT * FROM english, hindi;
或等效的写法:
SELECT * FROM english CROSS JOIN hindi;
结果:
| Tag | Inenglish | Tag | Inhindi |
|---|---|---|---|
| 1 | One | 2 | Do |
| 2 | Two | 2 | Do |
| 3 | Three | 2 | Do |
| 1 | One | 3 | Teen |
| 2 | Two | 3 | Teen |
| 3 | Three | 3 | Teen |
| 1 | One | 4 | Char |
| 2 | Two | 4 | Char |
| 3 | Three | 4 | Char |
备注
- 在 MySQL 中,
JOIN等价于INNER JOIN和CROSS JOIN(笛卡尔积)。 - 如果希望返回匹配记录,推荐使用
INNER JOIN;如果需要生成所有可能的组合,则使用CROSS JOIN。
MySQL 高级联结与子查询详解
1. 自然联结(Natural Join)
自然联结根据两个表的共同列(相同名称和数据类型)进行匹配,其结果与在所有共同列上执行 INNER JOIN 相同。
示例:
SELECT hindi.Tag, hindi.Inhindi, english.Inenglish
FROM hindi
NATURAL JOIN english
USING (Tag);
2. 外联结(Outer Joins)
2.1 左外联结(Left Join / Left Outer Join)
左外联结返回左表中的所有记录,以及右表中匹配的记录。如果右表中没有匹配的记录,则显示 NULL。
语法:
SELECT field1, field2
FROM table1
LEFT JOIN table2
ON field1 = field2;
示例:
SELECT e.Inenglish AS English, e.Tag, '--no row--' AS Hindi
FROM english AS e
LEFT JOIN hindi AS h
ON e.Tag = h.Tag
WHERE h.Inhindi IS NULL;
结果:
| English | Tag | Hindi |
|---|---|---|
| One | 1 | --no row-- |
2.2 右外联结(Right Join / Right Outer Join)
右外联结返回右表中的所有记录,以及左表中匹配的记录。如果左表中没有匹配的记录,则显示 NULL。
示例:
SELECT '--no row--' AS English, h.Tag, h.Inhindi AS Hindi
FROM english AS e
RIGHT JOIN hindi AS h
ON e.Tag = h.Tag
WHERE e.Inenglish IS NULL;
结果:
| English | Tag | Hindi |
|---|---|---|
| --no row-- | 4 | Char |
2.3 全外联结(Full Outer Join)
MySQL 不直接支持 FULL OUTER JOIN,可以通过 LEFT JOIN 和 RIGHT JOIN 结合 UNION 来模拟:
示例:
(SELECT a.*, b.*
FROM tab1 a
LEFT JOIN tab2 b
ON a.id = b.id)
UNION
(SELECT a.*, b.*
FROM tab1 a
RIGHT JOIN tab2 b
ON a.id = b.id);
3. 多表联结
MySQL 支持多表联结,可以将多个表按逻辑顺序连接。
示例:
SELECT group_type.type_id, group_type.name, COUNT(people_job.job_id) AS count
FROM group_type
JOIN (groups JOIN people_job ON groups.group_id = people_job.group_id)
ON group_type.type_id = groups.type
GROUP BY type_id
ORDER BY type_id;
结果:
| type_id | name | count |
|---|---|---|
| 1 | Official GNU software | 148 |
| 2 | non-GNU software and documentation | 268 |
| 3 | www.gnu.org portion | 4 |
| 6 | www.gnu.org translation team | 5 |
4. 子查询(Subqueries)
子查询是嵌套在另一个查询中的查询,常用于简化复杂的 SQL 逻辑。
4.1 基本用法
子查询通常出现在 WHERE 或 HAVING 子句中,用于过滤数据。
示例: 查询销售目标超过所有销售代表配额总和的城市:
SELECT City
FROM Offices
WHERE Target > (SELECT SUM(Quota) FROM SalesReps WHERE RepOffice = OfficeNbr);
4.2 子查询规则
- 子查询只能返回单列。
- 子查询不能使用
ORDER BY。 - 子查询可以引用主查询中的列(外部引用)。
4.3 示例
-
列出订单或信用额度超过 50,000 的所有客户:
SELECT DISTINCT CustNbr FROM Customers, Orders WHERE CustNbr = Cust AND (CreditLimit > 50000 OR Amt > 50000); -
查询销售目标超过某些条件的城市:
SELECT City FROM Offices WHERE Target > (SELECT SUM(Quota) FROM SalesReps WHERE RepOffice = OfficeNbr);
5. 注意事项
- 列名和数据类型匹配:在联结操作中,确保两个表的列名和数据类型一致。
LEFT和RIGHT的对称性:LEFT JOIN和RIGHT JOIN的结果可以通过交换表的顺序和关键字得到相同结果。- 默认联结类型:如果未指定联结类型,MySQL 默认使用
INNER JOIN。
通过熟练使用各种联结和子查询,您可以轻松处理复杂的业务需求,并实现高效的数据查询和操作。