机器学习
机器学习算法的第三大类是概率模型。我们之前看到,K近邻算法使用距离(例如欧几里得距离)的思想来分类实体,而逻辑模型使用逻辑表达式来划分实例空间。在本节中,我们将探讨概率模型如何利用概率的思想来分类新实体。
概率模型将特征和目标变量视为随机变量。建模过程表示并操作这些变量的不确定性水平。概率模型有两种类型:预测性模型和生成性模型。预测性概率模型使用条件概率分布 P(Y∣X) 的思想,通过 X 可以预测 Y。生成性模型估计联合分布 P(Y,X)。一旦我们知道生成模型的联合分布,我们就可以推导出涉及相同变量的任何条件或边际分布。因此,生成模型能够通过了解联合概率分布来创建新的数据点及其标签。联合分布寻找两个变量之间的关系。一旦推断出这种关系,就可以推断出新的数据点。
朴素贝叶斯就是概率分类器的一个例子。
我们可以使用贝叶斯规则来实现这一点:
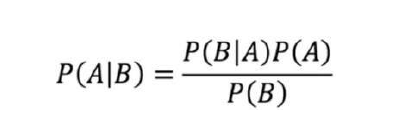
P(A∣B)=P(B)P(B∣A)P(A)
朴素贝叶斯算法基于条件概率的思想。条件概率是基于在某事已经发生的情况下,另一件事发生的概率。因此,算法的任务是查看证据并确定特定类别的可能性,并相应地为每个实体分配标签。
模型的几个主要类别:
| 几何模型 | 概率模型 | 逻辑模型 |
| 例如:K近邻、线性回归、支持向量机、逻辑回归等 | 例如:朴素贝叶斯、高斯过程回归、条件随机场等 | 例如:决策树、随机森林等 |
The third family of machine learning algorithms is the probabilistic models. We have seen
before that the k-nearest neighbour algorithm uses the idea of distance (e.g., Euclidian distance) to
classify entities, and logical models use a logical expression to partition the instance space. In this
section, we see how the probabilistic models use the idea of probability to classify new entities.
Probabilistic models see features and target variables as random variables. The process of modelling
represents and manipulates the level of uncertainty with respect to these variables. There are two
types of probabilistic models: Predictive and Generative. Predictive probability models use the idea of
a conditional probability distribution P (Y |X) from which Y can be predicted from X. Generative models
estimate the joint distribution P (Y, X). Once we know the joint distribution for the generative models,
we can derive any conditional or marginal distribution involving the same variables. Thus, the
generative model is capable of creating new data points and their labels, knowing the joint probability
distribution. The joint distribution looks for a relationship between two variables. Once this relationship
is inferred, it is possible to infer new data points.
Naïve Bayes is an example of a probabilistic classifier.
We can do this using the Bayes rule defined as
The Naïve Bayes algorithm is based on the idea of Conditional Probability. Conditional probability is
based on finding the probability that something will happen, given that something else has already
happened. The task of the algorithm then is to look at the evidence and to determine the likelihood of a
specific class and assign a label accordingly to each entity.
Some broad categories of models:
Geometric models
Probabilistic models
Logical models
E.g. K-nearest neighbors, linear Naïve Bayes, Gaussian process Decision tree, random forest, ...
regression,
support
vector regression, conditional random
machine, logistic regression, ...
field, ...