机器学习
- 考虑构建一个学习型机器人。这个机器人,或者说智能体(agent),拥有一组传感器来观察其环境的状态(state),以及一组可以执行的**动作(actions)**来改变这个状态。
- 它的任务是学习一种控制策略(control strategy),或者说策略(policy),用于选择能够实现其目标的动作。
- 智能体的目标可以通过**奖励函数(reward function)**来定义,该函数为智能体从每个不同状态可能采取的每个不同动作分配一个数值。
- 这个奖励函数可以内置在机器人中,或者只由一个外部教师知道,该教师为机器人执行的每个动作提供奖励值。
- 机器人的任务是执行一系列动作,观察其结果,并学习一个控制策略。
- 这个控制策略是从任何初始状态出发,选择能够最大化智能体随时间累积奖励的动作。
例子:
- 一个移动机器人可能拥有摄像头和声纳等传感器,以及“前进”和“转向”等动作。
- 机器人可能有一个目标:当电池电量低时,对接上电池充电器。
- 对接电池充电器的目标可以通过以下方式实现:为立即导致连接到充电器的状态-动作转换分配一个正奖励(例如,+100),而为所有其他状态-动作转换分配零奖励。
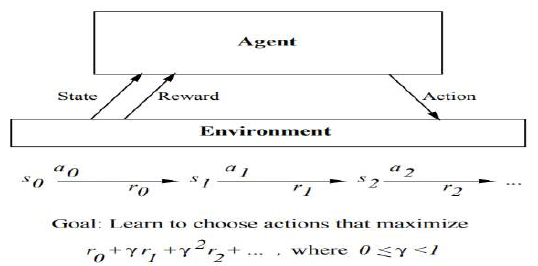
强化学习问题
- 一个智能体与其环境互动。智能体存在于由一组可能的**状态(S)**描述的环境中。
- 智能体可以执行一组可能的动作(A)中的任何一个。每次它在某个状态 st 中执行一个动作 a 时,智能体都会收到一个实值奖励 r,这表示这个状态-动作转换的即时价值。这会产生一系列状态 si、动作 ai 和即时奖励 ri,如图所示。
- 智能体的任务是学习一个控制策略 ,该策略能够最大化这些奖励的预期总和。
强化学习问题特征
-
延迟奖励(Delayed reward):智能体的任务是学习一个目标函数 π,它将当前状态 s 映射到最优动作 。在强化学习中,训练信息并非以 (s,π(s)) 的形式直接提供。相反,当智能体执行其动作序列时,训练器只提供一系列即时奖励值。因此,智能体面临**时序信用分配(temporal credit assignment)**的问题:确定其动作序列中的哪些动作应该被认为产生了最终的奖励。
-
探索(Exploration):在强化学习中,智能体通过选择的动作序列来影响训练样本的分布。这就提出了一个问题:哪种实验策略能够产生最有效的学习?学习者在选择时面临权衡:是倾向于探索未知的状态和动作,还是利用已经知道会产生高奖励的状态和动作。
-
部分可观测状态(Partially observable states):虽然智能体的传感器可以在每个时间步感知环境的整个状态,但在许多实际情况中,传感器只提供部分信息。在这种情况下,智能体在选择动作时需要结合其过去的观察和当前的传感器数据,最好的策略可能是选择那些专门用于提高环境可观测性的动作。
-
终身学习(Life-long learning):机器人需要在同一环境中,使用相同的传感器学习多个相关任务。例如,一个移动机器人可能需要学习如何对接电池充电器、如何穿过狭窄的走廊以及如何从激光打印机中取出输出。这种设置提出了利用先前获得的经验或知识来减少学习新任务时样本复杂度的可能性。
Consider building a learning robot. The robot, or agent, has a set of sensors to observe the state of
its environment, and a set of actions it can perform to alter this state.
Its task is to learn a control strategy, or policy, for choosing actions that achieve its goals.
The goals of the agent can be defined by a reward function that assigns a numerical value to each
distinct action the agent may take from each distinct state.
This reward function may be built into the robot, or known only to an external teacher who
provides the reward value for each action performed by the robot.
The task of the robot is to perform sequences of actions, observe their consequences, and learn a
control policy.
The control policy is one that, from any initial state, chooses actions that maximize the reward
accumulated over time by the agent.
Example:
A mobile robot may have sensors such as a camera and sonars, and actions such as "move
forward" and "turn."
The robot may have a goal of docking onto its battery charger whenever its battery level is low.
The goal of docking to the battery charger can be captured by assigning a positive reward (Eg.,
+100) to state-action transitions that immediately result in a connection to the charger and a
reward of zero to every other state-action transition.
Reinforcement Learning Problem
An agent interacting with its environment. The agent exists in an environment described by some
set of possible states S.
Agent perform any of a set of possible actions A. Each time it performs an action a, in some state st
the agent receives a real-valued reward r, that indicates the immediate value of this state-action
transition. This produces a sequence of states si, actions ai, and immediate rewards ri as shown in
the figure.
The agent's task is to learn a control policy, π: S → A, that maximizes the expected sum of these
Reinforcement learning problem characteristics
1. Delayed reward: The task of the agent is to learn a target function π that maps from the current state
s to the optimal action a = π (s). In reinforcement learning, training information is not available in (s, π
(s)). Instead, the trainer provides only a sequence of immediate reward values as the agent executes its
sequence of actions. The agent, therefore, faces the problem of temporal credit assignment:
determining which of the actions in its sequence are to be credited with producing the eventual
rewards.
2. Exploration: In reinforcement learning, the agent influences the distribution of training examples by
the action sequence it chooses. This raises the question of which experimentation strategy produces
most effective learning. The learner faces a trade-off in choosing whether to favor exploration of
unknown states and actions, or exploitation of states and actions that it has already learned will yield
high reward.
3. Partially observable states: The agent's sensors can perceive the entire state of the environment at
each time step, in many practical situations sensors provide only partial information. In such cases, the
agent needs to consider its previous observations together with its current sensor data when choosing
actions, and the best policy may be one that chooses actions specifically to improve the observability of
the environment.
4. Life-long learning: Robot requires to learn several related tasks within the same environment, using
the same sensors. For example, a mobile robot may need to learn how to dock on its battery charger,
how to navigate through narrow corridors, and how to pick up output from laser printers. This setting
raises the possibility of using previously obtained experience or knowledge to reduce sample complexity
when learning new tasks.