机器学习
Completion requirements
智能体如何才能为任意环境学习到最优策略 π∗ 呢?
学习者可获得的训练信息是即时奖励序列 r(si,ai),其中 。有了这类训练信息,学习一个定义在状态和动作上的数值评估函数会更容易,然后可以根据这个评估函数来执行最优策略。
那么,智能体应该尝试学习什么样的评估函数呢?
一个显而易见的选择是 V∗。当 时,智能体应该偏好状态 s1 而非状态 s2,因为从 s1 开始的累积未来奖励会更大。
在状态 s 下的最优动作 a 是那个能最大化“即时奖励 r(s,a) 加上其直接后继状态 V∗ 值(经过 γ 折扣)”总和的动作。
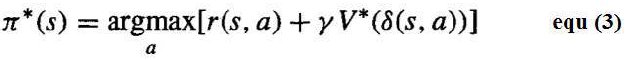
How can an agent learn an optimal policy π * for an arbitrary environment?
The training information available to the learner is the sequence of immediate rewards r(si,ai)
for i = 0, 1,2, . . . . Given this kind of training information it is easier to learn a numerical evaluation
function defined over states and actions, then implement the optimal policy in terms of this evaluation
function.
What evaluation function should the agent attempt to learn?
One obvious choice is V*. The agent should prefer state sl over state s2 whenever V*(sl) > V*(s2),
because the cumulative future reward will be greater from sl
The optimal action in state s is the action a that maximizes the sum of the immediate reward r(s, a) plus
the value V* of the immediate successor state, discounted by γ.
Last modified: Friday, 20 June 2025, 10:25 AM