机器学习
Completion requirements
- 学习 Q 函数就等同于学习最优策略。
- 关键问题在于,我们只有一系列随时间分散的即时奖励 r,如何找到一种可靠的方法来估计 Q 的训练值。这可以通过迭代近似来实现。
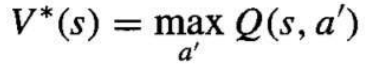
我们可以重写 Q 函数的定义:
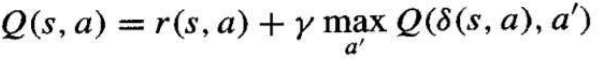
Q 学习算法

这是一个假设奖励和动作都是确定性的 Q 学习算法。折扣因子 γ 可以是任何常数,只要满足 即可。
我们用 Q^ 来表示学习器对实际 Q 函数的估计或假设。
Learning the Q function corresponds to learning the optimal policy.
The key problem is finding a reliable way to estimate training values for Q, given only a sequence of
immediate rewards r spread out over time. This can be accomplished through iterative
approximation
Rewriting Equation
Q learning algorithm:
Q learning algorithm assuming deterministic rewards and actions. The discount factor γ may be any
constant such that 0 ≤ γ < 1
Q̂ to refer to the learner's estimate, or hypothesis, of the actual Q function
Last modified: Friday, 20 June 2025, 10:35 AM