Python 机器学习
简介
为了成功执行并产生结果,机器学习模型必须自动化一些标准工作流。自动化这些标准工作流的过程可以通过 Scikit-learn 管道完成。从数据科学家的角度来看,管道是一个通用但非常重要的概念。它基本上允许数据从其原始格式流向一些有用的信息。管道的工作原理可以通过以下图表理解:
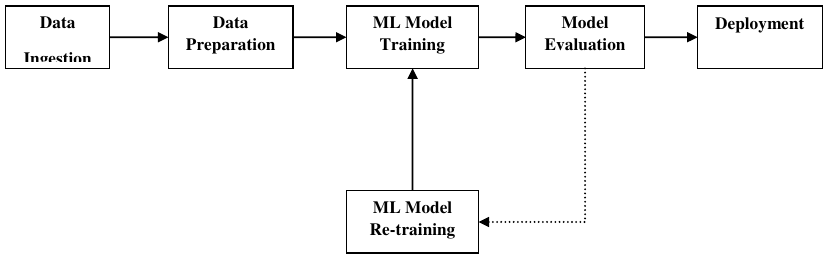
数据摄取 rightarrow 数据准备 rightarrow ML 模型训练 rightarrow 模型评估 rightarrow ML 模型再训练 rightarrow 部署
机器学习管道的各个模块如下:
- 数据摄取 (Data ingestion):顾名思义,它是将数据导入以用于机器学习项目的过程。数据可以从单个或多个系统实时或批量提取。这是最具挑战性的步骤之一,因为数据质量会影响整个机器学习模型。
- 数据准备 (Data Preparation):导入数据后,我们需要准备数据以供机器学习模型使用。数据预处理是数据准备最重要的技术之一。
- ML 模型训练 (ML Model Training):下一步是训练我们的机器学习模型。我们有各种机器学习算法,如监督学习、无监督学习、强化学习,用于从数据中提取特征并进行预测。
- 模型评估 (Model Evaluation):接下来,我们需要评估机器学习模型。在自动化机器学习 (AutoML) 管道中,机器学习模型可以通过各种统计方法和业务规则进行评估。
- ML 模型再训练 (ML Model retraining):在 AutoML 管道中,第一个模型不一定是最好的。第一个模型被视为基线模型,我们可以重复训练它以提高模型的准确性。
- 部署 (Deployment):最后,我们需要部署模型。此步骤涉及将模型应用于并迁移到业务操作中供其使用。
机器学习管道面临的挑战 (Challenges Accompanying ML Pipelines)
为了创建机器学习管道,数据科学家面临许多挑战。这些挑战分为以下三类:
数据质量 (Quality of Data)
任何机器学习模型的成功都严重依赖于数据质量。如果提供给机器学习模型的数据不准确、不可靠且不健壮,那么我们将得到错误或误导性的输出。
数据可靠性 (Data Reliability)
与机器学习管道相关的另一个挑战是我们提供给机器学习模型的数据的可靠性。众所周知,数据科学家可以从各种来源获取数据,但要获得最佳结果,必须确保数据源可靠且受信任。
数据可访问性 (Data Accessibility)
为了从机器学习管道中获得最佳结果,数据本身必须可访问,这需要数据的整合、清理和整理。作为数据可访问性属性的结果,元数据将使用新标签进行更新。
建模机器学习管道和数据准备 (Modelling ML Pipeline and Data Preparation)
数据从训练数据集到测试数据集的泄漏是数据科学家在为机器学习模型准备数据时需要处理的一个重要问题。通常,在数据准备时,数据科学家在学习之前对整个数据集使用标准化或归一化等技术。但这些技术无法帮助我们防止数据泄漏,因为训练数据集会受到测试数据集中数据规模的影响。
通过使用机器学习管道,我们可以防止这种数据泄漏,因为管道确保数据准备(如标准化)仅限于交叉验证过程的每个折叠。
示例 (Example)
以下是一个 Python 示例,演示了数据准备和模型评估工作流。为此,我们使用 Sklearn 中的 Pima Indian Diabetes 数据集。首先,我们将创建一个标准化数据的管道。然后将创建一个线性判别分析模型,最后使用 10 折交叉验证评估管道。
首先,导入所需的包,如下所示:
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
现在,我们需要像前面的示例一样加载 Pima 糖尿病数据集:
# 假设您已将 'pima-indians-diabetes.csv' 文件保存在本地路径
path = r"C:\pima-indians-diabetes.csv"
headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age',
'class']
data = read_csv(path, names=headernames)
array = data.values
X = array[:,0:8] # 特征
Y = array[:,8] # 目标
接下来,我们将借助以下代码创建一个管道:
estimators = []
estimators.append(('standardize', StandardScaler()))
estimators.append(('lda', LinearDiscriminantAnalysis()))
model = Pipeline(estimators)
最后,我们将评估此管道并输出其准确性,如下所示:
# 修正 KFold 的 random_state 参数以确保可重复性
kfold = KFold(n_splits=20, random_state=7, shuffle=True) # 添加 shuffle=True 以确保 KFold 的随机性
results = cross_val_score(model, X, Y, cv=kfold)
print(results.mean())
输出:
0.7790148448043184
上述输出是该设置在数据集上准确性的摘要。
建模机器学习管道和特征提取 (Modelling ML Pipeline and Feature Extraction)
数据泄漏也可能发生在机器学习模型的特征提取步骤。这就是为什么特征提取过程也应该受到限制,以阻止训练数据集中的数据泄漏。与数据准备的情况一样,通过使用机器学习管道,我们也可以防止这种数据泄漏。FeatureUnion 是机器学习管道提供的一个工具,可以用于此目的。
示例 (Example)
以下是一个 Python 示例,演示了特征提取和模型评估工作流。为此,我们使用 Sklearn 中的 Pima Indian Diabetes 数据集。
首先,将使用 PCA(主成分分析)提取 3 个特征。然后,将使用统计分析提取 6 个特征。特征提取后,将使用 FeatureUnion 工具组合多个特征选择和提取过程的结果。最后,将创建一个逻辑回归模型,并使用 10 折交叉验证评估管道。
首先,导入所需的包,如下所示:
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.pipeline import Pipeline
from sklearn.pipeline import FeatureUnion
from sklearn.linear_model import LogisticRegression
from sklearn.decomposition import PCA
from sklearn.feature_selection import SelectKBest
现在,我们需要像前面的示例一样加载 Pima 糖尿病数据集:
# 假设您已将 'pima-indians-diabetes.csv' 文件保存在本地路径
path = r"C:\pima-indians-diabetes.csv"
headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age',
'class']
data = read_csv(path, names=headernames)
array = data.values
X = array[:,0:8] # 特征
Y = array[:,8] # 目标
接下来,将创建特征联合,如下所示:
features = []
features.append(('pca', PCA(n_components=3)))
features.append(('select_best', SelectKBest(k=6)))
feature_union = FeatureUnion(features)
接下来,将借助以下脚本行创建管道:
estimators = []
estimators.append(('feature_union', feature_union))
estimators.append(('logistic', LogisticRegression(solver='liblinear'))) # 添加 solver 参数,因为默认值已更改
model = Pipeline(estimators)
最后,我们将评估此管道并输出其准确性,如下所示:
# 修正 KFold 的 random_state 参数以确保可重复性
kfold = KFold(n_splits=20, random_state=7, shuffle=True) # 添加 shuffle=True 以确保 KFold 的随机性
results = cross_val_score(model, X, Y, cv=kfold)
print(results.mean())
输出:
0.7789811066126855
上述输出是该设置在数据集上准确性的摘要。
23. Machine Learning with Pipelines – Machine
Automatic
Learning with Workflows
Python
Introduction
In order to execute and produce results successfully, a machine learning model must
automate some standard workflows. The process of automate these standard workflows
can be done with the help of Scikit-learn Pipelines. From a data scientist’s perspective,
pipeline is a generalized, but very important concept. It basically allows data flow from its
raw format to some useful information. The working of pipelines can be understood with
the help of following diagram:
Data
Data
ML Model
Model
Deployment
Preparation
Training
Evaluation
Ingestion
ML Model
Re-training
The blocks of ML pipelines are as follows:
Data ingestion: As the name suggests, it is the process of importing the data for use in
ML project. The data can be extracted in real time or batches from single or multiple
systems. It is one of the most challenging steps because the quality of data can affect the
whole ML model.
Data Preparation: After importing the data, we need to prepare data to be used for our
ML model. Data preprocessing is one of the most important technique of data preparation.
ML Model Training: Next step is to train our ML model. We have various ML algorithms
like supervised, unsupervised, reinforcement to extract the features from data, and make
predictions.
Model Evaluation: Next, we need to evaluate the ML model. In case of AutoML pipeline,
ML model can be evaluated with the help of various statistical methods and business rules.
ML Model retraining: In case of AutoML pipeline, it is not necessary that the first model
is best one. The first model is considered as a baseline model and we can train it repeatably
to increase model’s accuracy.
143
Machine Learning with Python
Deployment: At last, we need to deploy the model. This step involves applying and
migrating the model to business operations for their use.
Challenges Accompanying ML Pipelines
In order to create ML pipelines, data scientists face many challenges. These challenges fall
into the following three categories:
Quality of Data
The success of any ML model depends heavily on the quality of data. If the data we are
providing to ML model is not accurate, reliable and robust, then we are going to end with
wrong or misleading output.
Data Reliability
Another challenge associated with ML pipelines is the reliability of data we are providing
to the ML model. As we know, there can be various sources from which data scientist can
acquire data but to get the best results, it must be assured that the data sources are
reliable and trusted.
Data Accessibility
To get the best results out of ML pipelines, the data itself must be accessible which requires
consolidation, cleansing and curation of data. As a result of data accessibility property,
metadata will be updated with new tags.
Modelling ML Pipeline and Data Preparation
Data leakage, happening from training dataset to testing dataset, is an important issue
for data scientist to deal with while preparing data for ML model. Generally, at the time of
data preparation, data scientist uses techniques like standardization or normalization on
entire dataset before learning. But these techniques cannot help us from the leakage of
data because the training dataset would have been influenced by the scale of the data in
the testing dataset.
By using ML pipelines, we can prevent this data leakage because pipelines ensure that
data preparation like standardization is constrained to each fold of our cross-validation
procedure.
Example
The following is an example in Python that demonstrate data preparation and model
evaluation workflow. For this purpose, we are using Pima Indian Diabetes dataset from
Sklearn. First, we will be creating pipeline that standardized the data. Then a Linear
Discriminative analysis model will be created and at last the pipeline will be evaluated
using 10-fold cross validation.
First, import the required packages as follows:
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
144
Machine Learning with Python
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
Now, we need to load the Pima diabetes dataset as did in previous examples:
path = r"C:\pima-indians-diabetes.csv"
headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age',
'class']
data = read_csv(path, names=headernames)
array = data.values
Next, we will create a pipeline with the help of the following code:
estimators = []
estimators.append(('standardize', StandardScaler()))
estimators.append(('lda', LinearDiscriminantAnalysis()))
model = Pipeline(estimators)
At last, we are going to evaluate this pipeline and output its accuracy as follows:
kfold = KFold(n_splits=20, random_state=7)
results = cross_val_score(model, X, Y, cv=kfold)
print(results.mean())
Output
0.7790148448043184
The above output is the summary of accuracy of the setup on the dataset.
Modelling ML Pipeline and Feature Extraction
Data leakage can also happen at feature extraction step of ML model. That is why feature
extraction procedures should also be restricted to stop data leakage in our training dataset.
As in the case of data preparation, by using ML pipelines, we can prevent this data leakage
also. FeatureUnion, a tool provided by ML pipelines can be used for this purpose.
Example
The following is an example in Python that demonstrates feature extraction and model
evaluation workflow. For this purpose, we are using Pima Indian Diabetes dataset from
Sklearn.
First, 3 features will be extracted with PCA (Principal Component Analysis). Then, 6
features will be extracted with Statistical Analysis. After feature extraction, result of
multiple feature selection and extraction procedures will be combined by using
145
Machine Learning with Python
FeatureUnion tool. At last, a Logistic Regression model will be created, and the pipeline
will be evaluated using 10-fold cross validation.
First, import the required packages as follows:
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.pipeline import Pipeline
from sklearn.pipeline import FeatureUnion
from sklearn.linear_model import LogisticRegression
from sklearn.decomposition import PCA
from sklearn.feature_selection import SelectKBest
Now, we need to load the Pima diabetes dataset as did in previous examples:
path = r"C:\pima-indians-diabetes.csv"
headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age',
'class']
data = read_csv(path, names=headernames)
array = data.values
Next, feature union will be created as follows:
features = []
features.append(('pca', PCA(n_components=3)))
features.append(('select_best', SelectKBest(k=6)))
feature_union = FeatureUnion(features)
Next, pipeline will be creating with the help of following script lines:
estimators = []
estimators.append(('feature_union', feature_union))
estimators.append(('logistic', LogisticRegression()))
model = Pipeline(estimators)
At last, we are going to evaluate this pipeline and output its accuracy as follows:
kfold = KFold(n_splits=20, random_state=7)
results = cross_val_score(model, X, Y, cv=kfold)
print(results.mean())
146
Machine Learning with Python
Output
0.7789811066126855
The above output is the summary of accuracy of the setup on the dataset.