迁移到IPv6
章节大纲
-
引言
在迁移阶段,主机应逐步具备访问IPv6目标地址的能力,同时保持对IPv4目标地址的访问能力。迁移所有网络设备是必要但不充分的条件:用户需要为整个网络制定一个新的地址规划以实现IPv4与IPv6的协同工作。
主机迁移
应用程序迁移
将IPv6支持引入应用程序需要修改源代码:
- 服务器端:服务器上的运行进程应开启两个线程,一个监听IPv4套接字,另一个监听IPv6套接字,以同时支持IPv4和IPv6请求。
- 客户端:例如,浏览器等应用程序应能够正确输入和输出IPv6格式的地址。
操作系统迁移
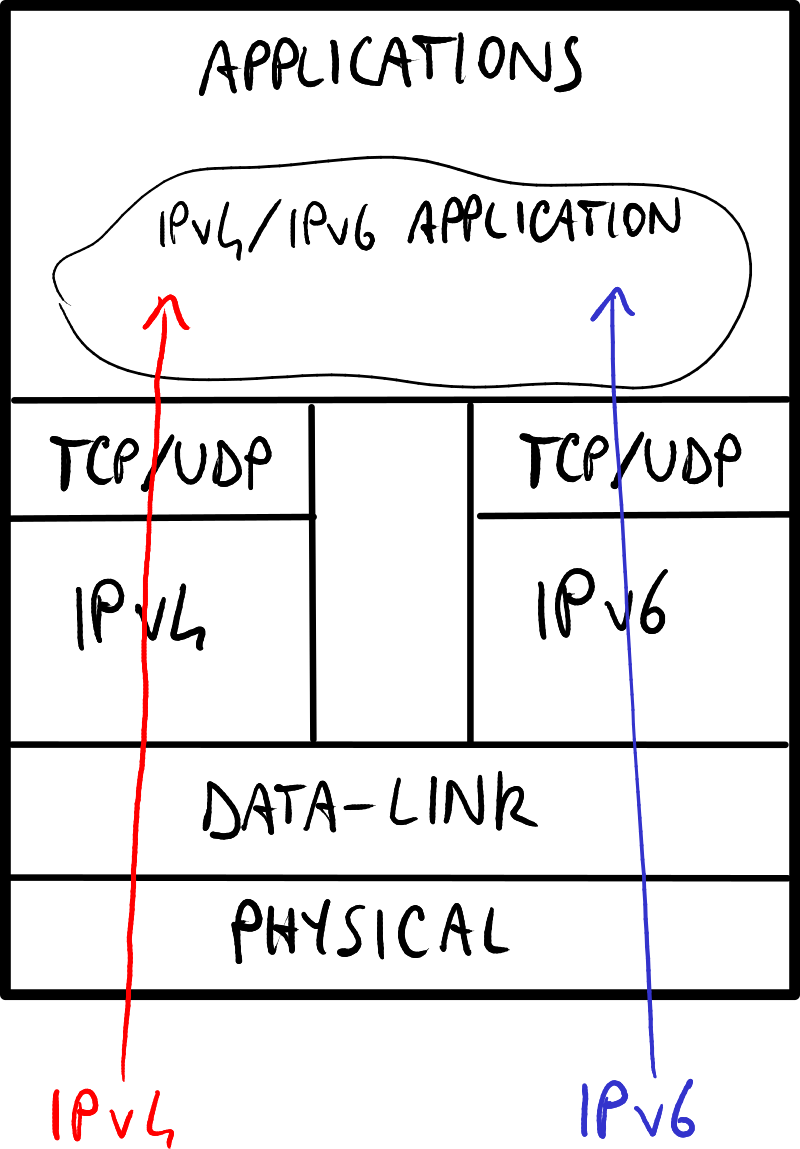
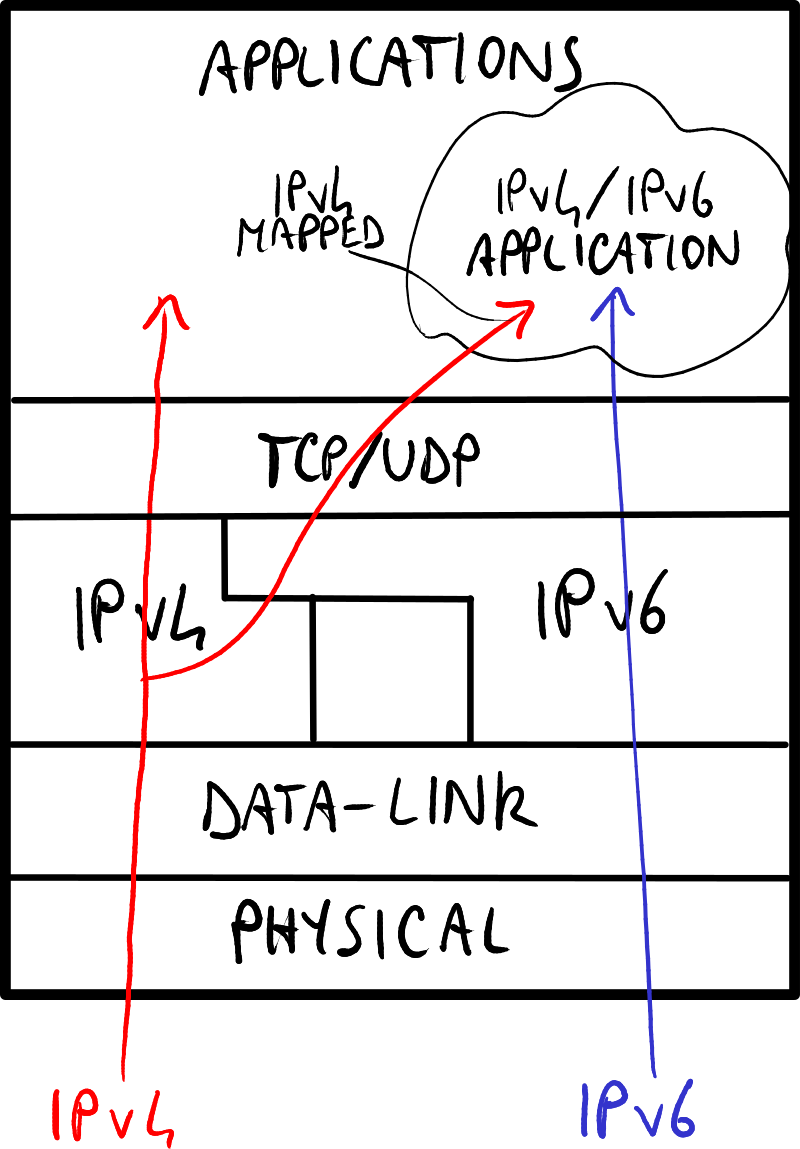
操作系统通过采用双栈(Dual Stack)方法支持IPv6:
- 无双层模式:操作系统独立处理IPv4和IPv6地址 → 软件需要同时支持IPv4和IPv6地址。
- 双层模式:操作系统能够将IPv4地址转换为IPv4映射的IPv6地址 → 软件只需支持IPv6地址,无需关心IPv4地址。
双层模式使用最为广泛,因为它将复杂性转移到了操作系统核心。
网络设备迁移
交换机迁移
理论上,交换机仅工作在第2层,因此不受第3层协议变化的影响。但某些附加功能可能带来问题,例如IGMP嗅探(用于过滤传入的组播数据包)。由于数据包格式和字段变化,交换机可能无法识别IPv6组播数据包并丢弃它们。
路由器迁移
当代路由器大多已支持IPv6,但由于经验不足及IPv6流量需求较低,IPv6性能通常仍逊于IPv4。
典型的支持IPv6的路由器采用类似“夜间船只(ships in the night)”的双栈方法:IPv4和IPv6由两个独立的传输层栈支持 → 这需要完全复制所有组件,包括路由协议、路由表、访问列表等。
-
路由表:
- IPv6路由与IPv4路由方式相同,但需要两张独立的路由表。
- IPv6路由表可存储以下几种条目:
- 间接条目(O/S代码):指定下一跳路由器的接口地址(通常为链路本地地址)。
- 直接条目:指定路由器自身的接口,用于发送到本地链路的包:
- 连接的网络(C代码):指定本地链路的前缀。
- 接口地址(L代码):指定本地链路中的接口标识符。
-
路由协议:
- 支持IPv6的路由协议可以采用两种方法:
- 集成路由(例如BGP):允许同时交换IPv4和IPv6的路由信息 → 效率更高。
- 夜间船只模式(例如RIP、OSPF):协议仅交换IPv6路由信息 → 灵活性更高,可以分别使用不同协议处理IPv4和IPv6路由信息。
- 支持IPv6的路由协议可以采用两种方法:
DNS迁移
支持IPv6的DNS可以将两个IP地址映射到同一个别名:一个IPv4地址和一个IPv6地址 → 公共目标既可通过IPv4也可通过IPv6访问。
- 支持IPv6的DNS不仅可通过IPv6返回IPv6地址,也可通过IPv4返回 → 因为DNS消息属于应用层,转发DNS查询和回复所用的传输层协议并不重要。
- 执行DNSv6查询的命令为:
set q=aaaa。
例如,一家公司可能希望通过IPv6为其公共网站提供访问服务。然而,由于当前大部分流量通过IPv4传输,IPv4服务在性能和容错性方面通常比IPv6服务更可靠。为了避免用户因IPv6性能问题转而选择竞争对手的网站,公司可以采取以下措施:
- 进行预评估,测试用户与公司服务器之间的连接性能。
- 在DNS中实现附加机制:DNS应能够查看查询的源地址。
- 如果尚未进行连接性能评估,仅返回IPv4地址;
- 如果连接性能良好,则同时返回IPv4和IPv6地址。
隧道解决方案
网络在零日时并不会完全支持IPv6 → IPv6流量可能需要通过仅支持IPv4的网络部分。面向网络的隧道解决方案使得即使IPv6网络通过仅支持IPv4的基础设施连接,也能够实现IPv6网络之间的互通,其原理是将IPv6数据包封装在IPv4头中,仅用于通过隧道传输:
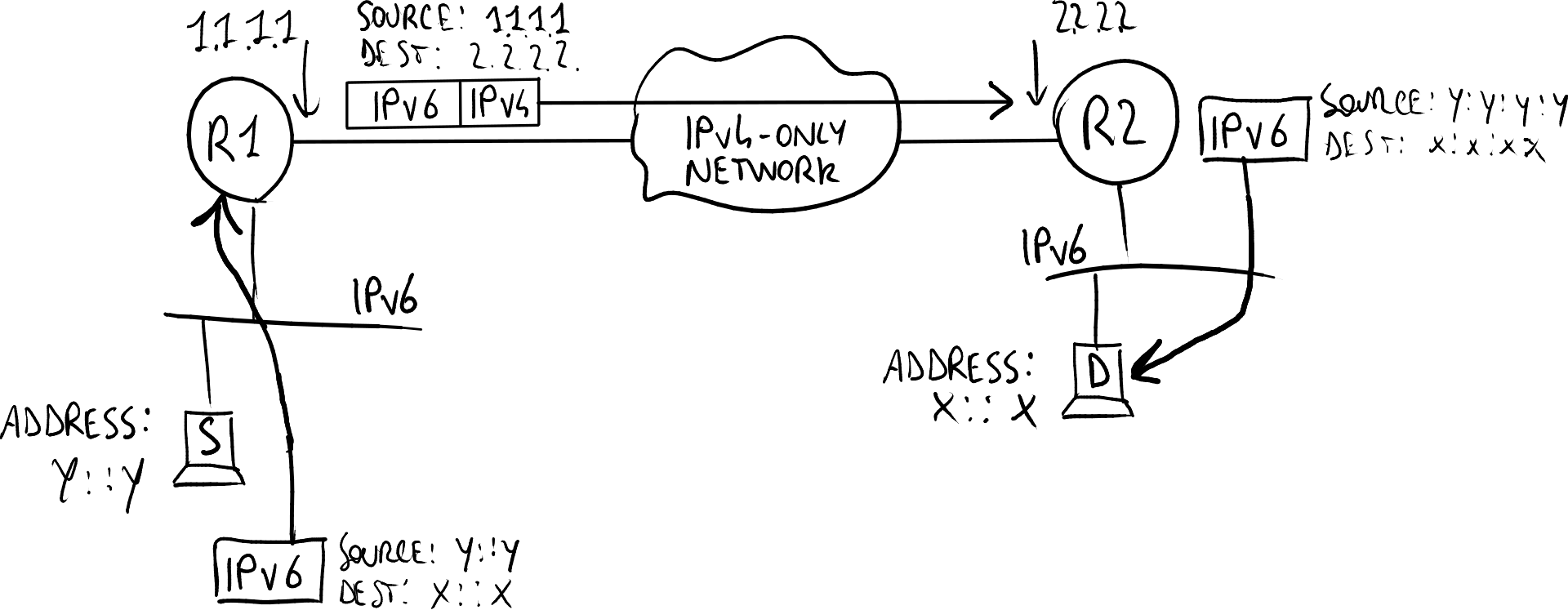
隧道数据包的大小(包括20字节的IPv4头)不能超过IPv4数据包的最大大小 → 有两种可能的解决方案:
- 分段:路由器在将IPv4数据包发送到隧道之前对其进行分段 → 由于性能原因,分段已不推荐使用;
- 较小的IPv6数据包:主机应生成具有较小MTU大小的IPv6数据包,以考虑到IPv4头插入的额外大小 → 路由器可以通过“路由器广告”ICMPv6消息指定允许的MTU大小。
面向主机的隧道解决方案
面向主机的隧道解决方案对于主机来说更为即插即用,但它们不是专业的解决方案,并且不能解决IPv4地址短缺的问题,因为每个主机仍然需要拥有一个IPv4地址。此类解决方案包括:
- 使用IPv6 IPv4兼容地址,隧道终结点在主机或路由器;
- 6over4;
- ISATAP。
使用IPv6 IPv4兼容地址
这些解决方案假定双栈主机在需要联系IPv4目标时,将IPv6数据包发送到IPv4兼容的IPv6地址,该地址的前96个高位为零,剩余32个低位与目标IPv4地址一致。然后,IPv6数据包被封装在IPv4数据包中,IPv4数据包的目标地址取决于你希望隧道终结在哪个位置:
- 端到端终结:双栈主机上的伪接口执行封装,将IPv6数据包封装为目标主机的IPv4数据包;
- 路由器双栈终结:主机上的伪接口将目标主机的IPv6数据包发送到双栈路由器的IPv4地址:
- 为目标生成IPv6 IPv4兼容地址,如前所述;
- IPv6数据包封装为指向双栈路由器的IPv4数据包;
- 双栈路由器解封装数据包并将其发送到目标主机。
6over4
这个方法的思想是通过IPv4模拟一个支持组播的本地网络。实际上,像通过以太网连接两个IPv6主机一样,邻居发现被用来利用以太网的广播机制;在这个解决方案中,我们把IPv4当作低层协议,并改变邻居发现来查找IPv4地址,而不是MAC地址。这个方法可以推广到连接IPv6网络的云(而非单独的主机)的情况,通过双栈路由器在IPv4网络中进行通信。在这种情况下,除了邻居发现之外,还可以使用修改版的路由器发现协议,通过发送路由器请求来发现连接到主机IPv4网络的路由器IPv4地址,这些路由器允许访问不同的IPv6网络;实际上,主机可以通过路由器广告获取有关可访问IPv6网络的信息。
这个方法的一个问题是IPv4组播的使用,在不同提供商的网络中,IPv4组播通常是禁用的。该解决方案适用于当你完全控制一个网络时:因此,它无法用于将全球网络从IPv4迁移到IPv6。
6over4 邻居发现
根据RFC的提案,IPv6地址与IPv4地址进行映射:实际上,IPv4地址作为目标IPv6地址的接口标识符使用。这样,所展示的机制就变得不再必要,因为主机可以直接进行隧道通信,无需邻居发现来查找IPv4地址。当然,当IPv6地址不是从IPv4地址构建时,这个方法就不适用,因此仍然需要一个更通用的机制来联系路由器。因此,假设我们只知道一个IPv6地址,邻居发现将会发送到请求节点的组播地址(例如,如果IPv6地址是
fe80::101:101,那么它会发送到ff02::1:ff01:101),该地址位于IPv4的6over4组播网络,地址为239.192.x.y,其中最后16位由IPv6地址的最后16位组成(因此在上述示例中,将为239.192.1.1)。ISATAP
ISATAP的思想类似于6over4,即使用IPv4网络作为物理链路来到达IPv6目标,但我们希望克服对组播支持的要求。在没有邻居发现机制的情况下,使用ISATAP的目标IPv4地址会嵌入到IPv6地址中,具体地,嵌入到接口标识符中,其格式为
0000:5efe:x:y,其中x和y是IPv4地址的32位。可以看出,这个解决方案并没有解决IPv6引入的根本问题——IPv4地址的稀缺性。然而,在IPv4链路连接非主机(而是具有IPv6云的边界路由器)的场景中,这个解决方案更为有用。在这种情况下,IPv4网络中的主机如果想要与属于某个云的主机通过IPv6通信,就必须配备潜在路由器列表(PRL)。此时会出现以下问题:-
如何获取PRL? 目前有两种解决方案:一种是专有的,基于使用DHCP;另一种是标准的,基于使用DNS。在后者中,可以通过DNS查询特定的名称格式
isatap.dominio.it来提供连接到IPv4网络的IPv6路由器的PRL。 -
应将数据包发送到哪个路由器以到达IPv6目标? 对PRL中的每个路由器使用单播路由器发现协议,以通过路由器广告获取回应。实际上,在路由器广告中,路由器还可以宣布可通过它们到达的IPv6网络列表(参见ICMP路由器广告中的Prefix Information Option中的L=0标志)。
面向网络的隧道解决方案
通常,面向网络的隧道解决方案需要手动配置,且封装可以基于IPv6在IPv4中的封装(协议类型 = 41)、GRE、IPsec等。
6to4
与先前的解决方案相比,6to4的最大进步在于新的场景中不再是单个主机需要一个IPv4地址来从IPv6云中出去,而是一个完整的IPv6网络需要一个IPv4地址来与外界通信。两个地址之间的映射会发生在IPv6前缀中,而不是接口标识符中:一个特殊的前缀被分配给所有IPv6网络,包含指向双栈路由器接口的IPv4地址,双栈路由器面对的是该云。前缀
2002::/16用于标识使用6to4的IPv6主机:在接下来的32位中设置IPv4地址,剩下的16位用于表示多个子网,而接口标识符则像其他IPv6使用场景一样生成。在这个解决方案中,还有一个具有特定作用的路由器——6to4转发路由器,它必须是6to4路由器的默认网关,用来将非6to4格式的数据包转发到全球IPv6网络。该路由器的地址是192.88.99.1,这是一个任何播送地址:6to4的设计者认为这种方式很有用,因为它使得在同一网络中存在多个6to4转发路由器时不会遇到地址冲突的问题。实际例子
假设有两个IPv6云连接到一个IPv4云,且双栈路由器的接口分别为连接到IPv6云A和云B的地址
192.1.2.3和9.254.2.252。假设网络A中的主机a想要发送一个数据包给网络B中的主机b。根据上述配置可以看出,网络A中的主机将使用2002:c001:02:03/48地址,而网络B中的主机使用2002:09fe:02fc::/48地址。从a到b的IPv6数据包将被封装在一个IPv4数据包中,目标地址为9.254.2.252,该地址来自目标IPv6地址的前缀。数据包到达该路由器时,将会被解封装并根据网络B的IPv6地址计划进行转发。Teredo
Teredo与6to4非常相似,唯一不同的是封装是在一个包含在IPv4数据包中的UDP段内进行的,而不是简单地封装在IPv4中。这是为了克服6to4的一个局限性,即穿越NAT的问题:由于6to4的IPv4数据包中没有两级封装,NAT无法正常工作。
隧道代理
6to4解决方案的问题在于它不够通用:你被绑定在使用
2002::/16前缀,并且无法使用常规的全球单播地址。在隧道代理解决方案中,由于无法从IPv6前缀推断出数据包应发送到哪个端点,因此使用一个服务器,该服务器根据给定的IPv6地址提供要联系的端点隧道地址。实现隧道代理的路由器称为隧道服务器,而提供映射的服务器称为隧道代理服务器。隧道与6to4相同,即IPv6封装在IPv4中:如果穿越NAT是一个问题,你还可以使用Teredo的方式,通过UDP进行封装,再封装在IPv4中。隧道代理服务器需要进行配置:隧道信息控制(TIC)用于转发有关给定隧道服务器可达网络的信息,从配置的隧道服务器到隧道代理服务器。而隧道设置协议(TSP)则用于向隧道代理服务器请求信息。同样,你可以为全球IPv6网络提供默认网关。总结来说,配置了这个方案的路由器,当一个数据包到达时,可以:
- 如果数据包与路由表中的条目匹配,直接转发(经典情况);
- 向隧道代理服务器询问是否需要对该地址进行隧道封装;
- 如果隧道代理服务器的响应是否定的,则将数据包发送到全球IPv6默认网关。
问题
这是一个集中式解决方案,因此隧道代理服务器是单点故障的来源。 它使控制计划变得复杂。 如果这个服务器被用于互联不同的网络,即使它们属于不同的提供商,也会引发管理责任的问题。
优势
它比6to4更灵活,因为它允许使用所有的全球单播地址。
将IPv6支持引入网络边缘
基于NAT的解决方案
主要基于NAT的解决方案
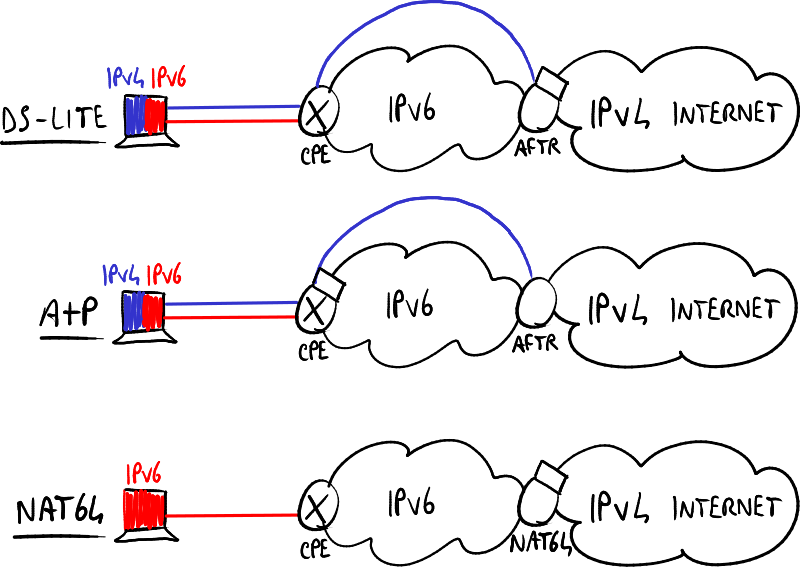
目标是迁移大型提供商的网络,使得在网络边缘的IPv4和/或IPv6云能够使用IPv6骨干网进行互操作。常见的场景是用户希望通过提供商的IPv6网络连接到IPv4目的地。
所有可用的选项都利用了NAT。NAT的使用有些逆流而行,因为IPv6的目标之一就是避免在网络中使用NAT,因其带来了许多问题(例如,数据包在传输中发生变化、对等网络问题等)。然而,基于NAT的解决方案存在多种优势:NAT已经广泛应用于网络,其问题和限制已知,应用程序的NAT穿透问题也已被了解。因此,普遍的优势在于迄今为止积累的大量经验。
主要组成部分
在基于NAT的解决方案中,有三个主要组件:
- 客户边缘设备(CPE):这是位于客户边缘、位于提供商网络之前的路由器。
- 地址族转换路由器(AFTR):它是IPv6隧道集中器,即隧道末端的设备。
- NAT44/NAT64:它是一种NAT,用于将IPv4/IPv6地址转换为IPv4地址。
主要基于NAT的解决方案
- NAT64
- 双栈精简(DS-Lite):NAT44 + 4-over-6隧道
- 双栈精简地址+端口(DS-Lite A+P):预配置端口范围的DS-Lite
- NAT444:CGN + CPE NAT44,即当家庭用户从电信公司获取服务时,在自己的家庭网络中添加一个NAT;每个从家庭网络出去的数据包会经过两次地址转换。
- 运营商级NAT(CGN):大规模的NAT44,用于电信公司将成千上万的(用户)私有地址映射到有限的公共地址。
对于面向移动设备的大型网络迁移,选择了NAT64解决方案。
为了在网络边缘迁移到IPv6并保持IPv4兼容性,一些电信运营商正在规划大规模的迁移到DS-Lite,因为它是一个经过充分测试的解决方案,并且已有许多兼容设备出售。
由于缺乏经验,A+P解决方案尚未被认真考虑。
NAT64
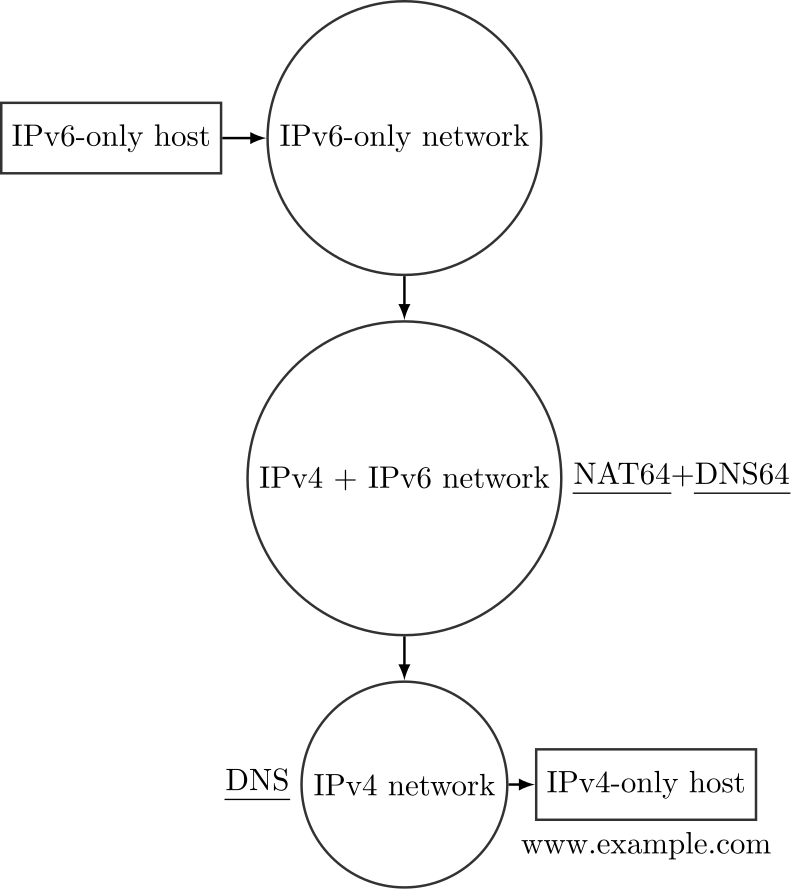
IPv6-only用户在浏览器中输入www.example.com,作为IPv6用户,他会向提供商的DNS64发送AAAA查询。假设www.example.com有IPv4地址“20.2.2.2”。 如果DNS64没有解析到该名称,它需要将查询发送到上级DNS,假设在IPv4网络中。 在最佳情况下,DNS64会将AAAA查询发送给上级DNS,得到AAAA类型的响应(即IPv6格式),并将该响应原封不动地返回给主机(通过IPv4数据包发送的DNS查询也能要求解析出IPv6地址)。 在最坏的情况下,如果上级DNS不支持IPv4,它会回复“名称错误”;此时,DNS64再次发送查询,但这次是A类型的查询,然后会得到一个正确的响应。该响应将转换为AAAA并返回给主机。在返回给主机的响应中,最后32位与上级DNS在A记录中发送的IPv4地址相同,而其他96位则补充完成IPv6地址;因此,最终地址将是“64:FF9B::20.2.2.2”。 此时,主机准备好与www.example.com建立TCP连接。 NAT64介入:它将来自主机的IPv6数据包转换为IPv4,并对来自20.2.2.2的包执行反向操作。
考虑
在这种情况下,没有隧道机制:IPv6头部仅被替换为IPv4头部,反之亦然。 IPv6-only主机并不知道目标地址与IPv4地址有关。 NAT64不仅能够将IPv6地址转换为IPv4地址,而且它在某种程度上使得网络相信232个IPv6地址可用,因为从主机到NAT64的每个数据包将有“64:FF9B::20.2.2.2”作为目标地址,前缀为“64:FF9B/96”。 提供商网络(NAT64和DNS64所在的网络)是IPv6本地的,因此提供商网络中的主机可以直接与其他支持IPv6的主机进行通信,而无需经过NAT64。 “64:FF9B/96”是专门为这种转换技术标准化的地址空间,分配给NAT64,但网络管理员可以根据需要更改它。值得注意的是,网络管理员需要配置路由,以确保任何具有该前缀的数据包都会送往NAT64,并配置NAT64,使其将所有具有该前缀的IPv6数据包转换为IPv4并转发到IPv4网络。
缺点
NAT的存在引入了一个典型的问题:位于NAT后面的主机不能轻易地从外部访问。 通常情况下,当DNS没有地址解析时,它不会回复任何信息,而是直接不回应,而不是发送“名称错误”;这会导致DNS64等待超时,从而延迟时间,超时后DNS64会发送A类型的查询。 如果用户希望直接输入IPv4地址,这种解决方案就无法使用:用户始终需要指定目标的名称。
DS-Lite
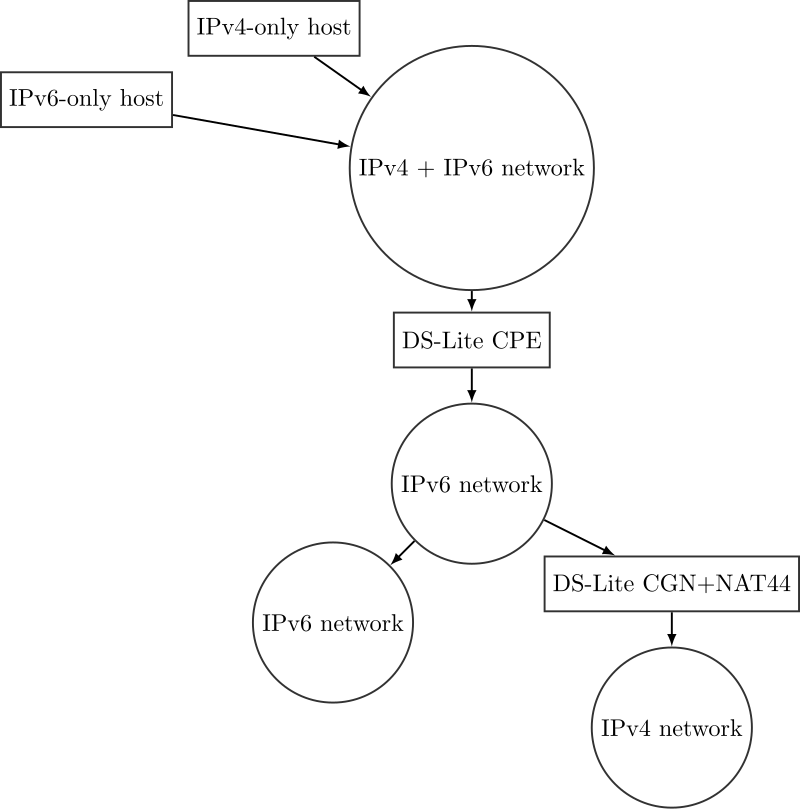
**双栈精简(DS-Lite)**解决方案通过将NAT和DHCP功能移至提供商网络的边缘,从而简化CPE,变成一个同时作为AFTR和CGN-NAT44的设备。
提供商的DHCP服务器为每个CPE的每个主机分配一个唯一的IPv6地址,该地址在提供商网络中是唯一的。 当用户需要发送IPv4数据包时,需要进行隧道操作,将IPv4数据包封装到IPv6数据包中,因为提供商的网络仅支持IPv6。因此,当CPE收到IPv4数据包时,它需要将其隧道化为IPv6数据包,以便将其发送到AFTR,之后是IPv4云;因此,提供商IPv6网络中,CPE和AFTR之间的场景涉及大量的隧道操作。特别地,CPE和AFTR之间的数据包,源IPv6地址是AFTR的地址,目标IPv4地址是IPv4网络中的目标地址。 AFTR在去除IPv6头部后,将数据包发送到NAT44,NAT44将IPv4(私有)源地址替换为NAT所接收的与该流关联的IPv4地址。 DS-Lite的主要优势是显著减少了提供商公共地址的使用数量。
提供商网络中是否会有重复的IPv4地址?
不会,因为NAT44直接将主机的IPv4地址转换为可用的公共IPv4地址。如果有重复的私有IPv4地址,NAT将遇到歧义问题。缺点
- 一个IPv4主机无法联系IPv6目标 → 仅支持IPv6的目标只能被IPv6主机访问。相反,IPv6主机可以直接与IPv6节点进行数据交换,无需经过提供商的AFTR。
- 某些应用无法在这种情况下工作:由于NAT不再由用户管理,而是由提供商管理,因此无法执行一些常见操作,例如打开/关闭特定应用所需的端口。
DS-Lite A+P
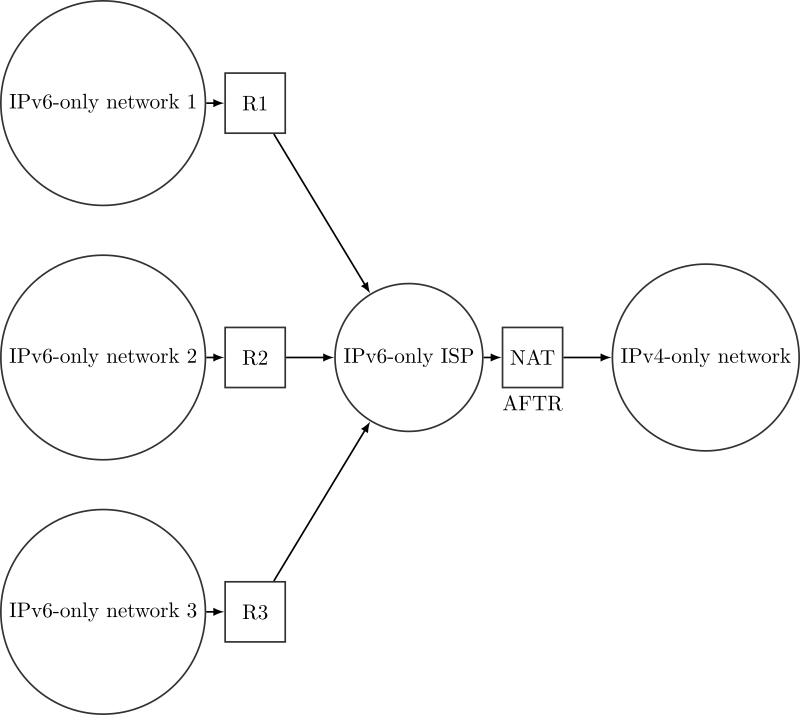
**双栈精简地址+端口(DS-Lite A+P)**解决方案仍然使用提供商的IPv6-only网络,但NAT被移到CPE上,以便用户可以根据自己的需求进行配置。
与DS-Lite类似,从CPE出去的IPv4数据包仍然需要通过隧道化,因为提供商网络仍然是IPv6-only。
每个CPE上的NAT需要一个公共IPv4地址的问题通过允许重复使用公共IPv4地址得到解决,CPE通过端口进行区分。每个CPE使用特定的端口范围,AFTR根据每个CPE使用的端口范围来区分数据流,即使多个CPE使用相同的公共IPv4地址。
这种解决方案与DS-Lite类似,但私有IPv4地址空间更加由终端用户控制,因为NAT位于用户的CPE上,用户可以配置它,尽管有些限制:用户不能使用不在其端口范围内的端口。此方法可以节省IPv4地址(但相对于DS-Lite来说,节省的数量较少)。
在意大利,这种解决方案基本上是非法的,因为端口号没有记录,如果发生攻击,就无法追踪到攻击者。
在核心网络中传输IPv6流量
主要目标是让IPv6流量能够通过全球网络传输,而不会破坏现有的网络结构,该网络已经运行了超过20年,并且目前运行良好。全球范围内的IPv4网络大规模迁移至IPv6会涉及人力和技术上的高成本,这几乎是不可持续的。
6PE
**6提供商边缘(6PE)**解决方案的目标是通过MPLS骨干网将多个IPv6云连接在一起。6PE要求运营商的网络采用MPLS技术。在这种方案中,提供商的边缘是用户CPE首先遇到的路由器。
思路
- 保持核心网络不变(不排除未来的变化可能性)。
- 为提供商网络的边缘添加IPv6支持。
- 通过MPLS/BGP传递IPv6路由信息,类似于VPN的工作原理。
要求
- 主要要求是拥有一个MPLS核心网络。
在图中:

- MPLS核心网络由PE-1、P-1、P-2、PE-2组成;
- 两个侧设备PE-1和PE-2部分“嵌入”到MPLS网络中;
- CE与PE之间的连接可以视为为家庭用户提供ADSL连接的连接。
6PE的设计是让核心网络能够支持IPv4数据包通过MPLS传输,而只在提供商的边缘路由器(PE)添加IPv6支持。事实上,一旦数据包被封装成MPLS数据包,中间设备就不再关心封装的数据包类型,而只关心标签,从而确定如何路由该数据包。
实际上,PE需要进行额外的更新以支持MG-BGP协议,该协议允许传输和通信IPv4和IPv6路由。
对于这种解决方案的一个重大优势是只需要更新PE路由器,而不需要更新所有中间路由器:这是提供商可以管理的一个低成本操作。
IPv6网络的广告方式
CE-3广播自己能够访问IPv6网络“2001:3::/64”。 该信息也会传递给PE-2。 PE-2将此信息发送到网络中的所有PE,告知它能够通过下一个跳点“FFFF:20.2.2.2”访问“2001:3::/64”网络,尽管它的接口是IPv4(这是因为如果给出IPv6路由,则需要给出IPv6的下一跳)。 PE-1接收到该信息,并将其传递给所有与其连接的路由器,包括家庭CPE,告知它能够访问网络“2001:3::/64”。 如果PE-1与地址“20.2.2.2”之间尚不存在MPLS路径,则使用经典的MPLS机制(例如LDPv4信令协议)来建立该路径。
IPv6流量的路由方式
为了路由IPv6数据包,使用两个标签:
- LDP/IGPv4外部标签到PE-2:用于标识PE之间的LSP。
- MP-BGP内部标签到CE-3:用于标识目标CPE。
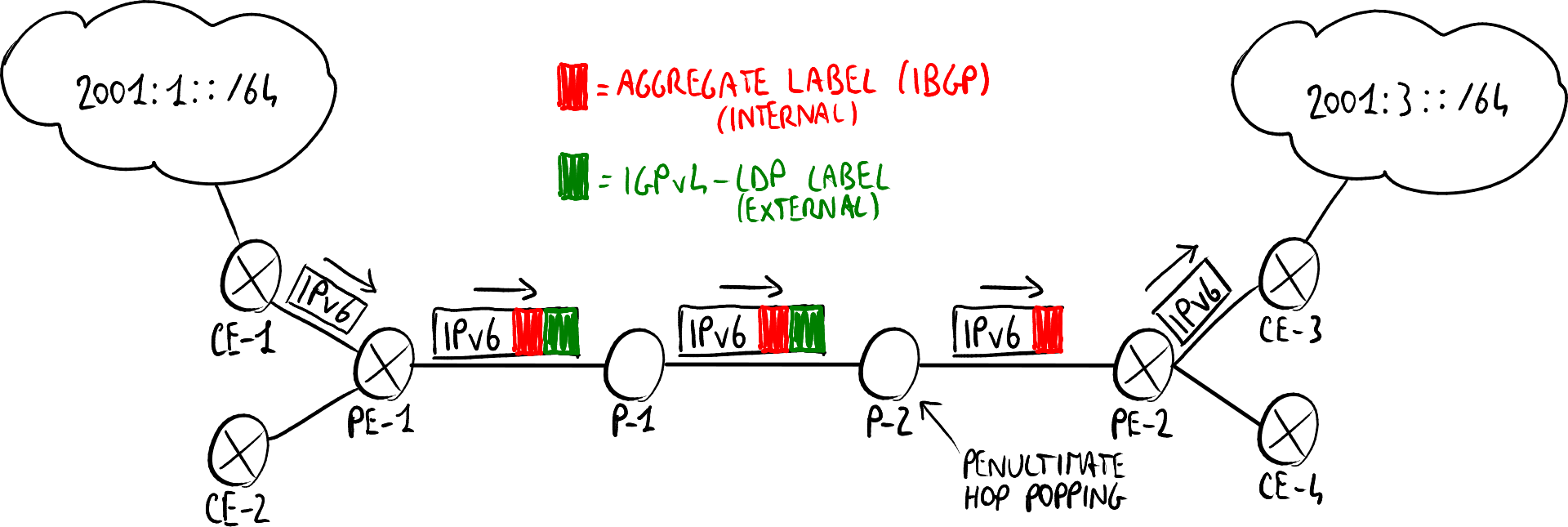
假设网络“2001:1::/64”中的主机想要将数据包发送到“2001:3::/64”网络中的主机:
- 数据包到达CE-1;
- CE-1知道“2001:3::1/64”网络的存在,并将数据包发送到PE-1;
- PE-1在数据包前添加两个标签:内部标签和外部标签;
- PE-1将数据包发送到P-1,P-1再转发到P-2;
- P-2,作为倒数第二跳,移除外部标签(倒数第二跳标签弹出)并将数据包发送到PE-2;
- PE-2移除内部标签,并将数据包发送到CE-3;
- CE-3将数据包转发到目标网络“2001:3::/64”。
考虑事项
- PE路由器需要支持双栈并支持MP-BGP,而中间路由器不需要任何更改。
- 这种解决方案可以为客户提供原生的IPv6服务,而无需更改IPv4 MPLS核心网络(需要的操作成本和风险最小)。
- 该方案适用于部署少量IPv6云的情况。
安全问题
由于IPv6尚未广泛使用,安全性问题经验较少 → IPv6可能仍然存在未被发现的安全漏洞,攻击者可能会利用这些漏洞。此外,在迁移阶段,主机需要同时开放两个端口,一个用于IPv4,另一个用于IPv6 → 需要保护这两个端口免受外部攻击。
DDoS攻击与SYN洪水 主机接口可以有多个IPv6地址 → 它可以生成多个TCP SYN请求,每个请求都有不同的源地址,向服务器发送,利用这一点耗尽服务器内存,使其打开多个未关闭的TCP连接。
虚假路由广告消息 主机可能开始发送“路由器广告”消息,宣称虚假的前缀 → 链路中的其他主机将开始发送具有错误前缀的源地址的包。