计算机网络技术与服务
Section outline
-
严格来说,广域网(WAN)是覆盖广泛区域的网络,跨越多个地区、国家,甚至在互联网的情况下覆盖全球。更一般来说,任何用于长距离传输数据的计算机网络技术都可以被称为WAN。
WAN技术应根据其设计的应用(遥测、电话、数据传输等)满足一些服务持续时间、比特率和延迟约束。
异步传输模式(ATM)代表了多种技术的融合,过去电信和信息技术领域在并行使用的方式中,都引入了用于长距离传输数据的技术:
- 在电信领域,电话从模拟信号转为数字信号,随后ISDN和B-ISDN开始同时承载语音和数据;
- 在信息技术领域,帧中继通过利用分组交换取代了模拟和数字专线,而X.25则通过将复杂性从核心节点转移到边缘节点来实现。
如今,ATM由于其较低的复杂性和更高的简便性,正逐渐被IP取代。
ISDN
集成服务数字网(ISDN)可以同时传输数据和语音:各种数字设备可以连接到总线上,并通过可用的ISDN通道进行传输:- 基本速率接入(BRA)或基本速率接口(BRI):提供2个64kbps的数据B通道和1个16kbps的信令D通道 → 总速率:144kbps(适用于单个用户或小型办公室);
- 主速率接入(PRA)或主速率接口(PRI):提供30个64kbps的数据B通道和1个16kbps的信令D通道 → 总速率:2Mbps(适用于公司)。
传输基于时分复用(TDM);所有通道都连接到网络终端并通过称为“本地环路”的数字线路进入网络。这些通道继承了电信运营商的逻辑:即使没有数据交换,它们仍然处于活动状态。
PDH
PDH的层次结构。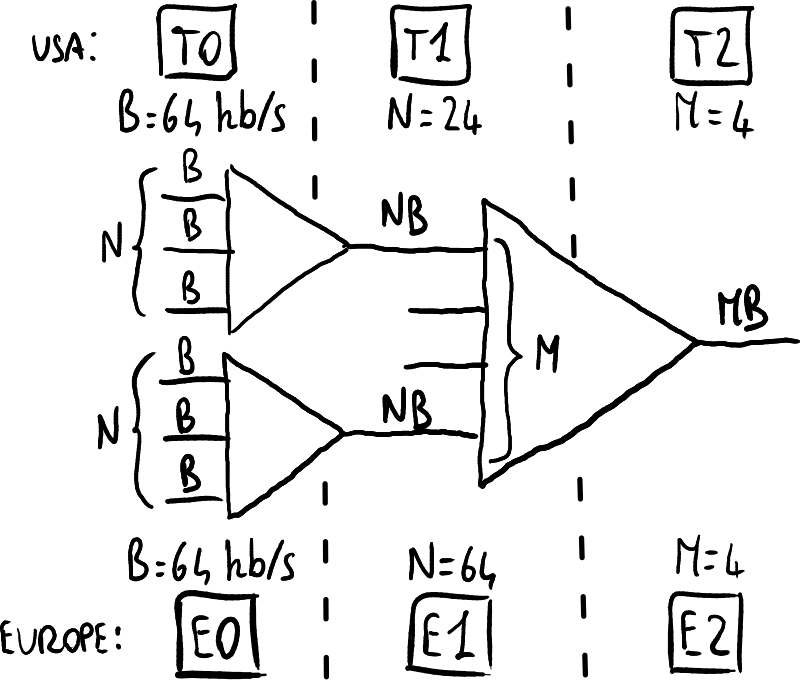
Plesiochronous Digital Hierarchy(PDH)是一种旧标准,旨在通过基于TDM的数字电话网络传输64Kbps的数字语音通道(PCM)。该系统称为“准同步”是因为需要在发射机和接收机之间进行严格同步,尽管每个设备都有自己的时钟。
数据流按层次结构组织:通道按从低层到高层的顺序进行聚合(整流),层级越高,比特率越高。例如,在T1层,24个T0层通道被放入一个单一的帧中,紧挨在一起:由于帧必须持续125微秒,所以在T1层,比特率将比T0层高24倍。
SDH
SDH物理和协议体系结构。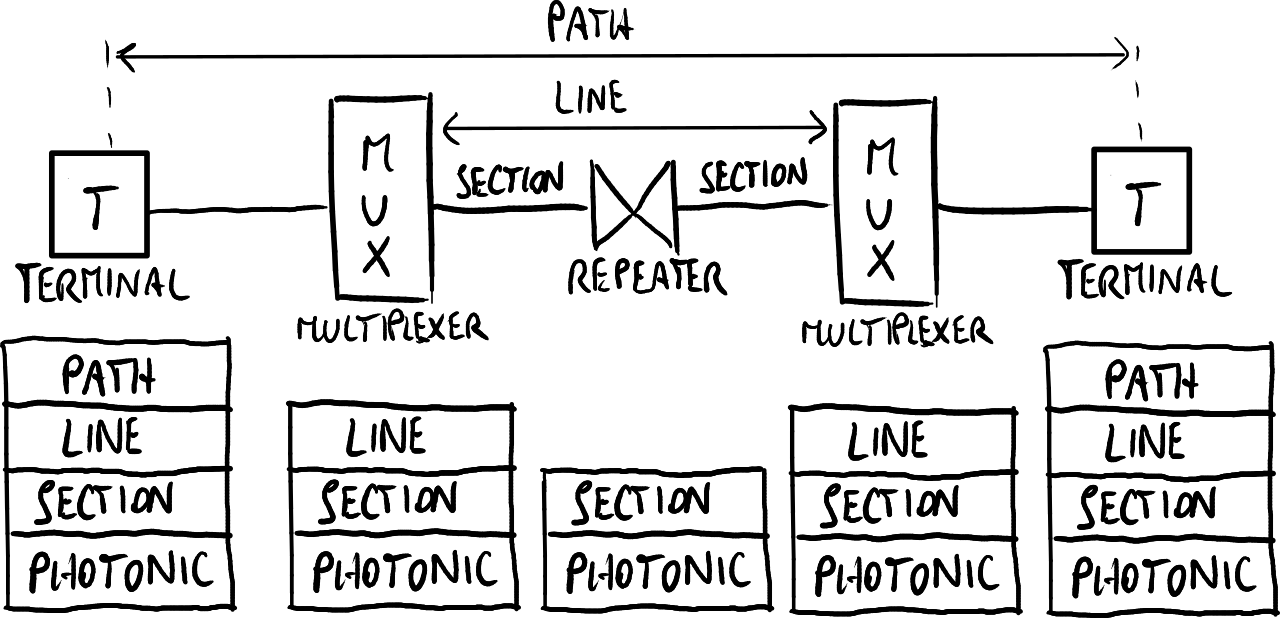
同步数字层次(SDH),是国际标准SONET的欧洲对应物,与PDH不同,它具有更高的速度:- 系统内存在一个统一的时钟 → 需要一个同步网络来实现更紧密的同步;
- 铜线需要被光纤替代;
- 流复用比PDH更复杂,因为它旨在优化硬件处理。
协议架构被组织为一个层次堆栈,每个物理网络架构中的节点根据其功能实现这些层次:
- 路径层:端到端的两个终端之间的互联;
- 线路层:通过复用器将路径分割为多条线路;
- 节段层:通过中继器将线路分割为多个段(适用于长距离);
- 光子层:光纤的最低层。
每个时间帧持续125微秒,其头部包括用于合并和分离通道的同步信息,以及用于检测故障和恢复的OAM(操作、管理和维护)信息。
SDH和PDH代表了ATM和帧中继运行的传输层。
帧中继
帧中继是一种面向连接的二层标准,用于在分组交换网络上建立永久虚拟电路。每个永久电路通过数据链路连接标识符(DLCI)来识别。该标准非常灵活:实际上,它并未指定网络中使用的上层技术(ATM、X.25等)。
CIR
蓝色用户的服务是有保障的,但是绿色用户没有,因为他的爆发量太高了。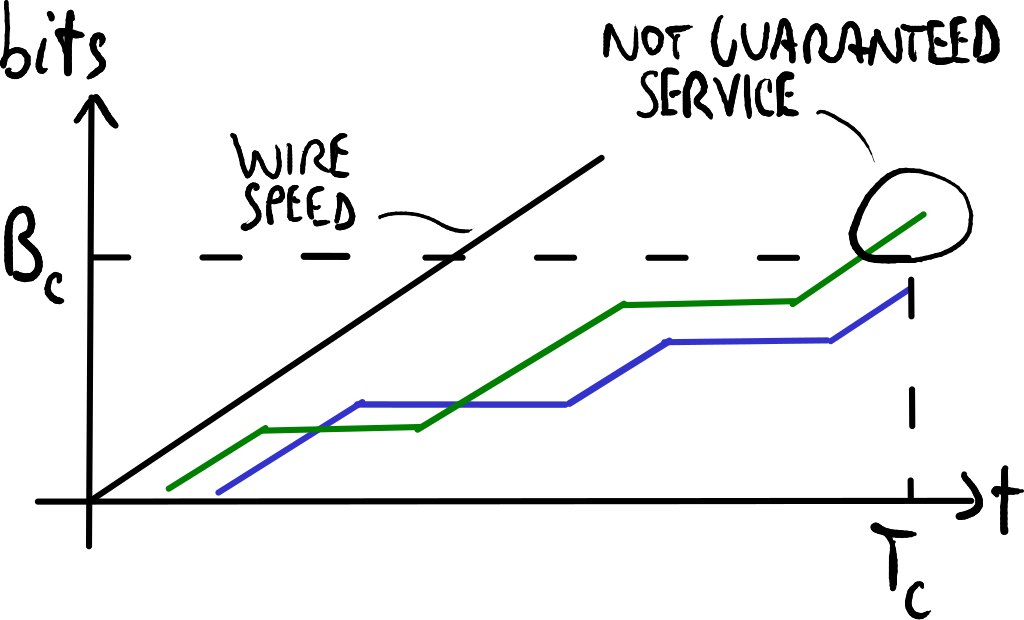
最大支持比特率不足以描述帧中继网络的性能,因为用户可能会以最大比特率(线速)连续发送比特,导致网络拥堵。因此,网络提供商还提供了承诺信息速率(CIR),即用户在某个时间间隔内可以传输的最大比特数,以确保服务:CIR = BC ⋅ TC,其中BC称为承诺突发大小:
- 低突发性:用户很少发送数据包 → 始终保证服务;
- 高突发性:用户连续以线速发送数据包 → 一旦超过承诺突发大小,服务将不再保证。
当用户的终端设备(DTE)达到最大突发性时,可以停止传输。
ATM
异步传输模式(ATM)是一种面向连接的标准,用于在B-ISDN网络上建立虚拟电路。每个电路由虚拟路径标识符(VPI)和虚拟电路标识符(VCI)标识,并可以通过信令消息进行永久或动态设置。ATM单元非常小:每个ATM单元长53字节,由一个5字节的头部和48字节的有效负载组成 → 低延迟和低封装延迟。
ATM网络具有非常复杂的模型,源自电信运营商的思维,旨在全面控制网络并保证高容错性。
AAL 5
当ATM设计时,预期它会普遍实施在网络中,包括用户PC的网络卡边缘。目前,PC在边缘仅实现IP协议,因为其实现成本更低,ATM只能作为网络核心的传输层存在。ATM适配层(AAL)类型5用于分段和重组(SAR):
- 分段:IP数据包被拆分成ATM单元;
- 重组:ATM单元被组合成IP数据包。
AAL使IP和ATM之间的交互变得复杂,因为IP地址需要转换为ATM连接标识符,反之亦然 → 如今的趋势是放弃ATM控制平面,转而采用MPLS控制平面。
光网络
在光网络中,数据通过使用波长分复用(WDM)技术通过光纤传输,并通过基于镜面的光开关系统进行切换。波长分复用(WDM)允许将多个光信号传输到一根光纤中 → 提高了光纤的传输能力:
- 粗波分复用(CWDM):允许传输较少数量的波长间隔较大的信号 → 更便宜,因为解复用更容易;
- 密波分复用(DWDM):允许传输更多数量的信号,波长间隔较小 → 更昂贵,因为解复用更复杂。
光开关基于由微机电系统(MEMS)控制的镜面反射,将电磁信号从输入光纤反射到输出光纤。光开关非常灵活:它利用电磁波的物理特性,而不关心比特内容 → 网络可以升级到更高的速度,因为光开关的工作与比特率无关。
存在几种类型的光开关:
- 加/删复用器:最简单的光开关,可以插入(添加)来自发射器的信号到网络中,并从网络中提取(删除)信号传向接收器;
- 交叉连接:可以将多个输入光纤连接到多个输出光纤;
- 光纤交叉连接:来自输入光纤的所有电磁波被切换到输出光纤;
- 波段交叉连接:来自输入光纤的一组具有接近波长的电磁波被切换到输出光纤;
- 波长交叉连接:来自输入光纤的一组具有相同波长的电磁波被切换到输出光纤;
- 波长开关:配置是动态的,即开关可以比交叉连接更快速地改变电路 → 故障恢复非常迅速。
通过波长转换,光开关可以将信号的波长更改为输出光纤中未使用的波长,从而保持所有信号的分离。
光开关可以用于网络骨干网中,连接主要接入点,通过光纤在全球城市之间建立光路径。光开关可以通过使用LDP和RSVP等信令和路由协议来设置光路径。光开关具有容错性:当链路断开时,它们可以通过其他光路径反射波。
WDM可以作为任何二层协议(SONET、以太网等)上运行的传输层,定义帧的边界。
然而,纯光交换技术仍处于初期阶段:如今WDM交换机比包交换机更昂贵,且接口数量有限,因为镜面系统对于多个接口会变得非常复杂。此外
,光交换是面向连接的:当电路建立时,资源仍然会分配,即使电路当前未使用 → 光交换适用于流量相对连续的网络骨干网。
一些更便宜的解决方案通过将镜子替换为电气交换矩阵来克服技术限制:每个光信号通过光电(OE)转换被转换成比特序列,以便更容易地进行交换,然后再转换回光信号。重新转换后的信号被再生,可以在失去功率之前传输更长的距离,但这种解决方案有很多缺点:与全光交换机相比,交换机消耗的功率较大,并且改变比特率需要升级交换机。
-
多协议标签交换(MPLS)是新一代宽带(IP)公共网络的关键技术。它可以被视为一种协议架构(或协议套件),用于控制不同的子协议。
MPLS工作在一个通常被认为位于传统第2层(数据链路层)和第3层(网络层)之间的层级。
优势
MPLS的引入简化了传统的“庞大洋葱”(指复杂的网络协议堆栈)。
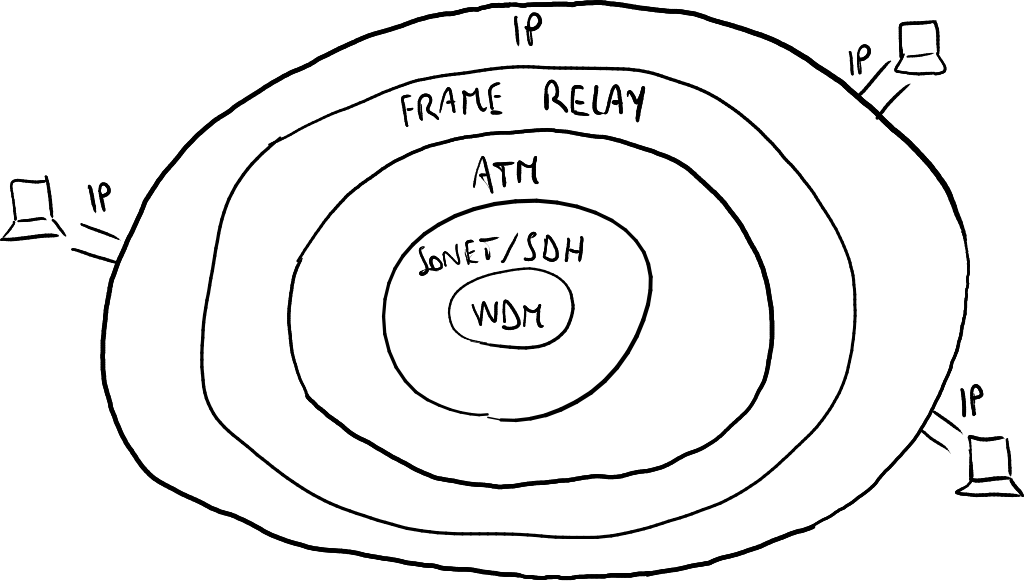
IP协议最初是为了研究目的开发的,并未设计为一种可销售的服务。它是所谓的“尽力而为协议”,这意味着它没有明确保证可靠服务(如速度、延迟等)的目的。
当IP开始成为商业产品时,国际电信联盟(ITU)开始开发一些协议(如ATM、帧中继等),以保证服务的可靠性和稳定性,认为它们将在计算机通信世界中普遍应用。然而,最终用户仍然继续使用IP,因此如今的服务提供商必须处理许多协议,以便将IP传输到最终用户。这种“庞大洋葱”对服务提供商而言几乎毫无意义,因为为了确保互操作性,需要高昂的维护、设备和软件开发成本。
思科系统是第一个将标签交换(Tag Switching)引入路由器的厂商,随后IETF采用了这一协议并将其命名为MPLS。
MPLS结合了无连接协议和面向连接协议的最佳特点,解决了“庞大洋葱”问题,原因有二:
- MPLS为基于IP的网络提供了更大的服务可靠性,并且有一个更为独立的、统一的控制平面;
- 在IP中,控制平面和数据平面在每次网络变化时都会不断更新;
- 在MPLS中,更新仅发生在建立新LSP(标签交换路径)时;由于数据平面和控制平面分离,可以设置具有独立约束的路径;
- MPLS允许通过简单地更新软件来重用传统的ATM设备。
主要特点
- 流量工程:通过分配流量负载以避免网络拥堵;
- 协议独立性(多协议支持):有助于IPv4向IPv6过渡;
- 质量保障设计:虽然尚未完全支持;
- 统一控制平面:它可以应用于除IP外的任何网络(例如,光纤网络中的MPLS);
- 快速故障恢复:可以在两个节点之间创建两条路径,因此在第一条路径出现故障时,LSR可以快速通知并将流量偏移到第二条路径(而在IP中,插入两条路径到路由表中比较困难,且若链路失败,路由器需要交换路由信息并执行复杂算法来找到另一条路径)。
网络架构
MPLS网络的示例。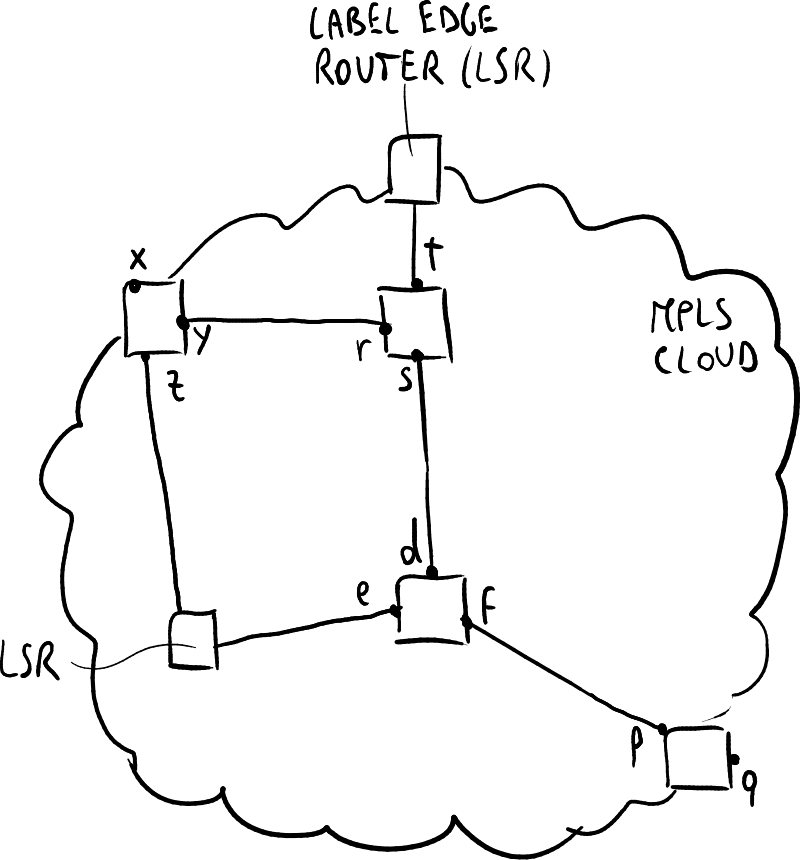
标签交换路由器(LSR)是负责切换用于路由数据包的标签的设备。当LSR位于MPLS云的边缘时,它们被称为标签边缘路由器(LER)。LSR结合了路由器的智能性和交换机的速度:它们能够像路由器一样智能地进行路由,但避免了交换机那样复杂的数据结构和算法。MPLS云可以逐步部署:它们可以扩展并相互集成。
数据平面
数据平面是根据数据包标签进行交换的能力。
包含单个标签堆栈条目的数据包格式。MPLS标签交换示例。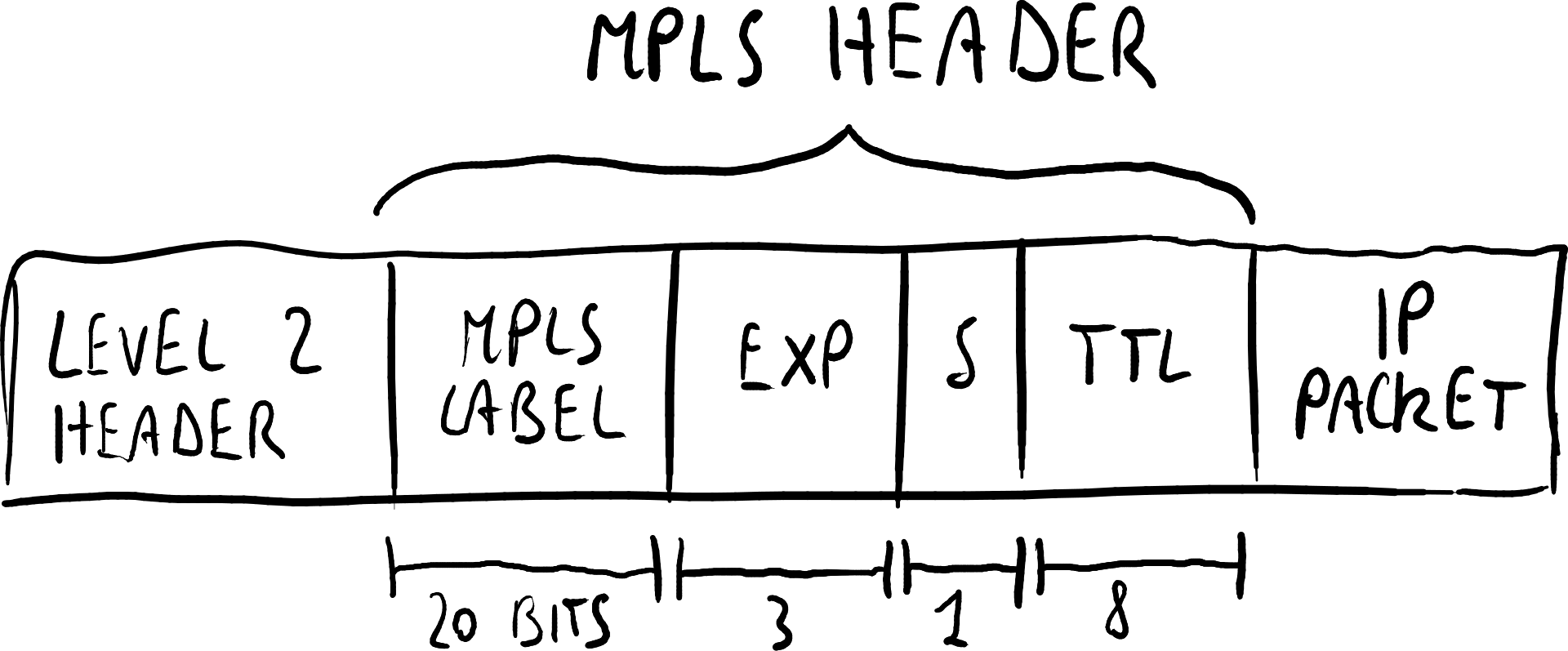
MPLS头部
IP数据包前面会附加一个包含一个或多个标签堆栈条目的MPLS头部。每个标签堆栈条目包含四个字段:- 标签:路由依据这个字段,而非IP目的地址;
- 流量类(exp):用于质量服务(QoS)优先级和显式拥塞通知(ECN);
- 堆栈底部标志(S):若设置,当前标签为堆栈中的最后一个标签;
- 生存时间(TTL)。
标签交换
MPLS标签交换示例。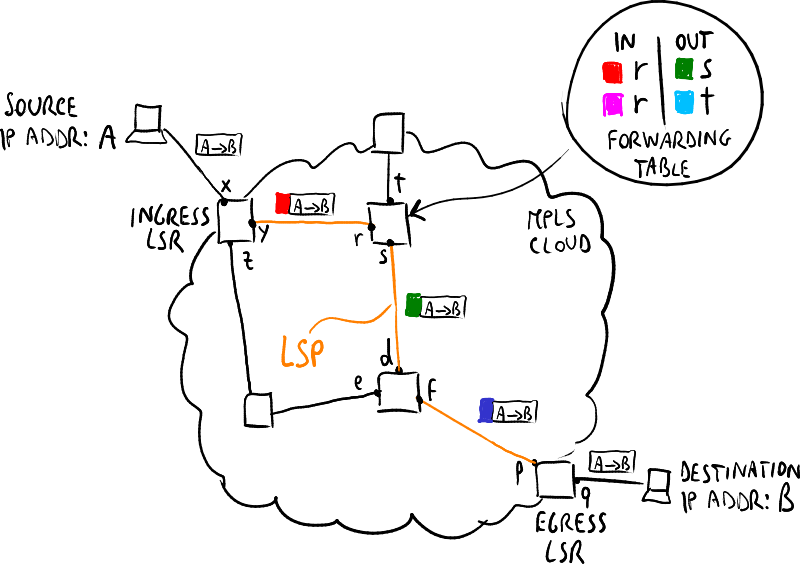
标签交换路径(LSP)是由信令协议建立的路径,将源标签边缘路由器(入口)与排水路由器(出口)连接起来:- 当入口LSR接收到一个数据包时,它会为数据包添加标签,并将其转发到先前创建的LSP的下一个跳点;
- 当出口LSR接收到数据包时,它会去掉标签并将数据包从MPLS云中转发出去。
转发等效类(FEC) 是一组可以以相同方式转发的数据包,即它们可以绑定到相同的MPLS标签。标签在整个MPLS云中并不唯一,但在每个跳点上都会改变(标签交换)。请注意,确保标签在网络中的唯一性会导致过于复杂的协议和过长的标签。
使用标签使得MPLS能够提供两种服务:
-
快速查找:IP路由使用“最长前缀匹配”算法,算法复杂,难以优化,并且在处理大量路由时速度不足。
MPLS相对于IP提供了更快的查找,因为数据包转发决策仅依赖标签,这些标签被放置在IP数据包之前,无需检查数据包本身的内容:每个标签实际上可以作为键来访问路由表,如数组或哈希表,以加快路由发现。 -
流量工程:IP倾向于将流量聚集在一起,但大量数据包通过同一路径传输并不能提供高效的服务。这种现象不容易避免,因为这需要静态路由配置 → 昂贵且不可扩展。
MPLS能够像面向连接的协议一样控制流量:MPLS路由同时涉及源和目标标签,路由器可以为新的数据包流分配标签,选择负载最小的路径,以避免拥堵并实现流量分配。此外,由于非工作节点导致路径故障不会影响其他路径。
层次性和可扩展性
LSP中的标签层次。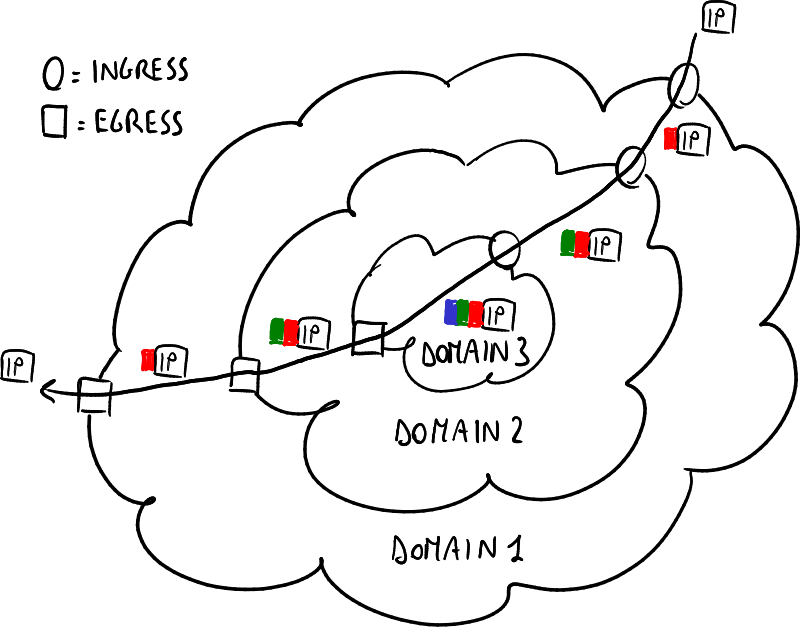
MPLS具有很好的可扩展性:在一个大型的MPLS云域(域1)内,可以以层次化的方式定义一个更小的MPLS云域(域2)等,多个标签堆栈条目可以并排存储在堆栈数据结构中。当数据包进入更高域的云时,标签堆栈条目会从内到外添加;当数据包退出较低域的云时,标签堆栈条目会从外到内移除,而不在云边缘的LSR始终处理最外层的标签堆栈条目。这个标签层次结构可以对应于服务提供商的层次结构,标签的数量仅受以太网帧大小的限制。这种技术带来了一些优势:
- 减少了路由和转发表的大小,因为它们不需要全面;
- 允许重用现有的交换硬件(如ATM、帧中继等):MPLS头部直接放入二层头部,因此可以通过升级软件处理现有硬件。
控制平面
控制平面是选择要插入数据包中的标签的能力。
为特定FEC创建转发表(以及更广义上的LSP)分为三步:
- 标签绑定:始终由下游节点执行,下游节点为FEC选择标签,这可以通过两种方式进行(非互斥):
- 无请求:下游节点可以随时选择标签,即使网络中没有流量;
- 按需:上游节点请求下游节点选择一个固定标签;
- 标签分发:下游节点将选择的标签通知给上游节点;
- 标签映射:上游节点通过将来自特定端口、特定标签的入站数据包映射到出站数据包(从特定端口、特定标签发出),在其转发表中创建新条目。
标签可以通过两种方式分配:
- 静态分配:网络管理员手动设置LSP,就像在面向连接的技术中设置永久虚拟电路(PVC)一样 → 这种解决方案无法扩展,并且限制了不同服务提供商之间的互操作性;
- 动态分配:标签绑定、分发和映射由LSR自动执行,无需手动干预:
- 数据驱动:LSP的创建由接收到的数据包触发,每个LSR根据流量自主选择标签;
- 控制驱动:在某些情况下,LSR会分配标签,即使没有流量;
- 拓扑驱动(或协议驱动):每当发现新的目的地时,会创建到该目的地的LSP → 没有流量工程,网络的工作方式
与IP网络相同;
- 显式驱动:LSP的创建通常由标签边缘路由器通过数据驱动或手动配置显式信令发起。
协议
标签分发协议
下游节点可以使用三种不兼容的协议来通知上游节点标签绑定:- 标签分发协议(LDP):专门为标签分发设计;
- 扩展边界网关协议(BGP):下游节点在BGP路由消息中包括一个新字段,用于通知上游节点选择的标签(仅适用于协议驱动标签绑定);
- 扩展资源预留协议(RSVP):下游节点在RSVP消息中包括一个新字段,用于通知上游节点选择的标签(用于质量服务)。
路由协议
传统的路由协议可以增强以支持流量工程,因为它们携带有关路由约束的信息。借助OSPF-TE和IS-IS-TE等路由协议(基于OSPF、IS-IS、BGP-4),每个节点可以收集网络拓扑信息,以便了解哪些节点是其上游节点,以便通知标签绑定。
有两种可能的路由策略:
- 逐跳路由(如IP路由中):分布式路由协议,每个LSR根据最短路径准则自行决定路由,因此可能所有路由器都选择同一路径 → 拥堵风险;
- 显式路由(支持基于约束的路由):集中式路由协议,出口LSR被通知哪些链路当前最为繁忙,并选择负载最小的链路以创建新的LSP,从而使路径尽可能不重叠。
为了支持显式路由,基本分配标签应扩展:
- **基于约束的路由LDP(CR-LDP)**是LDP的扩展;
- **RSVP流量工程(RSVP-TE)**是RSVP的扩展。
-
互联网协议版本6(IPv6)是一种旨在克服IPv4局限的新协议。引入这一协议的主要原因是提供相较于IPv4更大的地址空间。
IPv6与IPv4的比较
IPv6扩展了ICMP协议,集成了以下协议功能:
- ARP:在地址配置过程中称为“邻居发现”。
- IGMP:在管理组播组成员时称为“组播监听器发现”。
在IPv6中,一些协议需要升级,主要是因为这些协议涉及地址(这些协议并非与第3层无关):
- DNS协议;
- 路由协议:如RIP、OSPF、BGP、IDRP;
- 传输协议:如TCP、UDP;
- 套接字接口。
IPv6新增功能
以下新增功能最初被设计为IPv4的附加组件,后被移植并嵌入到IPv6中。
局域网部署效率
IPv6通过高效使用组播和任播地址提高了局域网的部署效率:
- 组播:每个组播地址标识一个节点组,数据包将转发到组内的所有节点。
- 任播:每个任播地址标识一个节点组,数据包仅转发到组中距离最近的节点。
数据安全与隐私
IPv6协议中内置了安全机制,例如IPsec。
策略路由
IPv6支持按不同策略转发数据包,而不仅仅依赖目的地址(例如,基于源地址转发)。
即插即用
IPv6定义了自动配置协议:
- 无状态:无需联系任何服务器,仅保证链路本地访问。
- 有状态:通过DHCP服务器可实现互联网访问。
流量区分
IPv6支持不同数据流的差异化处理(例如,电话通话需要更低的延迟)。
移动性
设备可在不同网络间移动,同时保持所有服务可用(例如,使用GSM/LTE的移动设备在不同小区间移动)。
游牧性
设备可在不同网络间移动,但无需确保服务保持活跃 → 相较于移动性要求更低。
更好的路由可扩展性
通常,为了简化路由需要进行地址聚合,但这会浪费地址空间。IPv6使用与IPv4几乎相同的路由技术,但如果地址分配高效,则可以减少路由表的大小。
地址
地址格式
每个IPv6地址为128位长,前缀替代了网络掩码:
前缀 接口标识符链路
IPv6中的链路概念与IPv4中的子网类似:
- 在IPv4中,子网是一组具有相同前缀的主机;
- 在IPv6中,链路是实际的物理网络。
同一链路上的所有主机都具有相同的前缀,因此可以直接通信;不同链路上的主机通过路由器通信。
地址空间组织
全球单播地址
聚合全球单播地址
等同于IPv4的公网地址,以三位“001”开头:3 16 48 64 88 96 104 128 001 ID TLA ID NLA ID SLA OUI ('universal' bit = 1) FF FE 制造商选择的MAC部分 前缀 接口标识符(EUI 64)- 前缀:必须与主机连接的链路分配的前缀一致。
- 分配准则:基于拓扑结构,根据服务提供商层级分配:
- TLA:顶级权威(大型服务提供商);
- NLA:下级权威(中间服务提供商);
- SLA:子网级权威(组织)。
- 接口标识符:标识主机接口。可选择采用EUI-64格式,即从主机的48位MAC地址派生的64位IPv6接口标识符。
IPv4互操作地址
过渡阶段使用,前80位为零:
- IPv4映射地址:前80位为零,接下来的16位为1:
0000 0000 0000 0000 0000 FFFF ... - IPv4兼容地址:前80位为零,接下来的16位为零(例如IPv6地址“::10.0.0.1”映射到IPv4地址“10.0.0.1”):
0000 0000 0000 0000 0000 0000 ...
本地单播地址
链路本地地址
这些是通过自动配置生成的“自动”私有地址,用于连接IPv6链路:FExx ...站点本地地址
等同于IPv4的私有地址:FDxx ...组播地址
组播地址标识一组站点,具有以下格式:
8 12 16 128 FF 标志 (000T) 范围 组ID互联网协议版本6(IPv6)是一种旨在克服IPv4局限的新协议。引入这一协议的主要原因是提供相较于IPv4更大的地址空间。
IPv6与IPv4的比较
IPv6扩展了ICMP协议,集成了以下协议功能:
- ARP:在地址配置过程中称为“邻居发现”。
- IGMP:在管理组播组成员时称为“组播监听器发现”。
在IPv6中,一些协议需要升级,主要是因为这些协议涉及地址(这些协议并非与第3层无关):
- DNS协议;
- 路由协议:如RIP、OSPF、BGP、IDRP;
- 传输协议:如TCP、UDP;
- 套接字接口。
IPv6新增功能
以下新增功能最初被设计为IPv4的附加组件,后被移植并嵌入到IPv6中。
局域网部署效率
IPv6通过高效使用组播和任播地址提高了局域网的部署效率:
- 组播:每个组播地址标识一个节点组,数据包将转发到组内的所有节点。
- 任播:每个任播地址标识一个节点组,数据包仅转发到组中距离最近的节点。
数据安全与隐私
IPv6协议中内置了安全机制,例如IPsec。
策略路由
IPv6支持按不同策略转发数据包,而不仅仅依赖目的地址(例如,基于源地址转发)。
即插即用
IPv6定义了自动配置协议:
- 无状态:无需联系任何服务器,仅保证链路本地访问。
- 有状态:通过DHCP服务器可实现互联网访问。
流量区分
IPv6支持不同数据流的差异化处理(例如,电话通话需要更低的延迟)。
移动性
设备可在不同网络间移动,同时保持所有服务可用(例如,使用GSM/LTE的移动设备在不同小区间移动)。
游牧性
设备可在不同网络间移动,但无需确保服务保持活跃 → 相较于移动性要求更低。
更好的路由可扩展性
通常,为了简化路由需要进行地址聚合,但这会浪费地址空间。IPv6使用与IPv4几乎相同的路由技术,但如果地址分配高效,则可以减少路由表的大小。
地址
地址格式
每个IPv6地址为128位长,前缀替代了网络掩码:
前缀 接口标识符链路
IPv6中的链路概念与IPv4中的子网类似:
- 在IPv4中,子网是一组具有相同前缀的主机;
- 在IPv6中,链路是实际的物理网络。
同一链路上的所有主机都具有相同的前缀,因此可以直接通信;不同链路上的主机通过路由器通信。
地址空间组织
全球单播地址
聚合全球单播地址
等同于IPv4的公网地址,以三位“001”开头:3 16 48 64 88 96 104 128 001 ID TLA ID NLA ID SLA OUI ('universal' bit = 1) FF FE 制造商选择的MAC部分 前缀 接口标识符(EUI 64)- 前缀:必须与主机连接的链路分配的前缀一致。
- 分配准则:基于拓扑结构,根据服务提供商层级分配:
- TLA:顶级权威(大型服务提供商);
- NLA:下级权威(中间服务提供商);
- SLA:子网级权威(组织)。
- 接口标识符:标识主机接口。可选择采用EUI-64格式,即从主机的48位MAC地址派生的64位IPv6接口标识符。
IPv4互操作地址
过渡阶段使用,前80位为零:
- IPv4映射地址:前80位为零,接下来的16位为1:
0000 0000 0000 0000 0000 FFFF ... - IPv4兼容地址:前80位为零,接下来的16位为零(例如IPv6地址“::10.0.0.1”映射到IPv4地址“10.0.0.1”):
0000 0000 0000 0000 0000 0000 ...
本地单播地址
链路本地地址
这些是通过自动配置生成的“自动”私有地址,用于连接IPv6链路:FExx ...站点本地地址
等同于IPv4的私有地址:FDxx ...组播地址
组播地址标识一组站点,具有以下格式:
8 12 16 128 FF 标志 (000T) 范围 组ID以下是字段的含义:
组播地址字段
-
标志字段(Flag field,4位):
- 用于标记组播组的类型:
- T = 1:临时组播组(例如用户定义的电话会议组)。
- T = 0:永久组播组(例如网络中所有主机的地址,无法被覆盖)。
- 用于标记组播组的类型:
-
范围字段(Scope field,4位):
- 用于限制组播的传播范围(比IPv4的TTL更优):
- 1 = 节点本地:数据包无法离开主机。
- 2 = 链路本地:数据包无法离开第2层网络。
- 5 = 站点本地:数据包无法离开,例如校园网络。
- 8 = 组织本地:数据包无法离开组织网络。
- E = 全球:数据包可到达任何地方。
- 用于限制组播的传播范围(比IPv4的TTL更优):
-
组ID字段(Group ID field,112位):
- 标识组播组,数据包将转发到组内所有节点。
如果主机想加入组播组,需要通过ICMP协议请求加入。一旦加入组播组,该主机将接收发送到该组播地址的所有数据包。需要注意的是,接收组播数据包的主机并非由发送方决定,而是由目标端决定。
请求节点组播地址
每个活动节点默认属于一个请求节点组播组,其地址派生自该节点的IPv6地址:
96 104 128 FF02::1 FF IPv6地址的后24位同一组播组中可能有多个主机,但通常不会,因为组播地址由IPv6地址生成。
将IPv6映射到以太网
每个组播数据包通过一个带特定MAC地址的以太网帧传输,该MAC地址从IPv6组播地址派生,从而确保只有相关主机处理数据包:
16 48 3333 IPv6目标地址的后32位
IPv6地址的高级主题
重新编号
由于全球地址的前缀是根据服务提供商的层级分配的,如果公司希望更换服务提供商,公司网络中的所有链路前缀都需要更改。IPv6支持对主机和路由器进行简单的重新编号:
- 主机:路由器逐步停止广播旧前缀(弃用),开始广播新前缀(首选) → 在迁移阶段,每个主机将为同一接口拥有两个带不同前缀的地址。
- 路由器:路由器重新编号是一个标准,允许边界路由器通知内部其他路由器新前缀。
然而,重新编号仍有一些未解决的问题,例如如何自动更新DNS条目、防火墙过滤器、基于地址的企业策略等。
多宿主(Multi-homing)
一家大公司可能选择从两个不同的服务提供商购买互联网连接,以确保即使一个服务提供商出现问题,也能保持连接。
由于全球地址的前缀是根据服务提供商层级分配的,公司网络内的每个主机将为同一接口拥有两个带不同前缀的全球地址 → 主机需要为每个出站数据包选择正确的地址。这可能导致一些非平凡的配置问题:
- 基于目的地址的路由:主机应选择正确的前缀,否则如果主机选择了提供商A的前缀,而目标在提供商B的网络中 → 边界路由器将数据包直接转发到提供商B的网络 → 提供商B可能会阻止该数据包,因为源地址前缀不同。
- DNS中的双重注册:主机需要以两个不同地址为同一别名在DNS中注册。
- 自动重新编号:重新编号机制应动态支持从提供商B切换到提供商C。
作用域地址
主机可能有两个接口(例如以太网接口和Wi-Fi接口),可以同时连接到两个不同的链路。当主机想向链路本地目标地址发送数据包时,它不知道是通过接口A还是接口B发送,因为两个链路的前缀相同;此外,由于每个链路本地地址在其链路中是唯一的,链路A中的主机可能与链路B中的另一主机拥有相同的链路本地地址。
在IPv6中,主机需要在目标IPv6地址中指定一个称为**作用域(scope)**的标识符,用于标识物理接口(例如
FE80::0237:00FF:FE02:A7FD%19)。作用域值由操作系统根据其内部标准选择。
标准IPv6头部
标准IPv6头部具有以下固定大小(40字节)的格式:
4 12 16 24 32 版本(6) 优先级 流标签 有效负载长度 下一头部 跳数限制 源地址 目标地址关键字段
- 版本字段(4位):通常不使用,因为数据包的区分由第2层完成 → 支持双栈模式。
- 优先级字段(8位):等同于IPv4的“服务类型”字段,用于区分不同服务。
- 流标签字段(20位):用于区分不同的流,以支持服务质量(QoS)。
- 下一头部字段(8位):指向数据包的有效负载,即上层协议(如TCP/UDP)或扩展头部链中的第一个扩展头部。
- 跳数限制字段(8位):等同于IPv4的“生存时间(TTL)”字段。
- 源地址字段(128位):包含数据包的发送方IPv6源地址。
- 目标地址字段(128位):包含数据包的接收方IPv6目标地址。
移除的IPv4字段
- 校验和字段:错误保护由第2层(帧校验序列)完成。
- 分片字段:分片功能被移至“分片”扩展头部。
- 头部长度字段:IPv6头部固定大小,其他功能通过扩展头部可选提供。
扩展头部
IPv6包含六种扩展头部,仅在需要时添加,并按以下顺序处理:
- 逐跳选项头部(Hop by hop option):包含每一跳都需要处理的可选信息。
- 路由头部(Routing):启用源路由,允许发送方决定数据包的路径。
- 分片头部(Fragment):管理数据包分片。
- 认证头部(Authentication Header,AH):用于验证发送方身份。
- 封装安全负载头部(Encapsulating Security Payload,ESP):用于加密数据包内容。
- 目标选项头部(Destination option):包含仅由目标节点处理的可选信息。
路由器始终仅处理到“路由”扩展头部为止的部分。
所有扩展头部都有相同的通用格式(长度必须是64位的倍数):
8 16 32 Next Header Header Length Extension data :::- Next Header字段:指定链中下一个扩展头部,或如果这是最后一个扩展头部,则为上层头部(如TCP/UDP)。
- Header Length字段:指定当前扩展头部的长度。
新扩展头部可能会随着时间标准化,旧设备可能无法处理这些新头部,但可以通过“Header Length”字段跳过未知扩展头部。某些扩展头部(如“分片”扩展头部)具有固定长度,不包含“Header Length”字段。
逐跳选项与目标选项
逐跳选项头部和目标选项头部可以包含多个附加选项:
- 逐跳选项:包含每个路由器必须处理的选项。
- 目标选项:包含仅由目标处理的选项。
例如,包含两个8位长值的扩展头部格式如下:
8 16 24 32 Next Header Header Length Type1 Length Value1 Type2 Length2 Value2每个选项包含以下字段:
- Length字段(8位):指定当前选项的长度,以便路由器在无法识别该选项时可跳过。
- Type字段(8位):标识当前选项:
- 前两位指定当选项无法识别时的执行操作:
00:忽略当前选项并继续下一个选项。01:丢弃数据包。10:丢弃数据包并生成ICMPv6参数问题消息。11:若目标地址为组播,则不生成ICMP消息,否则丢弃数据包并生成ICMP消息。
- 第三位指定选项是否可动态更改:
0:选项不可更改。1:选项可动态更改。
- 前两位指定当选项无法识别时的执行操作:
- Value字段(可变长度):包含选项的具体值。
路由头部
路由头部允许发送方指定数据包的路径(源路由),格式如下:
8 16 24 32 Next Header Header Length Routing Type Segment Left (reserved) Router Address 1 ... Router Address N字段说明:
- Routing Type字段(8位):指定路由类型(目前“0”表示传统源路由)。
- Segment Left字段(8位):指定到目标的剩余跳数。
- Router Address字段(128位每个):列出数据包需要经过的路由器的IPv6地址。
示例:
源S发送到目标D的数据包包含路由头部,强制数据包依次经过路由器R1和R2。初始时数据包的目标地址为R1,但实际目标地址D在路由头部中指定。当数据包到达R1时,R1识别该包的目标地址为自身,但发现路由头部中的目标是另一节点。R1根据路由头部将下一跳地址替换为R2并转发,直到D接收到“Segment Left”为0的数据包,表示包已到达最终目标。目标D通过路由头部记录的路径列表反向发送回复数据包。
分片头部
分片头部用于将数据包分为较小的片段,格式如下:
8 16 29 31 32 Next Header (reserved) Fragment Offset (reserved) M Identification字段说明:
- Fragment Offset字段(13位):指定片段在原始数据包中的起始字节编号。
- 更多片段标志(M,1位):如果为0,表示当前数据包是最后一个片段。
- 标识字段(Identification,32位):所有片段共享相同的标识符。
每个数据包分为两部分:
- 不可分片部分:包括IPv6头部及“分片”头部之前的所有扩展头部,在所有片段中重复。
- 可分片部分:包括“分片”头部之后的扩展头部和数据包负载。
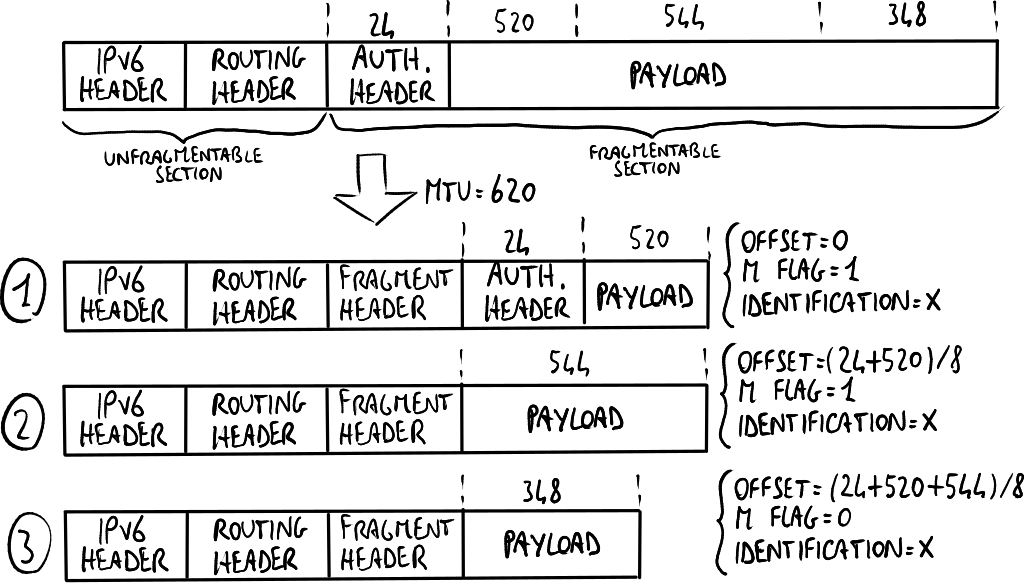
示例:
与IPv4不同,IPv6仅允许发送方分片,路由器不支持分片。为了提高性能,IPv6建议使用路径MTU发现代替分片。
IPsec扩展
IPv6中的IPsec是集成的协议套件,包括两种头部:
- 认证头部(AH):验证数据包完整性,但不包含传输过程中改变的字段(如“Hop Limit”字段)。
- 封装安全负载头部(ESP):验证并加密数据包负载,保护数据隐私。
安全关联(SA)
IPsec不定义具体的加密和认证算法,通信双方需协商使用的算法 → 灵活性:可根据需求选择算法。
SA是双方就密钥和算法达成的协议,由安全参数索引(SPI)标识,SPI包含于AH和ESP头部中。SA是单向逻辑通道,双向通信需要两条SA。密钥交换(IKE协议)
用于安全协商密钥的主要策略:
- 静态配置:手动配置密钥,无需协商。
- Diffie-Hellman方法:无需传输密钥即可协商。
- 互联网密钥交换(IKE)协议:使用数字证书和非对称加密以安全方式传递密钥。
IKE协议通过以下过程建立安全关联:
- 使用证书验证通信双方身份;
- 使用非对称加密交换密钥;
- 定期通过ISAKMP协议重新协商密钥,以防止第三方通过暴力破解或统计分析获取密钥。
IPsec
IPv6 的 IPsec 协议套件从 IPv4 的 IPsec 套件中移植而来。在 IPv6 中,IPsec 是一个集成协议套件,定义了以下两种头部:
- 认证头部(Authentication Header, AH):验证整个数据包的完整性,但不包括传输过程中发生变化的字段(例如“跳数限制”字段),以保证数据包内容未被篡改。
- 封装安全负载头部(Encapsulating Security Payload, ESP):对数据包的有效负载进行验证和加密,以保护数据隐私。
安全关联(SA)
IPsec 并未定义用于加密和认证的具体算法,通信双方需要协商要使用的算法以交换受 IPsec 保护的信息 → 灵活性:算法根据需求选择。
安全关联(SA) 是双方之间关于 ESP 和 AH 所使用的私钥和算法的协议集合。
- 标识:每个 SA 由一个安全参数索引(SPI)标识,SPI 包含在 AH 和 ESP 头部中。
- 单向逻辑通道:通信双方 A 和 B 必须分别为从 A 到 B 和从 B 到 A 的消息建立单独的 SA。通常每个 TCP 端口会有一个单独的 SA。
互联网密钥交换(IKE)协议
为了安全协商密钥,避免第三方获取,有以下三种主要策略:
- 静态配置:手动在双方配置密钥,无需协商。
- Diffie-Hellman 方法:无需传输密钥即可协商密钥,第三方无法通过监听获取密钥。
- IKE 协议:利用数字证书和非对称加密,以安全方式传递密钥。
IKE 协议过程:
- IKE 协议要求双方为从 A 到 B 和从 B 到 A 的子 SA 协商密钥。
- 从 A 到 B 的 IKE SA 的建立过程:
- B 向 A 请求用于子 SA 的密钥;
- A 向可信的认证机构请求 B 的数字证书以验证其身份;
- 认证机构将 B 的数字证书返回给 A,该证书由认证机构的私钥加密,并包含 B 的签名(B 与其公钥的关联);
- A 使用认证机构的公钥解密证书,并获取与 B 关联的公钥;
- A 将子 SA 的密钥发送给 B,使用 B 的公钥加密,确保仅 B 能解密;
- B 接收消息,用其私钥解密并获取密钥;
- 子 SA 通过协商的密钥从 A 到 B 建立。
ISAKMP:
为了防止第三方通过暴力破解或统计分析获取密钥,互联网安全关联密钥管理协议(ISAKMP) 是 IKE 的一个子协议,用于定期安全地重新协商密钥。
认证头部(AH)
认证头部为 IP 数据包提供无连接完整性和数据源身份验证,确保数据包内容未被篡改。
限制:AH 还会验证地址和端口,因此在 NAT 环境中会遇到问题。- 核心概念:任何人都可以读取数据包内容,但无法更改内容。
认证头部格式:
8 16 32 Next Header Payload Length (reserved) SPI Sequence Number Authentication Data :::字段说明:
- Next Header 字段(8 位):指定下一个封装的协议。
- Payload Length 字段(8 位):指定认证头部的长度(以 32 位字为单位,减去 2);可清零。
- 安全参数索引(SPI,32 位):标识数据包对应的安全关联(如果清零,表示无安全关联;1 到 255 的值为保留值)。
- 序列号字段(Sequence Number,32 位):包含递增的计数值。
- 消息摘要字段(可变长度):通过使用私钥计算数据包内容的摘要。如果有人想更改数据包内容,必须知道该私钥才能重新计算消息摘要。
特点:消息摘要类似于错误检测字段,确保数据包内容的完整性和来源的真实性。
封装安全负载(ESP)
ESP头部为IP数据包提供来源真实性、完整性和机密性保护:通过验证和加密数据包的有效负载来保护数据隐私。
尽管ESP可以进行认证,但其功能不同于AH:ESP并不认证整个IPv6数据包。
核心概念:任何人都无法读取数据包内容,因此也无法篡改内容。
ESP头部始终是头部链中的最后一个,格式如下:
16 24 32 SPI Sequence Number Payload Data ::: Padding ::: Padding Length Next Header Authentication Data :::字段说明:
- 安全参数索引(SPI,32位):标识数据包对应的安全关联(SA)。
- 序列号字段(Sequence Number,无符号32位):包含递增的计数值,即使接收方未启用反重放服务,此字段对发送方也是必需的。
- 有效负载数据字段(Payload Data,可变长度):包含由
Next Header字段描述的数据。 - 填充字段(Padding,可变长度0到255位):用于确保加密数据以4字节对齐。
- 填充长度字段(Padding Length,8位):指定填充字段的大小(以字节为单位)。
- 下一个头部字段(Next Header,8位):描述
Payload Data字段格式的协议号(IPv4/IPv6)。 - 认证数据字段(Authentication Data,可变长度):包含完整性校验值(ICV),用于验证ESP包的内容(不包括
Authentication Data字段本身)。
认证算法的规范决定了
Authentication Data字段的长度,以及用于验证的比较规则和处理步骤。注意:Authentication Data字段未加密。ESP支持两种使用模式,可选择与AH结合使用:
- 传输模式(Transport Mode):ESP不加密IPv6头部 → 中间节点可以看到IPv6头部中的源和目标地址。
IPv6 Header 其他扩展头部 ESP头部(加密部分) TCP/UDP头部 有效负载 ESP认证 加密数据 认证数据 - 隧道模式(Tunnel Mode):IPv6数据包被封装到另一个包含ESP的IPv6数据包中 → 原始数据包的IPv6头部(包括源和目标地址)被加密,外界无法看到。
IPv6 Header ESP头部(加密部分) IPv6 Header 其他扩展头部 TCP/UDP头部 有效负载 ESP认证 加密数据 认证数据
ICMPv6
**互联网控制消息协议版本6(ICMPv6)**是IPv6标准的组成部分,集成了ARP和IGMP协议的功能并进行了扩展。
所有ICMPv6消息都位于数据包的扩展头部之后,具有以下通用格式:
8 16 32 Type Code Checksum Message Body :::字段说明:
- Type字段:标识ICMPv6消息类型。
ICMPv6消息类型示例:
- 诊断消息(类似ICMPv4,用于报告网络错误或问题):
1:目标不可达(Destination Unreachable)2:数据包过大(Packet Too Big)3:超时(Time Exceeded)4:参数问题(Parameter Problem)
- Ping命令使用的消息:
128:回显请求(Echo Request)129:回显回复(Echo Reply)
- **组播监听器发现(Multicast Listener Discovery,扩展IGMP功能):
130:组播监听器查询(Multicast Listener Query)131:组播监听器报告(Multicast Listener Report)132:组播监听器完成(Multicast Listener Done)
- **邻居发现(Neighbor Discovery,扩展ARP功能):
133:路由器请求(Router Solicitation)134:路由器通告(Router Advertisement)135:邻居请求(Neighbor Solicitation)136:邻居通告(Neighbor Advertisement)137:重定向(Redirect)
数据包过大(Packet Too Big)
当路由器接收到一个过大的数据包时,它会执行一种称为**路径MTU发现(Path MTU Discovery)**的技术。路由器会丢弃该数据包,并返回一个ICMPv6消息,类型为“Packet Too Big”(数据包过大),通知发送方允许的最大传输单元(MTU)大小。发送方据此调整数据包大小,使其不超过路由器指定的MTU。这种技术的目标是尽量避免数据包分片。
组播监听器发现(Multicast Listener Discovery)
组播监听器发现是ICMPv6的一个组件,扩展了IPv4 IGMP协议的功能,用于管理组播组的成员关系:
- 组播监听器查询(Multicast Listener Query):
- 常规查询(General Query):路由器询问主机是否有兴趣加入某些组播组。
- 特定组播地址查询(Multicast Address Specific Query):路由器询问主机是否有兴趣加入特定组播组。
- 组播监听器报告(Multicast Listener Report):主机通知路由器,它希望加入一个特定组播组,以接收发送到该组播地址的所有组播数据包。
- 组播监听器完成(Multicast Listener Done):主机通知路由器,它希望停止接收来自特定组播组的组播数据包。
邻居发现(Neighbor Discovery)
邻居发现是ICMPv6的一个组件,扩展了IPv4 ARP协议的功能,包括以下功能:
- 邻居请求(Neighbor Solicitation):主机发送一个多播数据包,目标IPv6地址为目标设备的请求节点组播地址,以获取其MAC地址。
- 邻居通告(Neighbor Advertisement):拥有指定IPv6地址的主机返回其MAC地址。
- 路由器请求(Router Solicitation):主机发送一个多播数据包,请求路由器返回包含网络信息(如链路前缀、自配置/DHCP标志、默认网关等)的“路由器通告”消息。
- 路由器通告(Router Advertisement):路由器广播其存在信息,包括链路相关的前缀及主机是否应自配置或查询DHCP服务器的标志。
这些ICMPv6消息支持主机的IPv6地址自动配置过程。
链路本地地址自动配置
链路本地地址的自动配置依赖于“邻居请求”和“邻居通告”ICMPv6消息:
- 主机生成候选链路本地地址:
- 前缀:始终为
FE80::。 - 接口标识符:基于MAC地址(EUI-64格式)或随机生成(增强隐私)。
- 前缀:始终为
- 主机通过多播发送“邻居请求”消息,目标为候选地址对应的请求节点组播地址,询问是否有其他主机已经占用了该地址(重复地址检测)。
- 如果链路中已存在该地址的主机,会返回“邻居通告”消息,主机需随机生成另一个候选地址并重新检测。
- 如果无人回复,该地址在链路中唯一,主机即可通过链路本地地址与其他主机通信,但尚无法访问互联网,因为仍需获取一个全局地址。
全局地址自动配置
全局地址的自动配置依赖以下ICMPv6消息:“路由器请求”、“路由器通告”、“邻居请求”和“邻居通告”:
- 主机通过多播发送“路由器请求”消息,路由器返回“路由器通告”消息,包含以下标志:
- M标志(托管地址配置):
M = 1:主机需联系DHCP服务器获取链路前缀及其他网络配置参数(如DNS地址),忽略路由器通告消息(有状态配置)。M = 0:主机需查看O标志:- O = 1:主机可从路由器通告中获取链路前缀,但需联系DHCP服务器获取其他网络配置参数。
- O = 0:主机可从路由器通告中获取链路前缀,无需其他网络配置信息(无状态配置)。
- M标志(托管地址配置):
- 主机生成候选全局地址:
- 前缀:从路由器通告消息或DHCP服务器中获取。
- 接口标识符:基于MAC地址(EUI-64格式)或随机生成(增强隐私)。
- 主机通过多播发送“邻居请求”消息,检查候选地址是否被占用。
- 如果地址未被占用,主机即完成全局地址配置,可通过全局地址访问互联网。
其他实现方式
微软曾提出一种主机无需知道DNS服务器地址即可联系的实现方案:主机发送数据包到固定的任播地址,网络负责将其转发到DNS服务器。然而,该方案实际应用较少,原因包括:
- 对任播地址管理的实现较少;
- GNU/Linux系统不支持该方案。
由于自动配置依赖于MAC地址,若网络卡损坏且需更换,主机地址需更改,而缓存(如DNS缓存)无法立即更新。因此,静态配置仍然适用于需要固定地址的设备(如公共服务器),以确保持续可访问性。
-
引言
在迁移阶段,主机应逐步具备访问IPv6目标地址的能力,同时保持对IPv4目标地址的访问能力。迁移所有网络设备是必要但不充分的条件:用户需要为整个网络制定一个新的地址规划以实现IPv4与IPv6的协同工作。
主机迁移
应用程序迁移
将IPv6支持引入应用程序需要修改源代码:
- 服务器端:服务器上的运行进程应开启两个线程,一个监听IPv4套接字,另一个监听IPv6套接字,以同时支持IPv4和IPv6请求。
- 客户端:例如,浏览器等应用程序应能够正确输入和输出IPv6格式的地址。
操作系统迁移
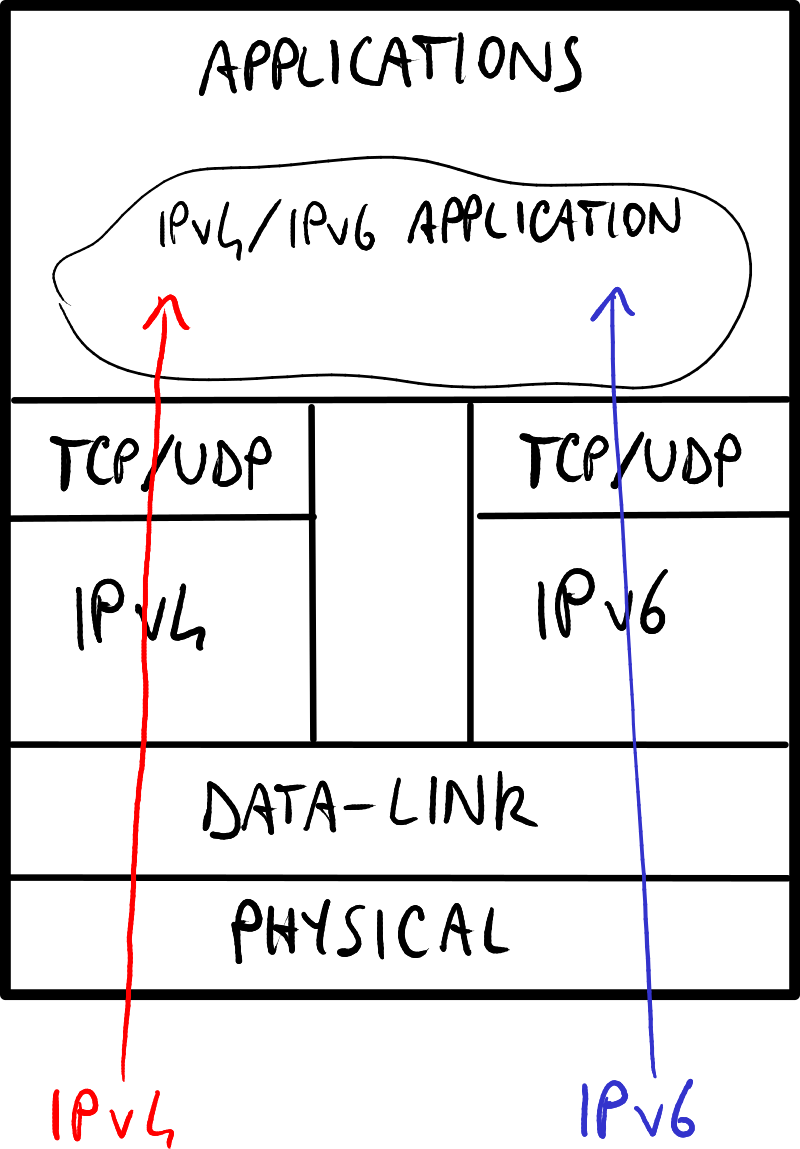
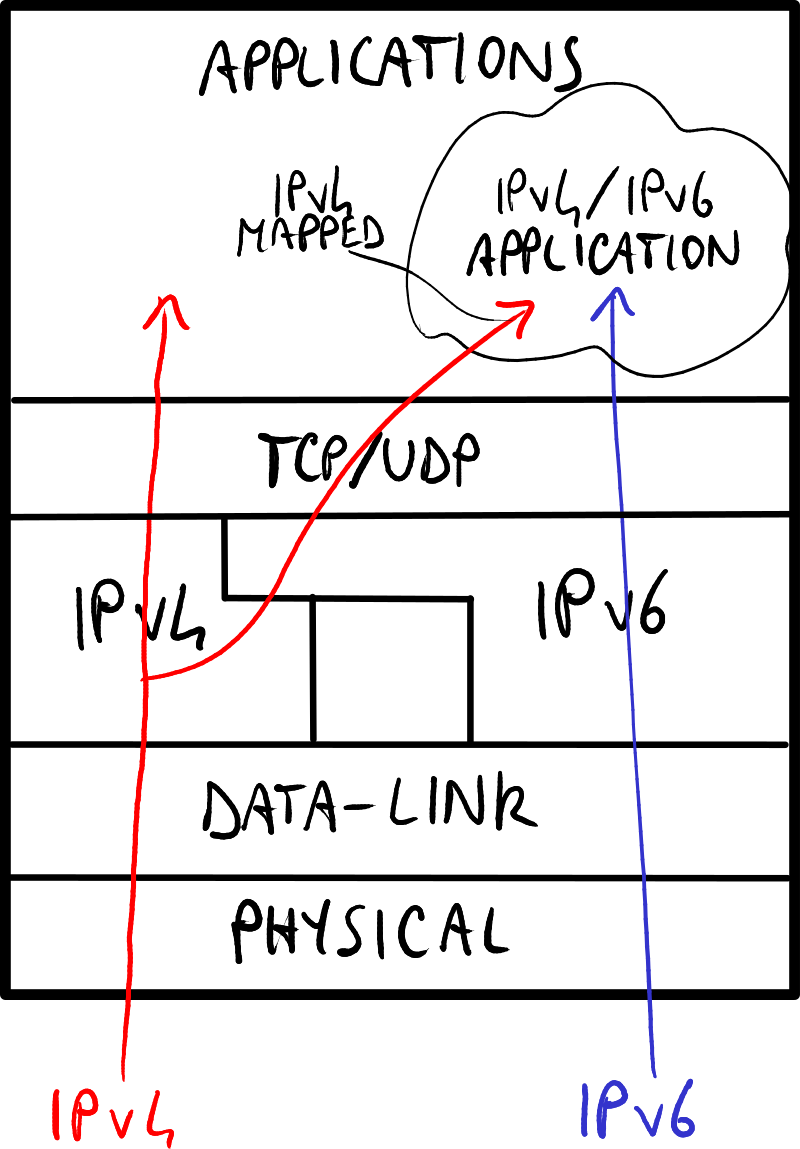
操作系统通过采用双栈(Dual Stack)方法支持IPv6:
- 无双层模式:操作系统独立处理IPv4和IPv6地址 → 软件需要同时支持IPv4和IPv6地址。
- 双层模式:操作系统能够将IPv4地址转换为IPv4映射的IPv6地址 → 软件只需支持IPv6地址,无需关心IPv4地址。
双层模式使用最为广泛,因为它将复杂性转移到了操作系统核心。
网络设备迁移
交换机迁移
理论上,交换机仅工作在第2层,因此不受第3层协议变化的影响。但某些附加功能可能带来问题,例如IGMP嗅探(用于过滤传入的组播数据包)。由于数据包格式和字段变化,交换机可能无法识别IPv6组播数据包并丢弃它们。
路由器迁移
当代路由器大多已支持IPv6,但由于经验不足及IPv6流量需求较低,IPv6性能通常仍逊于IPv4。
典型的支持IPv6的路由器采用类似“夜间船只(ships in the night)”的双栈方法:IPv4和IPv6由两个独立的传输层栈支持 → 这需要完全复制所有组件,包括路由协议、路由表、访问列表等。
-
路由表:
- IPv6路由与IPv4路由方式相同,但需要两张独立的路由表。
- IPv6路由表可存储以下几种条目:
- 间接条目(O/S代码):指定下一跳路由器的接口地址(通常为链路本地地址)。
- 直接条目:指定路由器自身的接口,用于发送到本地链路的包:
- 连接的网络(C代码):指定本地链路的前缀。
- 接口地址(L代码):指定本地链路中的接口标识符。
-
路由协议:
- 支持IPv6的路由协议可以采用两种方法:
- 集成路由(例如BGP):允许同时交换IPv4和IPv6的路由信息 → 效率更高。
- 夜间船只模式(例如RIP、OSPF):协议仅交换IPv6路由信息 → 灵活性更高,可以分别使用不同协议处理IPv4和IPv6路由信息。
- 支持IPv6的路由协议可以采用两种方法:
DNS迁移
支持IPv6的DNS可以将两个IP地址映射到同一个别名:一个IPv4地址和一个IPv6地址 → 公共目标既可通过IPv4也可通过IPv6访问。
- 支持IPv6的DNS不仅可通过IPv6返回IPv6地址,也可通过IPv4返回 → 因为DNS消息属于应用层,转发DNS查询和回复所用的传输层协议并不重要。
- 执行DNSv6查询的命令为:
set q=aaaa。
例如,一家公司可能希望通过IPv6为其公共网站提供访问服务。然而,由于当前大部分流量通过IPv4传输,IPv4服务在性能和容错性方面通常比IPv6服务更可靠。为了避免用户因IPv6性能问题转而选择竞争对手的网站,公司可以采取以下措施:
- 进行预评估,测试用户与公司服务器之间的连接性能。
- 在DNS中实现附加机制:DNS应能够查看查询的源地址。
- 如果尚未进行连接性能评估,仅返回IPv4地址;
- 如果连接性能良好,则同时返回IPv4和IPv6地址。
隧道解决方案
网络在零日时并不会完全支持IPv6 → IPv6流量可能需要通过仅支持IPv4的网络部分。面向网络的隧道解决方案使得即使IPv6网络通过仅支持IPv4的基础设施连接,也能够实现IPv6网络之间的互通,其原理是将IPv6数据包封装在IPv4头中,仅用于通过隧道传输:
隧道数据包的大小(包括20字节的IPv4头)不能超过IPv4数据包的最大大小 → 有两种可能的解决方案:
- 分段:路由器在将IPv4数据包发送到隧道之前对其进行分段 → 由于性能原因,分段已不推荐使用;
- 较小的IPv6数据包:主机应生成具有较小MTU大小的IPv6数据包,以考虑到IPv4头插入的额外大小 → 路由器可以通过“路由器广告”ICMPv6消息指定允许的MTU大小。
面向主机的隧道解决方案
面向主机的隧道解决方案对于主机来说更为即插即用,但它们不是专业的解决方案,并且不能解决IPv4地址短缺的问题,因为每个主机仍然需要拥有一个IPv4地址。此类解决方案包括:
- 使用IPv6 IPv4兼容地址,隧道终结点在主机或路由器;
- 6over4;
- ISATAP。
使用IPv6 IPv4兼容地址
这些解决方案假定双栈主机在需要联系IPv4目标时,将IPv6数据包发送到IPv4兼容的IPv6地址,该地址的前96个高位为零,剩余32个低位与目标IPv4地址一致。然后,IPv6数据包被封装在IPv4数据包中,IPv4数据包的目标地址取决于你希望隧道终结在哪个位置:
- 端到端终结:双栈主机上的伪接口执行封装,将IPv6数据包封装为目标主机的IPv4数据包;
- 路由器双栈终结:主机上的伪接口将目标主机的IPv6数据包发送到双栈路由器的IPv4地址:
- 为目标生成IPv6 IPv4兼容地址,如前所述;
- IPv6数据包封装为指向双栈路由器的IPv4数据包;
- 双栈路由器解封装数据包并将其发送到目标主机。
6over4
这个方法的思想是通过IPv4模拟一个支持组播的本地网络。实际上,像通过以太网连接两个IPv6主机一样,邻居发现被用来利用以太网的广播机制;在这个解决方案中,我们把IPv4当作低层协议,并改变邻居发现来查找IPv4地址,而不是MAC地址。这个方法可以推广到连接IPv6网络的云(而非单独的主机)的情况,通过双栈路由器在IPv4网络中进行通信。在这种情况下,除了邻居发现之外,还可以使用修改版的路由器发现协议,通过发送路由器请求来发现连接到主机IPv4网络的路由器IPv4地址,这些路由器允许访问不同的IPv6网络;实际上,主机可以通过路由器广告获取有关可访问IPv6网络的信息。
这个方法的一个问题是IPv4组播的使用,在不同提供商的网络中,IPv4组播通常是禁用的。该解决方案适用于当你完全控制一个网络时:因此,它无法用于将全球网络从IPv4迁移到IPv6。
6over4 邻居发现
根据RFC的提案,IPv6地址与IPv4地址进行映射:实际上,IPv4地址作为目标IPv6地址的接口标识符使用。这样,所展示的机制就变得不再必要,因为主机可以直接进行隧道通信,无需邻居发现来查找IPv4地址。当然,当IPv6地址不是从IPv4地址构建时,这个方法就不适用,因此仍然需要一个更通用的机制来联系路由器。因此,假设我们只知道一个IPv6地址,邻居发现将会发送到请求节点的组播地址(例如,如果IPv6地址是
fe80::101:101,那么它会发送到ff02::1:ff01:101),该地址位于IPv4的6over4组播网络,地址为239.192.x.y,其中最后16位由IPv6地址的最后16位组成(因此在上述示例中,将为239.192.1.1)。ISATAP
ISATAP的思想类似于6over4,即使用IPv4网络作为物理链路来到达IPv6目标,但我们希望克服对组播支持的要求。在没有邻居发现机制的情况下,使用ISATAP的目标IPv4地址会嵌入到IPv6地址中,具体地,嵌入到接口标识符中,其格式为
0000:5efe:x:y,其中x和y是IPv4地址的32位。可以看出,这个解决方案并没有解决IPv6引入的根本问题——IPv4地址的稀缺性。然而,在IPv4链路连接非主机(而是具有IPv6云的边界路由器)的场景中,这个解决方案更为有用。在这种情况下,IPv4网络中的主机如果想要与属于某个云的主机通过IPv6通信,就必须配备潜在路由器列表(PRL)。此时会出现以下问题:-
如何获取PRL? 目前有两种解决方案:一种是专有的,基于使用DHCP;另一种是标准的,基于使用DNS。在后者中,可以通过DNS查询特定的名称格式
isatap.dominio.it来提供连接到IPv4网络的IPv6路由器的PRL。 -
应将数据包发送到哪个路由器以到达IPv6目标? 对PRL中的每个路由器使用单播路由器发现协议,以通过路由器广告获取回应。实际上,在路由器广告中,路由器还可以宣布可通过它们到达的IPv6网络列表(参见ICMP路由器广告中的Prefix Information Option中的L=0标志)。
面向网络的隧道解决方案
通常,面向网络的隧道解决方案需要手动配置,且封装可以基于IPv6在IPv4中的封装(协议类型 = 41)、GRE、IPsec等。
6to4
与先前的解决方案相比,6to4的最大进步在于新的场景中不再是单个主机需要一个IPv4地址来从IPv6云中出去,而是一个完整的IPv6网络需要一个IPv4地址来与外界通信。两个地址之间的映射会发生在IPv6前缀中,而不是接口标识符中:一个特殊的前缀被分配给所有IPv6网络,包含指向双栈路由器接口的IPv4地址,双栈路由器面对的是该云。前缀
2002::/16用于标识使用6to4的IPv6主机:在接下来的32位中设置IPv4地址,剩下的16位用于表示多个子网,而接口标识符则像其他IPv6使用场景一样生成。在这个解决方案中,还有一个具有特定作用的路由器——6to4转发路由器,它必须是6to4路由器的默认网关,用来将非6to4格式的数据包转发到全球IPv6网络。该路由器的地址是192.88.99.1,这是一个任何播送地址:6to4的设计者认为这种方式很有用,因为它使得在同一网络中存在多个6to4转发路由器时不会遇到地址冲突的问题。实际例子
假设有两个IPv6云连接到一个IPv4云,且双栈路由器的接口分别为连接到IPv6云A和云B的地址
192.1.2.3和9.254.2.252。假设网络A中的主机a想要发送一个数据包给网络B中的主机b。根据上述配置可以看出,网络A中的主机将使用2002:c001:02:03/48地址,而网络B中的主机使用2002:09fe:02fc::/48地址。从a到b的IPv6数据包将被封装在一个IPv4数据包中,目标地址为9.254.2.252,该地址来自目标IPv6地址的前缀。数据包到达该路由器时,将会被解封装并根据网络B的IPv6地址计划进行转发。Teredo
Teredo与6to4非常相似,唯一不同的是封装是在一个包含在IPv4数据包中的UDP段内进行的,而不是简单地封装在IPv4中。这是为了克服6to4的一个局限性,即穿越NAT的问题:由于6to4的IPv4数据包中没有两级封装,NAT无法正常工作。
隧道代理
6to4解决方案的问题在于它不够通用:你被绑定在使用
2002::/16前缀,并且无法使用常规的全球单播地址。在隧道代理解决方案中,由于无法从IPv6前缀推断出数据包应发送到哪个端点,因此使用一个服务器,该服务器根据给定的IPv6地址提供要联系的端点隧道地址。实现隧道代理的路由器称为隧道服务器,而提供映射的服务器称为隧道代理服务器。隧道与6to4相同,即IPv6封装在IPv4中:如果穿越NAT是一个问题,你还可以使用Teredo的方式,通过UDP进行封装,再封装在IPv4中。隧道代理服务器需要进行配置:隧道信息控制(TIC)用于转发有关给定隧道服务器可达网络的信息,从配置的隧道服务器到隧道代理服务器。而隧道设置协议(TSP)则用于向隧道代理服务器请求信息。同样,你可以为全球IPv6网络提供默认网关。总结来说,配置了这个方案的路由器,当一个数据包到达时,可以:
- 如果数据包与路由表中的条目匹配,直接转发(经典情况);
- 向隧道代理服务器询问是否需要对该地址进行隧道封装;
- 如果隧道代理服务器的响应是否定的,则将数据包发送到全球IPv6默认网关。
问题
这是一个集中式解决方案,因此隧道代理服务器是单点故障的来源。 它使控制计划变得复杂。 如果这个服务器被用于互联不同的网络,即使它们属于不同的提供商,也会引发管理责任的问题。
优势
它比6to4更灵活,因为它允许使用所有的全球单播地址。
将IPv6支持引入网络边缘
基于NAT的解决方案
主要基于NAT的解决方案
目标是迁移大型提供商的网络,使得在网络边缘的IPv4和/或IPv6云能够使用IPv6骨干网进行互操作。常见的场景是用户希望通过提供商的IPv6网络连接到IPv4目的地。
所有可用的选项都利用了NAT。NAT的使用有些逆流而行,因为IPv6的目标之一就是避免在网络中使用NAT,因其带来了许多问题(例如,数据包在传输中发生变化、对等网络问题等)。然而,基于NAT的解决方案存在多种优势:NAT已经广泛应用于网络,其问题和限制已知,应用程序的NAT穿透问题也已被了解。因此,普遍的优势在于迄今为止积累的大量经验。
主要组成部分
在基于NAT的解决方案中,有三个主要组件:
- 客户边缘设备(CPE):这是位于客户边缘、位于提供商网络之前的路由器。
- 地址族转换路由器(AFTR):它是IPv6隧道集中器,即隧道末端的设备。
- NAT44/NAT64:它是一种NAT,用于将IPv4/IPv6地址转换为IPv4地址。
主要基于NAT的解决方案
- NAT64
- 双栈精简(DS-Lite):NAT44 + 4-over-6隧道
- 双栈精简地址+端口(DS-Lite A+P):预配置端口范围的DS-Lite
- NAT444:CGN + CPE NAT44,即当家庭用户从电信公司获取服务时,在自己的家庭网络中添加一个NAT;每个从家庭网络出去的数据包会经过两次地址转换。
- 运营商级NAT(CGN):大规模的NAT44,用于电信公司将成千上万的(用户)私有地址映射到有限的公共地址。
对于面向移动设备的大型网络迁移,选择了NAT64解决方案。
为了在网络边缘迁移到IPv6并保持IPv4兼容性,一些电信运营商正在规划大规模的迁移到DS-Lite,因为它是一个经过充分测试的解决方案,并且已有许多兼容设备出售。
由于缺乏经验,A+P解决方案尚未被认真考虑。
NAT64
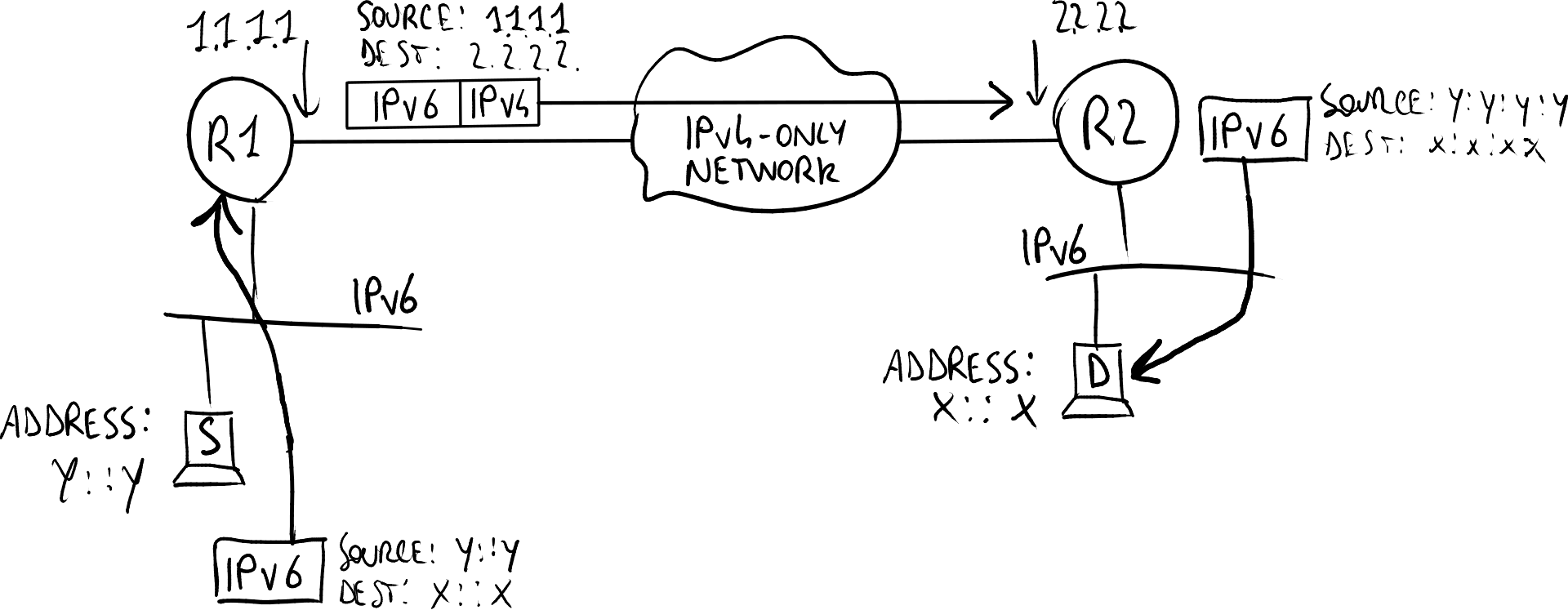
IPv6-only用户在浏览器中输入www.example.com,作为IPv6用户,他会向提供商的DNS64发送AAAA查询。假设www.example.com有IPv4地址“20.2.2.2”。 如果DNS64没有解析到该名称,它需要将查询发送到上级DNS,假设在IPv4网络中。 在最佳情况下,DNS64会将AAAA查询发送给上级DNS,得到AAAA类型的响应(即IPv6格式),并将该响应原封不动地返回给主机(通过IPv4数据包发送的DNS查询也能要求解析出IPv6地址)。 在最坏的情况下,如果上级DNS不支持IPv4,它会回复“名称错误”;此时,DNS64再次发送查询,但这次是A类型的查询,然后会得到一个正确的响应。该响应将转换为AAAA并返回给主机。在返回给主机的响应中,最后32位与上级DNS在A记录中发送的IPv4地址相同,而其他96位则补充完成IPv6地址;因此,最终地址将是“64:FF9B::20.2.2.2”。 此时,主机准备好与www.example.com建立TCP连接。 NAT64介入:它将来自主机的IPv6数据包转换为IPv4,并对来自20.2.2.2的包执行反向操作。
考虑
在这种情况下,没有隧道机制:IPv6头部仅被替换为IPv4头部,反之亦然。 IPv6-only主机并不知道目标地址与IPv4地址有关。 NAT64不仅能够将IPv6地址转换为IPv4地址,而且它在某种程度上使得网络相信232个IPv6地址可用,因为从主机到NAT64的每个数据包将有“64:FF9B::20.2.2.2”作为目标地址,前缀为“64:FF9B/96”。 提供商网络(NAT64和DNS64所在的网络)是IPv6本地的,因此提供商网络中的主机可以直接与其他支持IPv6的主机进行通信,而无需经过NAT64。 “64:FF9B/96”是专门为这种转换技术标准化的地址空间,分配给NAT64,但网络管理员可以根据需要更改它。值得注意的是,网络管理员需要配置路由,以确保任何具有该前缀的数据包都会送往NAT64,并配置NAT64,使其将所有具有该前缀的IPv6数据包转换为IPv4并转发到IPv4网络。
缺点
NAT的存在引入了一个典型的问题:位于NAT后面的主机不能轻易地从外部访问。 通常情况下,当DNS没有地址解析时,它不会回复任何信息,而是直接不回应,而不是发送“名称错误”;这会导致DNS64等待超时,从而延迟时间,超时后DNS64会发送A类型的查询。 如果用户希望直接输入IPv4地址,这种解决方案就无法使用:用户始终需要指定目标的名称。
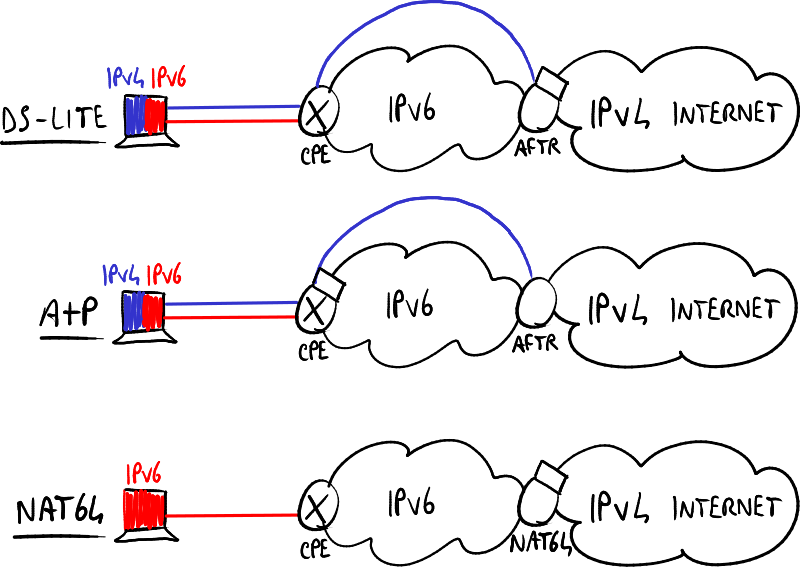
DS-Lite
**双栈精简(DS-Lite)**解决方案通过将NAT和DHCP功能移至提供商网络的边缘,从而简化CPE,变成一个同时作为AFTR和CGN-NAT44的设备。
提供商的DHCP服务器为每个CPE的每个主机分配一个唯一的IPv6地址,该地址在提供商网络中是唯一的。 当用户需要发送IPv4数据包时,需要进行隧道操作,将IPv4数据包封装到IPv6数据包中,因为提供商的网络仅支持IPv6。因此,当CPE收到IPv4数据包时,它需要将其隧道化为IPv6数据包,以便将其发送到AFTR,之后是IPv4云;因此,提供商IPv6网络中,CPE和AFTR之间的场景涉及大量的隧道操作。特别地,CPE和AFTR之间的数据包,源IPv6地址是AFTR的地址,目标IPv4地址是IPv4网络中的目标地址。 AFTR在去除IPv6头部后,将数据包发送到NAT44,NAT44将IPv4(私有)源地址替换为NAT所接收的与该流关联的IPv4地址。 DS-Lite的主要优势是显著减少了提供商公共地址的使用数量。
提供商网络中是否会有重复的IPv4地址?
不会,因为NAT44直接将主机的IPv4地址转换为可用的公共IPv4地址。如果有重复的私有IPv4地址,NAT将遇到歧义问题。缺点
- 一个IPv4主机无法联系IPv6目标 → 仅支持IPv6的目标只能被IPv6主机访问。相反,IPv6主机可以直接与IPv6节点进行数据交换,无需经过提供商的AFTR。
- 某些应用无法在这种情况下工作:由于NAT不再由用户管理,而是由提供商管理,因此无法执行一些常见操作,例如打开/关闭特定应用所需的端口。
DS-Lite A+P
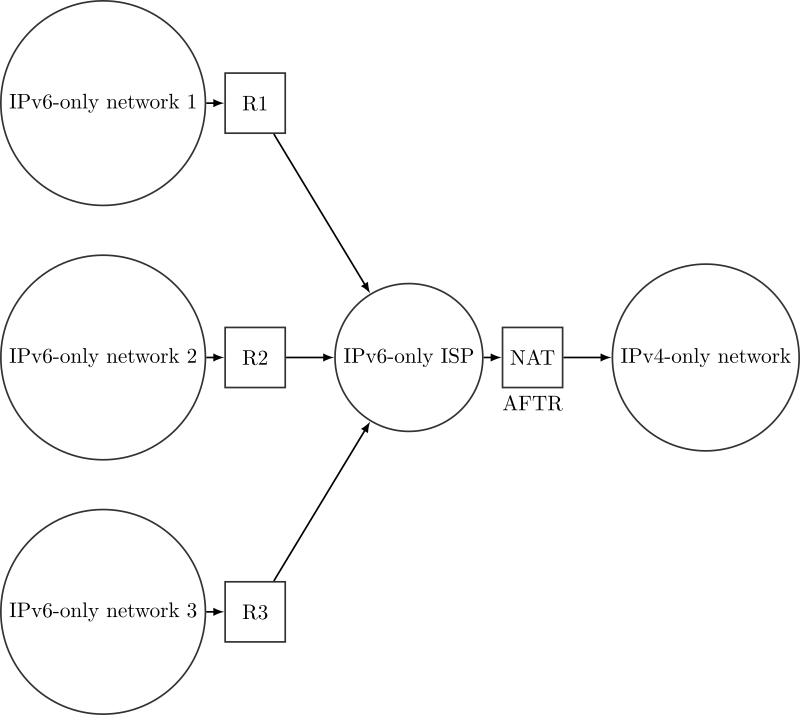
**双栈精简地址+端口(DS-Lite A+P)**解决方案仍然使用提供商的IPv6-only网络,但NAT被移到CPE上,以便用户可以根据自己的需求进行配置。
与DS-Lite类似,从CPE出去的IPv4数据包仍然需要通过隧道化,因为提供商网络仍然是IPv6-only。
每个CPE上的NAT需要一个公共IPv4地址的问题通过允许重复使用公共IPv4地址得到解决,CPE通过端口进行区分。每个CPE使用特定的端口范围,AFTR根据每个CPE使用的端口范围来区分数据流,即使多个CPE使用相同的公共IPv4地址。
这种解决方案与DS-Lite类似,但私有IPv4地址空间更加由终端用户控制,因为NAT位于用户的CPE上,用户可以配置它,尽管有些限制:用户不能使用不在其端口范围内的端口。此方法可以节省IPv4地址(但相对于DS-Lite来说,节省的数量较少)。
在意大利,这种解决方案基本上是非法的,因为端口号没有记录,如果发生攻击,就无法追踪到攻击者。
在核心网络中传输IPv6流量
主要目标是让IPv6流量能够通过全球网络传输,而不会破坏现有的网络结构,该网络已经运行了超过20年,并且目前运行良好。全球范围内的IPv4网络大规模迁移至IPv6会涉及人力和技术上的高成本,这几乎是不可持续的。
6PE
**6提供商边缘(6PE)**解决方案的目标是通过MPLS骨干网将多个IPv6云连接在一起。6PE要求运营商的网络采用MPLS技术。在这种方案中,提供商的边缘是用户CPE首先遇到的路由器。
思路
- 保持核心网络不变(不排除未来的变化可能性)。
- 为提供商网络的边缘添加IPv6支持。
- 通过MPLS/BGP传递IPv6路由信息,类似于VPN的工作原理。
要求
- 主要要求是拥有一个MPLS核心网络。
在图中:

- MPLS核心网络由PE-1、P-1、P-2、PE-2组成;
- 两个侧设备PE-1和PE-2部分“嵌入”到MPLS网络中;
- CE与PE之间的连接可以视为为家庭用户提供ADSL连接的连接。
6PE的设计是让核心网络能够支持IPv4数据包通过MPLS传输,而只在提供商的边缘路由器(PE)添加IPv6支持。事实上,一旦数据包被封装成MPLS数据包,中间设备就不再关心封装的数据包类型,而只关心标签,从而确定如何路由该数据包。
实际上,PE需要进行额外的更新以支持MG-BGP协议,该协议允许传输和通信IPv4和IPv6路由。
对于这种解决方案的一个重大优势是只需要更新PE路由器,而不需要更新所有中间路由器:这是提供商可以管理的一个低成本操作。
IPv6网络的广告方式
CE-3广播自己能够访问IPv6网络“2001:3::/64”。 该信息也会传递给PE-2。 PE-2将此信息发送到网络中的所有PE,告知它能够通过下一个跳点“FFFF:20.2.2.2”访问“2001:3::/64”网络,尽管它的接口是IPv4(这是因为如果给出IPv6路由,则需要给出IPv6的下一跳)。 PE-1接收到该信息,并将其传递给所有与其连接的路由器,包括家庭CPE,告知它能够访问网络“2001:3::/64”。 如果PE-1与地址“20.2.2.2”之间尚不存在MPLS路径,则使用经典的MPLS机制(例如LDPv4信令协议)来建立该路径。
IPv6流量的路由方式
为了路由IPv6数据包,使用两个标签:
- LDP/IGPv4外部标签到PE-2:用于标识PE之间的LSP。
- MP-BGP内部标签到CE-3:用于标识目标CPE。
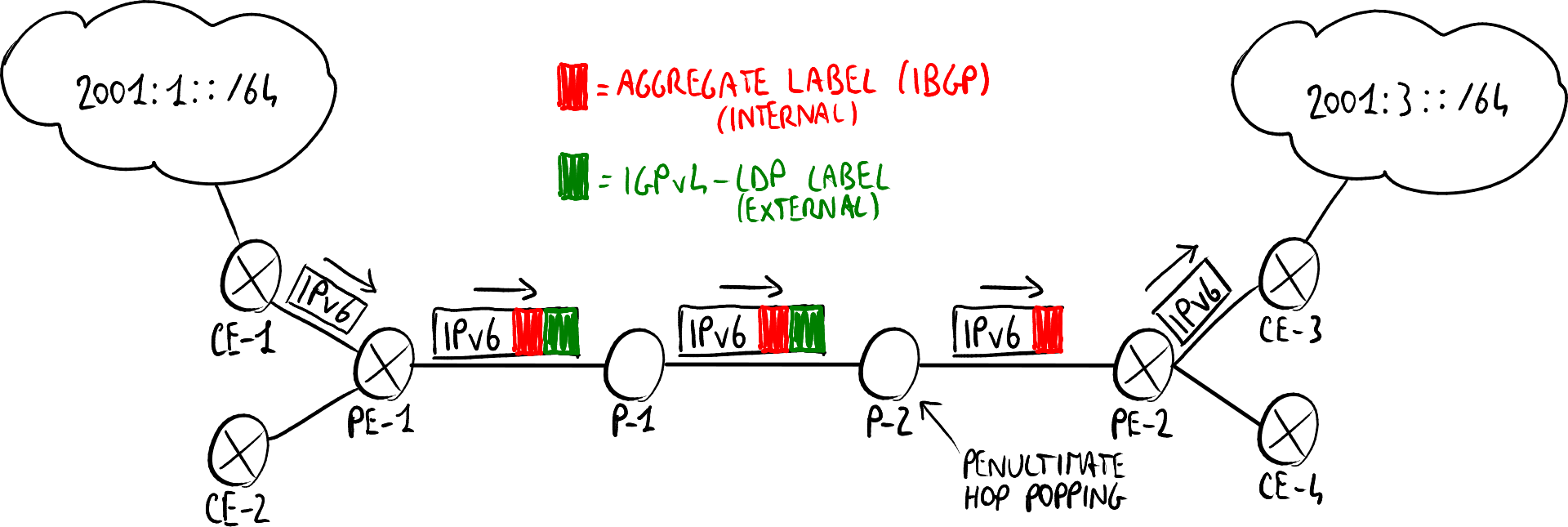
假设网络“2001:1::/64”中的主机想要将数据包发送到“2001:3::/64”网络中的主机:
- 数据包到达CE-1;
- CE-1知道“2001:3::1/64”网络的存在,并将数据包发送到PE-1;
- PE-1在数据包前添加两个标签:内部标签和外部标签;
- PE-1将数据包发送到P-1,P-1再转发到P-2;
- P-2,作为倒数第二跳,移除外部标签(倒数第二跳标签弹出)并将数据包发送到PE-2;
- PE-2移除内部标签,并将数据包发送到CE-3;
- CE-3将数据包转发到目标网络“2001:3::/64”。
考虑事项
- PE路由器需要支持双栈并支持MP-BGP,而中间路由器不需要任何更改。
- 这种解决方案可以为客户提供原生的IPv6服务,而无需更改IPv4 MPLS核心网络(需要的操作成本和风险最小)。
- 该方案适用于部署少量IPv6云的情况。
安全问题
由于IPv6尚未广泛使用,安全性问题经验较少 → IPv6可能仍然存在未被发现的安全漏洞,攻击者可能会利用这些漏洞。此外,在迁移阶段,主机需要同时开放两个端口,一个用于IPv4,另一个用于IPv6 → 需要保护这两个端口免受外部攻击。
DDoS攻击与SYN洪水 主机接口可以有多个IPv6地址 → 它可以生成多个TCP SYN请求,每个请求都有不同的源地址,向服务器发送,利用这一点耗尽服务器内存,使其打开多个未关闭的TCP连接。
虚假路由广告消息 主机可能开始发送“路由器广告”消息,宣称虚假的前缀 → 链路中的其他主机将开始发送具有错误前缀的源地址的包。
-
一家希望为其远程终端(单一用户、数据中心、分支机构)建立企业私有网络的公司可以采用两种不同的方式:
- 公司可以建立自己的专用基础设施(专线、拨号连接);
- 公司可以采用虚拟专用网络(VPN)解决方案。
虚拟专用网络(VPN)允许公司通过公共共享基础设施(如互联网或互联网服务提供商的网络)为多个用户提供连接,同时执行自己的策略(如安全性、服务质量、私有地址),就像它拥有自己的私有网络一样。
VPN解决方案的优点包括:
- 成本低廉:不再需要为远程用户建立昂贵的物理连接,VPN解决方案利用了预先存在的基础设施,因此成本可以共享;
- 选择性:通过防火墙,只有具有权限的用户才能访问 → 提高了安全性;
- 灵活性:可以轻松地添加允许的用户,用户可以轻松移动。
VPN由一些主要组件构成:
- 数据通过隧道传输,因此它们与在共享基础设施上移动的其他数据分开,使用如GRE、L2TP、MPLS、PPTP和IPsec等协议;
- 数据被加密以提高安全性,使用如IPsec和MPPE等协议;
- 数据完整性受到检查,因此无法篡改,通过TCP校验和或IPsec中的AH进行检查;
- 在建立隧道之前,检查隧道另一端的身份,通过认证机制(例如使用数字证书)。
分类
VPN解决方案可以根据以下几个方面进行分类:
- 部署方式:访问型或站点到站点型(内部网/外部网);
- 互联网接入方式:集中式或分布式;
- 模型:覆盖型或对等型;
- 供应方式:客户型或供应商型;
- 层次:第二层、第三层或第四层;
- 虚拟拓扑:中心-分支型或网状型。
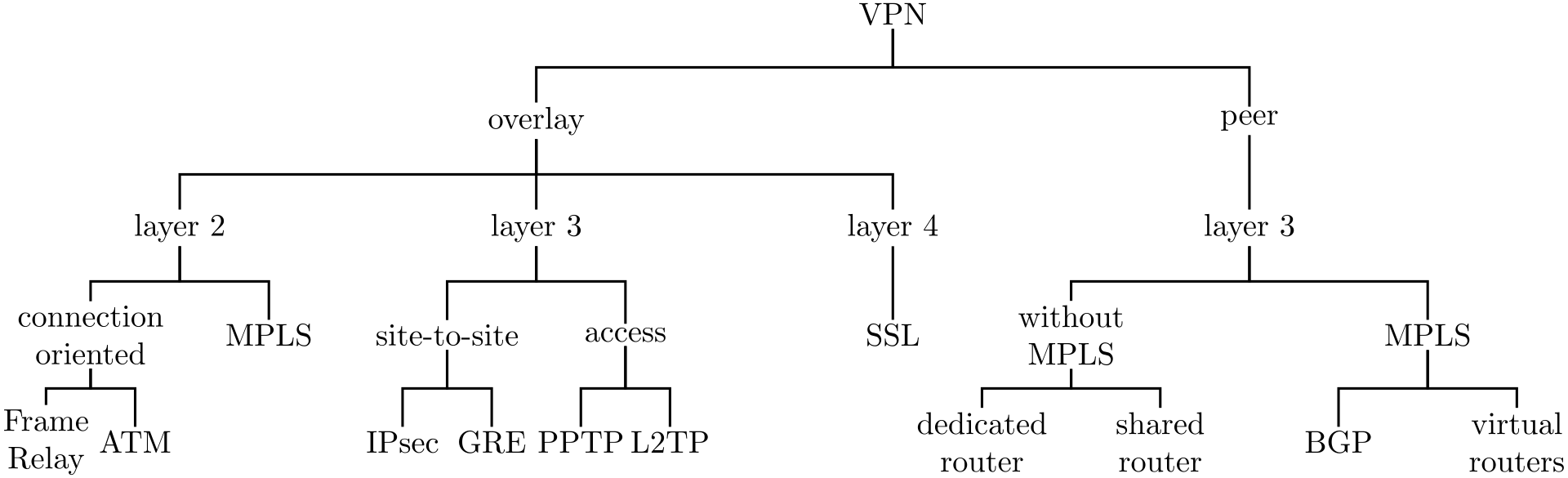
覆盖型 对等型 访问型 L2TP, PPTP 站点到站点型 IPsec, GRE MPLS 部署场景
VPN可以部署在两种主要场景中:
- 访问型VPN(也称为“远程VPN”或“虚拟拨入”):它将拨号连接虚拟化,通过ISDN、PSTN、有线调制解调器、无线局域网等连接单个用户到企业网络,使用如PPTP和L2TP等协议;
- 站点到站点型VPN:它将专线虚拟化,并使用如IPsec、GRE和MPLS等协议连接多个远程网络。
站点到站点型VPN可以通过两种方式部署:
- 内部网VPN:所有互联的网络属于同一公司;
- 外部网VPN:互联的网络属于多家公司。
VPN特性要求
VPN必须满足以下一些要求:
- 安全性:防火墙可以限制对网络资源的访问;
- 数据加密:保护通过共享基础设施传输的信息;
- 可靠性:保证任务关键流量能够到达目标;
- 可扩展性:该解决方案必须适用于小型和大型网络;
- 增量部署:随着网络的增长,解决方案仍然可以工作。
对于访问型VPN,额外的要求包括:
- 强认证:验证移动用户的身份(例如个人笔记本可能会被盗);
- 用户及其账户的集中管理。
对于站点到站点型外部网VPN,额外的要求包括:
- 选择性访问:每家公司可以允许其他公司访问某些服务,但阻止访问其私有网络的其他服务;
- 地址冲突管理:一个私有地址可能属于两个不同的私有网络 → 需要NAT;
- 使用开放标准解决方案:不同公司需要能够共享相同的VPN解决方案;
- 流量控制:每家公司需要控制从其他公司网络进入的流量,并消除网络接入点的瓶颈。
互联网接入
连接到VPN的远程终端可以通过以下两种方式访问公共互联网:
- 集中式互联网接入:所有从互联网进出的流量都必须通过总部的VPN网关;
- 分布式互联网接入:从互联网进出的流量不涉及VPN,VPN仅用于企业流量。
集中式互联网接入
优点:
- 集中策略管理:公司可以为所有连接的远程终端设置互联网访问策略(例如禁止员工在工作时访问某些网站);
- 安全性:企业防火墙可以保护主机免受来自互联网的恶意数据包的攻击。
缺点:
- 远程终端的速度较慢:数据包需要经过更多的跳数才能到达目标,因为它们总是必须经过总部的VPN网关,而不是直接到达目的地;
- 总部需要更高的带宽;
- 强制连接:VPN必须始终处于活动状态,用户不能临时禁用VPN并在没有企业防火墙保护的情况下上网,否则如果用户在没有防火墙的情况下感染了恶意软件,当重新连接VPN时,企业网络可能会受到感染。
分布式互联网接入
优点:
- 远程终端的速度较快:数据包总是直接朝互联网目的地发送;
- 自愿连接:用户可以随时禁用VPN而不会带来额外的安全威胁。
缺点:
- 分布式策略管理:公司需要在远程终端配置多个路由器来设置自己的策略;
- 安全威胁:缺少企业防火墙保护。
Overlay model.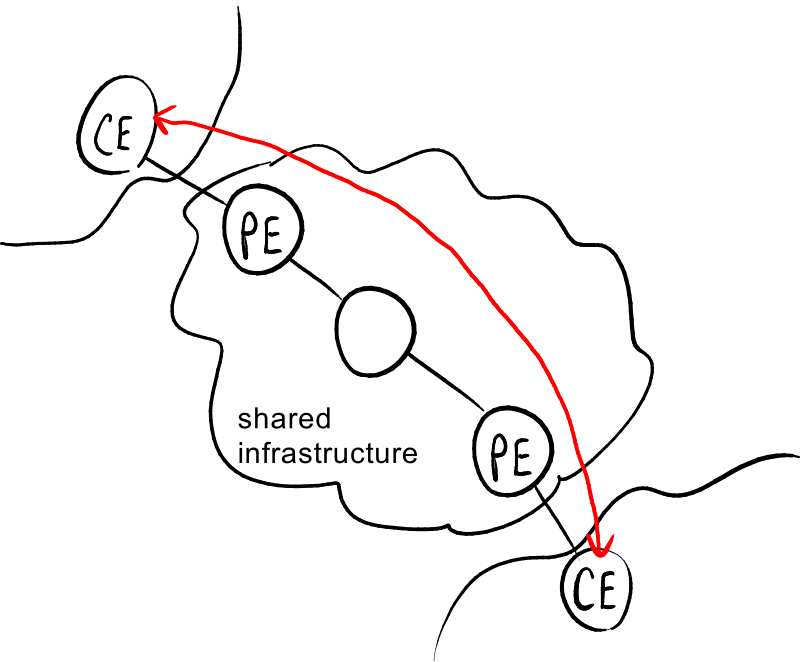 Peer model.
Peer model.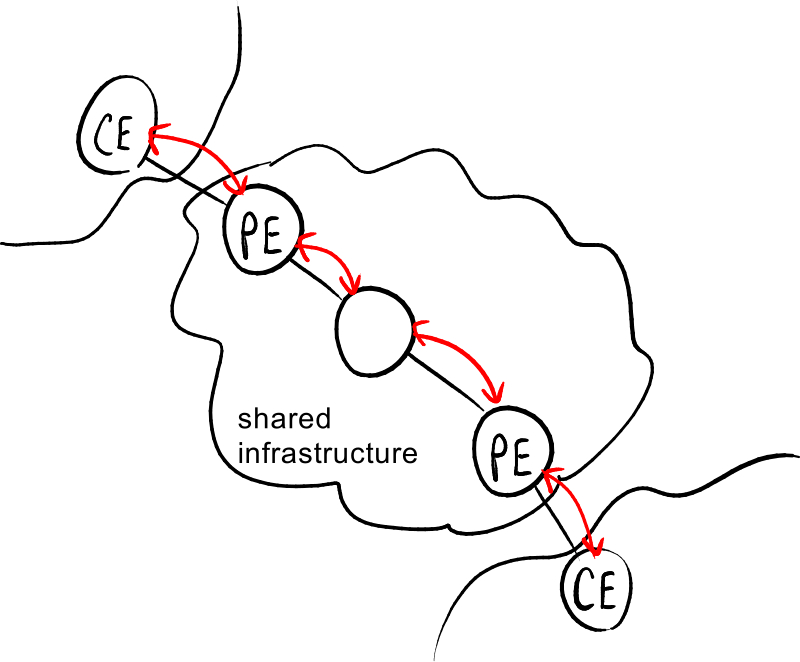
VPN可以根据共享基础设施的角色分为两种模型:
- 覆盖模型(Overlay model):基础设施对VPN解决方案不了解,仅提供IP连接服务;它只传输数据包,而不识别这些数据包是否属于VPN,在VPN网关之间传输数据包,但不与基础设施进行交互 → 适用于数据隐私:基础设施的管理员无法查看私密数据或利用路由信息;
- 对等模型(Peer model):基础设施内部的网关参与VPN的创建并相互交互 → 提供更好的路由,更多的可扩展性。
基于非MPLS的对等模型VPN可以是:
- 专用路由器(Dedicated router):基础设施的管理者将一些路由器专门分配给某个客户,其他路由器分配给另一个客户,依此类推;
- 共享路由器(Shared router):基础设施中的每个路由器由多个客户共享 → 成本较低。
提供方式
客户自建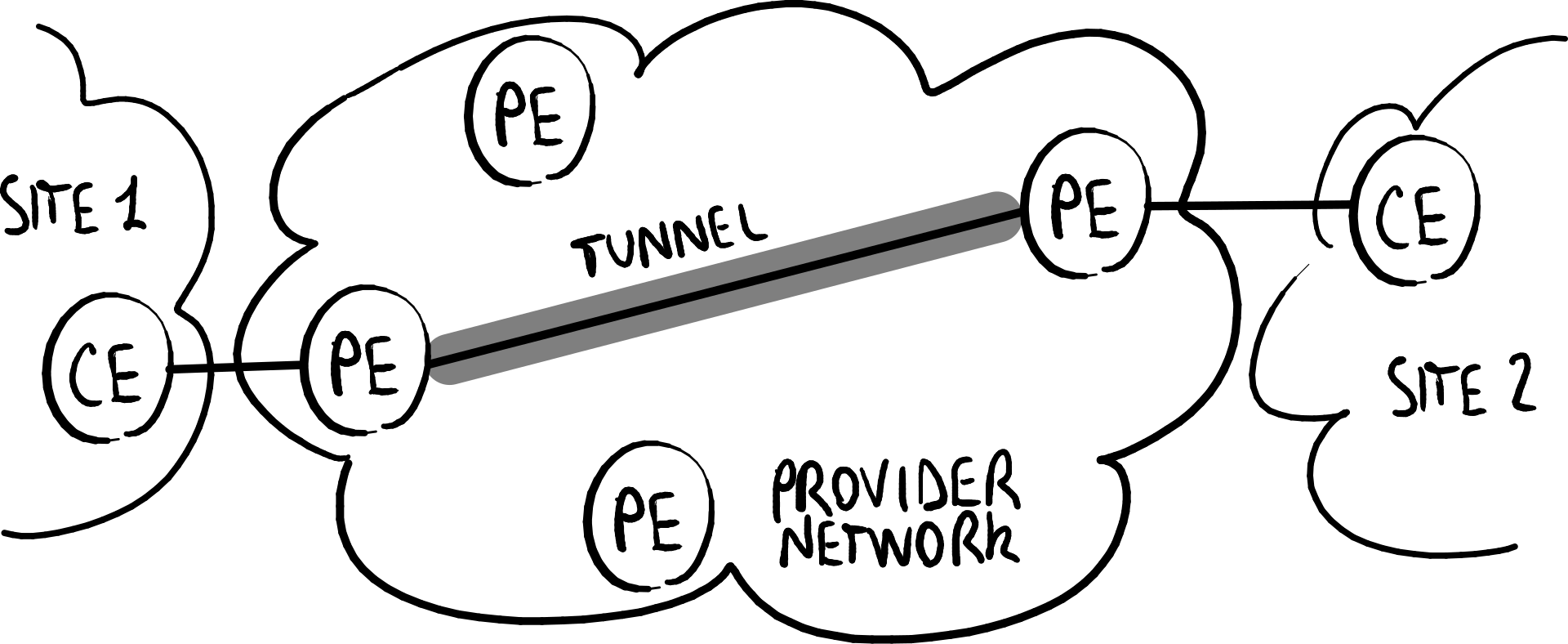 提供商提供
提供商提供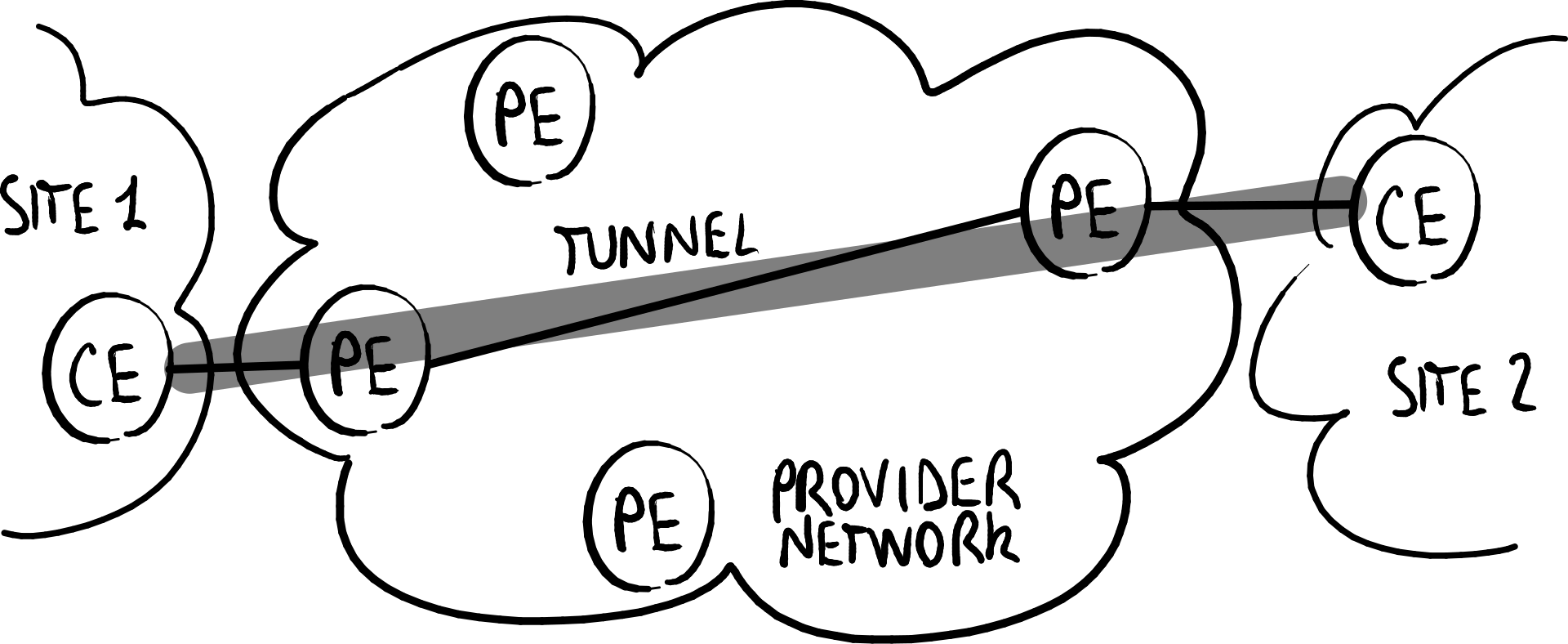
VPN可以由客户或提供商提供:
- 客户自建(Customer provision):用户自己创建并管理VPN,隧道设置在客户边缘设备(CE)之间;
- 提供商提供(Provider provision):VPN由互联网连接提供商提供并管理,隧道设置在提供商边缘设备(PE)之间。
客户自建的VPN不能采用对等模型,因为提供商无法了解由客户自行创建的VPN。
层次
VPN连接可以处于不同的层次:
- 第二层(Layer 2):在VPN中交换以太网帧:
- 虚拟专用局域网服务(VPLS):将局域网虚拟化,终端看似处于同一局域网 → 允许广播数据包;
- 虚拟专用线路服务(VPWS):在分组交换网络上虚拟化专线;
- 仅IP局域网类似服务(IPLS):虚拟化IP网络,仅允许IP数据包(如ICMP和ARP);
- 第三层(Layer 3):在VPN中交换IP数据包;
- 第四层(Layer 4):在VPN中设置TCP连接(可能使用SSL进行安全性保护)。
虚拟拓扑
根据虚拟拓扑,VPN可以分为两类:
- 中心-分支型(Hub and spoke):每对终端只能通过总部进行通信 → 由于流量较大,可能会在总部发生瓶颈;
- 网状型(Mesh):每对终端可以直接通信,而无需通过总部 → 路由更好,但隧道的数量更多。
协议
-
PPP(点对点协议): 点对点协议(PPP)是一个第二层协议,用于点对点连接(如拨号、ISDN)来封装上层的任何协议。它是对HDLC协议的扩展。
PPP数据包的格式如下:
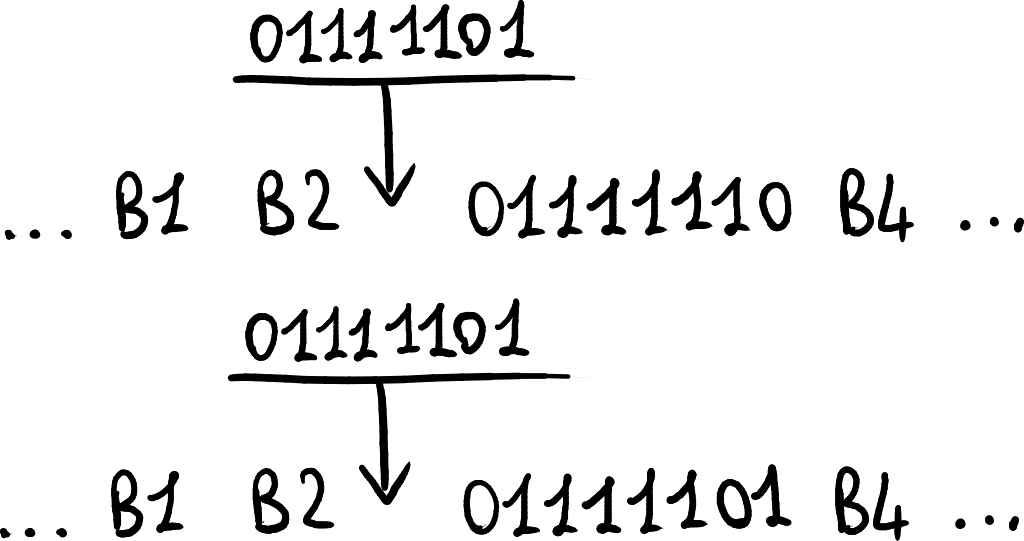
1字节 1字节 1字节 1或2字节 2或4字节 1字节 01111110(旗帜) 地址 控制 协议 数据 CRC 01111110(旗帜)其中最重要的字段包括:
- 起始和结束旗帜:用于数据帧定界;
- 地址和控制字段:这些字段继承自HDLC,但在点对点连接中没有实际意义,它们的存在是为了简化HDLC设备的处理算法升级;
- 协议字段:指定上层协议,即封装的数据包的协议类型。
为了发送“01111110”作为数据,需要进行字节级填充:当数据中出现与定界字节相同的字节时,插入转义序列“01111101”。
**链路控制协议(LCP)**的任务是打开和关闭PPP连接,协商一些选项(如最大帧长、认证协议)。
-
GRE(通用路由封装): IP数据包不能直接封装第三层或以下的协议,因为IPv4头中的“协议”字段只能指定上层协议(如TCP、UDP、ICMP)。通用路由封装(GRE)是一种协议,用于将任何协议(包括IP及其他低层协议)封装到IP中。GRE头插入在封装的IP头和被封装的数据包之间,并将封装IP头中的“协议”字段设置为47。
GRE头的格式如下:
5 8 13 16 32 C R K S s Recur Flags Version(0) 协议类型 校验和(可选) 偏移(可选) 键(可选) 序列号(可选) 路由(可选) :::其中最重要的字段包括:
- C, R, K, S标志(每个1位):指示可选字段的存在或缺失;
- 严格源路由(s)标志(1位):如果设置为1,当源路由列表(“路由”字段)结束时,如果目标尚未到达,数据包将被丢弃(类似于TTL);
- Recur字段(3位):指定允许的最大封装次数(目前不支持);
- 版本字段(3位):指定GRE协议的版本(此处为0);
- 协议类型字段(16位):指定被封装数据包的协议;
- 路由字段:指定数据包应经过的中间路由器的IP地址序列(源路由)。
-
增强型GRE: 增强型GRE头的格式引入了新的“确认号”字段:
5 8 13 16 32 C R K S s Recur A Flags Version(1) 协议类型 键(有效载荷长度) 键(会话ID) 序列号(可选) 确认号(可选)其中最重要的字段包括:
- 键字段(32位):
- 有效载荷长度(16位):指定数据包的长度,不包括GRE头(以字节为单位);
- 会话ID(16位):指定数据包的会话ID;
- 确认号字段(32位):发送方在数据包中放入已接收的最后一个序列号(累积确认)。
新的“确认号”字段与“序列号”字段结合使用,可以支持一些附加机制:
- 流量控制:滑动窗口避免目的地泛滥,并在收到确认包时移动;
- 乱序包检测:增强型GRE是为PPP封装设计的,而PPP用于点对点连接,因此预计数据包不会乱序 → 乱序数据包将被丢弃;
- 丢包检测:当超时过期时,即未收到任何确认包,数据包被视为丢失,但丢失的数据包不会重新传输;
- 拥塞控制:当检测到过多的超时时,数据包传输将减慢,以避免网络拥塞。
- 键字段(32位):
L2TP(第二层隧道协议)
L2TP的原始参考场景:提供商提供的部署模式。 客户自建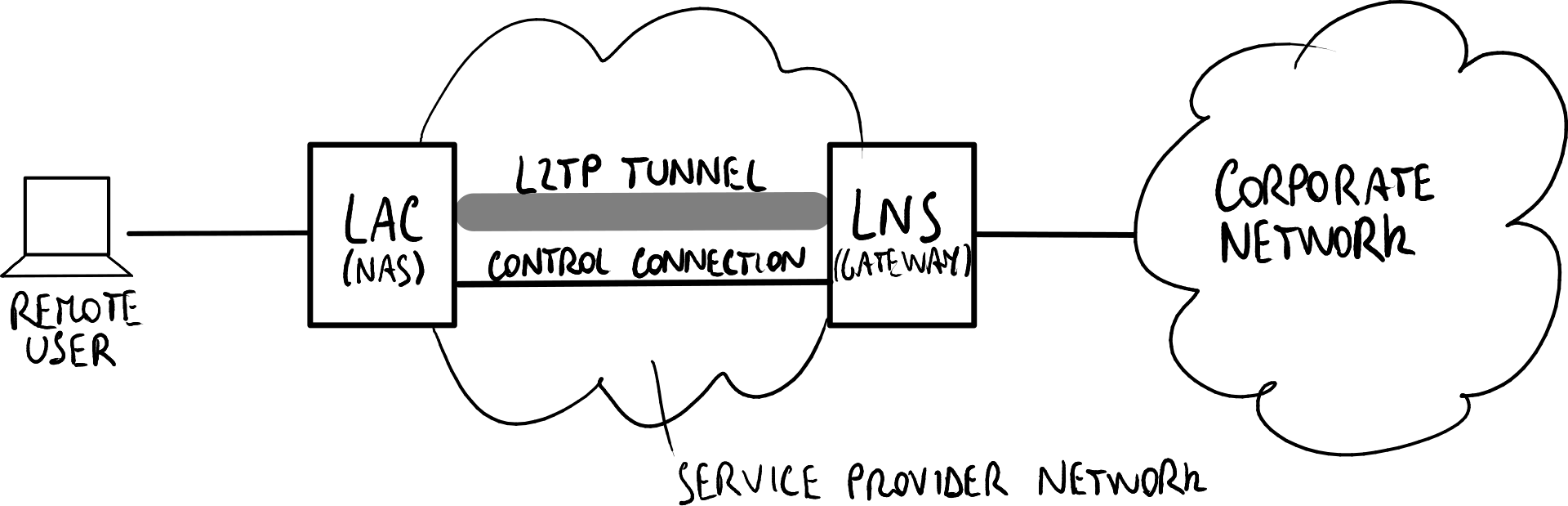
**第二层隧道协议(L2TP)**是一种将任何第二层协议(本文讨论的是PPP)封装到IP中的协议。L2TP最初是为提供商提供的接入VPN设计的,并由IETF标准化;后来通过将LAC(L2TP访问集中器)功能实现到用户机器中,L2TP扩展到了客户自建接入VPN。
在L2TP的原始参考场景中,一个远程用户希望通过点对点(PPP)连接向公司网络内的内部服务器发送数据包。需要建立L2TP隧道连接到目标L2TP网络服务器(LNS),并在隧道内部建立L2TP会话,以模拟通过服务提供商网络的PPP连接。
当PPP帧到达L2TP访问集中器(LAC)时,如果尚未与LNS建立L2TP隧道,LAC必须在打开L2TP会话之前建立到LNS的隧道:LNS通过类似挑战握手认证协议(CHAP)的机制验证自身身份,并建立一个新的控制连接。
每个L2TP会话在隧道内部使用两个通道:
- 数据通道:用于传输数据消息,即PPP帧;
- 控制通道:用于交换控制消息,管理通信(如验证数据包是否到达、重传丢失的数据包、检查数据包的正确顺序)。
与数据消息不同,控制消息以可靠的方式交换:丢失的控制消息总是会被重传。
多个会话可以共享同一个隧道,使用相同的控制连接来区分来自多个远程用户的PPP帧流:每个隧道由隧道ID标识,每个会话由会话ID标识。
安全性
除了在隧道建立步骤中确保身份验证外,L2TP本身并不提供任何安全机制:实际上,使用像加密这样的机制来保护L2TP数据包在隧道中传输没有意义,因为服务提供商的LAC仍然可以查看第二层帧 → 任何安全机制必须端到端实现,即在用户和公司网络内部的最终目的地之间。
可选地,可以通过隧道使用IPsec:它提供强大的安全性,但实现起来比较复杂。
L2TP隧道内的数据包包含多个封装的头部:
- MAC头部
- IP头部
- UDP头部
- L2TP头部
- PPP头部
- PPP负载
PPP头部
它标识远程用户与公司网络内部服务器之间的点对点连接。
L2TP头部
它标识L2TP隧道:
8 16 32 T L 0 S 0 O P 0 版本(2) 长度 隧道ID 会话ID Ns Nr 偏移大小 偏移填充 :::最重要的字段包括:
- T标志(1位):如果设置为0,数据包是数据消息;如果设置为1,则为控制消息;
- 隧道ID字段(16位):标识L2TP隧道;
- 会话ID字段(16位):标识L2TP会话,即隧道中的数据通道;
- Ns字段(16位):包含数据/控制消息的序列号;
- Nr字段(16位):包含要接收的下一个控制消息的序列号,用于可靠的控制连接。
UDP头部
为什么使用如UDP这样的第四层协议来传输第二层帧?这可以通过考虑一般网络中的防火墙来解释:如果数据包没有第四层封装,它更容易被防火墙丢弃。
另一个可能的原因是,第四层可以通过套接字访问,而操作系统负责第三层。由于L2TP希望作为PPTP的解决方案(PPTP由操作系统供应商提出),L2TP设计者希望它对应用程序可用,而不是与操作系统供应商的意图绑定。
也可以使用其他第四层协议(如ATM,帧中继)。
IP头部
它包含隧道端点的IP地址。在原始参考场景中,IP地址对应于LAC和LNS。
PPTP(点对点隧道协议)
L2TP的原始参考场景:提供商提供的部署模式。 客户自建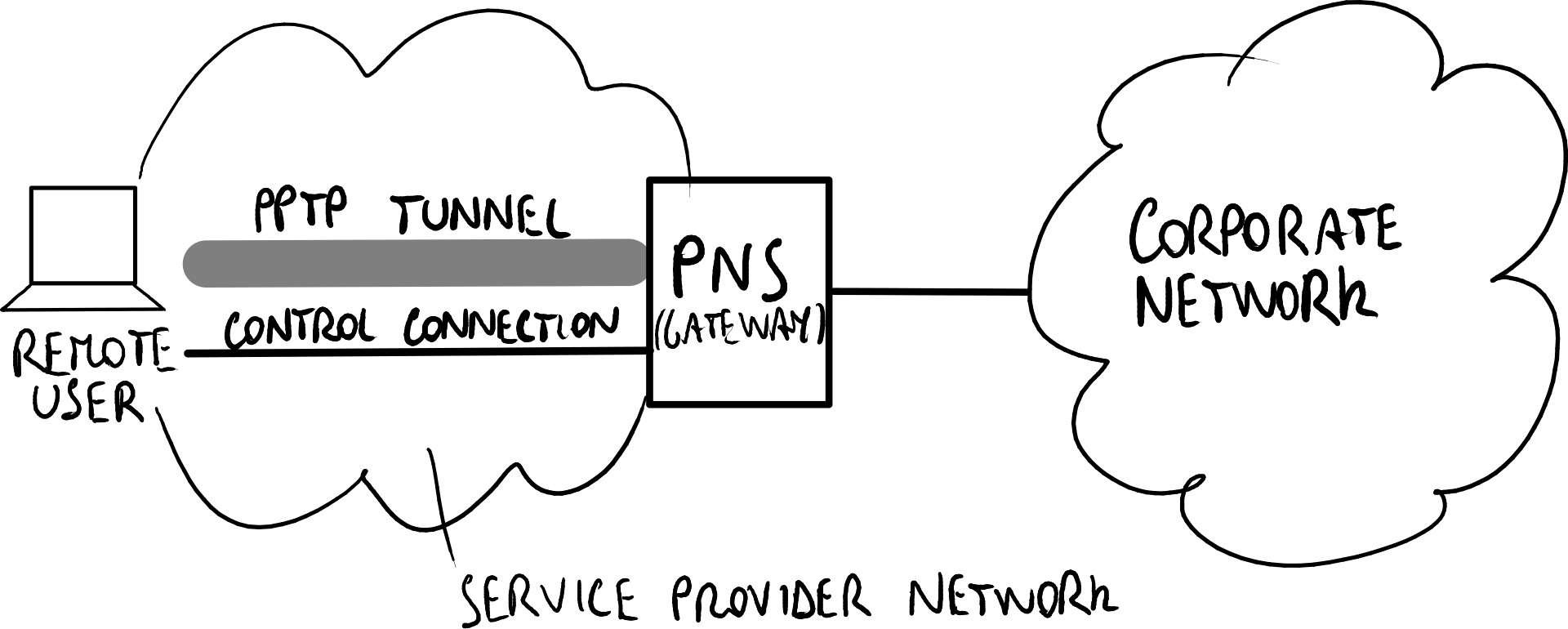
PPTP原始参考场景:客户自建的部署模式。
**点对点隧道协议(PPTP)**是一种将PPP协议封装到IP中的协议。PPTP最初是为客户自建的接入VPN设计的,并由主要的操作系统供应商开发;后来通过引入具有类似LAC功能的PPTP访问集中器(PAC),将其扩展到提供商提供的接入VPN。
PPTP原始参考场景与L2TP的不同之处在于,PPTP隧道是在远程用户和PPTP网络服务器(PNS)之间建立的。
与L2TP不同,PPTP提供了较弱(可选)的安全机制:标准涵盖了特定的微软专有安全协议,如用于加密的MPPE和用于认证的MS CHAP,因此没有协议协商。
数据通道
封装的PPP帧通过数据通道传输:
IP头部 GRE头部 PPP头部 PPP负载PPTP使用增强型GRE协议将PPP帧封装到IP中。PPP负载可以选择性地通过MPPE进行加密。
控制通道
PPTP控制消息通过控制通道传输:
IP头部 TCP头部 PPTP控制消息控制消息用于隧道数据会话的建立、管理和拆除,发送到PNS的知名TCP端口1723。
IPsec
互联网协议安全(IPsec)协议集在IPv4中的功能与在IPv6中的类似。主要的区别在于,在IPv6中,IPsec是作为扩展头包含在标准中,而在IPv4中,它是一个新的附加协议,封装到IP中(对于AH,"协议"字段设置为51,对于ESP设置为50):
-
身份验证头(AH):
IPv4头部 AH头部 TCP/UDP头部 负载 已验证数据 -
封装安全有效载荷(ESP):
IPv4头部 ESP头部(用于加密) TCP/UDP头部 负载 ESP头部 加密数据 已验证数据
SSL
安全套接层(SSL),现在称为传输层安全性(TLS),是一种旨在为客户端和服务器之间提供通信安全性的加密协议:
- 客户端通过TCP连接到端口443并发送挑战请求进行服务器认证;
- 服务器向客户端发送Hello消息,包含其证书和使用服务器私钥加密的挑战响应;
- 客户端通过查阅信任的认证机构的证书列表来验证证书,然后使用服务器的公钥解密响应;
- 客户端为安全通信选择一个私钥并通过服务器公钥加密发送 → 从此之后,所有记录消息都将使用该私钥加密(该私钥应定期重新协商);
- 服务器通常要求用户在网页上输入用户名和密码进行客户端认证(在应用层)。
访问VPN

拨号连接场景
基本上,一个远程用户,通常是公司的员工,希望通过公司网络联系一个服务器。他可以通过拨号点对点连接到公司网关,使用PPP协议将IP数据包封装:
- 通过链路控制协议(LCP),他可以协商第二层参数(如认证协议);
- 通过网络控制协议(NCP),他可以协商第三层参数(如公司网络内的私有IP地址、DNS等)。
在接受拨号连接之前,公司网关会通过**远程认证拨号用户服务(RADIUS)**协议联系公司安全服务器来检查用户身份。公司安全服务器是一个集中的AAA服务器:
- 认证:识别用户(例如通过用户名和密码);
- 授权:检查用户可以访问哪些服务以及哪些服务被限制;
- 计费:跟踪用户活动(例如,用于计费)。
访问VPN可以虚拟化远程用户与公司网络之间的拨号连接,借助服务提供商的共享基础设施来降低成本。PPP协议将在VPN隧道中继续使用,避免对公司网关做出过多的更改。
客户自建部署
访问VPN以客户自建方式部署。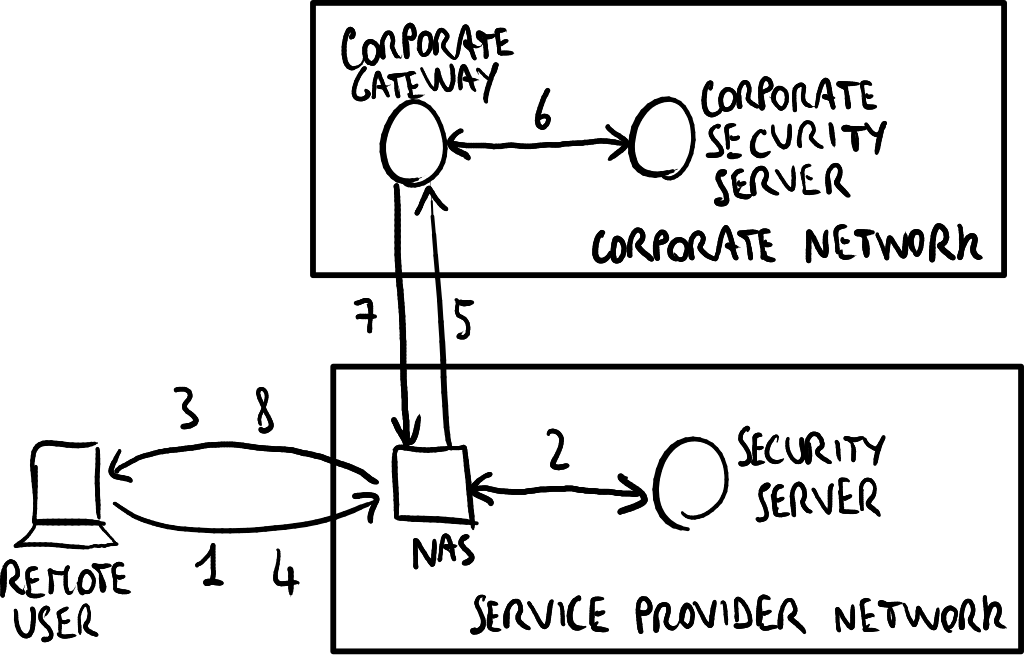
在客户自建的访问VPN中,隧道在远程用户与公司网关之间建立:
- 用户请求与服务提供商的NAS建立PPP拨号连接,并通过LCP和NCP协商连接配置参数;
- NAS通过RADIUS协议通过提供商的安全服务器检查用户身份;
- NAS为用户提供PPP拨号连接的配置参数,特别是公共IP地址;
- 用户请求与公司网关建立VPN隧道,发送包含IP数据包的PPP帧,其中目的IP地址为公司网关的公共IP地址;
- NAS通过服务提供商的网络将请求转发给公司网关;
- 公司网关通过RADIUS协议通过公司安全服务器检查用户身份;
- 公司网关为用户提供VPN隧道的配置参数,特别是公司网络内的私有IP地址;
- NAS将公司网关的回复转发给远程用户。
一旦VPN建立,用户将拥有两个IP地址:一个是服务提供商的公共IP地址,另一个是公司网关的公司IP地址。用户通过隧道发送的PPP帧格式如下:
PPP头部 IP头部 PPP头部 IP头部 IP负载 src: 用户的公共IP地址 src: 用户的公司IP地址 dst: 公司网关的公共IP地址 dst: 最终目的地的公司/公共IP地址优点
用户独立于服务提供商:后者仅提供用户与公司网关之间的互联网连接。
缺点
用户可能暂时禁用VPN连接并通过互联网连接到外部服务器 → 如果他感染了恶意软件,当他重新连接到VPN时,会感染公司网络。
提供商自建部署
访问VPN以提供商自建方式部署。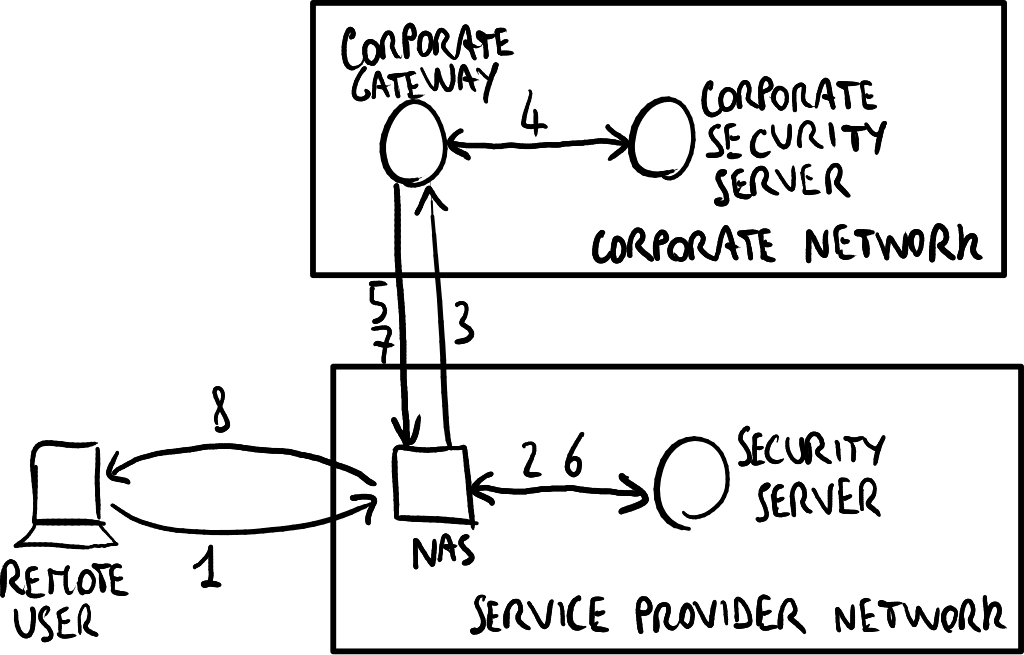
在提供商自建的访问VPN中,隧道在服务提供商的NAS和公司网关之间建立:
- 用户请求与公司网关建立PPP拨号连接,并通过LCP和NCP协商连接配置参数;
- NAS通过RADIUS协议通过提供商安全服务器检查用户身份,特别是将用户标识为VPN用户;
- NAS请求与公司网关建立与用户相关的VPN隧道,发送目的IP地址为公司网关公共IP地址的IP数据包;
- 公司网关通过RADIUS协议通过公司安全服务器检查用户身份;
- 公司网关为NAS提供VPN隧道的配置参数;
- NAS可选择性地记录接受信息和/或流量,以便向公司收费;
- 公司网关为用户提供PPP连接的配置参数(拨号已虚拟化),特别是公司网络内的私有IP地址;
- NAS将公司网关的回复转发给远程用户。
一旦VPN建立,用户只拥有公司IP地址,并且无法知道服务提供商NAS与公司网关之间的隧道。NAS通过隧道发送的IP数据包格式如下:
IP头部 PPP头部 IP头部 IP负载 src: 服务提供商NAS的公共IP地址 src: 用户的公司IP地址 dst: 公司网关的公共IP地址 dst: 最终目的地的公司/公共IP地址优点
用户无法在不经过公司网关的情况下访问互联网(集中式访问)→ 更高的安全性。
缺点
用户不独立于服务提供商:如果他更换服务提供商,VPN连接将无法再工作。
站点到站点VPN
基于IPsec的VPN
在基于IPsec的VPN中,IPsec在隧道模式下用于VPN网关之间:两个主机之间的IP数据包被封装成一个IP数据包,具有ESP头部(可选的AH头部),在两个VPN网关之间传输,这样两个主机的IP地址也可以通过ESP进行加密。
私有内网可以通过以下方式进行保护:
- 防火墙:根据公司策略过滤流量,例如允许的IP地址,防火墙可以放置在不同位置相对于VPN网关:
- 在VPN网关之前:VPN网关被保护,但防火墙无法过滤加密的VPN流量;
- 在VPN网关之后:防火墙可以过滤解密后的VPN流量,但VPN网关没有保护;
- 与VPN网关并行:数据包既经过VPN网关之前,也经过VPN网关之后,防火墙的工作量更大,但VPN网关和VPN流量都得到了保护;
- 集成到VPN网关中:VPN网关和防火墙的功能集成到一个设备中 → 最大的灵活性;
- 入侵检测系统(IDS):观察流量以尝试检测是否有攻击发生,并将两个IDS探针放置在VPN网关并行位置:
- VPN网关之前的探针观察来自隧道的流量,保护来自共享基础设施的攻击;
- VPN网关之后的探针观察VPN流量,保护来自公司网络的攻击(例如,安装在员工PC上的恶意软件,或如果站点到站点VPN是外联网时来自其他公司的攻击)。
NAT(网络地址转换)的存在可能会导致IPsec的问题:
- AH(认证头)认证整个数据包,因此它也包括IP头 → NAT需要更改IP地址,这样认证就无法继续工作;
- ESP(封装安全有效载荷)加密负载,因此隧道中的NAT将无法查看加密的IP地址和TCP/UDP端口,从而处理不同的VPN站点。
基于MPLS的VPN
第二层:PWE3
MPLS基于第二层的站点到站点VPN示例。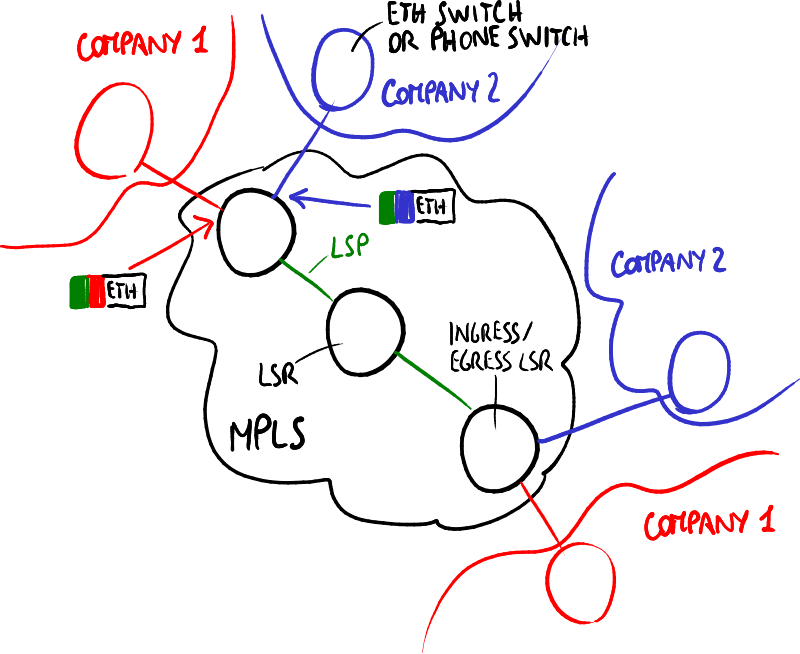
伪线仿真端到端(PWE3)标准允许在MPLS网络上仿真物理线路,以便在第二层终端(如以太网交换机或电话交换机)之间交换以太网帧。这种类型的连接对以太网帧的延迟有一定要求,就像它们通过物理线路传输一样。
流量通过LSP传输,然后需要能够到达通过入口/出口LSR连接的多个站点之一:
- 外部标签:标识两个入口/出口LSR之间的LSP,并且它后面跟着多个内部标签之一;
- 内部标签:标识公司VPN隧道,入口/出口LSR使用它将帧从其接口之一发送到公司站点。
基于MPLS的第二层VPN没有充分利用MPLS的所有优势,因为流量工程的路由协议与IP非常兼容 → 通常,LSP是手动配置的。
第三层:BGP
MPLS/BGP基于第三层的站点到站点VPN示例。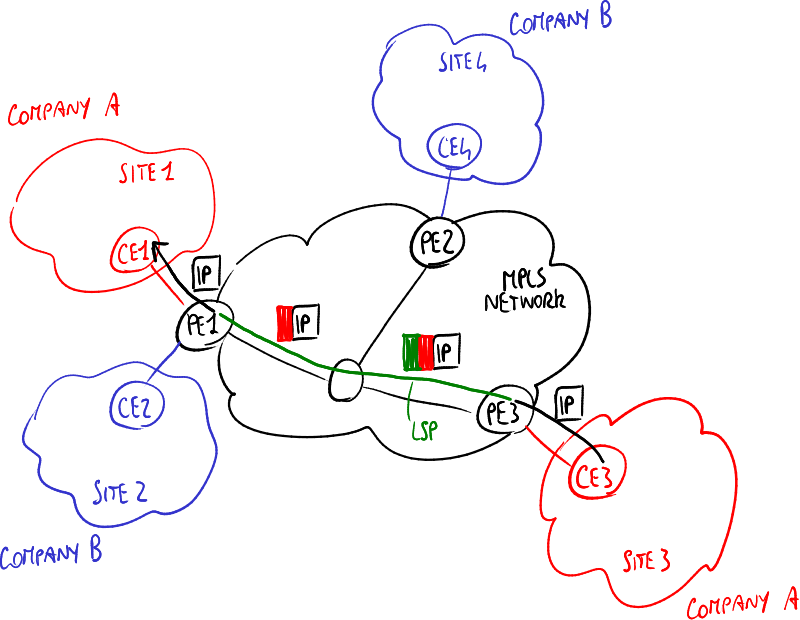
边界网关协议(BGP)被扩展为内部BGP和外部BGP,以支持通过MPLS部署VPN,例如公司A的站点1:
- 公司A的CE1通过内部BGP向PE1广告站点1内的目的地址,即告诉PE1站点1内所有可以到达的IP地址;
- PE1为CE1的每个IP地址分配一个标签,并将映射记录到特定于其端口的VPN路由和转发(VRF)表中;
- PE1通过外部BGP将选择的标签广告到其他PEs,发送包含每个IP地址及其地址族标识符的路由分隔符的数据包,实际是指向公司A站点的端口,方便在两个不同公司网络中有相同私有地址时使用。
此步骤需要手动执行:系统管理员必须在PE1与MPLS网络中的每个其他PE之间建立对等会话; 其他PE可以处理广告消息或忽略它们:
- 与公司A站点连接的每个PE(如图中的PE3)将PE1的广告信息记录到其VRF表中,即记录站点1内每个IP目的地的标签,换句话说,记录与站点1地址族关联的IP地址,以及PE1的IP地址;
- 没有连接公司A站点的每个PE(如图中的PE2)将直接忽略PE1的广告信息。
一旦PE之间的IP目的地址被广告出去,VPN数据就可以开始沿着MPLS LSP发送,例如从公司A的CE3到公司A的CE1:
- 作为入口LSR的PE3将两个标签压入标签栈:
- 内部标签:先前由PE1广告的标签;
- 外部标签:通过MPLS标签绑定、分发和映射协议为从PE3到PE1的LSP确定的标签;
- 中间LSR不关心内部标签,而是仅在LSP沿途操作外部标签;
- 在PE1之前的最后一个LSR去除外部标签(倒数第二个标签弹出),然后将数据包发送到PE1;
- 作为出口LSR的PE1在其VRF表中查找内部标签,并找到将数据包发送到的端口,随后去除内部标签并将数据包发送到CE1。
优点
这种解决方案非常具可扩展性:
- 每个中间LSR只需要处理与PE数量相同的LSP,而不是与IP目的地数量相同;
- 每个PE只需要处理与其连接的站点数量相同的VRF表。
缺点
PE之间的对等会话需要手动配置。
该解决方案不提供任何加密,因为它是由服务提供商提供的,企业需要信任服务提供商。
第三层:虚拟路由器
在使用虚拟路由器的基于MPLS的VPN中,每个PE为与其连接的每个公司运行一个(虚拟)路由器实例,因此每个实例只处理一个公司网络 → 协议更简单,因为它只处理一个VPN,但可扩展性较低,因为路由器实例需要手动配置。
MPLS/虚拟路由器基于第三层的站点到站点VPN示例。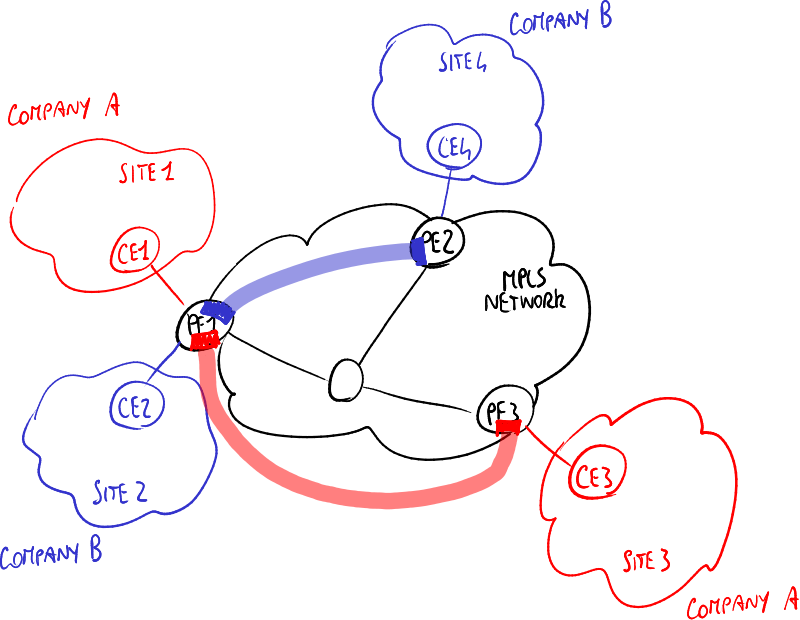
SSL(伪)VPN
SSL可用于创建站点到站点和访问VPN,但它主要用于SSL(伪)VPN,通过基于TCP/UDP的隧道为服务(如Web服务、电子邮件)提供安全访问。SSL(伪)VPN的主要优点是它们在任何网络场景中都有很好的兼容性,不会遇到穿越NAT、防火墙或路由器的问题,SSL服务还可以通过HTTPS被Web浏览器访问。
与替代解决方案的比较
与IPsec的比较
优点
SSL比IPsec在以下方面更方便:- 使用:IPsec有太多选项需要配置和管理,而SSL只需要将应用程序与实现SSL的库一起编译;
- 安全性:SSL工作在应用层 → 攻击SSL只涉及应用程序,而不会影响整个操作系统;
- 成熟度:它已经使用了很多年,经过了多个版本 → 代码中的错误很少;
- 兼容性与NAT穿越:
- SSL位于传输层之上,因此不会认证IP头部;
- 不像IPsec ESP那样加密端口。
缺点
SSL对DoS攻击很敏感:数据包总是需要处理到传输层,而IPsec在网络层就会丢弃它们。与PPTP的比较
SSL克服了一些PPTP的问题:
- 与非微软平台的互操作性差;
- 一些网络管理员可能会配置路由器阻止GRE,PPTP就是基于GRE协议的,因为他们不喜欢源路由特性。
SSL(伪)VPN的不同类型
-
Web代理
Web服务器不支持HTTPS → 在公司网络边缘,‘VPN网关’通过HTTP从Web服务器下载网页,并通过HTTPS将其传输到公司网络外的用户。 -
端口转发
客户端运行支持应用协议(如FTP、SMTP、POP3)的应用程序 → 客户端上安装的端口转发器将发送到特定端口的应用程序协议数据包转换为HTTPS数据包并通过其他端口发送,反之亦然。 -
应用程序翻译
Web服务器是支持应用协议(如FTP、SMTP、POP3)的应用服务器 → ‘VPN网关’通过端口转发机制将HTTPS转换为应用协议,反之亦然。 -
SSL协议的应用
一些应用协议可以原生集成SSL(如SMTP-over-SSL、POP-over-SSL) → 客户端和Web服务器可以直接安全通信,无需‘VPN网关’翻译。 -
应用程序代理
客户端使用SSL协议的应用,但Web服务器不支持 → 仍然需要‘VPN网关’进行端口转发机制。 -
网络扩展
客户端和Web服务器都不支持SSL → 需要两个‘VPN网关’,一个在用户端,另一个在Web服务器端,因此SSL隧道在这两个‘VPN网关’之间创建。
-
///////////////////////////////////////
基于IP的语音(VoIP)
VoIP(Voice over IP,语音传输协议)是指通过IP网络传输语音电话和多媒体数据的技术。
电路交换与分组交换
电路交换电话网络 在传统的电路交换电话网络(POTS)中,语音是通过分配静态电路传输的,语音以64 Kbps的比特率进行采样(根据采样定理)。使用这种网络存在一些限制:
- 无压缩:由于每个电话通话分配了64千比特的带宽,压缩数据是没有意义的;
- 必须分配整数个电路:以支持多媒体或多信道通信;
- 无静音抑制:即使在停顿时,语音样本也会被传输,电路继续占用;
- 无统计复用:无法根据多个通话的当前需求动态共享带宽;
- 信令程序:需要用于电路分配(例如响铃音、忙音、空闲音等)。
分组交换数据网络 在分组交换数据网络(IP网络)中,语音通过数据包动态传输,这使得一些新特性成为可能:
- 更好的压缩:减少数据包的数量;
- 高质量通信:比特率不再限制为64 Kbps;
- 静音抑制:停顿期间不会传输数据包;
- 统计复用:带宽分配更为灵活;
- 无需静态资源分配:信令程序不再分配静态资源;
- 灵活性:用户在移动时,仍可以通过相同的电话号码或账户联系。
然而,引入了一个新问题:在分组交换网络中,无法真正保留资源 → 很难保证语音通话的服务质量,因为数据包可能会有延迟或丢失:
- 延迟:国际电信联盟(ITU)定义了一些端到端延迟的参考值:
- 0-150毫秒:对人耳来说是可以接受的;
- 150-400毫秒:仅对跨洲通话可接受;
-
400毫秒:不可接受,会影响通话质量;
- 丢包:人耳可以容忍最多5%的丢包率而不会有明显问题。
TCP与UDP
UDP和TCP数据包(理论上)会同时到达接收方,唯一的区别是TCP必须等待确认数据包 → 因此UDP是最自然的选择。实际上,Skype通常使用TCP,因为它能够更容易穿越NAT和防火墙,尽管有时会因滑动窗口机制发生短暂的静音。
从电路交换到分组交换的迁移
传统的电路交换网络(POTS)可以逐步迁移到基于IP的分组交换网络:
- 基于电话的IP网络(ToIP):网络边缘的终端仍以电路交换方式工作,但网络骨干基于IP并内部执行数据包化处理 → VoIP的使用对用户是透明的,额外的多媒体服务对终端用户不可用。
- 新的电信运营商可以将其电话网络建设为ToIP网络 → 电信运营商可以通过构建和维护单一的集成基础设施节省成本;
- 混合网络:部分终端为VoIP,部分仍为传统终端;
- IP网络:所有终端均为VoIP,但智能网络服务(例如免付费电话)仍为传统形式,因为它们工作得非常好,网络运营商不愿意进行现代化改造;
- 仅IP网络:所有终端均为VoIP,所有智能网络服务也都通过IP工作。
网关
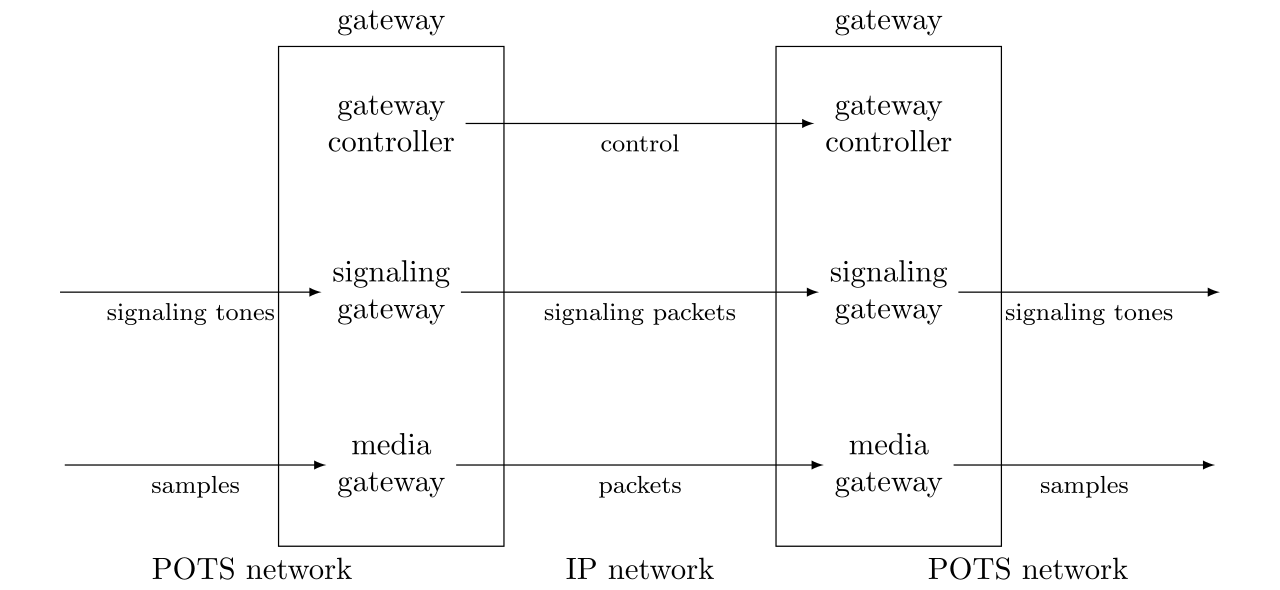
网关是一种设备,用于将POTS网络与IP网络连接起来。它由三个组件组成:
- 媒体网关:能够将POTS网络中的语音样本转换为IP网络中的数据包,反之亦然;
- 信令网关:能够将POTS网络中的信号音转换为IP网络中的信令数据包,反之亦然;
- 网关控制器:负责监督和监控整个网关,控制流量质量,执行授权和认证(如计费),定位目的地等。仅网关控制器在仅IP网络中仍然有用。
VoIP流程的创建步骤
发送端:
接收端应该执行以下步骤:
- 采样
- 编码
- 数据包化
- 排队
- 传输
采样 采样将模拟信号的语音转换为数字样本。采样具有灵敏度(比特数)、采样频率(赫兹=1/秒)和理论比特率(比特/秒)等特征。
编码 编码技术用于减少比特率,但它们可能由于编码算法引入额外的延迟。
主要的编码技术有:
- 差分编码:每个样本是基于与前一个样本或后一个样本的差异来编码的;
- 加权编码:在视频通话中,与周围环境相比,应该对说话者的图像使用更高的比特率进行编码;
- 有损编码:一些音频和视频信息会被不可逆地移除(可能质量的损失不会被人耳察觉)。
当编码算法必须在移动终端(如嵌入式系统或低功耗设备)上执行时,复杂性是一个重要问题。此外,一些服务不支持有损压缩编码的数据:例如,传真不支持质量损失。因此,电信运营商仍然倾向于使用PCM64编解码器,它具有恒定的64 Kbps比特率:这种方式需要较少的处理功率,并且传真和其他电话网络服务也支持这种方式。
说话者的声音,在通过接收端扬声器后,可能会通过接收端麦克风反向传回,并在经过一段时间的延迟后传输到发射端扬声器,这种延迟叫做回程延迟,如果延迟显著,可能会干扰说话者本人 → 回声消除技术旨在避免说话者听到自己的声音。
数据包化
数据包化延迟取决于每个数据包插入的样本数,这是延迟与效率之间的权衡:
- 延迟:如果在一个数据包中插入太多样本,数据包就需要等到最后一个样本才会发送 → 如果太多样本被打包在一起,第一个样本的到达将会有显著延迟;
- 效率:每个IP数据包都有由其头部带来的大小开销 → 如果数据包中插入的样本过少,头部开销将显著增加比特率。
一些基于冗余的错误校正技术可能会被采用:每个数据包不仅携带当前样本,还携带前一个样本,这样如果前一个数据包丢失,仍然可以恢复该样本。
排队
当输入流量超过输出链路的容量时,路由器应该存储等待传输的数据包(缓冲) → 这会增加延迟和抖动。优先级队列管理可以解决这些问题:计算机网络技术与服务/服务质量。
传输
为减少传输延迟,可以考虑以下解决方案:
- 增加带宽,但ADSL提供商通常更关注增加下行带宽;
- 使用PPP交织,即将一个大帧拆分为多个小的PPP帧,但并非所有提供商都实现了PPP交织;
- 在语音通话期间避免使用其他应用程序(如数据传输)。
接收端
接收端应该执行以下步骤:
- 去抖动:去抖动模块应以生成语音时使用的相同速度播放数据包;
- 重新排序:由于是分组交换,网络可能会传递乱序的数据包 → 需要一个模块来重新排序;
- 解码:解码算法应实施一些技术:
- 丢失的数据包应使用预测技术进行处理,通过插入白噪声或播放最后一个接收到的数据包的样本来填补;
- 静音抑制:接收方在对话的停顿期间引入白噪声,因为完美的静音会被用户感知为通话故障。重要的是,能够在说话者恢复讲话时立即停止白噪声。
RTP(实时传输协议)
RTP用于通过UDP传输VoIP流。
特性
-
本地多播传输
RTP允许即使在不支持多播的网络上进行多播传输。实际上,IP支持多播,但它要求网络提供商配置其网络设备以创建每个VoIP流的多播组 → RTP允许在应用层上以即插即用的方式进行数据多播,而无需网络提供商干预。 -
只包含基本特性
RTP不指定应该由底层协议管理的特性,如数据包碎片化和传输错误检测(校验和)。 -
数据格式独立性
RTP只包括“Payload Type”(有效负载类型)字段,以指定数据包内容的类型和所使用的编解码器,但不指定如何编码数据以及使用哪些编解码器(这些信息由“音视频配置文件”文档单独指定)。不能将世界上每个编解码器与一个代码关联 → 发送方和接收方应在会话设置期间就使用的编解码器代码达成一致,并且这些代码仅在该会话内有效。 -
实时数据传输
丢包是允许的 → “序列号”和“时间戳”字段组合在一起,以便在丢包的情况下,在正确的时间点重新启动音频/视频的播放。 -
流区分
多媒体会话需要为每个多媒体流(音频、视频、白板等)打开一个RTP会话,即一个UDP连接。
RTP控制协议(RTCP)
RTCP用于执行连接监控和控制:接收端收集一些统计数据(例如丢包、延迟等信息),并定期将其发送给源端,以便源端根据当前网络能力调节多媒体流的质量,从而尽可能确保服务的正常运行。例如,接收方可以判断某个编解码器的比特率过高,超出了网络的支持能力,因此可以切换到比特率较低的编解码器。
非标准端口
RTP没有定义标准端口 → 由于没有固定的端口,RTP数据包很难被防火墙和服务质量管理工具检测到。然而,一些实现使用静态端口范围,以避免在防火墙上打开过多端口,并简化服务质量的标记。
多播传输
传统方案
单播主机:
发送方:N-1流; 接收方:N-1流;
接收方:N-1流;
多播主机:
发送方:1流; 接收方:N-1流。
接收方:N-1流。
没有RTP混音器的传统解决方案始终需要所有主机具有较高的带宽能力。在WebRTC上下文中,这种模式称为选择性转发单元(SFU)。
RTP混音器
RTP混音器是一种能够操控RTP流进行多播传输的设备:例如,在视频会议中,混音器会将来自其他主机的流混合成一条流,发送给每个主机。
带有混音器的单播主机:
发送方:1流; 接收方:1流。
接收方:1流。
每个主机传输和接收单一流
每个主机仅传输和接收一个流 → 混音器用于节省带宽:即使是带宽较低的主机也可以加入视频会议。混音器应该是具有最高带宽能力的主机,以便能够接收来自其他主机的所有流,并将所有流传输给其他主机。在WebRTC中,这种模式被称为多点控制单元(MCU)。
RTP头部
RTP头部具有以下格式:
2 3 4 8 9 16 32 V P X CC M Payload Type Sequence Number Timestamp Synchronization source identifier (SSRC) Contributing source identifier (CSRC) ::: 其中,最重要的字段是:
- CSRC Count (CC) 字段(4位):指定“CSRC”字段中的标识符数量;
- Marker (M) 标志(1位):用于标记数据包的优先级,表示高优先级或低优先级,以便进行服务质量管理;
- Payload Type (PT) 字段(7位):指定数据包有效负载的类型,通常包含与所使用编解码器对应的代码;
- Synchronization source identifier (SSRC) 字段(32位):标识RTP混音器(例如,下面的混音器M);
- Contributing source identifier (CSRC) 字段(可变长度):标识为多播流做出贡献的多个源(例如,下面的源S1、S2、S3)。
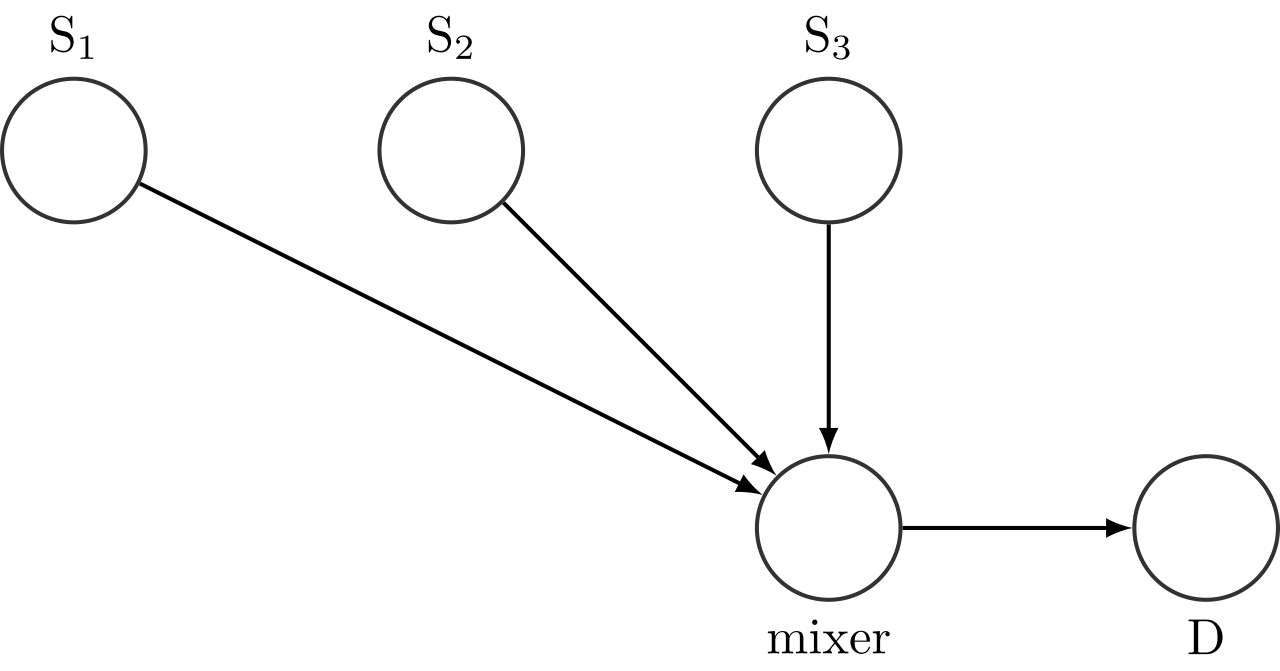
示例:来自源S1、S2、S3的语音被混合成一个流,传送到目标D。
H.323
H.323是由ITU标准化的一种应用层信令协议套件。它是一个非常复杂的标准,因为它继承了电信运营商的逻辑。
H.323网络组件
H.323网络示例。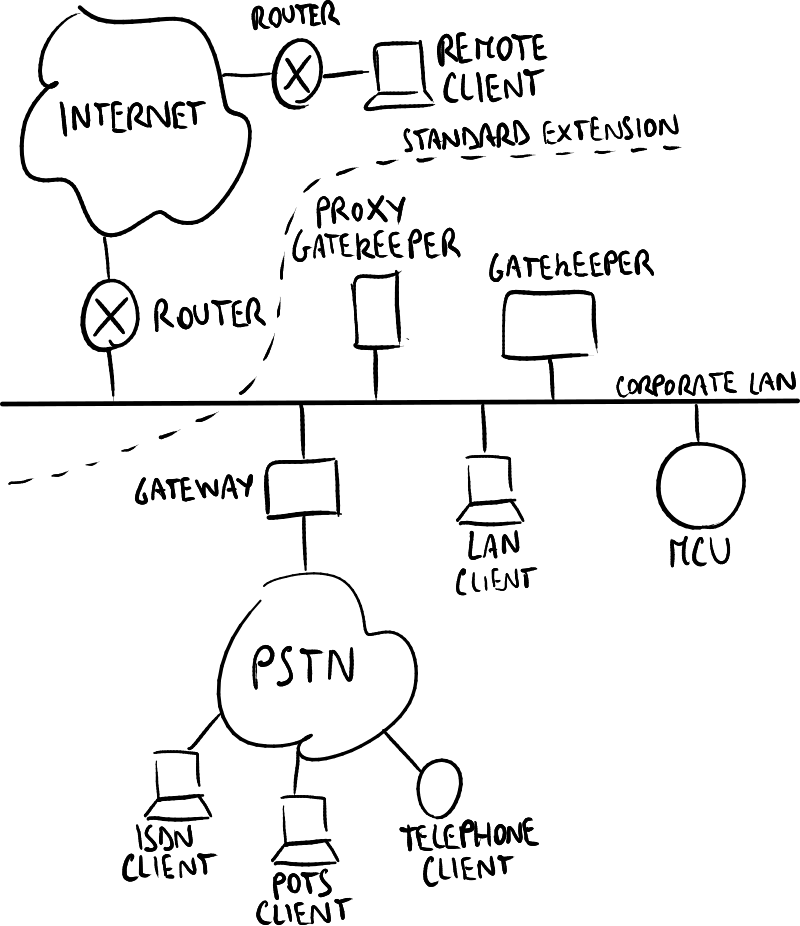
H.323最初是为了允许连接到公司局域网(LAN)的主机与通过传统电路交换网络(PSTN)连接的远程设备进行通信(音频、视频、共享白板等)而开发的:
- Gatekeeper:实现网关控制器,负责认证和定位用户,记录注册用户等;
- Proxy Gatekeeper:客户端通过代理网关与网关联系 → 这减少了低功耗客户端设备的工作量,但不是强制性的;
- Multipoint Control Unit (MCU):实现RTP混音器;
- Gateway:实现信令网关和媒体网关,翻译数据通道、控制通道和信令程序,连接局域网和PSTN,且在局域网中视为H.323终端,在PSTN中视为电话终端。
后来,H.323标准被扩展到广域网(WAN),使得通过互联网与远程用户的通信成为可能。
Gatekeeper的区域
Gatekeeper的区域由它管理的终端集合组成。一个区域可能涉及多个网络层,例如多个通过路由器隔开的局域网。
H.323协议架构
H.323 protocol stack.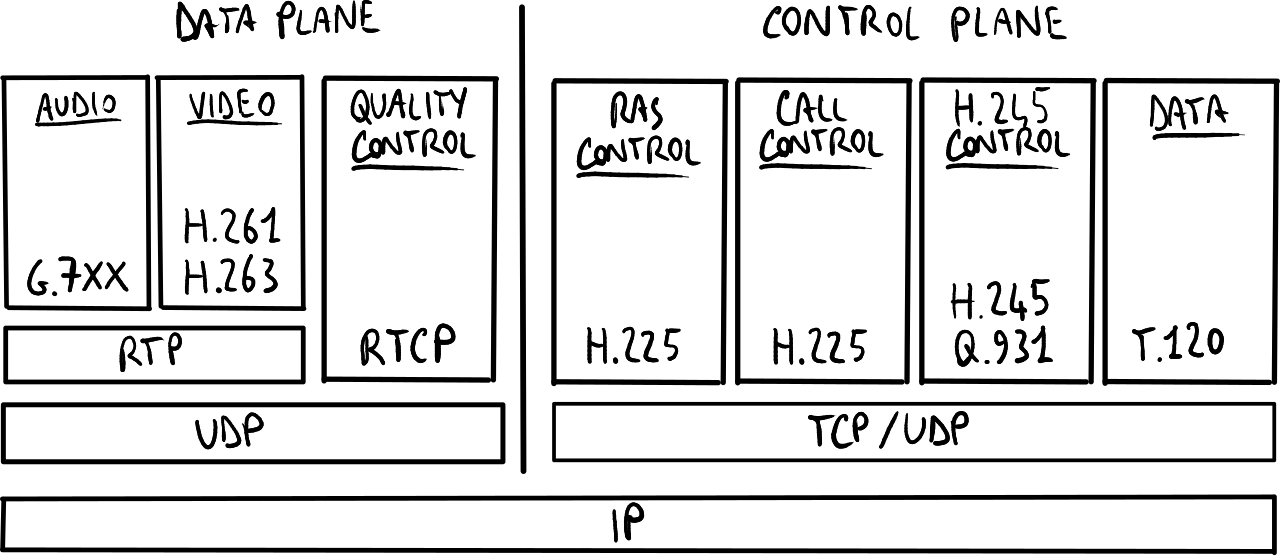 Block diagram of an H.323 terminal.
Block diagram of an H.323 terminal.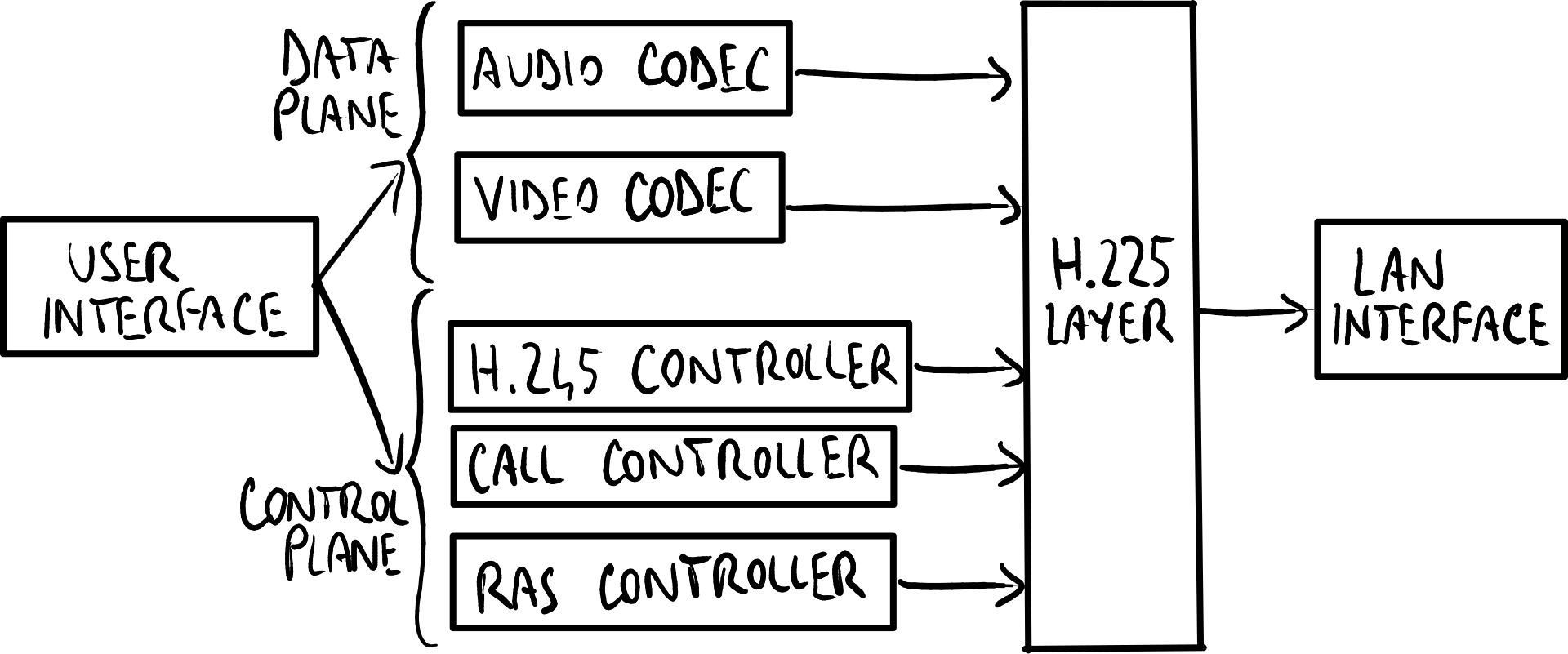
H.323协议栈比较复杂,因为它由多个协议组成:
- 数据平面:包括RTP和RTCP协议,位于UDP上;
- 控制平面:包括位于TCP/UDP上的信令协议:
- RAS控制器:允许终端与Gatekeeper交换控制消息:
- 注册消息:终端请求Gatekeeper加入区域;
- 许可消息:终端请求Gatekeeper联系另一个终端;
- 状态消息:终端告诉Gatekeeper自己是否处于活动状态;
- 带宽消息:RAS控制器通知Gatekeeper带宽变化,以便在链路过载时拒绝新的呼叫;
- Call控制器:允许终端与另一个终端交换控制消息;
- H.245控制器:允许两个终端协商编解码器等参数;
- 数据控制:允许终端发送控制消息用于桌面共享或其他多媒体数据流。
- RAS控制器:允许终端与Gatekeeper交换控制消息:
最终,H.225层将所有消息组合在一起:它创建一种可靠的虚拟隧道,允许通过不可靠的IP网络发送H.323消息,模拟电路的可靠性。
地址分配
每个终端通过一个**(IP地址, TCP/UDP端口)**对唯一标识,因此可以通过地址/端口对直接联系,无需通过Gatekeeper。
如果存在Gatekeeper,地址/端口对可以映射为更容易记住的别名(例如,name@domain.com、E-164电话号码、昵称)。由于这些别名与用户账户相关联,它们启用了便携性:用户即使更改IP地址,仍然可以通过同一号码联系到他。
H.323呼叫的主要步骤
H.323呼叫包括六个主要步骤:
- 注册:呼叫方终端在其区域内查找Gatekeeper,并通过RAS控制建立RAS通道;
- 呼叫设置:呼叫方终端通过Call控制与被呼叫方终端建立通道;
- 协商:使用H.245控制协议协商带宽和编解码器等参数;
- 数据传输:通过RTP传输语音;
- 关闭:使用H.245控制协议关闭数据通道;
- 拆除:使用RAS控制协议关闭RAS通道。
Gatekeeper可以扮演两个角色:
- Gatekeeper路由呼叫:呼叫总是通过Gatekeeper进行 → 这对于NAT穿越很有用:Gatekeeper充当中继服务器;
- Gatekeeper直接端点:呼叫直接到达端点,但首先呼叫方和被呼叫方客户端应与Gatekeeper进行许可步骤,用于计费和带宽管理。
主要问题与批评
- H.323标准未提供容错支持,因为它仅考虑了单一的Gatekeeper → 各个厂商开发了自己的定制功能来提供此类功能,但它们彼此之间不兼容;
- H.323标准不支持不同区域之间的通信 → 一家公司无法与另一家公司合并其区域;
- 消息使用ASN.1格式进行编码:这种格式非文本,因此调试非常困难,并且需要处理低级别的机器细节(例如,小端存储);
- 协议栈由多个协议组成,每个功能对应一个协议。
SIP(会话发起协议)
SIP(Session Initiation Protocol)是一个由IETF通过RFC标准化的应用层信令协议。如今,SIP的普及速度远超过H.323,主要得益于其遵循互联网哲学(“保持简单”)的方式:例如,它使用基于文本的方式(如HTTP),因此编码容易理解。SIP的交互方式是客户端-服务器。
特性
SIP protocol stack.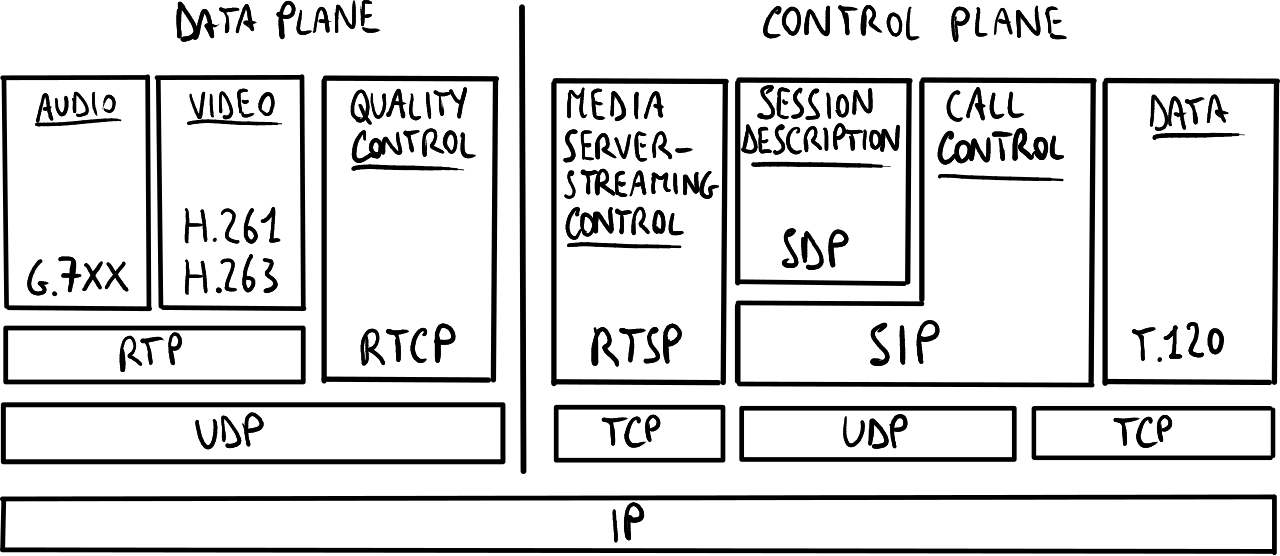
SIP协议栈。
SIP协议栈比H.323的协议栈更简洁,因为SIP在控制平面中只有一个通用层。SIP仅涵盖信令功能:它将与信令无关的方面,如带宽管理,交给其他已有协议,从而减少了设计的复杂性:
- RTP/RTCP:用于传输和控制多媒体流;
- SDP:用于通知多媒体流的控制信息;
- RTSP(实时流协议):类似RTP的协议,用于处理实时流和其他类型的资源(例如,为语音邮件快速转发已录制的语音消息);
- RSVP:用于在IP网络上保留资源,尝试在分组交换网络上构建类似电路交换网络的机制。
SIP可以在以下三种可能的传输层中运行:
- UDP:无需维持TCP连接,适用于低功耗设备;
- TCP:提供更多可靠性,适用于NAT穿越和穿越防火墙;
- TLS(带SSL的TCP):消息加密以提高安全性,但会丧失文本消息的优点。
SIP为语音通话提供一些主要服务:
- 用户定位:定义呼叫的目标终端;
- 用户容量:定义所使用的媒体(音频、视频等)和参数(编解码器);
- 用户可用性:定义被呼叫方是否愿意接听电话;
- 呼叫设置:建立连接并设置所有参数;
- 呼叫管理。
SIP信令不仅可用于语音呼叫,还可用于多种附加服务:电子出席(用户状态:可用、忙碌等)、即时消息、白板共享、文件传输、互动游戏等。SIP支持便携性:每个用户都有一个与其关联的帐户,因此即使用户移动并更改IP地址,仍然可以联系到他。
SIP网络组件
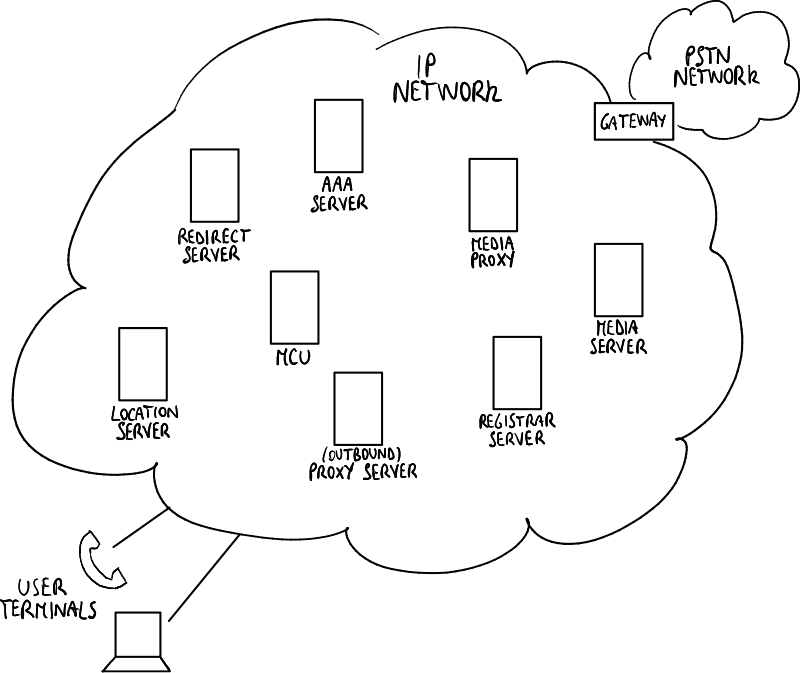
- 终端:每个主机既是客户端又是服务器(为了使其可达)。
- 注册服务器:负责跟踪主机与IP地址之间的映射。它实现了Gatekeeper:主机必须注册才能进入SIP网络。
- 代理服务器:管理主机与其他服务器之间消息的交换。主机可以选择仅与代理服务器通信,将SIP呼叫所需的所有任务委托给代理服务器。
- 重定向服务器:用于重定向来电(例如,用户只希望在工作时间接听工作手机)。
- 媒体服务器:用于存储增值内容(例如,语音信箱)。
- 媒体代理:可以作为防火墙穿越的中继服务器。
- 位置服务器:用于定位用户。当主机想要拨打电话时,首先请求位置服务器查找目标用户地址。
- AAA服务器(认证、授权、计费):注册服务器与AAA服务器交换消息以验证用户(例如,检查用户是否有权限进入网络)。
- 网关:连接IP网络和PSTN网络,通过转换SIP数据包和样本,进行双向通信。
- Multipoint Control Unit (MCU):实现RTP混音器,功能与H.323中的相同。
在许多情况下,一台机器(称为SIP服务器或SIP代理)实现了注册服务器、代理服务器、重定向服务器和媒体代理的功能。此外,位置服务器通常位于DNS服务器中,AAA服务器通常位于企业的AAA服务器中。
计费和域
每个用户都有一个SIP帐户,因此即使他移动并更改IP地址,仍然可以联系到他(便携性)。帐户地址的格式为
username@domain.com;电话终端也可以具有SIP地址,格式为telephone_number@gateway。SIP网络具有分布式架构:每个SIP服务器负责一个SIP域(相当于H.323中的区域),所有引用同一SIP服务器的主机属于同一SIP域,并且在其帐户地址中具有相同的域名。与H.323不同,SIP用户可以联系属于其他SIP域的用户:他们的SIP服务器将负责与另一个用户的SIP服务器进行通信。
假设一个属于Verizon域的美国用户移居意大利并连接到Telecom Italia网络。为了保持可达性,他需要联系Verizon SIP服务器进行注册,但他正在使用Telecom Italia的网络基础设施 → 他需要通过Telecom Italia SIP服务器(作为出站代理服务器)进行漫游服务,从而Telecom Italia可以跟踪该用户的通话进行计费。
域间互联
为了互联不同的域,需要确保所有的注册服务器可以被找到,因为它们存储着账户别名和IP地址之间的映射 → 在DNS服务器中需要两个附加记录来定位注册服务器:
- NAPTR记录:定义指定域可以使用的传输协议,指定用于SRV查询的别名;
- SRV记录:指定注册服务器的别名,用于A/AAAA查询,并指定指定传输协议的端口;
- A/AAAA记录:指定指定注册服务器别名的IPv4/IPv6地址。
DNS记录表可能包含多个SRV/NAPTR记录:
- 多个NAPTR记录:指定传输协议可用的多个注册服务器,“Preference”字段指定首选顺序;
- 多个SRV记录:指定可用的多个传输协议,“Priority”字段指定顺序(优先顺序为:TLS/TCP、TCP、UDP)。
SIP协议相关内容
可能不包含SRV/NAPTR记录:
- 没有NAPTR记录:主机仅尝试SRV查询(通常是UDP),并使用第一个SRV响应对应的传输协议;
- 没有SRV记录:注册服务器的地址必须静态配置在主机上,主机将使用标准端口5060。
ENUM标准
如何在传统电话上输入账户地址以联系SIP用户?每个SIP账户默认关联一个称为E.164地址的电话号码:
- 用户在传统电话上输入电话号码;
- POTS网络与SIP网络之间的网关将电话号码转换为带有固定域名
e164.arpa的别名,并查询DNS以检查是否存在NAPTR记录:- 如果DNS服务器找到NAPTR记录,则电话号码与SIP账户相关联,呼叫将被转发到目标SIP代理;
- 如果DNS服务器未找到NAPTR记录,则该电话号码对应POTS网络中的用户。
SIP消息
每个SIP消息具有以下文本格式:
- 消息类型(一行):指定消息类型;
- SIP头:包含有关多媒体流的信息;
- 空行(类似HTTP的行为);
- SDP消息(有效载荷):包含有关多媒体流的控制信息。
主要消息类型
SIP消息可以是以下几种类型之一,包括:
- REGISTER消息:用于向域注册,可以通过多播发送到所有注册服务器;
- INVITE消息:用于建立电话呼叫;
- ACK消息:这是SIP消息中的最后一条消息,标志着RTP流的开始;
- BYE消息:用于结束电话呼叫;
- CANCEL消息:用于取消挂起的呼叫设置请求;
- SUBSCRIBE, NOTIFY, MESSAGE消息:用于电子出席和即时消息;
- 代码消息:包括:
- 1xx = 临时代码:指示操作正在进行中(例如,100 Trying,180 Ringing);
- 2xx = 成功代码:指示成功的操作(例如,200 OK);
- 4xx = 客户端错误代码:指示错误的操作(例如,401 Unauthorized)。
SIP头中的主要字段
SIP头可以包含多个字段,包括:
- From字段:包含希望发起呼叫的终端的SIP地址;
- To字段:包含呼叫者希望联系的终端的SIP地址;
- Contact字段:SIP服务器用于指定被呼叫方终端的IP地址,呼叫者终端可以直接联系被呼叫方终端;
- Via字段:用于跟踪消息应该通过的所有SIP服务器(例如,出站代理服务器);
- Record Routing字段:指定是否所有SIP消息都应该通过代理服务器,这对于NAT穿越非常有用;
- Subject字段:包含SIP连接的主题;
- Content-Type、Content-Length、Content-Encoding字段:包含关于有效载荷类型(例如SDP的MIME格式)、长度(以字节为单位)和编码的信息。
SDP
SDP(会话描述协议)是一种基于文本的协议,用于描述多媒体会话:包括多媒体流的数量、媒体类型(音频、视频等)、编解码器、传输协议(例如RTP/UDP/IP)、带宽、地址和端口、每个流的开始/结束时间、源标识等。
SDP包含在SIP数据包的有效载荷中,用于通知有关多媒体流的控制信息(例如,携带电话呼叫邀请消息的SIP消息也需要通知使用哪个编解码器)。由于SDP设计于较早时,因此它包含一些对于SIP来说没有用的特性(例如每个流的开始/结束时间),但是SIP只是直接采用了SDP,而没有对其做任何修改以便重用现有软件。
SDP消息格式
每个SDP消息由一个会话部分和一个或多个媒体部分(每个多媒体流一个)组成:
- 会话部分:以
v=开始,包含当前会话中所有多媒体流的参数; - 媒体部分:以
m=开始,包含当前多媒体流的参数。
SIP呼叫过程的步骤
SIP呼叫分为四个步骤:
- 注册:呼叫者终端向域进行注册;
- 邀请:呼叫者终端请求建立呼叫;
- 数据传输:通过RTP传输语音;
- 拆除:结束呼叫。
注册步骤
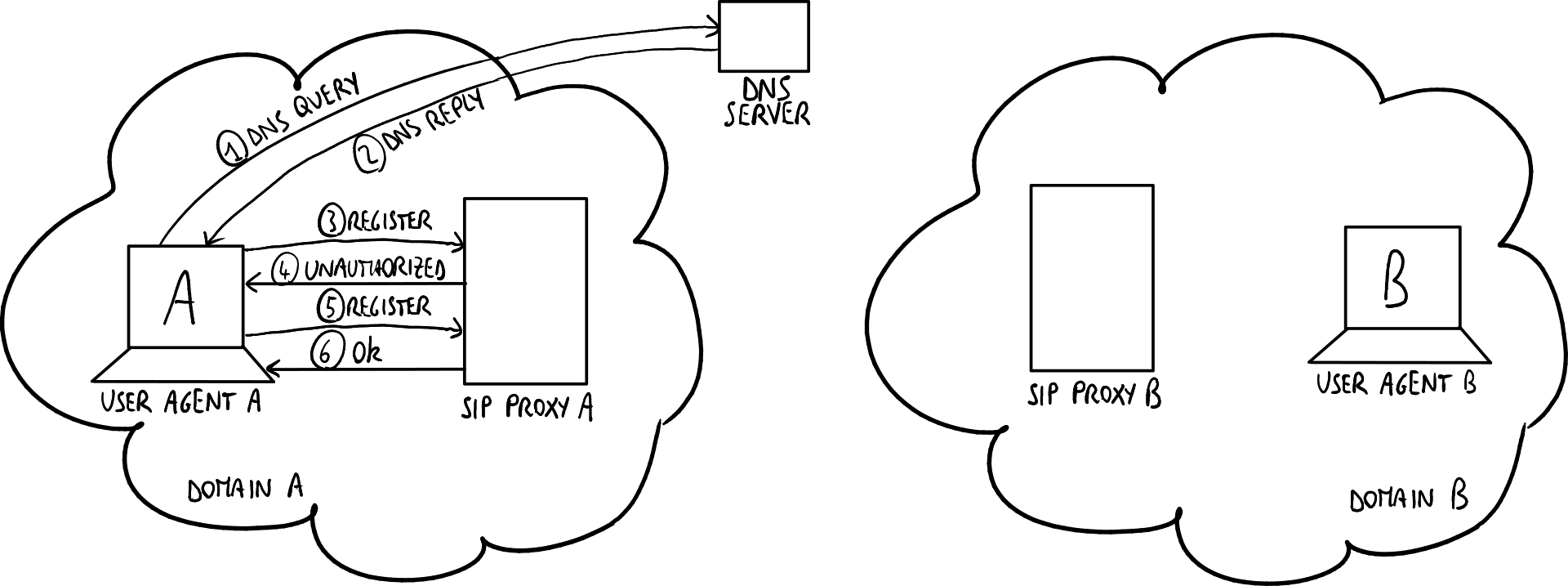
用户代理A希望通过联系其SIP代理将自己注册到域A:
- DNS查询与回复(NAPTR、SRV、A/AAA):A向DNS服务器查询SIP代理的IP地址;
- REGISTER消息:A请求SIP代理进行注册,但此时未插入密码;
- 401 Unauthorized消息:SIP代理要求进行身份验证,插入一个每次注册都会变化的挑战;
- REGISTER消息:A基于挑战和密码计算哈希值,并将结果发送到SIP代理;
- 200 OK消息:注册服务器检查挑战的回复并授予用户访问权限。
邀请步骤
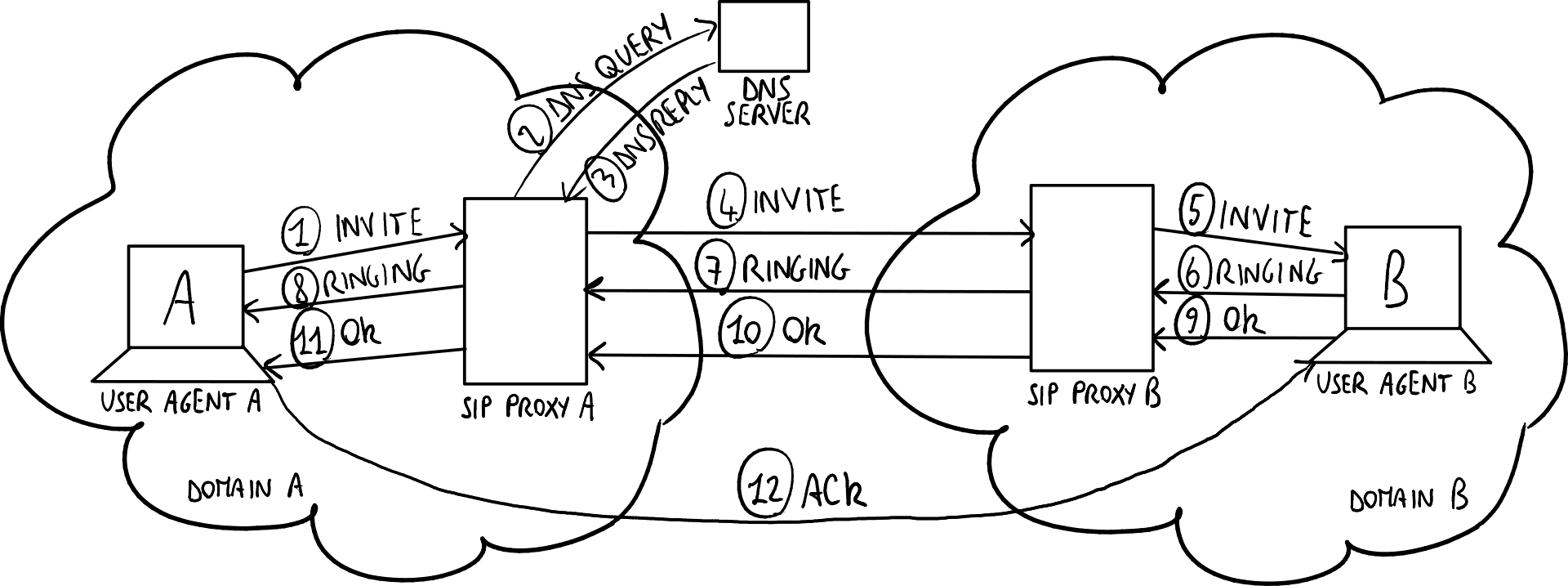
用户代理A希望通过B的SIP代理与用户代理B建立呼叫:
- A请求其SIP代理联系B,向其发送INVITE消息;
- A的SIP代理执行DNS查询以查找B的SIP代理IP地址(NAPTR、SRV、A/AAA);
- A的SIP代理向B的SIP代理发送INVITE消息;
- B的SIP代理向B发送INVITE消息;
- B通过SIP代理发送RINGING消息给A,使A的电话响铃;
- B接受呼叫,通过SIP代理发送OK消息给A;
- A通过SIP代理或直接根据Record Routing字段的值,通知B其已收到OK消息。
拆除步骤
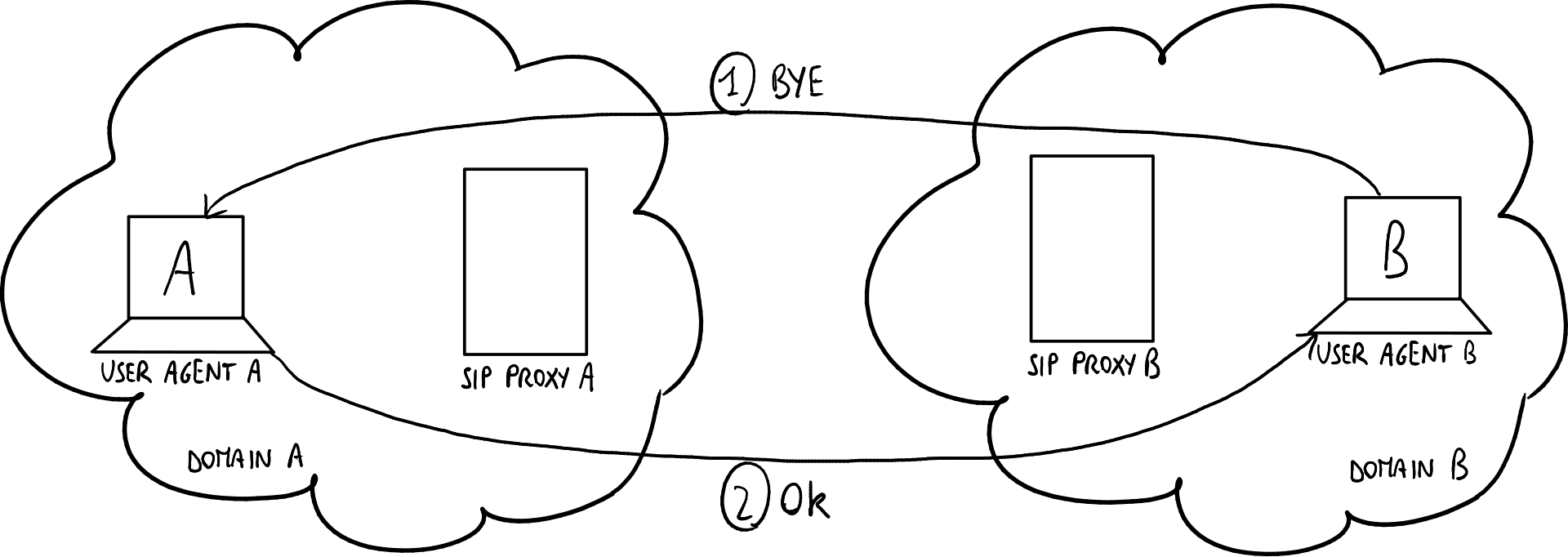
通话结束后,在关闭RTP流后:
- BYE消息:B通知A希望结束通话;
- OK消息:A通知B已收到BYE消息。
-
服务质量(Quality of Service, QoS)
服务质量是通过一系列技术手段来确保多媒体网络应用生成的非弹性流量满足特定的延迟和抖动要求。
主要方法
为服务质量提出了三种主要方法:
- 集成服务(IntServ):要求对网络基础设施进行根本性更改,以便应用能够预留端到端带宽 → 需要在主机和路由器中安装新的复杂软件;
- 区分服务(DiffServ):对网络基础设施的改动较少;
- 放任自流:不关心延迟和服务质量,认为网络永远不会拥塞 → 所有复杂性集中在应用层。
原则
- 包标记:路由器需要通过标记来区分不同的流量类别,并根据新的路由策略处理这些数据包。
- 提供保护(隔离):将某一类流量与其他流量隔离。
- 在提供隔离的同时,尽量高效地利用资源。
- 流量声明其需求(呼叫接纳),如果网络无法满足需求,则可能会拒绝该呼叫(例如,忙音)。
机制
数据包调度机制
调度机制的目标是管理进入数据包的优先级。
-
FIFO调度:实现简单且高效,但仅在有复杂丢包策略时有效:
- 尾丢包:始终丢弃到达的数据包;
- 随机丢包:随机丢弃队列中的一个数据包;
- 优先级丢包:丢弃最低优先级的数据包。
-
优先级调度:为每个类别提供一个缓冲区,并始终为最高优先级的类别服务。
这种方式无法保证隔离,可能会导致饿死现象:低优先级队列中的数据包永远不会被服务,因为高优先级数据包不断到达。此外,如果高优先级队列暂时为空,允许开始传输低优先级队列中的数据包,但如果高优先级数据包在传输开始后到达,该数据包将必须等待传输结束,尤其是在数据包较大的情况下 → 会引入传输延迟。
-
轮询调度:循环扫描各类队列,为每类队列提供一个服务(如果队列非空)。
这种方式能保证隔离并且公平,但不保证优先级。
-
加权公平队列(Weighted Fair Queuing):通过将轮询调度与优先级调度结合来对每类流量进行加权服务。
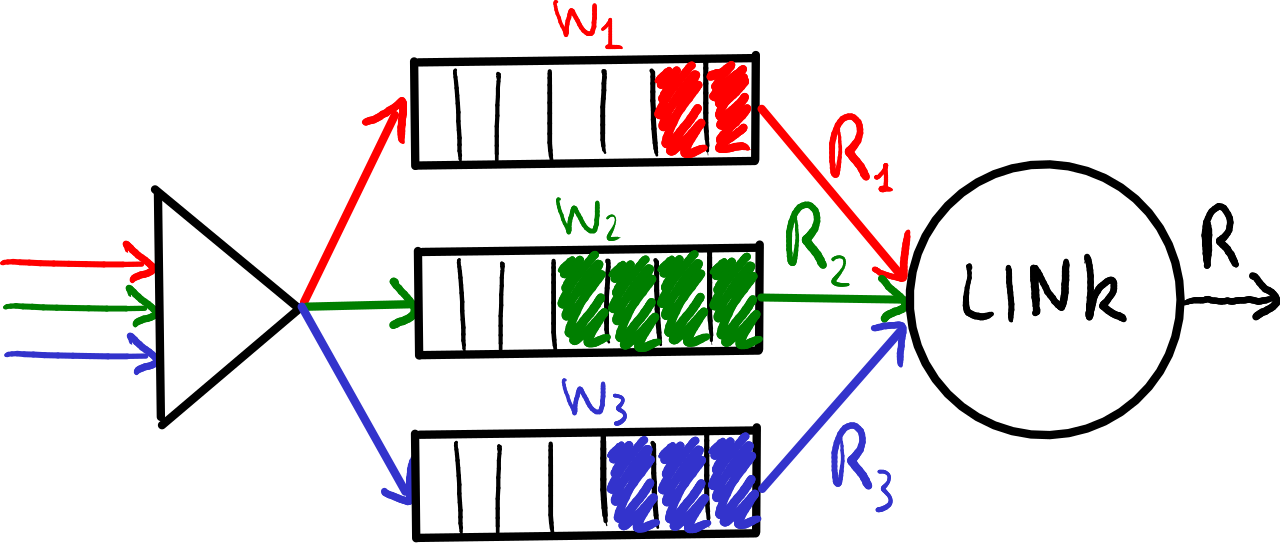
每个类别在每个周期中都会获得加权的服务量,带宽 RiR_i 对应于类别 ii(权重为 wiw_i)由以下公式给出(空队列的权重为零):
\(Ri=wi∑jwjRtotR_i = \frac{w_i}{\sum_{j} w_j} R_{tot}\)然而,这种解决方案的可扩展性不强,因为该公式需要为每一个数据包计算浮动运算。
流量控制机制
流量控制机制的目标是限制流量,以确保其不超过声明的参数,如:
- 长期平均速率:每单位时间可以发送多少数据包;
- 峰值速率:每分钟的数据包数;
- 最大突发大小:连续发送的最大数据包数(没有空闲间隔)。
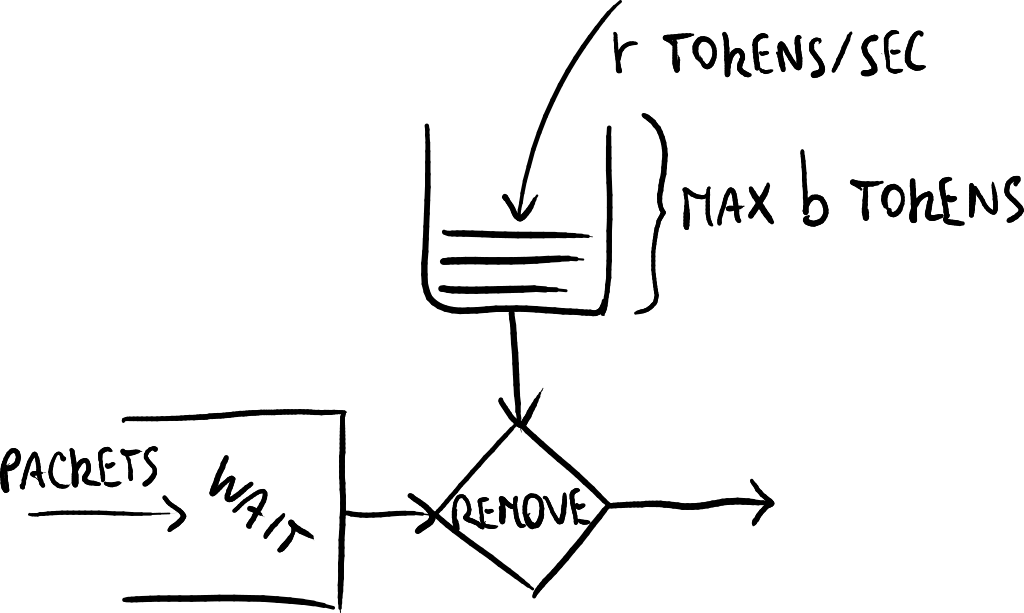
令牌桶(Token Bucket): 令牌桶是一种用于限制输入流量至指定突发大小和平均速率的技术:
- 桶中最多可持有 bb 个令牌;
- 令牌以速率 rr(每秒)生成,除非桶已满;
- 在时间间隔 tt 内,允许的数据包数量为 rt+brt + b。
集成服务(IntServ)
资源预留 主机请求一个需要资源的服务(路径消息):如果网络能够提供该服务,则会为用户提供,否则不会提供(预留消息)。 资源预留是IP协议中没有原生支持的功能。
呼叫接纳 到达的会话使用资源预留协议(RSVP)信令协议来声明:
- R-spec:定义请求的服务质量;
- T-spec:定义流量特性。
资源预留是由接收端而非发送端指定的。
然而,这种解决方案的可扩展性较差,且存在较大的问题,当前没有充分的理由去更好地实现集成服务。
区分服务(DiffServ)
区分服务(DiffServ)是一种由IETF提出的服务质量架构:它将复杂性(桶和缓冲区)从网络核心转移到边缘路由器(或主机),从而提高可扩展性。
架构 DiffServ架构由两大主要组件构成,负责每流量的管理:
- 边缘路由器:它们将数据包标记为“在配置文件内”(高优先级语音流量)或“在配置文件外”(低优先级数据流量);
- 核心路由器:根据边缘路由器的标记执行缓冲和调度,优先处理“在配置文件内”的数据包。
标记 标记由边缘路由器在**区分服务代码点(DSCP)**字段中执行,该字段位于IPv4头部的“服务类型”(Type of Service)字段中的6个最重要的位中,IPv6中则位于“优先级”(Priority)字段。
理想情况下,应该由源端在应用层进行标记,因为只有源端知道流量类型(语音流量或数据流量)。然而,大多数用户会将所有数据包声明为高优先级,因为他们可能不诚实 → 因此,标记应该由网关进行,网关通常受服务提供商控制。但一些研究表明,路由器通常能正确识别最多20-30%的流量,例如,由于加密流量的存在,路由器的识别能力受限。为了简化标记过程,可以通过将PC连接到某个端口,将电话连接到另一个端口来区分流量,路由器可以根据输入端口进行流量标记。
PHB(每跳行为) 一些每跳行为(PHB)正在被开发:
- 加速转发:某个类别的数据包发送速率等于或超过指定速率;
- 保证转发:四类流量:每类流量保证最低带宽量,并且有三种丢包优先级。
PHB指定了要提供的服务,而不是如何实现这些服务。
-
加密学的基本目标和应用
在网络上下文中,安全机制的基本目标是:
- 端点认证;
- 数据完整性:我们希望确保数据在从源到目的地的路径中没有被篡改;
- 机密性:我们希望确保数据不会被任何未经授权的人读取。
这些目标是通过使用加密机制来实现的。加密机制在两个不同的上下文中应用,即执行两种不同的操作:
- 加密:它包括对交换的数据进行加密,即改变数据包的内容,使得只有授权的人能够恢复原始内容;
- 签名:它用于保证数据的完整性和发送者的认证,操作是通过将一个小的字节序列附加到消息中,这个字节序列取决于数据本身以及发送者所拥有的一些信息:
- 端点可以通过重新计算这个字节序列来检查数据是否被修改;
- 这个操作类似于错误检测代码,但不同的是,字节序列是基于一个秘密密钥的。
密钥类型
有两种类型的密钥:
- 共享(或对称)密钥:相同的密钥,作为一个字节序列,被用来加密/签名和解密/认证数据。该密钥必须在通信的两个站点之间保密,这带来了一个困难,因为用于协商密钥的通信本身应该是安全的;
- 非对称密钥:使用两个不同的密钥来加密/签名和解密/认证数据。两个密钥中,称为公钥的一个,用来解密源主机通过其私钥加密的数据包,可以公开共享;另一个密钥必须保密。这两个密钥是成对的,意味着通过一个密钥加密的内容只能通过另一个密钥解密。
例如,如果你想安全地发送一个文件,你可以使用私钥应用加密算法,然后传播公钥:这样,任何想与该主机安全通信的人都可以使用该公钥加密消息,因为只有该主机拥有私钥,能够解码该消息。
为了验证发送者的身份,机制类似:如果你想确保用户能验证消息来自特定的发送者,他们只需要使用发送者的公钥解密发送的消息。
密钥类型的优缺点
非对称密钥比对称密钥更不稳定,并且在使用它们的算法中需要更多的计算资源。
在许多情况下,非对称密钥用于安全通信并协商对称密钥:
- 主机发送它打算用于单向通信的公钥;
- 目标主机选择一个对称密钥,并通过先前收到的公钥加密后转发它;
- 源主机使用私钥解密消息,从那时起它将使用其中包含的对称密钥。
关键点:当某人收到与某个实体相关的公钥时,必须确认该实体的身份,即它确实是它声称的那个实体:为此,我们使用证书。
证书
证书是用于验证公钥属于某个实体的文件。数字证书包含:
- 关于密钥的信息;
- 关于所有者身份的信息;
- 经过认证机构验证证书内容的数字签名。
签名实际上是一个字节序列,一种摘要,使用认证机构的私钥进行加密。验证签名意味着检查证书是否已由认证机构验证,因此你只需使用它的证书,该证书将包含公钥,用来解密签名。认证机构的证书可能已经为主机所知,例如它已经存在于操作系统或Web浏览器中,或者可能需要下载并以相同的方式进行验证。根CA证书必须以可靠的方式获得。