结构化查询语言(Structured Query Language)
超越电子表格
首先,数据库是数据的集合。这些数据以表格的形式组织,如示例中的 person 表所示。此外,DBMS 中还有许多其他类型的对象:视图、函数、过程、索引、权限等。最初,我们将重点放在表格上,并展示其中的四个表格。它们作为我们维基书的基础。其他类型的对象将在后面介绍。
我们尽量保持一切尽可能简单。然而,这四个最小化的表集展示了 1:n 以及 n:m 关系。
person
person 表存储关于虚构人物的信息;参见:创建一个简单的表。
-- 注释行以两个连续的减号 '--' 开始
CREATE TABLE person (
-- 定义列(名称 / 类型 / 默认值 / 可为空)
id DECIMAL NOT NULL,
firstname VARCHAR(50) NOT NULL,
lastname VARCHAR(50) NOT NULL,
date_of_birth DATE,
place_of_birth VARCHAR(50),
ssn CHAR(11),
weight DECIMAL DEFAULT 0 NOT NULL,
-- 选择一个已定义的列作为主键,并
-- 为主键约束猜一个有意义的名称:'person_pk' 可能是一个不错的选择
CONSTRAINT person_pk PRIMARY KEY (id)
);
contact
contact 表存储一些人的联系信息。有人可能会考虑将这些联系信息存储在 person 表的附加列中:一个用于电子邮件,一个用于 ICQ,等等。但我们出于一些严重的原因决定不这样做。
- 缺失值:许多人没有大部分这些联系值,或者我们不知道这些值。此后,表格将看起来像一个稀疏矩阵。
- 多重性:其他人有多个电子邮件地址或多个电话号码。我们是否应该定义许多列如
email_1、email_2等?上限是多少?标准 SQL 不提供类似于列的“值数组”的东西(某些实现提供)。 - 未来扩展:有一天,可能会有一种或多种今天未知的联系类型。那时我们必须修改表格。
当联系数据存储到自己的表中时,我们可以轻松处理所有这些情况。唯一需要特别注意的是将人物与其联系数据关联起来。这项任务将由 contact 表的 person_id 列管理。它包含与分配的 person 表主键相同的值。
一般来说,我们有一个信息单元(person),它可能属于同类型的多个信息单元(contact)。我们称这种关联为关系——在这种情况下是 1:m 关系(也称为一对多关系)。每当我们遇到这种情况时,我们将可能多次出现的值存储在一个单独的表中,并与第一个表的 id 一起存储。
CREATE TABLE contact (
-- 定义列(名称 / 类型 / 默认值 / 可为空)
id DECIMAL NOT NULL,
person_id DECIMAL NOT NULL,
-- 如果省略 contact_type,则使用默认值
contact_type VARCHAR(25) DEFAULT 'email' NOT NULL,
contact_value VARCHAR(50) NOT NULL,
-- 选择一个已定义的列作为主键
CONSTRAINT contact_pk PRIMARY KEY (id),
-- 定义 `person_id` 列与 `person` 表的 `id` 列之间的外键关系
CONSTRAINT contact_fk FOREIGN KEY (person_id) REFERENCES person(id),
-- 更多约束
CONSTRAINT contact_check CHECK (contact_type IN ('fixed line', 'mobile', 'email', 'icq', 'skype'))
);
hobby
人们通常有一个或多个爱好。关于多重性,我们在联系信息中遇到了相同的问题。因此,我们需要一个单独的爱好表。
CREATE TABLE hobby (
-- 定义列(名称 / 类型 / 默认值 / 可为空)
id DECIMAL NOT NULL,
hobbyname VARCHAR(100) NOT NULL,
remark VARCHAR(1000),
-- 选择一个已定义的列作为主键
CONSTRAINT hobby_pk PRIMARY KEY (id),
-- 禁止重复记录一个爱好
CONSTRAINT hobby_unique UNIQUE (hobbyname)
);
您可能已经注意到,没有对应人物的列。为什么会这样?对于爱好,我们有一个额外的问题:不仅一个人有多个爱好,同时多个人人有相同的爱好。
我们称这种关联为 n:m 关系。可以通过在两个原始表之间创建第三个表来设计它。第三个表存储第一个和第二个表的 id。这样可以决定哪个人从事哪个爱好。在我们的示例中,这个“中间表”是 person_hobby,将在下一步定义。
person_hobby
CREATE TABLE person_hobby (
-- 定义列(名称 / 类型 / 默认值 / 可为空)
id DECIMAL NOT NULL,
person_id DECIMAL NOT NULL,
hobby_id DECIMAL NOT NULL,
-- 此表也有自己的主键!
CONSTRAINT person_hobby_pk PRIMARY KEY (id),
-- 定义 `person_id` 列与 `person` 表的 `id` 列之间的外键关系
CONSTRAINT person_hobby_fk_1 FOREIGN KEY (person_id) REFERENCES person(id),
-- 定义 `hobby_id` 列与 `hobby` 表的 `id` 列之间的外键关系
CONSTRAINT person_hobby_fk_2 FOREIGN KEY (hobby_id) REFERENCES hobby(id)
);
person_hobby 表的每一行包含一个来自 person 表的 id 和一个来自 hobby 表的 id。这就是将人物和爱好信息关联起来的技术。
结构的可视化
执行上述命令后,您的数据库应包含四个表(没有任何数据)。这些表及其相互关系可以在所谓的实体关系图(Entity Relationship Diagram)中可视化。左侧是 person 和 contact 之间的 1:n 关系,右侧是 person 和 hobby 之间的 n:m 关系,以及其中间的 person_hobby 表。
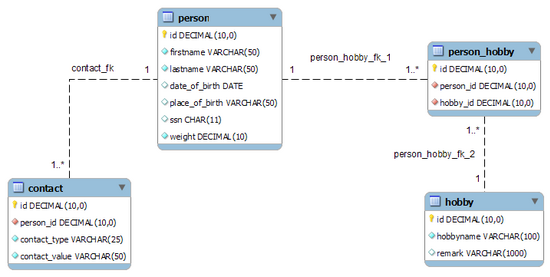
我们的示例数据库的可视化表示
您可以根据需要复制/粘贴这些示例,以帮助您学习和实践SQL。