计算机科学基础
互联网与万维网
互联网与万维网为我们提供了连接无数资源的能力,并塑造了我们社会利用技术进行在线存储和服务的方式。我们将运用之前学到的原则来研究互联网和网络通信。我们将探讨的原则包括:
- 信息可以被编码为消息。
- 一个协调系统是一组为共同目标相互协作的代理。
- 消息可以隐藏信息。
计算机网络
计算机网络被认为是一个通信子系统,它连接了一组计算机,使它们能够相互通信。谈到计算机网络时,必须考虑使其成为可能的两个部分:
硬件:
- 网络接口卡(NIC): 必需的硬件,用于连接到局域网。
- 电缆或天线: 用于传输信号。
- 网络交换机: 用于中继信号。
软件:
- 程序: 使用算法处理信息(比特)。
网络标准
类似于比特编码的过程,网络也需要使用标准。通信需要设备、消息格式和交互过程的标准。这些标准提供了有序的通信流程。
在有了这些标准后,我们可以研究网络实际如何运行。如前所述,计算机网络由两部分组成:硬件和软件。物理硬件为通信提供了途径,但并未真正启用网络功能。是软件(程序)使得计算机网络能够实现软件之间的通信。
本章的重点将放在以下三个软件标准上:
- 互联网协议套件: 定义通信的规则和结构。
- 软件分层: 通过分层实现功能的分解。
- 抽象简化: 利用抽象降低复杂性。
背景定义
理解提供的相关链接中的定义将为本章的学习提供基础。
协议栈
在分析实现网络通信所需的协议时,我们会发现不同的协议被分层以创建抽象级别。这些抽象层用于上层和下层(见下图)。通过这些层次的划分,每一层都专注于特定的功能,而无需了解其他层的细节。这种设计极大地简化了复杂系统的构建和维护。
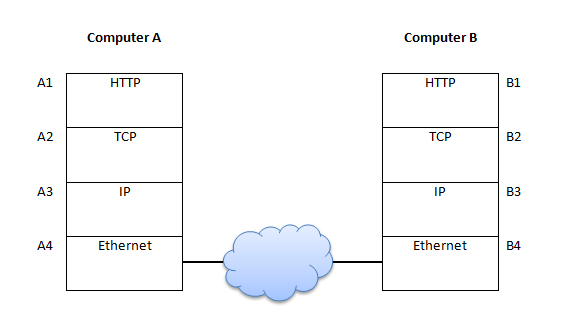
消息类比
假设计算机 A 想要向计算机 B 发送一条消息。以下是通过两组代理栈传递消息的步骤:
- 仅 A4 和 B4 能够访问物理邮箱以发送和接收包裹。
- A1 将消息拆分为包裹。
- A2 给包裹添加序列号和追踪号。
- A3 添加地址标签。
- A4 将包裹放入发件箱。
- 包裹到达 B4 的收件箱。
- B3 接收发往 B 的包裹。
- B2 使用序列号整理包裹顺序,并通过追踪号向 A2 确认包裹。
- A2 如果未收到确认,会重新发送包裹。
- B1 打开包裹,还原成原始消息。
网络协议的工作方式类似于以上流程,其中 A1 到 A4 和 B1 到 B4 是软件。而 A4 和 B4 之间的传输机制通常由金属电线、光纤或无线电波组成。
传输机制
之前我们通过计算机 A 和 B 解释了信息的传递方式。如今,网络之间的通信主要使用以下两种传输机制:
电路交换
在电话网络中,通信需要在传输前建立连接。例如,当你拨打电话时,电话会响铃直到对方接听或进入语音信箱。这种通信方式称为同步通信。
分组交换
与此相对,计算机网络使用分组交换。在分组交换中,每个数据包(小信息包)都被单独标记地址并单独传递。这一过程类似于通过共享运输媒介(如卡车、火车、船只、飞机)发送邮件。例如,当你寄送一封信时,你并不会等到收件人准备好再发送。这种通信方式称为异步通信。
互联网
我们已经了解了互联网的不同标准和协议。以下是互联网的几个重要特性,这些特性使其不同于万维网:
- 通信基础设施:互联网是信息高速公路。
- 全球计算机网络连接:通过**互联网协议(IP)**连接全球计算机网络。
- 多层通信协议:包括 IP、TCP 和 HTTP/FTP/SSH 等协议。
- 基于开放标准:任何人都可以创建新的互联网设备。
- 缺乏集中控制:互联网大多是去中心化的。
- 广泛可用性:只需简单、常见的软件,任何人都可以使用互联网。
万维网(World Wide Web)
万维网常被与互联网混淆,因为它依托于互联网运行。然而,万维网只是互联网提供的众多服务之一。了解万维网的特点至关重要(如下所示):
- 分布式网页或文档的集合:这些网页或文档可以通过网页协议(HTTP - 超文本传输协议)获取。
- 一种服务(应用):使用互联网作为传输机制。
- 众多运行在互联网之上的服务之一:其他服务还包括电子邮件、文件传输、远程登录等。
万维网的组成
万维网的运作依赖于两个主要角色:Web 服务器和Web 客户端(浏览器)。
Web 服务器
- 软件功能:监听网页请求,并访问存储的网页。
- 示例:Apache、微软的 Internet Information Server (IIS)。
Web 客户端(浏览器)
- 软件功能:获取并显示从 Web 服务器获取的文档。
- 示例:Firefox、Internet Explorer、Safari、Chrome。
统一资源定位符(URL)
**统一资源定位符(URL)**是用于标识网页位置的标识符。URL 系统是分层的(见下图)。

edu: 表示学校的网站URL(不是 .com 或 .org)。
www.sbuniv.edu: 西南浸会大学(SBU)官网的URL。
www.sbuniv.edu/COBACS/CIS/index.html: SBU官网下某网页的URL,路径为 /COBACS/CIS/index.html。
超文本标记语言(HTML)
定义网页的语言称为HTML。想要查看示例,可以打开一个新标签页,导航至西南浸会大学计算机与信息科学(CIS)系的网站。当页面打开后,右键点击网页并选择“查看页面源代码”(View Source)。这样你就可以看到用于创建该网页的HTML代码。
网页本身可能包含超文本(可点击的文字,用作链接)。一个链接实际上是指向另一个网页的定义URL。网页和链接结合在一起就构成了万维网。
在万维网上查找信息
了解如何在万维网上查找信息非常重要。以下是查找信息的步骤:
- **使用分层系统(目录)**来找到可能包含所需信息的页面URL。
- 利用知识推测,例如从
apple.com开始导航到 iPhone 5s 的页面。 - 使用搜索引擎:
- 我们寻找信息,而不是具体页面的位置。
- 可能会找到以前不知道存在的信息。
搜索引擎的工作原理
搜索引擎是定位资源的重要工具之一。但你是否想过它是如何运作的?以下是搜索引擎使用的步骤:
- 收集信息:通过网络爬虫(crawl the web)。
- 保存副本:缓存网页(cache web pages)。
- 构建索引。
- 理解查询。
- 确定每个可能结果与查询的相关性。
- 确定相关结果的排名。
- 呈现搜索结果。
重要页面的衡量标准
搜索完成后,会显示相关页面。然而,并非所有显示的相关页面都被认为重要。一个网页需要被可信来源进行排名才能获得重要性。
Google的创新之一是“PageRank”,即对网页“重要性”的衡量,它会考虑该页面的外部引用。
- 一个页面的重要性取决于指向该页面的重要网页的数量。例如,《纽约时报》上的一篇电子文章,由于有许多重要页面链接到该文章,其重要性或PageRank会高于某人的个人博客。