机器学习
无监督学习不提供正确响应,而是算法试图识别输入之间的相似性,以便将具有共同点的输入归类在一起。无监督学习的统计方法被称为密度估计。
无监督学习是一种机器学习算法,用于从没有标签响应的输入数据集中推断信息。在无监督学习算法中,观测数据不包含分类或归类信息。没有输出值,因此也没有对函数的估计。由于提供给学习器的示例是无标签的,因此无法评估算法输出结构的准确性。最常见的无监督学习方法是聚类分析,它用于探索性数据分析,以发现数据中隐藏的模式或分组。
示例
考虑以下关于进入诊所的患者数据。该数据包含患者的性别和年龄。
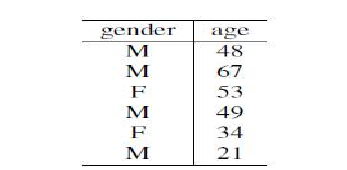
根据这些数据,我们能推断出进入诊所的患者的任何信息吗?
Correct responses are not provided, but instead the algorithm tries to identify similarities
between the inputs so that inputs that have something in common are categorised together. The
statistical approach to unsupervised learning is
known as density estimation.
Unsupervised learning is a type of machine learning algorithm used to draw inferences from
datasets consisting of input data without labeled responses. In unsupervised learning algorithms, a
classification or categorization is not included in the observations. There are no output values and so
there is no estimation of functions. Since the examples given to the learner are unlabeled, the accuracy
of the structure that is output by the algorithm cannot be evaluated. The most common unsupervised learning method is cluster analysis,which is used for exploratory data analysis to find hidden patterns or grouping in data.
Example
Consider the following data regarding patients entering a clinic. The data consists of the gender
and age of the patients.
Based on this data, can we infer anything regarding the patients entering the clinic?