机器学习
| 示例 | Sky | AirTemp | Humidity | Wind | Water | Forecast | EnjoySport |
| 1 | Sunny | Warm | Normal | Strong | Warm | Same | Yes |
| 2 | Sunny | Warm | High | Strong | Warm | Same | Yes |
| 3 | Rainy | Cold | High | Strong | Warm1 | Change | No |
| 4 | Sunny | Warm | High | Strong | Cool | Change | Yes |
2CANDIDATE-ELIMINATION 算法首先将版本空间初始化为包含 H 中所有假设的集合:
将 G 边界集初始化为包含 H 中最一般假设的集合:
G0=⟨?,?,?,?,?,?⟩
将 S 边界集初始化为包含最特殊(最不一般)假设的集合:
S0=⟨∅,∅,∅,∅,∅,∅⟩
-
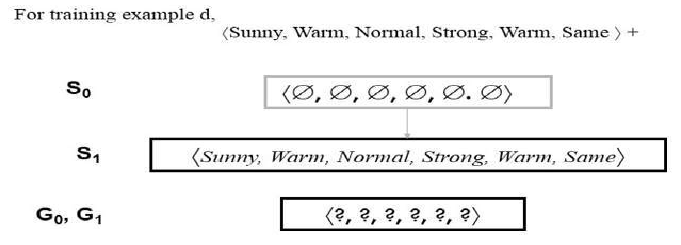
当呈现第一个训练示例时,CANDIDATE-ELIMINATION 算法检查 S 边界,发现它过于特殊,未能覆盖这个正例。
因此,边界通过将其移动到覆盖此新示例的最不一般(最小泛化)假设来修正。
对 G 边界无需进行更新以响应此训练示例,因为 G0 正确覆盖了此示例。
-
当观察到第二个训练示例时,它具有类似的效果,将 S 进一步泛化到 S2,而 G 再次保持不变,即 。

-
考虑第三个训练示例。这个负例表明版本空间的 G 边界过于一般,也就是说,G 中的假设错误地预测这个新示例是正例。
因此,G 边界中的假设必须特殊化,直到它正确分类这个新的负例。

鉴于有六个可以指定来特殊化 G2 的属性,为什么 G3 中只有三个新假设?
例如,假设 h=⟨?,?,Normal,?,?,?⟩ 是 G2 的一个最小特殊化,它正确地将新示例标记为负例,但它不包含在 G3 中。排除这个假设的原因是它与之前遇到的正例不一致。
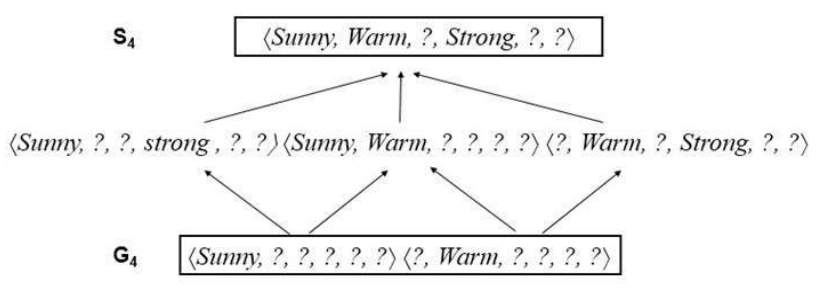
- 考虑第四个训练示例。

这个正例进一步泛化了版本空间的 S 边界。它还导致移除了 G 边界的一个成员,因为这个成员未能覆盖新的正例。
在处理完这四个示例后,边界集 S4 和 G4 划定了与逐步观察到的训练示例一致的所有假设的版本空间。
Example
Sky
AirTemp
Humidity
Wind
Water
Forecast
EnjoySport
1
Sunny
Warm
Normal
Strong
Warm
Same
Yes
2
Sunny
Warm
High
Strong
Warm
Same
Yes
3
Rainy
Cold
High
Strong
Warm
Change
No
4
Sunny
Warm
High
Strong
Cool
Change
Yes
CANDIDATE-ELIMINTION algorithm begins by initializing the version space to the set of all
hypotheses in H;
Initializing the G boundary set to contain the most general hypothesis in H
G0 ?, ?, ?, ?, ?, ?
Initializing the S boundary set to contain the most specific (least general) hypothesis
S0 , , , , ,
When the first training example is presented, the CANDIDATE-ELIMINTION algorithm checks the
S boundary and finds that it is overly specific and it fails to cover the positive example.
The boundary is therefore revised by moving it to the least more general hypothesis that covers
this new example
No update of the G boundary is needed in response to this training example because Go
correctly covers this example
When the second training example is observed, it has a similar effect of generalizing S further to S2,
leaving G again unchanged i.e., G2 = G1 =G0
Consider the third training example. This negative example reveals that the G boundary of
the version space is overly general, that is, the hypothesis in G incorrectly predicts that this
new example is a positive example.
The hypothesis in the G boundary must therefore be specialized until it correctly classifies
this new negative example.
Given that there are six attributes that could be specified to specialize G2, why are there only three
new hypotheses in G3?
For example, the hypothesis h = (?, ?, Normal, ?, ?, ?) is a minimal specialization of G2 that
correctly labels the new example as a negative example, but it is not included in G3. The
reason this hypothesis is excluded is that it is inconsistent with the previously encountered
positive examples
Consider the fourth training example.
19
This positive example further generalizes the S boundary of the version space. It also
results in removing one member of the G boundary, because this member fails to cover
the new positive example
After processing these four examples, the boundary sets S4 and G4 delimit the version space of all
hypotheses consistent with the set of incrementally observed training examples.