机器学习
在前面的章节中,我们讨论了许多不同的学习算法。尽管这些算法通常是成功的,但没有哪一种单一算法总是最准确的。现在,我们将讨论由多个学习器组成的模型,这些学习器相互补充,通过组合它们,我们可以获得更高的准确性。
此外,还有不同的方式来组合多个**基学习器(base-learner)**以生成最终输出:
图 2:一般思想 - 组合多个学习器
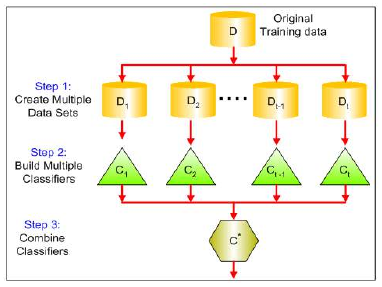
多专家组合(Multiexpert combination)
多专家组合方法中的基学习器并行工作。这些方法又可以分为两类:
- 全局方法,也称为学习器融合(learner fusion):给定一个输入,所有基学习器都生成一个输出,并且所有这些输出都被使用。
- 例子包括投票(voting)和堆叠(stacking)。
- 局部方法,或学习器选择(learner selection):例如,在专家混合(mixture of experts)中,有一个门控模型(gating model),它查看输入并选择一个(或很少几个)学习器负责生成输出。
多阶段组合(Multistage combination)
多阶段组合方法采用串行方法,其中下一个基学习器仅在前一个基学习器不够准确的实例上进行训练或测试。其思想是,基学习器(或它们使用的不同表示)按复杂性递增的顺序排列,以便除非之前的简单基学习器不自信,否则不使用复杂的基学习器(或不提取其复杂的表示)。
- 一个例子是级联(cascading)。
假设我们有 L 个基学习器。我们用 dj(x) 表示基学习器 Mj 给定任意维度输入 x 时的预测。在有多个表示的情况下,每个 Mj 使用不同的输入表示 xj。最终预测从基学习器的预测中计算得出:
其中 f(⋅) 是组合函数,Φ 表示其参数。
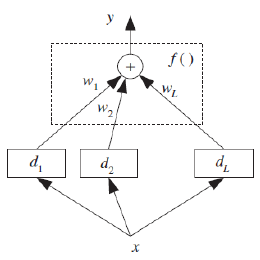
图 1:基学习器为 dj,其输出通过 f(⋅) 组合。这适用于单个输出;在分类的情况下,每个基学习器有 K 个输出,这些输出分别用于计算 yi,然后我们选择最大值。请注意,这里所有学习器都观察相同的输入;也可能出现不同的学习器观察相同输入对象或事件的不同表示的情况。
当有 K 个输出时,对于每个学习器,都有 dji(x),其中 ,然后,通过组合它们,我们也会生成 K 个值,,然后例如在分类中,我们选择具有最大 yi 值的类别:
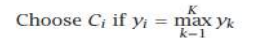
We discussed many different learning algorithms in the previous chapters. Though these are
generally successful, no one single algorithm is always the most accurate. Now, we are going to discuss
models composed of multiple learners that complement each other so that by combining them, we
attain higher accuracy.
There are also different ways the multiple base-learners are combined to generate the final
output:
Figure2: General Idea - Combining Multiple Learners
Multiexpert combination
Multiexpert combination methods have base-learners that work in parallel. These methods can
in turn be divided into two:
In the global approach, also called learner fusion, given an input, all base-learners generate an
output and all these outputs are used.
Examples are voting and stacking.
In the local approach, or learner selection, for example, in mixture of experts, there is a gating
model, which looks at the input and chooses one (or very few) of the learners as responsible for
generating the output.
Multistage combination
Multistage combination methods use a serial approach where the next base-learner is trained
with or tested on only the instances where the previous base-learners are not accurate enough. The
idea is that the base-learners (or the different representations they use) are sorted in increasing
complexity so that a complex base-learner is not used (or its complex representation is not extracted)
unless the preceding simpler base-learners are not confident.
An example is cascading.
Let us say that we have L base-learners. We denote by dj(x) the prediction of base-learner M j given the
arbitrary dimensional input x. In the case of multiple representations, each Mj uses a different input
representation xj . The final prediction is calculated from the predictions of
the base-learners:
y = f (d1, d2, . . . , dL |Φ)
where f (·) is the combining function with Φ denoting its parameters.
61
Figure 1: Base-learners are dj and their outputs are combined using f (·). This is for a single
output; in the case of classification, each base-learner has K outputs that are separately used to
calculate yi, and then we choose the maximum. Note that here all learners observe the same input; it
may be the case that different learners observe different representations of the same input object or
event.
When there are K outputs, for each learner there are dji (x), i = 1, . . . , K,
j = 1, . . . , L, and, combining them, we also generate K values, yi, i = 1, . . . , K and then for example in
classification, we choose the class with
the maximum yi value: