机器学习
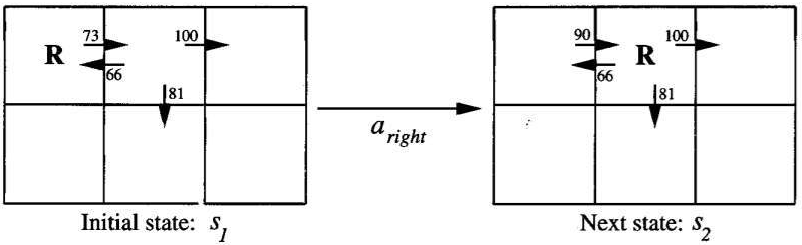
为了阐明 Q 学习算法的运作方式,我们来看一个智能体执行单个动作的例子,以及随之而来的 Q^ 值更新,如下图所示:
-
智能体在它的网格世界中向右移动了一个单元格,并为此转换获得了零的即时奖励。
-
我们应用 Q 学习的训练规则来更新它刚刚执行的状态-动作转换的 Q^ 估计值:
-
根据训练规则,这次转换的新的 Q^ 估计值是收到的奖励(零)加上到达状态的最高 Q^ 值(100),再乘以折扣因子 γ(0.9)。
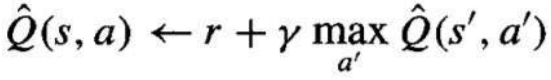
因此,更新后的 Q^ 值为 。
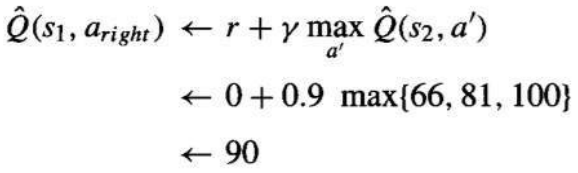
To illustrate the operation of the Q learning algorithm, consider a single action taken by an agent,
and the corresponding refinement to Q̂ shown in below figure
The agent moves one cell to the right in its grid world and receives an immediate reward of zero for
this transition.
Apply the training rule of Equation
to refine its estimate Q for the state-action transition it just executed.
According to the training rule, the new Q̂ estimate for this transition is the sum of the received
reward (zero) and the highest Q̂ value associated with the resulting state (100), discounted by γ (.9