机器学习
Q 学习算法并没有明确规定智能体如何选择动作。
- 一个显而易见的策略是,智能体在状态 s 时,选择能最大化 Q^(s,a) 的动作,从而利用其当前的近似 Q^ 值。
- 然而,采用这种策略,智能体面临一个风险:它可能会过度偏向在早期训练中发现具有高 Q^ 值的动作,而未能探索其他可能具有更高值的动作。
- 因此,Q 学习采用概率方法来选择动作。具有较高 Q^ 值的动作被赋予较高的概率,但每个动作都被赋予非零概率。
- 一种分配这种概率的方法是:
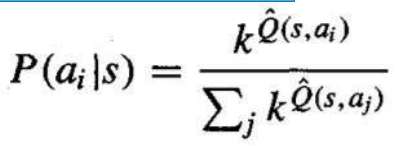
其中,P(ai∣s) 是给定智能体处于状态 s 时选择动作 ai 的概率, 是一个常数,它决定了选择偏向高 Q^ 值动作的强度。
The Q learning algorithm does not specify how actions are chosen by the agent.
One obvious strategy would be for the agent in state s to select the action a that maximizes Q̂(s, a),
thereby exploiting its current approximation Q̂.
However, with this strategy the agent runs the risk that it will overcommit to actions that are
found during early training to have high Q values, while failing to explore other actions that have
even higher values.
For this reason, Q learning uses a probabilistic approach to selecting actions. Actions with higher Q̂
values are assigned higher probabilities, but every action is assigned a nonzero probability.
One way to assign such probabilities is
Where, P(ai |s) is the probability of selecting action ai, given that the agent is in state s, and k > 0 is
a constant that determines how strongly the selection favors actions with high Q̂ values