Python机器学习项目
作为一个领域,机器学习与计算统计学密切相关,因此拥有统计学背景知识对于理解和利用机器学习算法非常有用。
对于可能没有学过统计学的人来说,首先定义相关性 (Correlation) 和回归 (Regression) 会很有帮助,因为它们是研究定量变量之间关系的常用技术。相关性是衡量两个变量之间关联程度的指标,这两个变量不被指定为因变量或自变量。回归在基本层面用于检查一个因变量和一个自变量之间的关系。由于当自变量已知时,回归统计量可用于预测因变量,因此回归具有预测能力。
机器学习的方法正在不断发展。就我们的目的而言,我们将介绍在撰写本文时机器学习中正在使用的几种流行方法。
k-近邻算法 (k-nearest neighbor)
k-近邻算法 (k-NN) 是一种模式识别模型,可用于分类和回归。k-NN 中的“k”是一个正整数,通常很小。无论是分类还是回归,输入都将包含空间内 k 个最近的训练样本。
我们将重点关注 k-NN 分类。在这种方法中,输出是类别归属。它将一个新对象分配给其 k 个最近邻居中最常见的类别。在 k = 1 的情况下,对象被分配给单个最近邻居的类别。
我们来看一个 k-近邻的例子。在下图中,有蓝色菱形对象和橙色星形对象。它们属于两个独立的类别:菱形类别和星形类别。

k-近邻初始数据集
当一个新对象被添加到空间中时——这里是一个绿色的心形——我们希望机器学习算法将其分类到某个类别中。

k-近邻数据集,包含待分类的新对象
当我们选择 k = 3 时,算法将找到绿色心形的三个最近邻居,以便将其分类到菱形类别或星形类别。
在我们的图中,绿色心形的三个最近邻居是一个菱形和两颗星。因此,算法将把心形分类到星形类别。
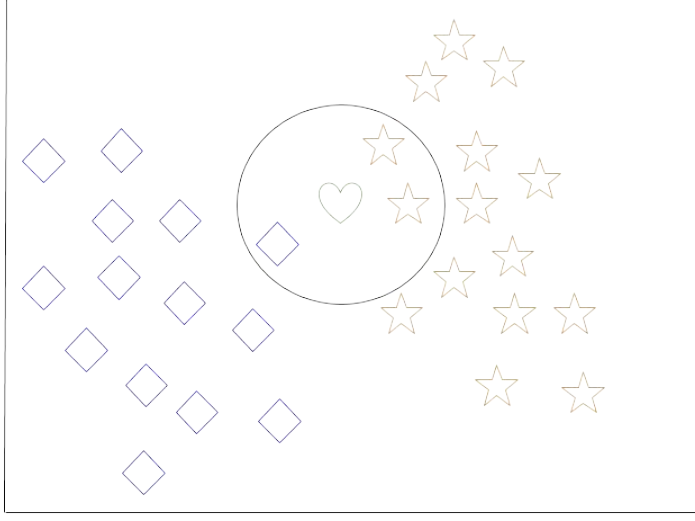
k-近邻数据集,分类完成
作为最基本的机器学习算法之一,k-近邻被认为是一种“惰性学习”,因为在对系统进行查询之前,不会发生超出训练数据的泛化。
决策树学习 (Decision Tree Learning)
一般而言,决策树用于可视化地表示决策并显示或指导决策制定。在处理机器学习和数据挖掘时,决策树被用作预测模型。这些模型将关于数据的观察结果映射到关于数据目标值的结论。
决策树学习的目标是创建一个模型,根据输入变量预测目标的值。
在预测模型中,通过观察确定的数据属性由分支表示,而关于数据目标值的结论则由叶子表示。
在“学习”树时,源数据根据属性值测试被划分为子集,该测试在每个派生子集上递归重复。一旦节点处的子集与它的目标值具有等效值,递归过程就将完成。
我们来看一个决定某人是否应该去钓鱼的各种条件的例子。这包括天气条件以及气压条件。
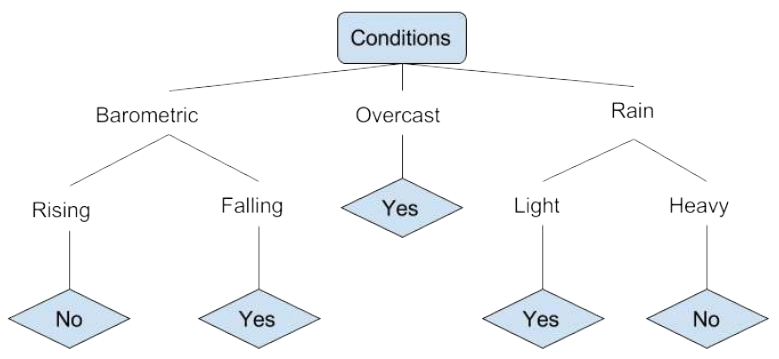
钓鱼决策树示例
在上面简化的决策树中,一个示例通过在树中将其排序到适当的叶节点进行分类。然后,它返回与特定叶相关联的分类,在这种情况下是“是”或“否”。该树根据当天是否适合钓鱼来对当天的条件进行分类。
一个真正的分类树数据集将比上面概述的具有更多的特征,但关系应该很容易确定。在使用决策树学习时,需要做出几个决定,包括选择哪些特征,使用什么条件进行分割,以及理解决策树何时达到了明确的终点。
深度学习 (Deep Learning)
深度学习试图模仿人脑如何将光和声音刺激处理成视觉和听觉。深度学习架构受到生物神经网络的启发,由硬件和 GPU 组成的人工神经网络中的多层构成。
深度学习使用非线性处理单元层的级联来提取或转换数据的特征(或表示)。一层的输出作为下一层的输入。在深度学习中,算法可以是监督的,用于分类数据,也可以是无监督的,执行模式分析。
在目前正在使用和开发的机器学习算法中,深度学习吸收的数据量最大,并且在某些认知任务中已经能够超越人类。由于这些特性,深度学习已成为人工智能领域具有巨大潜力的一个方法。
计算机视觉和语音识别都从深度学习方法中取得了显著进展。IBM Watson 是一个利用深度学习的知名系统示例。
人类偏见 (Human Biases)
尽管数据和计算分析可能让我们认为我们正在接收客观信息,但事实并非如此;基于数据并不意味着机器学习的输出是中立的。人类偏见在数据如何收集、组织以及最终在决定机器学习如何与该数据交互的算法中发挥作用。
例如,如果人们提供“鱼”的图像作为数据来训练算法,而这些人绝大多数选择的是金鱼的图像,那么计算机可能不会将鲨鱼分类为鱼。这会造成对鲨鱼作为鱼的偏见,鲨鱼将不被算作鱼。
当使用科学家的历史照片作为训练数据时,计算机可能无法正确分类同时也是有色人种或女性的科学家。事实上,最近的同行评审研究表明,人工智能和机器学习程序表现出类似人类的偏见,包括种族和性别偏见。例如,请参阅“从语言语料库中自动提取的语义包含类似人类的偏见”和“男性也喜欢购物:使用语料库级约束减少性别偏见放大”[PDF]。
随着机器学习在商业中越来越多地被利用,未被发现的偏见会加剧系统性问题,这可能导致人们无法获得贷款,无法看到高薪工作机会的广告,或者无法获得当日送达选项。
由于人类偏见会对他人产生负面影响,因此意识到它并尽可能努力消除它是极其重要的。实现这一目标的一种方法是确保有多样化的人员参与项目,并且有多样化的人员进行测试和审查。其他人则呼吁监管第三方来监控和审计算法,构建可以检测偏见的替代系统,以及将伦理审查作为数据科学项目规划的一部分。提高对偏见的认识,注意我们自己的无意识偏见,并在我们的机器学习项目和管道中构建公平性,可以有效地对抗该领域的偏见。
As a field, machine learning is closely related to computational statistics,
so
having
a
background
knowledge
in
statistics
is
useful for
understanding and leveraging machine learning algorithms.
For those who may not have studied statistics, it can be helpful to first
define correlation and regression, as they are commonly used techniques
for
investigating
the
relationship
among
quantitative variables.
Correlation is a measure of association between two variables that are not
designated as either dependent or independent. Regression at a basic
level is used to examine the relationship between one dependent and one
independent variable. Because regression statistics can be used to
anticipate the dependent variable when the independent variable is
known, regression enables prediction capabilities.
Approaches to machine learning are continuously being developed.
For our purposes, we’ll go through a few of the popular approaches that
are being used in machine learning at the time of writing.
k-nearest neighbor
The k-nearest neighbor algorithm is a pattern recognition model that can
be used for classification as well as regression. Often abbreviated as k-
NN, the k in k-nearest neighbor is a positive integer, which is typically
small. In either classification or regression, the input will consist of the k
closest training examples within a space.
We will focus on k-NN classification. In this method, the output is class
membership. This will assign a new object to the class most common
among its k nearest neighbors. In the case of k = 1, the object is assigned
to the class of the single nearest neighbor.
Let’s look at an example of k-nearest neighbor. In the diagram below,
there are blue diamond objects and orange star objects. These belong to
two separate classes: the diamond class and the star class.
k-nearest neighbor initial data set
When a new object is added to the space — in this case a green heart —
we will want the machine learning algorithm to classify the heart to a
certain class.
k-nearest neighbor data set with new object to classify
When we choose k = 3, the algorithm will find the three nearest
neighbors of the green heart in order to classify it to either the diamond
class or the star class.
In our diagram, the three nearest neighbors of the green heart are one
diamond and two stars. Therefore, the algorithm will classify the heart
with the star class.
k-nearest neighbor data set with classification complete
Among the most basic of machine learning algorithms, k-nearest
neighbor is considered to be a type of “lazy learning” as generalization
beyond the training data does not occur until a query is made to the
system.
Decision Tree Learning
For general use, decision trees are employed to visually represent
decisions and show or inform decision making. When working with
machine learning and data mining, decision trees are used as a predictive
model. These models map observations about data to conclusions about
the data’s target value.
The goal of decision tree learning is to create a model that will predict
the value of a target based on input variables.
In the predictive model, the data’s attributes that are determined
through observation are represented by the branches, while the
conclusions about the data’s target value are represented in the leaves.
When “learning” a tree, the source data is divided into subsets based
on an attribute value test, which is repeated on each of the derived
subsets recursively. Once the subset at a node has the equivalent value as
its target value has, the recursion process will be complete.
Let’s look at an example of various conditions that can determine
whether or not someone should go fishing. This includes weather
conditions as well as barometric pressure conditions.
fishing decision tree example
In the simplified decision tree above, an example is classified by
sorting it through the tree to the appropriate leaf node. This then returns
the classification associated with the particular leaf, which in this case is
either a Yes or a No. The tree classifies a day’s conditions based on
whether or not it is suitable for going fishing.
A true classification tree data set would have a lot more features than
what is outlined above, but relationships should be straightforward to
determine.
When
working
with
decision
tree learning,
several
determinations need to be made, including what features to choose, what
conditions to use for splitting, and understanding when the decision tree
has reached a clear ending.
Deep Learning
Deep learning attempts to imitate how the human brain can process light
and sound stimuli into vision and hearing. A deep learning architecture
is inspired by biological neural networks and consists of multiple layers
in an artificial neural network made up of hardware and GPUs.
Deep learning uses a cascade of nonlinear processing unit layers in
order to extract or transform features (or representations) of the data. The
output of one layer serves as the input of the successive layer. In deep
learning, algorithms can be either supervised and serve to classify data,
or unsupervised and perform pattern analysis.
Among the machine learning algorithms that are currently being used
and developed, deep learning absorbs the most data and has been able to
beat humans in some cognitive tasks. Because of these attributes, deep
learning has become the approach with significant potential in the
artificial intelligence space
Computer vision and speech recognition have both realized significant
advances from deep learning approaches. IBM Watson is a well-known
example of a system that leverages deep learning.
Human Biases
Although data and computational analysis may make us think that we
are receiving objective information, this is not the case; being based on
data does not mean that machine learning outputs are neutral. Human
bias plays a role in how data is collected, organized, and ultimately in the
algorithms that determine how machine learning will interact with that
data.
If, for example, people are providing images for “fish” as data to train
an algorithm, and these people overwhelmingly select images of
goldfish, a computer may not classify a shark as a fish. This would create
a bias against sharks as fish, and sharks would not be counted as fish.
When using historical photographs of scientists as training data, a
computer may not properly classify scientists who are also people of
color or women. In fact, recent peer-reviewed research has indicated that
AI and machine learning programs exhibit human-like biases that
include race and gender prejudices. See, for example “Semantics derived
automatically from language corpora contain human-like biases” and
“Men Also Like Shopping: Reducing Gender Bias Amplification using
Corpus-level Constraints” [PDF].
As machine learning is increasingly leveraged in business, uncaught
biases can perpetuate systemic issues that may prevent people from
qualifying for loans, from being shown ads for high-paying job
opportunities, or from receiving same-day delivery options.
Because human bias can negatively impact others, it is extremely
important to be aware of it, and to also work towards eliminating it as
much as possible. One way to work towards achieving this is by ensuring
that there are diverse people working on a project and that diverse
people are testing and reviewing it. Others have called for regulatory
third parties to monitor and audit algorithms, building alternative
systems that can detect biases, and ethics reviews as part of data science
project planning. Raising awareness about biases, being mindful of our
own unconscious biases, and structuring equity in our machine learning
projects and pipelines can work to combat bias in this field.