Python 机器学习
机器学习方法
有各种机器学习算法、技术和方法可用于通过数据构建模型以解决实际问题。在本章中,我们将讨论这些不同类型的方法。
不同类型的方法
以下是基于一些广泛类别的各种机器学习方法:
基于人工监督
在学习过程中,一些基于人工监督的方法如下:
监督学习
监督学习算法或方法是最常用的机器学习算法。这种方法或学习算法在训练过程中获取数据样本(即训练数据)及其相关输出(即每个数据样本的标签或响应)。
监督学习算法的主要目标是在执行多个训练数据实例后,学习输入数据样本和相应输出之间的关联。
例如,我们有:
x:输入变量
Y:输出变量
现在,应用算法学习从输入到输出的映射函数,如下所示:
Y=f(x)
现在,主要目标是很好地近似映射函数,以便即使当我们有新的输入数据 (x) 时,我们也能轻松预测该新输入数据(Y)的输出变量。
之所以称之为监督学习,是因为整个学习过程可以被视为由老师或监督者进行监督。监督机器学习算法的例子包括决策树、随机森林、KNN、逻辑回归等。
基于机器学习任务,监督学习算法可以分为以下两大类:
- 分类
- 回归
分类
基于分类的任务的关键目标是预测给定输入数据的类别输出标签或响应。输出将基于模型在训练阶段所学到的内容。由于我们知道类别输出响应意味着无序和离散值,因此每个输出响应将属于一个特定的类或类别。我们将在后续章节中详细讨论分类和相关算法。
回归
基于回归的任务的关键目标是预测给定输入数据的连续数值输出标签或响应。输出将基于模型在训练阶段所学到的内容。基本上,回归模型使用输入数据特征(自变量)及其相应的连续数值输出值(因变量或结果变量)来学习输入和相应输出之间的特定关联。我们还将在后续章节中详细讨论回归和相关算法。
无监督学习
顾名思义,它与监督机器学习方法或算法相反,这意味着在无监督机器学习算法中,我们没有任何监督者提供任何形式的指导。无监督学习算法在以下场景中很方便:我们没有像监督学习算法那样拥有预标记训练数据的自由,并且我们希望从输入数据中提取有用的模式。
例如,可以这样理解:
假设我们有:
x:输入变量,那么将没有相应的输出变量,算法需要发现数据中有趣的模式进行学习。
无监督机器学习算法的例子包括 K 均值聚类、K 最近邻等。
基于机器学习任务,无监督学习算法可以分为以下几大类:
- 聚类
- 关联
- 降维
聚类
聚类方法是最有用的无监督机器学习方法之一。这些算法用于发现数据样本之间的相似性和关系模式,然后将这些样本聚类到基于特征具有相似性的组中。聚类的真实世界示例是根据客户的购买行为对客户进行分组。
关联
另一个有用的无监督机器学习方法是关联,它用于分析大型数据集以查找进一步表示各种项目之间有趣关系的模式。它也被称为关联规则挖掘或市场篮子分析,主要用于分析客户购物模式。
降维
这种无监督机器学习方法通过选择一组主要或代表性特征来减少每个数据样本的特征变量数量。这里出现一个问题,为什么我们需要降维?其原因在于当开始从数据样本中分析和提取数百万个特征时出现的特征空间复杂性问题。这个问题通常被称为“维度诅咒”。PCA(主成分分析)、K 最近邻和判别分析是为此目的流行的一些算法。
异常检测
这种无监督机器学习方法用于找出通常不会发生的罕见事件或观测的出现。通过使用所学知识,异常检测方法将能够区分异常数据点和正常数据点。一些无监督算法,如聚类、KNN,可以根据数据及其特征检测异常。
半监督学习
这种算法或方法既不是完全监督的,也不是完全无监督的。它们基本上介于监督学习和无监督学习方法之间。这类算法通常使用少量的监督学习组件(即少量预标记的注释数据)和大量的无监督学习组件(即大量未标记的数据)进行训练。我们可以遵循以下任何一种方法来实现半监督学习方法:
- 第一种简单的方法是基于少量标记和注释的数据构建监督模型,然后通过将相同的模型应用于大量未标记数据来构建无监督模型,以获取更多标记样本。现在,在其上训练模型并重复该过程。
- 第二种方法需要一些额外的努力。在这种方法中,我们可以首先使用无监督方法对相似数据样本进行聚类,注释这些组,然后使用这些信息的组合来训练模型。
强化学习
这些方法与之前研究的方法不同,也很少使用。在这种学习算法中,会有一个代理,我们希望在一段时间内对其进行训练,使其能够与特定环境交互。代理将遵循一组策略与环境交互,然后观察环境后,它将根据环境的当前状态采取行动。强化学习方法的主要步骤如下:
- 步骤1:首先,我们需要准备一个具有一些初始策略的代理。
- 步骤2:然后观察环境及其当前状态。
- 步骤3:接下来,选择针对环境当前状态的最佳策略并执行重要操作。
- 步骤4:现在,代理可以根据上一步中采取的行动获得相应的奖励或惩罚。
- 步骤5:现在,如果需要,我们可以更新策略。
- 步骤6:最后,重复步骤 2-5,直到代理学会并采用最佳策略。
适合机器学习的任务
下图显示了哪种类型的任务适合各种机器学习问题:
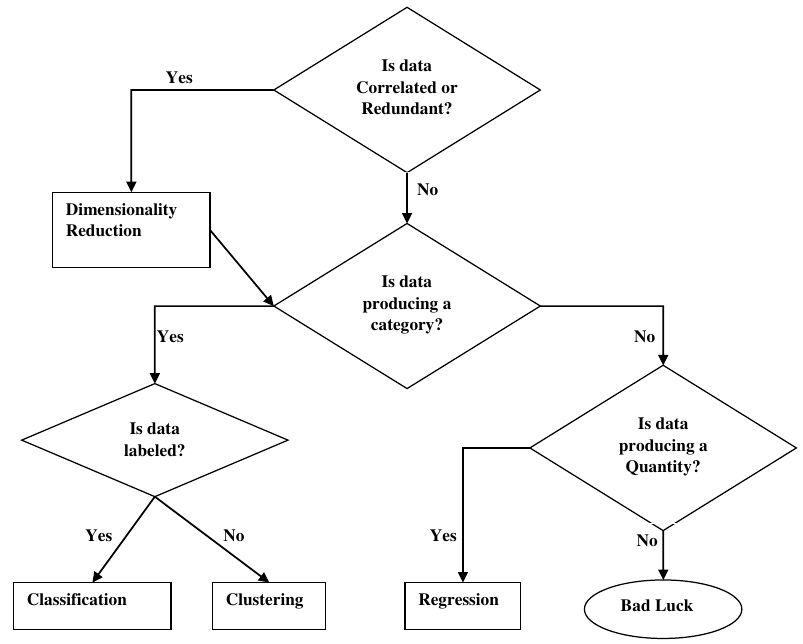
流程图解读:
- 数据是否已标记?
- 是:
- 数据是否生成类别?
- 是:分类
- 否:数据是否生成数量?
- 是:回归
- 否:运气不佳
- 数据是否生成类别?
- 否:
- 数据是否相关或冗余?
- 是:降维
- 否:聚类
- 数据是否相关或冗余?
- 是:
基于学习能力
在学习过程中,以下是基于学习能力的一些方法:
批量学习
在许多情况下,我们有端到端的机器学习系统,需要一次性使用所有可用的训练数据来训练模型。这种学习方法或算法称为批量学习或离线学习。之所以称为批量学习或离线学习,是因为它是一个一次性过程,模型将一次性使用数据进行训练。批量学习方法的主要步骤如下:
- 步骤1:首先,我们需要收集所有训练数据以开始训练模型。
- 步骤2:现在,通过一次性提供所有训练数据来开始模型训练。
- 步骤3:接下来,一旦获得满意的结果/性能,就停止学习/训练过程。
- 步骤4:最后,将这个训练好的模型部署到生产环境中。在这里,它将预测新数据样本的输出。
在线学习
它与批量学习或离线学习方法完全相反。在这些学习方法中,训练数据以多个增量批次(称为小批量)提供给算法。在线学习方法的主要步骤如下:
- 步骤1:首先,我们需要收集所有训练数据以开始训练模型。
- 步骤2:现在,通过向算法提供一小批训练数据来开始模型训练。
- 步骤3:接下来,我们需要以多个增量方式向算法提供小批量的训练数据。
- 步骤4:由于它不会像批量学习那样停止,因此在提供所有小批量训练数据后,也要向其提供新的数据样本。
- 步骤5:最后,它将根据新数据样本在一段时间内持续学习。
基于泛化方法
在学习过程中,以下是基于泛化方法的一些方法:
基于实例的学习
基于实例的学习方法是一种有用的方法,它通过基于输入数据进行泛化来构建机器学习模型。它与之前研究的学习方法相反,这种学习涉及机器学习系统和方法,它们直接使用原始数据点来得出新数据样本的结果,而无需在训练数据上构建显式模型。
简单来说,基于实例的学习基本上通过查看输入数据点开始工作,然后使用相似性度量来泛化和预测新的数据点。
基于模型的学习
在基于模型的学习方法中,在基于各种模型参数(称为超参数)构建的机器学习模型上进行迭代过程,其中输入数据用于提取特征。在这种学习中,超参数根据各种模型验证技术进行优化。这就是为什么我们可以说基于模型的学习方法采用更传统的机器学习方法进行泛化。
3. Python Machine Learning – Methods
Machine for Learning Machine with Python
Learning
There are various ML algorithms, techniques and methods that can be used to build models
for solving real-life problems by using data. In this chapter, we are going to discuss such
different kinds of methods.
Different Types of Methods
The following are various ML methods based on some broad categories:
Based on human supervision
In the learning process, some of the methods that are based on human supervision are as
follows:
Supervised Learning
Supervised learning algorithms or methods are the most commonly used ML algorithms.
This method or learning algorithm take the data sample i.e. the training data and its
associated output i.e. labels or responses with each data samples during the training
process.
The main objective of supervised learning algorithms is to learn an association between
input data samples and corresponding outputs after performing multiple training data
instances.
For example, we have
x: Input variables and
Y: Output variable
Now, apply an algorithm to learn the mapping function from the input to output as follows:
Y=f(x)
Now, the main objective would be to approximate the mapping function so well that even
when we have new input data (x), we can easily predict the output variable (Y) for that
new input data.
It is called supervised because the whole process of learning can be thought as it is being
supervised by a teacher or supervisor. Examples of supervised machine learning
algorithms includes Decision tree, Random Forest, KNN, Logistic Regression etc.
Based on the ML tasks, supervised learning algorithms can be divided into following two
broad classes:
Classification
Regression
17
Machine Learning with Python
Classification
The key objective of classification-based tasks is to predict categorial output labels or
responses for the given input data. The output will be based on what the model has learned
in training phase. As we know that the categorial output responses means unordered and
discrete values, hence each output response will belong to a specific class or category. We
will discuss Classification and associated algorithms in detail in the upcoming chapters
also.
Regression
The key objective of regression-based tasks is to predict output labels or responses which
are continues numeric values, for the given input data. The output will be based on what
the model has learned in its training phase. Basically, regression models use the input
data features (independent variables) and their corresponding continuous numeric output
values (dependent or outcome variables) to learn specific association between inputs and
corresponding outputs. We will discuss regression and associated algorithms in detail in
further chapters also.
Unsupervised Learning
As the name suggests, it is opposite to supervised ML methods or algorithms which means
in unsupervised machine learning algorithms we do not have any supervisor to provide
any sort of guidance. Unsupervised learning algorithms are handy in the scenario in which
we do not have the liberty, like in supervised learning algorithms, of having pre-labeled
training data and we want to extract useful pattern from input data.
For example, it can be understood as follows:
Suppose we have:
x: Input variables, then there would be no corresponding output variable and the
algorithms need to discover the interesting pattern in data for learning.
Examples of unsupervised machine learning algorithms includes K-means clustering, K-
nearest neighbors etc.
Based on the ML tasks, unsupervised learning algorithms can be divided into following
broad classes:
Clustering
Association
Dimensionality Reduction
Clustering
Clustering methods are one of the most useful unsupervised ML methods. These
algorithms used to find similarity as well as relationship patterns among data samples and
then cluster those samples into groups having similarity based on features. The real-world
example of clustering is to group the customers by their purchasing behavior.
Association
Another useful unsupervised ML method is Association which is used to analyze large
dataset to find patterns which further represents the interesting relationships between
various items. It is also termed as Association Rule Mining or Market basket analysis
which is mainly used to analyze customer shopping patterns.
18
Machine Learning with Python
Dimensionality Reduction
This unsupervised ML method is used to reduce the number of feature variables for each
data sample by selecting set of principal or representative features. A question arises here
is that why we need to reduce the dimensionality? The reason behind is the problem of
feature space complexity which arises when we start analyzing and extracting millions of
features from data samples. This problem generally refers to “curse of dimensionality”.
PCA (Principal Component Analysis), K-nearest neighbors and discriminant analysis are
some of the popular algorithms for this purpose.
Anomaly Detection
This unsupervised ML method is used to find out the occurrences of rare events or
observations that generally do not occur. By using the learned knowledge, anomaly
detection methods would be able to differentiate between anomalous or a normal data
point. Some of the unsupervised algorithms like clustering, KNN can detect anomalies
based on the data and its features.
Semi-supervised Learning
Such kind of algorithms or methods are neither fully supervised nor fully unsupervised.
They basically fall between the two i.e. supervised and unsupervised learning methods.
These kinds of algorithms generally use small supervised learning component i.e. small
amount of pre-labeled annotated data and large unsupervised learning component i.e. lots
of unlabeled data for training. We can follow any of the following approaches for
implementing semi-supervised learning methods:
The first and simple approach is to build the supervised model based on small
amount of labeled and annotated data and then build the unsupervised model by
applying the same to the large amounts of unlabeled data to get more labeled
samples. Now, train the model on them and repeat the process.
The second approach needs some extra efforts. In this approach, we can first use
the unsupervised methods to cluster similar data samples, annotate these groups
and then use a combination of this information to train the model.
Reinforcement Learning
These methods are different from previously studied methods and very rarely used also.
In this kind of learning algorithms, there would be an agent that we want to train over a
period of time so that it can interact with a specific environment. The agent will follow a
set of strategies for interacting with the environment and then after observing the
environment it will take actions regards the current state of the environment. The
following are the main steps of reinforcement learning methods:
Step1: First, we need to prepare an agent with some initial set of strategies.
Step2: Then observe the environment and its current state.
Step3: Next, select the optimal policy regards the current state of the environment
and perform important action.
Step4: Now, the agent can get corresponding reward or penalty as per accordance
with the action taken by it in previous step.
19
Machine Learning with Python
Step5: Now, we can update the strategies if it is required so.
Step6: At last, repeat steps 2-5 until the agent got to learn and adopt the optimal
policies.
Tasks Suited for Machine Learning
The following diagram shows what type of task is appropriate for various ML problems:
Yes
Dimensionality
Reduction
Yes
Is data
Correlated or
Redundant?
No
Is data
producing a
category?
No
Is data
labeled?
Is data
producing a
Quantity?
Yes
No
Yes
No
Classification
Clustering
Regression
Bad Luck
Based on learning ability
In the learning process, the following are some methods that are based on learning ability:
Batch Learning
In many cases, we have end-to-end Machine Learning systems in which we need to train
the model in one go by using whole available training data. Such kind of learning method
or algorithm is called Batch or Offline learning. It is called Batch or Offline learning
because it is a one-time procedure and the model will be trained with data in one single
batch. The following are the main steps of Batch learning methods:
Step1: First, we need to collect all the training data for start training the model.
20
Machine Learning with Python
Step2: Now, start the training of model by providing whole training data in one go.
Step3:
Next,
stop
learning/training
process
once
you
got
satisfactory
results/performance.
Step4: Finally, deploy this trained model into production. Here, it will predict the output
for new data sample.
Online Learning
It is completely opposite to the batch or offline learning methods. In these learning
methods, the training data is supplied in multiple incremental batches, called mini-
batches, to the algorithm. Followings are the main steps of Online learning methods:
Step1: First, we need to collect all the training data for starting training of the model.
Step2: Now, start the training of model by providing a mini-batch of training data to the
algorithm.
Step3: Next, we need to provide the mini-batches of training data in multiple increments
to the algorithm.
Step4: As it will not stop like batch learning hence after providing whole training data in
mini-batches, provide new data samples also to it.
Step5: Finally, it will keep learning over a period of time based on the new data samples.
Based on Generalization Approach
In the learning process, followings are some methods that are based on generalization
approaches:
Instance based Learning
Instance based learning method is one of the useful methods that build the ML models by
doing generalization based on the input data. It is opposite to the previously studied
learning methods in the way that this kind of learning involves ML systems as well as
methods that uses the raw data points themselves to draw the outcomes for newer data
samples without building an explicit model on training data.
In simple words, instance-based learning basically starts working by looking at the input
data points and then using a similarity metric, it will generalize and predict the new data
points.
Model based Learning
In Model based learning methods, an iterative process takes place on the ML models that
are built based on various model parameters, called hyperparameters and in which input
data is used to extract the features. In this learning, hyperparameters are optimized based
on various model validation techniques. That is why we can say that Model based learning
methods uses more traditional ML approach towards generalization.