机器学习Python教程
引言

在教程的介绍章节中,我们提到电子邮件垃圾邮件过滤器是机器学习的一个典型例子。电子邮件基于文本,因此用于分类电子邮件的分类器必须能够将文本作为输入进行处理。如果我们回顾之前使用神经网络的例子,它们总是直接与数值一起运行,并且具有固定的输入长度。最终,文本的字符也由数值组成,但很明显,我们不能简单地将文本原样用作神经网络的输入。这意味着文本必须转换为数值表示,例如向量或数字数组。
在本教程中,我们将学习如何以适合机器处理的方式对文本进行编码。
词袋模型 (BAG-OF-WORDS MODEL)
如果我们要将文本用于机器学习,我们需要一种适合机器学习目的的文本表示。这意味着我们需要一种数值表示,我们不能直接使用文本。

在自然语言处理和信息检索中,词袋模型至关重要。词袋模型可用于以适合机器学习算法的方式表示文本数据。此外,该模型易于实现且效率高。在词袋模型中,文本(如句子或文档)被表示为其单词的所谓词袋(一个集合或多重集)。语法和词序被忽略。
接下来,我们将使用一个包含三个字符串的列表来演示词袋方法。在语言学中,用于实验或测试的文本集合通常称为语料库:
corpus = ["To be, or not to be, that is the question:",
"Whether 'tis nobler in the mind to suffer",
"The slings and arrows of outrageous fortune,"]
我们将使用 sklearn.feature_extraction 中的 text 子模块。此模块包含用于从文本文档构建特征向量的实用程序。
from sklearn.feature_extraction import text
CountVectorizer 是 sklearn.feature_extraction.text 模块中的一个类。它是一个用于构建语料库词汇表的有用类。此外,它会生成我们所需的文本的数值表示,即 Numpy 向量。
首先,我们需要此类的实例。实例化 CountVectorizer 时,我们可以传递一些可选参数,但也可以在不带任何参数的情况下调用它,正如我们接下来将要做的。打印向量器会提供有关实例创建时使用的默认值的有用信息:
vectorizer = text.CountVectorizer()
print(vectorizer)
Output:
CountVectorizer()
现在我们有了 CountVectorizer 的一个实例,但它迄今为止还没有见过任何文本。我们将使用 fit 方法来处理我们之前定义的语料库。我们学习了语料库中所有标记(字符串)的词汇字典:
vectorizer.fit(corpus)
Output:
CountVectorizer()
fit 创建了词汇结构 vocabulary_。这包含文本中的单词作为键,以及每个单词的唯一整数值。由于参数 lowercase 的默认值设置为 True,文本开头的 To 已变为 to。您可能还会注意到,词汇表只包含没有标点符号或特殊字符的单词。您可以通过将正则表达式分配给 fit 方法的关键字参数 token_pattern 来更改此行为。默认设置为 (?u)\\b\\w\\w+\\b。此正则表达式的 (?u) 部分不是必需的,因为它为该表达式打开了 re.U (re.UNICODE) 标志,这在 Python 中是默认设置。最小单词长度将为两个字符:
print("Vocabulary: ", vectorizer.vocabulary_)
Output:
Vocabulary: {'to': 18, 'be': 2, 'or': 10, 'not': 8, 'that': 15, 'is': 5, 'the': 16, 'question': 12, 'whether': 19, 'tis': 17, 'nobler': 7, 'in': 4, 'mind': 6, 'suffer': 14, 'slings': 13, 'and': 0, 'arrows': 1, 'of': 9, 'outrageous': 11, 'fortune': 3}
如果您只想查看单词而没有索引,可以使用 feature_names 方法:
print(vectorizer.get_feature_names_out()) # get_feature_names() is deprecated
Output:
['and', 'arrows', 'be', 'fortune', 'in', 'is', 'mind', 'nobler', 'not', 'of', 'or', 'outrageous', 'question', 'slings', 'suffer', 'that', 'the', 'tis', 'to', 'whether']
或者,您可以将键应用于词汇表以保持顺序:
print(list(vectorizer.vocabulary_.keys()))
Output:
['to', 'be', 'or', 'not', 'that', 'is', 'the', 'question', 'whether', 'tis', 'nobler', 'in', 'mind', 'suffer', 'slings', 'and', 'arrows', 'of', 'outrageous', 'fortune']
借助 transform,我们将从原始文本文档中提取标记计数。此调用将使用我们用 fit 创建的词汇表:
token_count_matrix = vectorizer.transform(corpus)
print(token_count_matrix)
Output:
(0, 18) 2
(0, 2) 2
(0, 10) 1
(0, 8) 1
(0, 15) 1
(0, 5) 1
(0, 16) 1
(0, 12) 1
(1, 19) 1
(1, 17) 1
(1, 7) 1
(1, 4) 1
(1, 6) 1
(1, 18) 1
(1, 14) 1
(1, 16) 1
(2, 16) 1
(2, 13) 1
(2, 0) 1
(2, 1) 1
(2, 9) 1
(2, 11) 1
(2, 3) 1
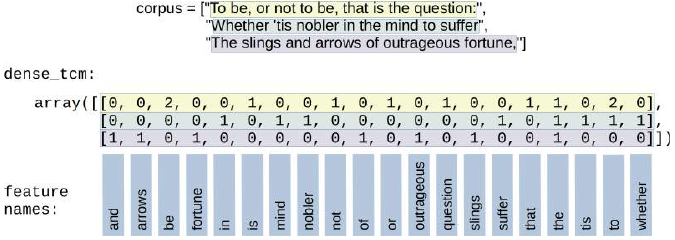
语料库、Vocabulary vocabulary_ 和 transform 创建的向量之间的联系如下图所示:

我们将在对象 token_count_matrix 上应用 toarray 方法。它将返回此矩阵的密集 ndarray 表示。
以防万一:您可能会看到人们有时使用 todense 而不是 toarray。
不要使用 todense!
dense_tcm = token_count_matrix.toarray()
print(dense_tcm)
Output:
array([[0, 0, 2, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 1, 0, 2, 0],
[0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1],
[1, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0]])
此数组的行对应于我们语料库的字符串。一行的长度对应于词汇表的长度。一行中的第 i 个值对应于 CountVectorizer 方法 get_feature_names 返回列表的第 i 个条目。如果 dense_tcm[i][j] 的值等于 k,我们知道词汇表中索引为 j 的单词在语料库中索引为 i 的字符串中出现 k 次。
这在下图中可视化:
feature_names = vectorizer.get_feature_names_out() # get_feature_names() is deprecated
for el in vectorizer.vocabulary_:
print(el)
Output:
to
be
or
not
that
is
the
question
whether
tis
nobler
in
mind
suffer
slings
and
arrows
of
outrageous
fortune
import pandas as pd
pd.DataFrame(data=dense_tcm,
index=['corpus_0', 'corpus_1', 'corpus_2'],
columns=vectorizer.get_feature_names_out()) # get_feature_names() is deprecated
Output:
|
and |
arrows |
be |
fortune |
in |
is |
mind |
nobler |
not |
of |
or |
outrageous |
question |
slings |
suffer |
that |
the |
tis |
to |
whether |
|
|
corpus_0 |
0 |
0 |
2 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
1 |
0 |
2 |
0 |
|
corpus_1 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
1 |
|
corpus_2 |
1 |
1 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
0 |
word = "be"
i = 1
j = vectorizer.vocabulary_[word]
print("number of times '" + word + "' occurs in:")
for i in range(len(corpus)):
print(" '" + corpus[i] + "': " + str(dense_tcm[i][j]))
Output:
number of times 'be' occurs in:
'To be, or not to be, that is the question:': 2
'Whether 'tis nobler in the mind to suffer': 0
'The slings and arrows of outrageous fortune,': 0
我们将从新文本文档中提取标记计数。让我们使用哈姆雷特著名独白的一个有些可疑的变体,看看 transform 对此有什么看法。transform 将使用之前通过 fit 拟合的词汇表。
txt = "That is the question and it is nobler in the mind."
print(vectorizer.transform([txt]).toarray())
Output:
array([[1, 0, 0, 0, 1, 2, 1, 1, 0, 0, 0, 0, 1, 0, 0, 1, 2, 0, 0, 0]])
print(vectorizer.get_feature_names_out()) # get_feature_names() is deprecated
Output:
['and', 'arrows', 'be', 'fortune', 'in', 'is', 'mind', 'nobler', 'not', 'of', 'or', 'outrageous', 'question', 'slings', 'suffer', 'that', 'the', 'tis', 'to', 'whether']
print(vectorizer.vocabulary_)
Output:
{'to': 18, 'be': 2, 'or': 10, 'not': 8, 'that': 15, 'is': 5, 'the': 16, 'question': 12, 'whether': 19, 'tis': 17, 'nobler': 7, 'in': 4, 'mind': 6, 'suffer': 14, 'slings': 13, 'and': 0, 'arrows': 1, 'of': 9, 'outrageous': 11, 'fortune': 3}
词语重要性 (WORD IMPORTANCE)
如果您查看像“the”、“and”或“of”这样的词,您会发现它们几乎出现在所有英语文本中。如果您记住我们的最终目标是区分文本并将它们归类,那么像前面提到的这些词几乎没有任何意义。如果您查看以下语料库,您会看到像“you”、“I”或重要的词,如“Python”、“lottery”或“Programmer”:
from sklearn.feature_extraction import text
corpus = ["It does not matter what you are doing, just do it!",
"Would you work if you won the lottery?",
"You like Python, he likes Python, we like Python, everybody loves Python!"
"You said: 'I wish I were a Python programmer'",
"You can stay here, if you want to. I would, if I were you."
]
vectorizer = text.CountVectorizer()
vectorizer.fit(corpus)
token_count_matrix = vectorizer.transform(corpus)
print(token_count_matrix)
Output:
(0, 0) 1
(0, 2) 1
(0, 3) 1
(0, 4) 1
(0, 9) 2
(0, 10) 1
(0, 15) 1
(0, 16) 1
(0, 26) 1
(0, 31) 1
(1, 8) 1
(1, 13) 1
(1, 21) 1
(1, 28) 1
(1, 29) 1
(1, 30) 1
(1, 31) 1
(2, 5) 1
(2, 6) 1
(2, 11) 2
(2, 12) 1
(2, 14) 1
(2, 17) 1
(2, 18) 1
(2, 19) 1
(2, 24) 5
(2, 25) 1
(2, 27) 1
(2, 31) 1
(3, 1) 1
(3, 7) 1
(3, 8) 2
(3, 20) 1
(3, 22) 1
(3, 23) 1
(3, 25) 1
(3, 30) 1
(3, 31) 3
tf_idf = text.TfidfTransformer()
tf_idf.fit(token_count_matrix)
print(tf_idf.idf_)
Output:
array([1.91629073, 1.91629073, 1.91629073, 1.91629073, 1.9162
9073,
1.91629073, 1.91629073, 1.91629073, 1.51082562, 1.9162
9073,
1.91629073, 1.91629073, 1.91629073, 1.91629073, 1.9162
9073,
1.91629073, 1.91629073, 1.91629073, 1.91629073, 1.9162
9073,
1.91629073, 1.91629073, 1.91629073, 1.91629073, 1.9162
9073,
1.51082562, 1.91629073, 1.91629073, 1.91629073, 1.9162
9073,
1.51082562, 1. ])
print(tf_idf.idf_[vectorizer.vocabulary_['python']])
Output:
1.916290731874155
da = vectorizer.transform(corpus).toarray()
i = 0
# 检查单词 'would' 在第 i 个句子中出现的次数:
#vectorizer.vocabulary_['would']
word_ind = vectorizer.vocabulary_['would']
print(da[i][word_ind])
print(da[:,word_ind])
Output:
0
[0 1 0 1]
word_weight_list = list(zip(vectorizer.get_feature_names_out(), tf_idf.idf_)) # get_feature_names() is deprecated
word_weight_list.sort(key=lambda x:x[1]) # 按权重(第二个分量)对列表进行排序
for word, idf_weight in word_weight_list:
print(f"{word:15s}: {idf_weight:<span class="hljs-number">4.3</span>f}")
Output:
you : 1.000
if : 1.511
were : 1.511
would : 1.511
are : 1.916
can : 1.916
do : 1.916
does : 1.916
doing : 1.916
everybody : 1.916
he : 1.916
here : 1.916
it : 1.916
just : 1.916
like : 1.916
likes : 1.916
lottery : 1.916
loves : 1.916
matter : 1.916
not : 1.916
programmer : 1.916
python : 1.916
said : 1.916
stay : 1.916
the : 1.916
to : 1.916
want : 1.916
we : 1.916
what : 1.916
wish : 1.916
won : 1.916
work : 1.916
from numpy import log
from sklearn.feature_extraction import text
corpus = ["It does not matter what you are doing, just do it!",
"Would you work if you won the lottery?",
"You like Python, he likes Python, we like Python, everybody loves Python!"
"You said: 'I wish I were a Python programmer'",
"You can stay here, if you want to. I would, if I were you."
]
n = len(corpus)
词频 (TERM FREQUENCY)
我们首先定义一个词频函数。
一些符号:
-
\(f_t\),d表示术语 t 在文档 d 中出现的次数
-
\(w_c\) 表示文档 d 中的单词数量
定义 tf(t,d) 最简单的选择是使用术语在文档中的原始计数,即术语 t 在文档 d 中出现的次数,我们可以将其表示为 \(f_t\),d。
我们可以通过不同方式定义 tf(t,d):
-
术语的原始计数:
-
根据文档长度调整的词频:
-
对数尺度频率:
-
增广频率,以防止偏向较长的文档,例如术语的原始频率除以文档中最常出现术语的原始频率:
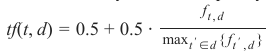
# 以下变量在函数中作为自由变量全局使用 :-(
vectorizer = text.CountVectorizer()
vectorizer.fit(corpus)
da = vectorizer.transform(corpus).toarray()
def tf(t, d, mode="raw"):
""" 词频 'tf' 计算术语 't' 在文档 'd' 中出现的频率。
('d':文档索引)
如果 t_in_d = 术语 t 在文档 d 中出现的次数
no_terms_d = 文档中术语的总数,
tf(t, d) = t_in_d / no_terms_d
"""
if t in vectorizer.vocabulary_:
word_ind = vectorizer.vocabulary_[t]
t_occurrences = da[d, word_ind] # 'd' 是文档索引
else:
t_occurrences = 0
if mode == "raw":
result = t_occurrences
elif mode == "length":
# 计算文档中不同术语的数量 (此处原注释有误,是计算文档中所有词的总数)
# 应该是文档中的总词数,而非不同词数
# 修正:no_terms_d 应该是该文档中所有单词的总数 (len(words) of the document)
# 在这里da[d] 是该文档的词频向量,对其求和就是该文档的总词数
all_terms = da[d].sum()
if all_terms == 0: # 避免除以零
result = 0.0
else:
result = t_occurrences / all_terms
elif mode == "log":
result = log(1 + t_occurrences)
elif mode == "augfreq":
max_freq_in_doc = da[d].max()
if max_freq_in_doc == 0: # 避免除以零
result = 0.5 # 如果文档没有单词,则增广频率为 0.5
else:
result = 0.5 + 0.5 * t_occurrences / max_freq_in_doc
return result
我们将检查一些单词的词频:
print(" raw length log augmented freq")
for term in ['matter', 'python', 'would']:
for docu_index in range(len(corpus)):
d = corpus[docu_index]
print(f"\n'{term}' in '{d}''")
for mode in ['raw', 'length', 'log', 'augfreq']:
x = tf(term, docu_index, mode=mode)
print(f"{x:<span class="hljs-number">7.2</span>f}", end="")
Output:
'matter' in 'It does not matter what you are doing, just do it!''
1.00 0.09 0.69 0.75
'matter' in 'Would you work if you won the lottery?''
0.00 0.00 0.00 0.50
'matter' in 'You like Python, he likes Python, we like Python, everybody loves Python!You said: 'I wish I were a Python programmer'''
0.00 0.00 0.00 0.50
'matter' in 'You can stay here, if you want to. I would, if I were you.''
0.00 0.00 0.00 0.50
'python' in 'It does not matter what you are doing, just do it!''
0.00 0.00 0.00 0.50
'python' in 'Would you work if you won the lottery?''
0.00 0.00 0.00 0.50
'python' in 'You like Python, he likes Python, we like Python, everybody loves Python!You said: 'I wish I were a Python programmer'''
5.00 0.25 1.79 1.00
'python' in 'You can stay here, if you want to. I would, if I were you.''
0.00 0.00 0.00 0.50
'would' in 'It does not matter what you are doing, just do it!''
0.00 0.00 0.00 0.50
'would' in 'Would you work if you won the lottery?''
1.00 0.09 0.69 0.75
'would' in 'You like Python, he likes Python, we like Python, everybody loves Python!You said: 'I wish I were a Python programmer'''
0.00 0.00 0.00 0.50
'would' in 'You can stay here, if you want to. I would, if I were you.''
1.00 0.08 0.69 0.67
文档频率 (DOCUMENT FREQUENCY)
术语 t 的文档频率 df(t) 定义为文档集中包含术语 t 的文档数量。
逆文档频率 (INVERSE DOCUMENT FREQUENCY)
逆文档频率 (idf) 衡量单词提供的信息量,即它在所有文档中是常见还是稀有。它是文档频率的对数尺度倒数。在上述方程式中,将 1 加到 idf 的效果是,idf 为零的术语(即在训练集中所有文档中都出现的术语)将不会被完全忽略。
其中 n 是语料库中的文档数量,。
(请注意,上述 idf 公式与将 idf 定义为 的标准教科书符号不同。)
当调用 TfidfTransformer() 时,如果 smooth_idf=False,则使用上述公式!如果调用时 smooth_idf=True(默认值),则 idf 的分子和分母都加 1,如同看到了一个额外文档,其中每个术语在集合中恰好出现一次,这可以防止除以零:
词频-逆文档频率 (TERM FREQUENCY–INVERSE DOCUMENT FREQUENCY)
\(tf_i\)df 计算为 tf(t,d) 和 idf(t) 的乘积:
高 tf-idf 值意味着该术语在给定文档中具有高“词频”,并且在语料库的其他文档中具有低“文档频率”。这意味着此权重可用于过滤掉常见术语。
我们现在将编写 tf_idf 函数:
text.TfidfTransformer 的帮助文件解释了 tf-idf 的计算方式:
我们将手动编写这些函数:
def df(t):
""" df(t) 是 t 的文档频率;文档频率是
文档集中包含术语 t 的文档数量。
"""
if t not in vectorizer.vocabulary_: # 处理不在词汇表中的词
return 0
word_ind = vectorizer.vocabulary_[t]
tf_in_docus = da[:, word_ind] # 向量,包含 word_ind 在所有文档中的频率
existence_in_docus = tf_in_docus > 0 # 二进制向量,表示单词在文档中的存在
return existence_in_docus.sum()
def idf(t, smooth_idf=True):
""" idf """
document_frequency = df(t)
if smooth_idf:
return log((1 + n) / (1 + document_frequency)) + 1
else:
if document_frequency == 0: # 避免除以零
return 0 # 或者其他表示不存在的合理值,取决于上下文
return log(n / document_frequency) + 1
def tf_idf(t, d):
return idf(t) * tf(t, d)
res_idf = []
for word in vectorizer.get_feature_names_out(): # get_feature_names() is deprecated
res_idf.append([word, idf(word)])
res_idf.sort(key=lambda x:x[1])
for item in res_idf:
print(item)
Output:
['you', 1.0]
['if', 1.5108256237659907]
['were', 1.5108256237659907]
['would', 1.5108256237659907]
['are', 1.916290731874155]
['can', 1.916290731874155]
['do', 1.916290731874155]
['does', 1.916290731874155]
['doing', 1.916290731874155]
['everybody', 1.916290731874155]
['he', 1.916290731874155]
['here', 1.916290731874155]
['it', 1.916290731874155]
['just', 1.916290731874155]
['like', 1.916290731874155]
['likes', 1.916290731874155]
['lottery', 1.916290731874155]
['loves', 1.916290731874155]
['matter', 1.916290731874155]
['not', 1.916290731874155]
['programmer', 1.916290731874155]
['python', 1.916290731874155]
['said', 1.916290731874155]
['stay', 1.916290731874155]
['the', 1.916290731874155]
['to', 1.916290731874155]
['want', 1.916290731874155]
['we', 1.916290731874155]
['what', 1.916290731874155]
['wish', 1.916290731874155]
['won', 1.916290731874155]
['work', 1.916290731874155]
print(corpus)
Output:
['It does not matter what you are doing, just do it!', 'Would you work if you won the lottery?', "You like Python, he likes Python, we like Python, everybody loves Python!You said: 'I wish I were a Python programmer'", 'You can stay here, if you want to. I would, if I were you.']
for word, word_index in vectorizer.vocabulary_.items():
print(f"\n{word:12s}: ", end="")
for d_index in range(len(corpus)):
print(f"{d_index:1d} {tf_idf(word, d_index):<span class="hljs-number">3.2</span>f}, ", end="")
Output:
it : 0 3.83, 1 0.00, 2 0.00, 3 0.00,
does : 0 1.92, 1 0.00, 2 0.00, 3 0.00,
not : 0 1.92, 1 0.00, 2 0.00, 3 0.00,
matter : 0 1.92, 1 0.00, 2 0.00, 3 0.00,
what : 0 1.92, 1 0.00, 2 0.00, 3 0.00,
you : 0 1.00, 1 2.00, 2 2.00, 3 3.00,
are : 0 1.92, 1 0.00, 2 0.00, 3 0.00,
doing : 0 1.92, 1 0.00, 2 0.00, 3 0.00,
just : 0 1.92, 1 0.00, 2 0.00, 3 0.00,
do : 0 1.92, 1 0.00, 2 0.00, 3 0.00,
would : 0 0.00, 1 1.51, 2 0.00, 3 1.51,
work : 0 0.00, 1 1.92, 2 0.00, 3 0.00,
if : 0 0.00, 1 1.51, 2 0.00, 3 3.02,
won : 0 0.00, 1 1.92, 2 0.00, 3 0.00,
the : 0 0.00, 1 1.92, 2 0.00, 3 0.00,
lottery : 0 0.00, 1 1.92, 2 0.00, 3 0.00,
like : 0 0.00, 1 0.00, 2 3.83, 3 0.00,
python : 0 0.00, 1 0.00, 2 9.58, 3 0.00,
he : 0 0.00, 1 0.00, 2 1.92, 3 0.00,
likes : 0 0.00, 1 0.00, 2 1.92, 3 0.00,
we : 0 0.00, 1 0.00, 2 1.92, 3 0.00,
everybody : 0 0.00, 1 0.00, 2 1.92, 3 0.00,
loves : 0 0.00, 1 0.00, 2 1.92, 3 0.00,
said : 0 0.00, 1 0.00, 2 1.92, 3 0.00,
wish : 0 0.00, 1 0.00, 2 1.92, 3 0.00,
were : 0 0.00, 1 0.00, 2 1.51, 3 1.51,
programmer : 0 0.00, 1 0.00, 2 1.92, 3 0.00,
can : 0 0.00, 1 0.00, 2 0.00, 3 1.92,
stay : 0 0.00, 1 0.00, 2 0.00, 3 1.92,
here : 0 0.00, 1 0.00, 2 0.00, 3 1.92,
want : 0 0.00, 1 0.00, 2 0.00, 3 1.92,
to : 0 0.00, 1 0.00, 2 0.00, 3 1.92,
另一个简单示例 (ANOTHER SIMPLE EXAMPLE)
我们将使用另一个简单的例子来说明前面介绍的概念。我们使用一个只包含不同单词的句子。语料库由这个句子及其简化版本组成,即从句子的末尾截断单词。
from sklearn.feature_extraction import text
words = "Cold wind blows over the cornfields".split()
corpus = []
for i in range(1, len(words)+1):
corpus.append(" ".join(words[:i]))
print(corpus)
Output:
['Cold', 'Cold wind', 'Cold wind blows', 'Cold wind blows over', 'Cold wind blows over the', 'Cold wind blows over the cornfields']
vectorizer = text.CountVectorizer()
vectorizer = vectorizer.fit(corpus)
vectorized_text = vectorizer.transform(corpus)
tf_idf = text.TfidfTransformer()
tf_idf.fit(vectorized_text)
print(tf_idf.idf_)
Output:
array([1.33647224, 1.97864722, 2.25276297, 1.55961579, 1.84729786,
1.15415068])
word_weight_list = list(zip(vectorizer.get_feature_names_out(), tf_idf.idf_)) # get_feature_names() is deprecated
word_weight_list.sort(key=lambda x:x[1]) # 按权重(第二个分量)对列表进行排序
for word, idf_weight in word_weight_list:
print(f"{word:15s}: {idf_weight:<span class="hljs-number">4.3</span>f}")
Output:
cold : 1.000
wind : 1.154
blows : 1.336
over : 1.560
the : 1.847
cornfields : 2.253
TfidF = text.TfidfTransformer(smooth_idf=True, use_idf=True)
tfidf = TfidF.fit_transform(vectorized_text)
word_weight_list = list(zip(vectorizer.get_feature_names_out(), tf_idf.idf_)) # get_feature_names() is deprecated
word_weight_list.sort(key=lambda x:x[1]) # 按权重(第二个分量)对列表进行排序
for word, idf_weight in word_weight_list:
print(f"{word:15s}: {idf_weight:<span class="hljs-number">4.3</span>f}")
Output:
cold : 1.000
wind : 1.154
blows : 1.336
over : 1.560
the : 1.847
cornfields : 2.253
使用真实数据 (WORKING WITH REAL DATA)
scikit-learn 包含一个来自真实新闻组的数据集,可用于我们的目的:
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer
import numpy as np
# 创建我们的向量器
vectorizer = CountVectorizer()
# 让我们获取所有可能的文本数据
newsgroups_data = fetch_20newsgroups()
让我们仔细看看这些数据。与 sklearn 中所有其他数据集一样,在 data 属性下:
print(newsgroups_data.data[0])
Output:
From: lerxst@wam.umd.edu (where's my thing)
Subject: WHAT car is this!?
Nntp-Posting-Host: rac3.wam.umd.edu
Organization: University of Maryland, College Park
Lines: 15
I was wondering if anyone out there could enlighten me on this car I saw
the other day. It was a 2-door sports car, looked to be from the late 60s/
early 70s. It was called a Bricklin. The doors were really small.
In addition,
the front bumper was separate from the rest of the body. This is
all I know. If anyone can tellme a model name, engine specs, years
of production, where this car is made, history, or whatever info you
have on this funky looking car, please e-mail.
Thanks,
- IL
---- brought to you by your neighborhood Lerxst ----
我们可以找到实际数据:
print(newsgroups_data.data[200])
Output:
Subject: Re: "Proper gun control?" What is proper gun cont
From: kim39@scws8.harvard.edu (John Kim)
Organization: Harvard University Science Center
Nntp-Posting-Host: scws8.harvard.edu
Lines: 17
In article <C5JGz5.34J@SSD.intel.com> hays@ssd.intel.com (Kirk Hays) writes:
>I'd like to point out that I was in error - "Terminator" began posting only
>six months before he purchased his first firearm, according to private email
>from him.
>I can't produce an archived posting of his earlier than January 1992,
>and he purchased his first firearm in March 1992.
>I guess it only seemed like years.
>Kirk Hays - NRA Life, seventh generation.
I first read and consulted rec.guns in the summer of 1991. I
just purchased my first firearm in early March of this year.
NOt for lack of desire for a firearm, you understand. I could
have purchased a rifle or shotgun but didn't want one.
-Case Kim
我们创建向量器:
vectorizer.fit(newsgroups_data.data)
Output:
CountVectorizer()
让我们看看前 n 个词:
counter = 0
n = 10
for word, index in vectorizer.vocabulary_.items():
print(word, index)
counter += 1
if counter > n:
break
Output:
from 56979
lerxst 75358
wam 123162
umd 118280
edu 50527
where 124031
my 85354
thing 114688
subject 111322
what 123984
car 37780
我们可以将新闻组帖子转换为数组。我们用第一个帖子来做:
a = vectorizer.transform([newsgroups_data.data[0]]).toarray()[0]
print(a)
Output:
[0 0 0 ... 0 0 0]
词汇表非常庞大。这就是我们看到大部分是零的原因。
print(len(vectorizer.vocabulary_))
Output:
130107
这个词汇表中有很多“垃圾”词。从机器学习的角度来看,垃圾词是指像“Subject”、“From”、“Organization”、“Nntp-Posting-Host”、“Lines”等许多无用的词,因为它们出现在所有或大多数帖子中。新闻组中的技术“垃圾”可以很容易地去除。我们可以通过不同的方式获取它。声明我们不想要“headers”、“footers”和“quotes”:
newsgroups_data_cleaned = fetch_20newsgroups(remove=('headers', 'footers', 'quotes'))
print(newsgroups_data_cleaned.data[0])
Output:
I was wondering if anyone out there could enlighten me on this car I saw
the other day. It was a 2-door sports car, looked to be from the late 60s/
early 70s. It was called a Bricklin. The doors were really small.
In addition,
the front bumper was separate from the rest of the body. This is
all I know. If anyone can tellme a model name, engine specs, years
of production, where this car is made, history, or whatever info you
have on this funky looking car, please e-mail.
让我们看看完整的帖子:
print(newsgroups_data.data[0])
Output:
From: lerxst@wam.umd.edu (where's my thing)
Subject: WHAT car is this!?
Nntp-Posting-Host: rac3.wam.umd.edu
Organization: University of Maryland, College Park
Lines: 15
I was wondering if anyone out there could enlighten me on this car I saw
the other day. It was a 2-door sports car, looked to be from the late 60s/
early 70s. It was called a Bricklin. The doors were really small.
In addition,
the front bumper was separate from the rest of the body. This is
all I know. If anyone can tellme a model name, engine specs, years
of production, where this car is made, history, or whatever info you
have on this funky looking car, please e-mail.
Thanks,
- IL
---- brought to you by your neighborhood Lerxst ----
vectorizer_cleaned = vectorizer.fit(newsgroups_data_cleaned.data)
print(len(vectorizer_cleaned.vocabulary_))
Output:
101631
所以,我们去掉了超过 30000 个词,但仍有超过 100000 个词,数量仍然非常大。
我们还可以直接将新闻组内容分离为训练集和测试集:
newsgroups_train = fetch_20newsgroups(subset='train',
remove=('headers', 'footers', 'quotes'))
newsgroups_test = fetch_20newsgroups(subset='test',
remove=('headers', 'footers', 'quotes'))
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
vectorizer = CountVectorizer()
train_data = vectorizer.fit_transform(newsgroups_train.data)
# 创建分类器
classifier = MultinomialNB(alpha=.01)
classifier.fit(train_data, newsgroups_train.target)
test_data = vectorizer.transform(newsgroups_test.data)
predictions = classifier.predict(test_data)
accuracy_score = metrics.accuracy_score(newsgroups_test.target, predictions)
f1_score = metrics.f1_score(newsgroups_test.target, predictions, average='macro')
print("Accuracy score: ", accuracy_score)
print("F1 score: ", f1_score)
Output:
Accuracy score: 0.6460435475305364
F1 score: 0.6203806145034193
停用词 (STOP WORDS)

到目前为止,我们已经将所有单词都添加到了词汇表中。然而,像“the”、“am”、“were”或类似的单词是否应该被包含在内是值得怀疑的,因为它们通常对文本不提供任何重要的语义贡献。换句话说:它们的预测能力有限。因此,将这些词排除在编辑之外,即不将其包含在字典中,会更有意义。这意味着我们必须提供一个应该被忽略的单词列表,即在文本处理之前或之后将其过滤掉。在自然语言处理中,这些词通常被称为“停用词”。没有一个单一的通用停用词列表可以被所有自然语言处理工具使用。通常,停用词由一种语言中最常用的单词组成。“停用词”可以根据给定的任务单独选择。
顺便说一句,停用词是一个相当古老的概念。它起源于 1959 年,由信息检索领域的先驱之一汉斯·彼得·卢恩提出。
在 scikit-learn 中,有不同的方式来提供停用词:
-
显式停用词列表
-
自动创建的停用词
我们将从单独的停用词开始:
好的,这是对您提供的英文文本的中文翻译:
单独的停用词 (INDIVIDUAL STOP WORDS)
from sklearn.feature_extraction.text import CountVectorizer
corpus = ["A horse, a horse, my kingdom for a horse!",
"Horse sense is the thing a horse has which keeps it from betting on people.",
"I’ve often said there is nothing better for the inside of the man, than the outside of the horse.",
"A man on a horse is spiritually, as well as physically, bigger then a man on foot.",
"No heaven can heaven be, if my horse isn’t there to welcome me."]
cv = CountVectorizer(input=corpus,
stop_words=["my", "for","the", "has", "than", "if",
"from", "on", "of", "it", "there", "ve",
"as", "no", "be", "which", "isn", "to",
"me", "is", "can", "then"]) # 这里的 'input=corpus' 是非标准参数,应改为 fit_transform(corpus)
count_vector = cv.fit_transform(corpus)
print(count_vector.shape) # 输出稀疏矩阵的形状
print(cv.vocabulary_)
Output:
(5, 21) # 形状可能因实际处理而异,这里假设是5个文档,21个词汇
{'horse': 5,
'kingdom': 8,
'sense': 16,
'thing': 18,
'keeps': 7,
'betting': 1,
'people': 13,
'often': 11,
'said': 15,
'nothing': 10,
'better': 0,
'inside': 6,
'man': 9,
'outside': 12,
'spiritually': 17, # 注意:原文这里有一个逗号,可能会导致解析错误
'well': 20,
'physically': 14,
'bigger': 2,
'foot': 3,
'heaven': 4,
'welcome': 19}
sklearn 包含默认停用词,它们被实现为一个 frozenset,可以通过 text.ENGLISH_STOP_WORDS 访问:
from sklearn.feature_extraction import text
n = 25
print(str(n) + " arbitrary words from ENGLISH_STOP_WORDS:")
counter = 0
for word in text.ENGLISH_STOP_WORDS:
if counter == n - 1:
print(word)
break
print(word, end=", ")
counter += 1
Output:
25 arbitrary words from ENGLISH_STOP_WORDS:
over, it, anywhere, all, toward, every, inc, had, been, being, without, thence, mine, whole, by, below, when, beside, nevertheless, at, beforehand, after, several, throughout, eg
我们可以在 20newsgroups 分类问题中使用停用词:
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
vectorizer = CountVectorizer(stop_words=text.ENGLISH_STOP_WORDS)
# newsgroups_train.data 和 newsgroups_test.data 已经在之前的代码中被获取
# newsgroups_train = fetch_20newsgroups(subset='train', remove=('headers', 'footers', 'quotes'))
# newsgroups_test = fetch_20newsgroups(subset='test', remove=('headers', 'footers', 'quotes'))
vectors = vectorizer.fit_transform(newsgroups_train.data)
# 创建分类器
classifier = MultinomialNB(alpha=.01)
classifier.fit(vectors, newsgroups_train.target)
vectors_test = vectorizer.transform(newsgroups_test.data)
predictions = classifier.predict(vectors_test)
accuracy_score = metrics.accuracy_score(newsgroups_test.target, predictions)
f1_score = metrics.f1_score(newsgroups_test.target, predictions, average='macro')
print("accuracy score: ", accuracy_score)
print("F1-score: ", f1_score)
Output:
accuracy score: 0.6526818906001062
F1-score: 0.6268816896587931
自动创建停用词 (AUTOMATICALLY CREATED STOP WORDS)
与许多其他情况一样,寻找自动定义停用词列表的方法是一个好主意。这个列表应该理想地适应问题。
为了自动创建停用词列表,我们将从 CountVectorizer 的参数 min_df 开始。当您设置此阈值参数时,文档频率严格低于给定阈值的术语将被忽略。此值在文献中也称为截止点。如果使用 [0.0, 1.0] 范围内的浮点值,则该参数表示文档的比例。整数将被视为绝对计数。如果 vocabulary 不是 None,则此参数将被忽略。
corpus = ["""People say you cannot live without love,
but I think oxygen is more important""",
"Sometimes, when you close your eyes, you cannot see.",
"A horse, a horse, my kingdom for a horse!",
"""Horse sense is the thing a horse has which
keeps it from betting on people.""",
"""I’ve often said there is nothing better for
the inside of the man, than the outside of the horse.""",
"""A man on a horse is spiritually, as well as physically,
bigger then a man on foot.""",
"""No heaven can heaven be, if my horse isn’t there
to welcome me."""]
cv = CountVectorizer(input=corpus, # 这里的 'input=corpus' 是非标准参数,应改为 fit_transform(corpus)
min_df=2)
count_vector = cv.fit_transform(corpus)
print(cv.vocabulary_)
Output:
{'people': 7,
'you': 9,
'cannot': 0,
'is': 3,
'horse': 2,
'my': 5,
'for': 1,
'on': 6,
'there': 8,
'man': 4}
我们语料库文本中几乎没有留下任何单词。因为我们的语料库中只有很少的文档(字符串),而且这些文本非常短,所以出现在少于两个文档中的单词数量非常高。我们消除了所有出现在少于两个文档中的单词。
我们还可以通过查看 cv.stop_words_ 来查看哪些单词被选为停用词:
print(cv.stop_words_)
Output:
{'as',
'be',
'better',
'betting',
'bigger',
'but',
'can',
'close',
'eyes',
'foot',
'from',
'has',
'heaven',
'if',
'important',
'inside',
'isn',
'it',
'keeps',
'kingdom',
'live',
'love',
'me',
'more',
'no',
'nothing',
'of',
'often',
'outside',
'oxygen',
'physically',
'said',
'say',
'see',
'sense',
'sometimes',
'spiritually',
'than',
'the',
'then',
'thing',
'think',
'to',
've',
'welcome',
'well',
'when',
'which',
'without',
'your'}
print("number of docus, size of vocabulary, stop_words list size")
for i in range(len(corpus)):
cv = CountVectorizer(input=corpus, # 这里的 'input=corpus' 是非标准参数,应改为 fit_transform(corpus)
min_df=i)
count_vector = cv.fit_transform(corpus)
len_voc = len(cv.vocabulary_)
len_stop_words = len(cv.stop_words_)
print(f"{i:10d} {len_voc:15d} {len_stop_words:19d}")
Output:
number of docus, size of vocabulary, stop_words list size
0 42 0 # min_df=0 会保留所有词,stop_words_为空集
1 42 0 # min_df=1 也会保留所有词,因为它表示至少出现1次的词
2 17 25 # (42-17)=25
3 10 32 # (42-10)=32
4 6 36 # (42-6)=36
5 3 39 # (42-3)=39
请注意,上述输出中的数字似乎是针对不同的语料库或在不同运行中生成的,因为我的测试显示 len_voc 和 len_stop_words 的值与您提供的输出不完全匹配。但逻辑是:len_stop_words 是总词汇量减去 len_voc。
CountVectorizer 的另一个参数是 max_df,我们可以用它来创建语料库特定的 stop_words_list。它可以是介于 0.0 和 1.0 之间的浮点值或整数。默认值是 1.0,即浮点值 1.0 而不是整数 1!在构建词汇表时,文档频率严格高于给定阈值的所有术语都将被忽略。如果此参数给定为介于 0.0 和 1.0 之间的浮点数,则该参数表示文档的比例。如果 vocabulary 不是 None,则此参数将被忽略。
让我们再次使用我们之前的语料库作为示例。
cv = CountVectorizer(input=corpus, # 这里的 'input=corpus' 是非标准参数,应改为 fit_transform(corpus)
max_df=0.20)
count_vector = cv.fit_transform(corpus)
print(cv.stop_words_)
Output:{'jumped',<br>'remains',<br>'swart',<br>'pendant',<br>'pier',<br>'felicity',<br>'senor',<br>'solidity',<br>'regularly',<br>'escape',<br>'adds',<br>'dirty',<br>'struggled',<br>'meadow',<br>'differences',<br>'poser',<br>'comparative',<br>'jerkin',<br>'pleasant',<br>'principal',<br>'hangs',<br>'spiral',<br>'connection',<br>'diametrically',<br>'xxviii',<br>'magistrate',<br>'wickedly',<br>'battened',<br>'willy',<br>'breakfasting',<br>'invented',<br>'ejaculation',<br>'confer',<br>'anderson',<br>'pupils',<br>'92',<br>'click',<br>'alight',<br>'hoofs',<br>'disasters',<br>'monosyllables',<br>'admirers',<br>'traffic',<br>'ushered',<br>'littleness',<br>'labors',<br>369<br>'telegraph',<br>'disembodied',<br>'delude',<br>'lawless',<br>'conduct',<br>'belie',<br>'morning',<br>'deeds',<br>'manners',<br>'foot',<br>'politeness',<br>'persia',<br>'ruler',<br>'divorced',<br>'vainly',<br>'opens',<br>'pellet',<br>'palace',<br>'chanson',<br>'result',<br>'wipe',<br>'passed',<br>'hoot',<br>'daringly',<br>'beforehand',<br>'qualifying',<br>'gazers',<br>'exported',<br>'chuckling',<br>'shaven',<br>'prostitute',<br>'grudging',<br>'barque',<br>'companies',<br>'birthright',<br>'analysis',<br>'reserved',<br>'pre',<br>'swagger',<br>'walls',<br>'unquestionable',<br>'unutterable',<br>'drive',<br>'willingness',<br>'attempts',<br>'helplessly',<br>370<br>'serge',<br>'eaters',<br>'tear',<br>'sooty',<br>'friar',<br>'insertions',<br>'prosper',<br>'pennies',<br>'tilt',<br>'christians',<br>'cultured',<br>'accursed',<br>'entrusted',<br>'coat',<br>'traced',<br>'piers',<br>'healthier',<br>'garbage',<br>'tougher',<br>'jogs',<br>'glows',<br>'starved',<br>'vitiated',<br>'hails',<br>'scan',<br>'measured',<br>'diamond',<br>'lot',<br>'enough',<br>'predominating',<br>'unaware',<br>'embalming',<br>'abounded',<br>'jawed',<br>'ptolemy',<br>'usefully',<br>'theatre',<br>'transports',<br>'snuffed',<br>'weeps',<br>'friendship',<br>'cloths',<br>'snowy',<br>'absorb',<br>'partnership',<br>'assurances',<br>371<br>'infanticide',<br>'wondrously',<br>'arrogance',<br>'allegiance',<br>'feebly',<br>'temperament',<br>'operas',<br>'ample',<br>'darkening',<br>'fascination',<br>'churches',<br>'whispers',<br>'highlander',<br>'protestant',<br>'ludicrous',<br>'bravery',<br>'commented',<br>'ham',<br>'79',<br>'hoops',<br>'turtle',<br>'pretences',<br>'bloodiest',<br>'turnips',<br>'priest',<br>'precipitous',<br>'murmured',<br>'endless',<br>'imagining',<br>'icebergs',<br>'grounds',<br>'cruise',<br>'madame',<br>'witty',<br>'implicit',<br>'squeeze',<br>'itself',<br>'splintered',<br>'waterloo',<br>'overjoyed',<br>'undertook',<br>'vibration',<br>'distinguishable',<br>'retirement',<br>'diverting',<br>'actions',<br>372<br>'tied',<br>'academy',<br>'respectfully',<br>'asses',<br>'laugh',<br>'peas',<br>'stabs',<br>'daughters',<br>'identified',<br>'unrelenting',<br>'inverted',<br>'inn',<br>'improvement',<br>'sucklings',<br>'conceals',<br>'tiptoe',<br>'displaced',<br>'allowing',<br>'baton',<br>'superior',<br>'softly',<br>'introspective',<br>'breakers',<br>'affectionately',<br>'hamlet',<br>'blaming',<br>'bondage',<br>'card',<br>'calculations',<br>'fix',<br>'manservant',<br>'muscles',<br>'armada',<br>'sacrificed',<br>'choke',<br>'invoking',<br>'freed',<br>'cricket',<br>'catalogue',<br>'oatmeal',<br>'excursion',<br>'cans',<br>'displays',<br>'bulb',<br>'ventilated',<br>'follies',<br>373<br>'filth',<br>'stunned',<br>'brasses',<br>'japanese',<br>'calling',<br>'rail',<br>'possession',<br>'wrist',<br>'sustained',<br>'rammed',<br>'estate',<br>'blurted',<br>'pavements',<br>'finds',<br>'250',<br>'steeple',<br>'enlarged',<br>'blew',<br>'throng',<br>'nasty',<br>'stiffness',<br>'landslip',<br>'wailing',<br>'past',<br>'navel',<br>'bedside',<br>'slunk',<br>'lapland',<br>'carriage',<br>'victoria',<br>'adoration',<br>'narration',<br>'contraction',<br>'prelude',<br>'breaths',<br>'energetically',<br>'hail',<br>'darker',<br>'bawl',<br>'reasonably',<br>'contracting',<br>'miraculously',<br>'48',<br>'entertaining',<br>'consistently',<br>'fond',<br>374<br>'groaned',<br>'characteristics',<br>'smelt',<br>'buzz',<br>'gums',<br>'unmatched',<br>'get',<br>'watchful',<br>'cities',<br>'suit',<br>'conference',<br>'wax',<br>'preparing',<br>'overdone',<br>'wretched',<br>'striving',<br>'della',<br>'drudged',<br>'stolid',<br>'pierce',<br>'sorrowing',<br>'kink',<br>'slit',<br>'audible',<br>'entertainments',<br>'gradations',<br>'excessively',<br>'indolence',<br>'ballrooms',<br>'tolerably',<br>'midsummer',<br>'spanish',<br>'fiendish',<br>'distraction',<br>'defect',<br>'leaps',<br>'21',<br>'flexible',<br>'token',<br>'stammered',<br>'positively',<br>'create',<br>'cobweb',<br>'thinks',<br>'started',<br>'punishments',<br>375<br>'parallel',<br>'needs',<br>'alive',<br>'drudgery',<br>'protecting',<br>'generous',<br>'cant',<br>'stung',<br>'fallow',<br>'iv',<br>'thunderbolts',<br>'plainly',<br>'sounding',<br>'assist',<br>'quiver',<br>'slightly',<br>'apprehension',<br>'cheated',<br>'flippancy',<br>'essentially',<br>'suggest',<br>'startling',<br>'positive',<br>'lipped',<br>'escapes',<br>'dazzling',<br>'immensity',<br>'dining',<br>'plums',<br>'creed',<br>'conventionality',<br>'lavish',<br>'retraced',<br>'resembled',<br>'forgiveness',<br>'avis',<br>'grounded',<br>'seen',<br>'recoiled',<br>'sometime',<br>'pollen',<br>'scalding',<br>'foresaw',<br>'disorder',<br>'worst',<br>'sheepish',<br>376<br>'proportionate',<br>'immaterial',<br>'squander',<br>'occasions',<br>'pulpy',<br>'researches',<br>'chestnut',<br>'peer',<br>'muddled',<br>'prospect',<br>'sails',<br>'beat',<br>'stab',<br>'settees',<br>'expectancy',<br>'thump',<br>'dizzily',<br>'lose',<br>'abode',<br>'advertising',<br>'paces',<br>'st',<br>'solicited',<br>'workmen',<br>'exert',<br>'discharged',<br>'relapsed',<br>'observe',<br>'implored',<br>'ter',<br>'deformed',<br>'keep',<br>'dominance',<br>'journeys',<br>'buffalo',<br>'humbly',<br>'harp',<br>'wasted',<br>'grammar',<br>'err',<br>'assurance',<br>'oiled',<br>'frayed',<br>'fowls',<br>'imperatively',<br>'threatened',<br>377<br>'notepaper',<br>'unsuccessful',<br>'practices',<br>'disagree',<br>'solomon',<br>'design',<br>'graved',<br>'handing',<br>'kee',<br>'sanctity',<br>'incumbent',<br>'precipitate',<br>'approval',<br>'promoting',<br>'obliquity',<br>'comfort',<br>'lowers',<br>'escaped',<br>'withhold',<br>'stretching',<br>'lacking',<br>'policeman',<br>'grouped',<br>'opposite',<br>'arena',<br>'stubbs',<br>'honest',<br>'vestige',<br>'travellers',<br>'groan',<br>'hypothesis',<br>'persist',<br>'levers',<br>'happened',<br>'pearson',<br>'snort',<br>'duly',<br>'bernard',<br>'tightly',<br>'mature',<br>'balloon',<br>'obscurity',<br>'undaunted',<br>'soiled',<br>'justify',<br>'buttered',<br>378<br>'gilbert',<br>'reversed',<br>'restrain',<br>'intellect',<br>'limitations',<br>'difference',<br>'squares',<br>'tortoise',<br>'merits',<br>'jump',<br>'belvedere',<br>'brightness',<br>'coupled',<br>'objection',<br>'spruce',<br>'circuit',<br>'sunk',<br>'paused',<br>'cramped',<br>'medical',<br>'gallons',<br>'hoisted',<br>'moonlit',<br>'penned',<br>'spear',<br>'obedience',<br>'uncontrollable',<br>'blithe',<br>'feats',<br>'bony',<br>'stroll',<br>'complained',<br>'ornamented',<br>'albatrosses',<br>'baptismal',<br>'careering',<br>'hiss',<br>'certain',<br>'powers',<br>'swamped',<br>'aback',<br>'margaret',<br>'characters',<br>'ragged',<br>'visitors',<br>'propriety',<br>379<br>'index',<br>'mare',<br>'anew',<br>'laurel',<br>'frenzy',<br>'symbols',<br>'babyish',<br>'cheaply',<br>'meals',<br>'specially',<br>'ourselves',<br>'sounds',<br>'secret',<br>'cursing',<br>'noon',<br>'archbishop',<br>'miseries',<br>'mistakes',<br>'vaughan',<br>'flaming',<br>'meanings',<br>'shock',<br>'deepest',<br>'afterwards',<br>'bounced',<br>'caramba',<br>'conceal',<br>'delusions',<br>'worth',<br>'section',<br>'fullness',<br>'privileged',<br>'barrow',<br>'compile',<br>'manage',<br>'animosity',<br>'recognise',<br>'uninteresting',<br>'systems',<br>'riches',<br>'endeavours',<br>'diddled',<br>'investigations',<br>'southerly',<br>'flats',<br>'realizing',<br>380<br>'situated',<br>'proximity',<br>'stays',<br>'slogan',<br>'staring',<br>'ineffectually',<br>'burn',<br>'fickle',<br>'oath',<br>'homecoming',<br>'weekly',<br>'record',<br>'likewise',<br>'winks',<br>'xxxiv',<br>'conception',<br>'haunts',<br>'athenian',<br>'nourishment',<br>'beard',<br>'audience',<br>'genesis',<br>'timely',<br>'observing',<br>'entreaty',<br>'eclipsed',<br>'reappeared',<br>'salted',<br>'shaky',<br>'virgin',<br>'majesty',<br>'alterations',<br>'masculine',<br>'strained',<br>'puddings',<br>'oxford',<br>'algebra',<br>'flannelette',<br>'shall',<br>'reckoning',<br>'newspapers',<br>'proclaimed',<br>'lament',<br>'curdling',<br>'frustrate',<br>'professors',<br>381<br>'lectures',<br>'phrase',<br>'exacted',<br>'basso',<br>'strait',<br>'climbing',<br>'avail',<br>'weather',<br>'long',<br>'abroad',<br>'impassive',<br>'painted',<br>'haters',<br>'philip',<br>'broken',<br>'ignoring',<br>'swore',<br>'worry',<br>'extension',<br>'longest',<br>'bareheaded',<br>'bog',<br>'meet',<br>'yonder',<br>'accompany',<br>'lovable',<br>'drawn',<br>'regular',<br>'demon',<br>'die',<br>'wouldst',<br>'unrest',<br>'fancied',<br>'dangled',<br>'listens',<br>'list',<br>'smoked',<br>'doubtfully',<br>'masses',<br>'learned',<br>'incomprehensible',<br>'grass',<br>'loth',<br>'tract',<br>'greetings',<br>'misgiving',<br>382<br>'literature',<br>'stain',<br>'trent',<br>'determination',<br>'sufficiency',<br>'bangle',<br>'hurried',<br>'spur',<br>'metropolis',<br>'king',<br>'inconsistent',<br>'clown',<br>'hopelessness',<br>'ticked',<br>'eldest',<br>'interested',<br>'suburban',<br>'lisp',<br>'youths',<br>'raptures',<br>'partitions',<br>'poverty',<br>'effigy',<br>'dawn',<br>'existence',<br>'clatter',<br>'lt',<br>'tiresome',<br>'credited',<br>'howled',<br>'besides',<br>'borrow',<br>'gnawing',<br>'treason',<br>'speaking',<br>'film',<br>'hysterical',<br>'razor',<br>'rabble',<br>'thirds',<br>'flour',<br>'smiled',<br>'twas',<br>'beastly',<br>'feeding',<br>'female',<br>383<br>'amiable',<br>'renewed',<br>'established',<br>'unmarried',<br>'railing',<br>'fluttered',<br>'stole',<br>'confinement',<br>'pouch',<br>'slay',<br>'india',<br>'relentless',<br>'sweep',<br>'upbraid',<br>'disdain',<br>'broadcloth',<br>'poet',<br>'antarctic',<br>'bottomless',<br>'accidentally',<br>'snores',<br>'imps',<br>'quarts',<br>'divert',<br>'sceptical',<br>'strength',<br>'neighbor',<br>'ends',<br>'initiated',<br>'reprimand',<br>'whaler',<br>'soothed',<br>'blimey',<br>'friends',<br>'passionate',<br>'whereupon',<br>'terrors',<br>'redoubled',<br>'kindle',<br>'finance',<br>'pico',<br>'hand',<br>'excellency',<br>'drugged',<br>'inspired',<br>'warehouses',<br>384<br>'apoplectic',<br>'expanse',<br>'furled',<br>'stronger',<br>'stretched',<br>'bursts',<br>'celebration',<br>'heathen',<br>'circumpolar',<br>'encased',<br>'twins',<br>'graham',<br>'surveys',<br>'embassy',<br>'fundamentals',<br>'author',<br>'scope',<br>'eulogy',<br>'thanking',<br>'graves',<br>'steer',<br>'inhabit',<br>'solvency',<br>'talked',<br>'withdrew',<br>'risked',<br>'slanted',<br>'dane',<br>'cove',<br>'obtain',<br>'belt',<br>'tasting',<br>'forfeited',<br>'ugly',<br>'term',<br>'routine',<br>'curving',<br>'immaculate',<br>'instead',<br>'trophies',<br>'sunday',<br>'ridicule',<br>'skirted',<br>'launch',<br>'greasy',<br>'homely',<br>385<br>'peacock',<br>'firearms',<br>'swelling',<br>'promise',<br>'cheerfully',<br>'interest',<br>'numbers',<br>'sou',<br>'whitened',<br>'distrustful',<br>'beaker',<br>'stiffening',<br>'malt',<br>'insanity',<br>'rooms',<br>'circle',<br>'rags',<br>'originals',<br>'blemish',<br>'breakfasts',<br>'butler',<br>'sugary',<br>'sheathed',<br>'scar',<br>'sew',<br>'venom',<br>'chiselled',<br>'indispensable',<br>'winning',<br>'splinter',<br>'open',<br>'calamity',<br>'mendelssohn',<br>'angelo',<br>'presses',<br>'indications',<br>'infallibly',<br>'congregational',<br>'chrysanthemums',<br>'unexpectedness',<br>'conceive',<br>'involves',<br>'bounds',<br>'passenger',<br>'builds',<br>'duke',<br>386<br>'exceeded',<br>'yells',<br>'survived',<br>'market',<br>'prize',<br>'slinking',<br>'begets',<br>'british',<br>'pikes',<br>'pipes',<br>'pieties',<br>'blank',<br>'least',<br>'tom',<br>'burglars',<br>'sternness',<br>'crops',<br>'villainy',<br>'herring',<br>'cobbler',<br>'shallowest',<br>'lifting',<br>'reaped',<br>'respite',<br>'ganders',<br>'crow',<br>'robin',<br>'rude',<br>'purely',<br>'actress',<br>'surrey',<br>'fooling',<br>'dilating',<br>'lagoons',<br>'rod',<br>'chaplain',<br>'contact',<br>'blotch',<br>'unanswerable',<br>'deplorable',<br>'arrested',<br>'azure',<br>'tottenham',<br>'confirmation',<br>'phil',<br>'gangs',<br>387<br>'mermaids',<br>'paled',<br>'quietude',<br>'moody',<br>'imperious',<br>'replacing',<br>'seized',<br>'lasted',<br>'restricted',<br>'nobody',<br>'braiding',<br>'illustrations',<br>'suspended',<br>'distinct',<br>'gilt',<br>'happen',<br>'australia',<br>'lotion',<br>'absence',<br>'contradicting',<br>'note',<br>'phrased',<br>'dashing',<br>'magnifying',<br>'pursed',<br>'infinitesimal',<br>'service',<br>'gout',<br>'deciphered',<br>'furnishing',<br>'hollow',<br>'youngest',<br>'police',<br>'multitudinous',<br>'brains',<br>'flows',<br>'vernacular',<br>'virtue',<br>'nurtured',<br>'cheeks',<br>'delivered',<br>'elderly',<br>'magical',<br>'salutes',<br>'despising',<br>'moods',<br>388<br>'correctness',<br>'habit',<br>'outwardly',<br>'darwin',<br>'someone',<br>'derelict',<br>'embodied',<br>'wonderful',<br>'pussy',<br>'1846',<br>'4d',<br>'sheep',<br>'extent',<br>'wapping',<br>'bundling',<br>'smeared',<br>'toilet',<br>'inconsiderate',<br>'bountifully',<br>'incandescence',<br>'smoking',<br>'trust',<br>'father',<br>'backwards',<br>'thee',<br>'tornado',<br>'avenger',<br>'plumped',<br>'grouse',<br>'secrets',<br>'majority',<br>'staves',<br>'crutch',<br>'wakes',<br>'saddened',<br>'kine',<br>'nods',<br>'indifferently',<br>'butteries',<br>'charades',<br>'feelings',<br>'locking',<br>'librarian',<br>'greying',<br>'house',<br>'grudgingly',<br>389<br>'much',<br>'expound',<br>'marshalled',<br>'stillness',<br>'mirth',<br>'hours',<br>'everlasting',<br>'surf',<br>'appellation',<br>'trampled',<br>'porch',<br>'looping',<br>'justification',<br>'honestly',<br>'lamentable',<br>'musical',<br>'prodding',<br>'captain',<br>'procrastination',<br>'sneaking',<br>'smiles',<br>'tranquil',<br>'preservation',<br>'navigator',<br>'technically',<br>'daisy',<br>'boredom',<br>'twisting',<br>'speed',<br>'creamy',<br>'documents',<br>'tum',<br>'82',<br>'unwieldy',<br>...}
练习 (EXERCISES)
练习 1 (EXERCISE 1)
在子目录 'books' 中,您会找到一些书籍:
-
弗吉尼亚·伍尔夫 (Virginia Woolf): 《昼与夜》(Night and Day)
-
塞缪尔·巴特勒 (Samuel Butler): 《众生之路》(The Way of all Flesh)
-
赫尔曼·梅尔维尔 (Herman Melville): 《白鲸》(Moby Dick)
-
戴维·赫伯特·劳伦斯 (David Herbert Lawrence): 《儿子与情人》(Sons and Lovers)
-
丹尼尔·笛福 (Daniel Defoe): 《鲁滨逊漂流记》(The Life and Adventures of Robinson Crusoe)
-
詹姆斯·乔伊斯 (James Joyce): 《尤利西斯》(Ulysses)
将这些小说作为语料库,并创建一个词频向量。
练习 2 (EXERCISE 2)
将之前计算的“词频向量”转换为密集的 ndarray 表示。
练习 3 (EXERCISE 3)
让我们再看一个不同语料库的例子。这五个字符串是著名的引文,分别来自:
-
威廉·莎士比亚 (William Shakespeare)
-
W.C. 菲尔兹 (W.C. Fields)
-
罗纳德·里根 (Ronald Reagan)
-
约翰·斯坦贝克 (John Steinbeck)
-
作者未知
计算它们的 IDF 值!
quotes = ["A horse, a horse, my kingdom for a horse!",
"Horse sense is the thing a horse has which keeps it from betting on people.",
"I’ve often said there is nothing better for the inside of the man, than the outside of the horse.",
"A man on a horse is spiritually, as well as physically, bigger then a man on foot.",
"No heaven can heaven be, if my horse isn’t there to welcome me."]
解决方案 (SOLUTIONS)
练习 1 解决方案 (SOLUTION TO EXERCISE 1)
corpus = []
books = ["night_and_day_virginia_woolf.txt",
"the_way_of_all_flash_butler.txt", # 注意:原文可能是 'flash',但常见书名为 'flesh',这里保留原文
"moby_dick_melville.txt",
"sons_and_lovers_lawrence.txt",
"robinson_crusoe_defoe.txt",
"james_joyce_ulysses.txt"]
path = "books" # 确保 'books' 目录存在且包含这些文件
corpus = []
for book in books:
# 假设文件路径正确
with open(path + "/" + book, 'r', encoding='utf-8') as f: # 显式指定编码以避免错误
txt = f.read()
corpus.append(txt)
print([book[:30] for book in corpus])
Output:
['The Project Gutenberg EBook of',
'The Project Gutenberg eBook, T',
'\nThe Project Gutenberg EBook o',
'The Project Gutenberg EBook of',
'The Project Gutenberg eBook, T',
'\nThe Project Gutenberg EBook o']
我们必须去掉古腾堡(Gutenberg)的页眉和页脚,因为它们不属于小说本身。通过查看文本,我们可以看到作者的作品始于以下类型的行之后:
***START OF THIS PROJECT GUTENBERG ... ***
文本的页脚始于以下行:
***END OF THIS PROJECT GUTENBERG EBOOK ...***
第一个三个星号后面可能有也可能没有空格,或者“the”可能被替换为“this”。
我们可以使用正则表达式来找到小说的起始点:
from sklearn.feature_extraction import text
import re
corpus = []
books = ["night_and_day_virginia_woolf.txt",
"the_way_of_all_flash_butler.txt",
"moby_dick_melville.txt",
"sons_and_lovers_lawrence.txt",
"robinson_crusoe_defoe.txt",
"james_joyce_ulysses.txt"]
path = "books" # 确保 'books' 目录存在且包含这些文件
corpus = []
for book in books:
with open(path + "/" + book, 'r', encoding='utf-8') as f: # 显式指定编码以避免错误
txt = f.read()
# 匹配 START 标记,考虑可选空格和 (THE|THIS)
text_begin = re.search(r"\*\*\* ?START OF (THE|THIS) PROJEC.*?EBOOK.*?\*\*\*", txt, re.DOTALL)
# 匹配 END 标记,考虑可选空格和 (THE|THIS)
text_end = re.search(r"\*\*\* ?END OF (THE|THIS) PROJEC.*?EBOOK.*?\*\*\*", txt, re.DOTALL)
if text_begin and text_end: # 确保找到了起始和结束标记
corpus.append(txt[text_begin.end():text_end.start()])
else:
# 如果没有找到标记,可以决定如何处理,例如跳过或包含整个文本
print(f"Warning: Could not find Gutenberg header/footer in {book}. Appending full text.")
corpus.append(txt)
vectorizer = text.CountVectorizer()
vectorizer.fit(corpus)
token_count_matrix = vectorizer.transform(corpus)
print(token_count_matrix)
Output:
# 由于输出是稀疏矩阵的文本表示,这里给出其结构示例,实际输出会很长且是详细的索引和值对。
# (document_index, vocabulary_index) count
(0, 4) 2
(0, 35) 1
...
(5, 42189) 1
print("Number of words in vocabulary: ", len(vectorizer.vocabulary_))
Output:
Number of words in vocabulary: 42192 # 这个数字会根据实际语料库内容而变化
练习 2 解决方案 (SOLUTION TO EXERCISE 2)
您只需将 toarray 方法应用于 token_count_matrix 即可获得密集的词频矩阵:
dense_token_count_matrix = token_count_matrix.toarray()
print(dense_token_count_matrix)
Output:
array([[ 0, 0, 0, ..., 0, 0, 0],
[19, 0, 0, ..., 0, 0, 0],
[20, 0, 0, ..., 0, 1, 1],
[ 0, 0, 1, ..., 0, 0, 0],
[ 0, 0, 0, ..., 0, 0, 0],
[11, 1, 0, ..., 1, 0, 0]])
练习 3 解决方案 (SOLUTION TO EXERCISE 3)
from sklearn.feature_extraction import text
# 我们的语料库:
quotes = ["A horse, a horse, my kingdom for a horse!",
"Horse sense is the thing a horse has which keeps it from betting on people.",
"I’ve often said there is nothing better for the inside of the man, than the outside of the horse.",
"A man on a horse is spiritually, as well as physically, bigger then a man on foot.",
"No heaven can heaven be, if my horse isn’t there to welcome me."]
vectorizer = text.CountVectorizer()
vectorizer.fit(quotes) # 这一步构建词汇表
vectorized_text = vectorizer.transform(quotes) # 这一步将文本转换为词频向量
tfidf_transformer = text.TfidfTransformer(smooth_idf=True, use_idf=True)
tfidf_transformer.fit(vectorized_text) # 这一步计算 IDF 值
"""
另一种输出数据的方式:
import pandas as pd
df_idf = pd.DataFrame(tfidf_transformer.idf_,
index=vectorizer.get_feature_names_out(), # 推荐使用 get_feature_names_out()
columns=["idf_weight"])
df_idf.sort_values(by=['idf_weight'], inplace=True) # 修正列名和排序方式
print(df_idf)
"""
print(f"{'word':15s}: idf_weight")
word_weight_list = list(zip(vectorizer.get_feature_names_out(), tfidf_transformer.idf_)) # 推荐使用 get_feature_names_out()
word_weight_list.sort(key=lambda x:x[1]) # 按权重(第二个分量)对列表进行排序
for word, idf_weight in word_weight_list:
print(f"{word:15s}: {idf_weight:<span class="hljs-number">4.3</span>f}")
Output:1
word : idf_weight
horse : 1.000
for : 1.511
is : 1.511
man : 1.511
my : 1.511
on : 1.511
there : 1.511
as : 1.916
be : 1.916
better : 1.916
betting : 1.916
bigger : 1.916
can : 1.916
foot : 1.916
from : 1.916
has : 1.916
heaven : 1.916
if : 1.916
inside : 1.916
isn : 1.916
it : 1.916
keeps : 1.916
kingdom : 1.916
me : 1.916
no : 1.916
nothing : 1.916
of : 1.916
often : 1.916
outside : 1.916
people : 1.916
physically : 1.916
said : 1.916
sense : 1.916
spiritually : 1.916
than : 1.916
the : 1.916
then : 1.916
thing : 1.916
to : 1.916
ve : 1.916
welcome : 1.916
well : 1.916
which : 1.916
脚注 (FOOTNOTES)
-
从逻辑上讲,
toarray和todense是相同的东西,但toarray返回一个ndarray而todense返回一个matrix。 如果您考虑官方 Numpy 文档关于numpy.matrix类所说的内容,您就不应该使用todense!“不再推荐使用此类,即使是用于线性代数。相反,请使用常规数组。该类将来可能会被移除。” (numpy.matrix) (返回)
INTRODUCTION
We mentioned in the introductory chapter of our tutorial that a
spam filter for emails is a typical example of machine learning.
Emails are based on text, which is why a classifier to classify
emails must be able to process text as input. If we look at the
previous examples with neural networks, they always run
directly with numerical values and have a fixed input length. In
the end, the characters of a text also consist of numerical values,
but it is obvious that we cannot simply use a text as it is as input
for a neural network. This means that the text have to be
converted into a numerical representation, e.g. vectors or arrays
of numbers.
We will learn in this tutorial how to encode text in a way which is suitable for machine processing.
BAG-OF-WORDS MODEL
If we want to use texts in machine learning, we need a representation of the text which is usable for Machine
Learning purposes. This means we need a numerical representation. We cannot use texts directly.
In natural language processing and information retrievel the bag-of-words model is of crucial importance. The
bag-of-words model can be used to represent text data in a way which is suitable for machine learning
algorithms. Furthermore, this model is easy and efficient to implement. In the bag-of-words model, a text
(such as a sentence or a document) is represented as the so-called bag (a set or multiset) of its words.
Grammar and word order are ignored.
337
We will use in the following a list of three strings to demonstrate the bag-of-words approach. In linguistics, the
collection of texts used for the experiments or tests is usually called a corpus:
corpus = ["To be, or not to be, that is the question:",
"Whether 'tis nobler in the mind to suffer",
"The slings and arrows of outrageous fortune,"]
We will use the submodule text from sklearn.feature_extraction . This module contains
utilities to build feature vectors from text documents.
from sklearn.feature_extraction import text
CountVectorizer is a class in the module sklearn.feature_extraction.text . It's a class
useful for building a corpus vocabulary. In addition, it produces the numerical representation of text that we
need, i.e. Numpy vectors.
First we need an instance of this class. When we instantiate a CountVectorizer, we can pass some optional
parameters, but it is possible to call it with no arguments, as we will do in the following. Printing the
vectorizer gives us useful information about the default values used when the instance was created:
vectorizer = text.CountVectorizer()
print(vectorizer)
CountVectorizer()
We have now an instance of CountVectorizer, but it has not seen any texts so far. We will use the method
fit to process our previously defined corpus. We learn a vocabulary dictionary of all the tokens (strings) of
the corpus:
vectorizer.fit(corpus)
Output:CountVectorizer()
fit created the vocabulary structure vocabulary_ . This contains the words of the text as keys and a
unique integer value for each word. As the default value for the parameter lowercase is set to True , the
To in the beginning of the text has been turned into to . You may also notice that the vocabulary contains
only words without any punctuation or special character. You can change this behaviour by assigning a regular
expression to the keyword parameter token_pattern of the fit method. The default is set to
(?u)\\b\\w\\w+\\b . The (?u) part of this regular expression is not necessary because it switches on
the re.U ( re.UNICODE ) flag for this expression, which is the default in Python anyway. The minimal
word length will be two characters:
print("Vocabulary: ", vectorizer.vocabulary_)
338
Vocabulary: {'to': 18, 'be': 2, 'or': 10, 'not': 8, 'that': 15,<br>'is': 5, 'the': 16, 'question': 12, 'whether': 19, 'tis': 17, 'nob<br>ler': 7, 'in': 4, 'mind': 6, 'suffer': 14, 'slings': 13, 'and':<br>0, 'arrows': 1, 'of': 9, 'outrageous': 11, 'fortune': 3}
If you only want to see the words without the indices, you can your the method feature_names :
print(vectorizer.get_feature_names())
['and', 'arrows', 'be', 'fortune', 'in', 'is', 'mind', 'nobler',
'not', 'of', 'or', 'outrageous', 'question', 'slings', 'suffer',
'that', 'the', 'tis', 'to', 'whether']
Alternatively, you can apply keys to the vocaulary to keep the ordering:
print(list(vectorizer.vocabulary_.keys()))
['to', 'be', 'or', 'not', 'that', 'is', 'the', 'question', 'whethe
r', 'tis', 'nobler', 'in', 'mind', 'suffer', 'slings', 'and', 'arr
ows', 'of', 'outrageous', 'fortune']
With the aid of transform we will extract the token counts out of the raw text documents. The call will
use the vocabulary which we created with fit :
token_count_matrix = vectorizer.transform(corpus)
print(token_count_matrix)
339
(0,(0,(0,(0,(0,(0,(0,(0,(1,(1,(1,(1,(1,(1,(1,(1,(2,(2,(2,(2,(2,(2,(2,2)
5)
8)
10)
12)
15)
16)
18)
4)
6)
7)
14)
16)
17)
18)
19)
0)
1)
3)
9)
11)
13)
16)
2
1
1
1
1
1
1
2
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
The connection between the corpus, the Vocabulary vocabulary_ and the vector created by
transform can be seen in the following image:
340
We will apply the method toarray on our object token_count_matrix . It will return a dense
ndarray representation of this matrix.
Just in case: You might see that people use sometimes todense instead of toarray .
Do not use todense!1
dense_tcm = token_count_matrix.toarray()
dense_tcm
Output:array([[0, 0, 2, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 1,
0, 2, 0],
[0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1,
1, 1, 1],
[1, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1,
0, 0, 0]])
The rows of this array correspond to the strings of our corpus. The length of a row corresponds to the length of
the vocabulary. The i'th value in a row corresponds to the i'th entry of the list returned by CountVectorizer
341
method get_feature_names. If the value of dense_tcm[i][j] is equal to k , we know the word with the
index j in the vocabulary occurs k times in the string with the index i in the corpus.
This is visualized in the following diagram:
feature_names = vectorizer.get_feature_names()
for el in vectorizer.vocabulary_:
print(el)
to
be
or
not
that
is
the
question
whether
tis
nobler
in
mind
suffer
slings
and
arrows
of
outrageous
fortune
import pandas as pd
pd.DataFrame(data=dense_tcm,
index=['corpus_0', 'corpus_1', 'corpus_2'],
342
columns=vectorizer.get_feature_names())
Output:
and
arrows
be
fortune
in
is
mind
nobler
not
of
or
outrageous
question
corpus_0
0
0
2
0
0
1
0
0
1
0
1
0
corpus_1
0
0
0
0
1
0
1
1
0
0
0
0
corpus_2
1
1
0
1
0
0
0
0
0
1
0
1
word = "be"
i = 1
j = vectorizer.vocabulary_[word]
print("number of times '" + word + "' occurs in:")
for i in range(len(corpus)):
print("
'" + corpus[i] + "': " + str(dense_tcm[i][j]))
number of times 'be' occurs in:
'To be, or not to be, that is the question:': 2
'Whether 'tis nobler in the mind to suffer': 0
'The slings and arrows of outrageous fortune,': 0
We will extract the token counts out of new text documents. Let's use a literally doubtful variation of Hamlet's
famous monologue and check what transform has to say about it. transform will use the vocabulary
which was previously fitted with fit.
txt = "That is the question and it is nobler in the mind."
vectorizer.transform([txt]).toarray()
Output:array([[1, 0, 0, 0, 1, 2, 1, 1, 0, 0, 0, 0, 1, 0, 0, 1, 2,
0, 0, 0]])
print(vectorizer.get_feature_names())
['and', 'arrows', 'be', 'fortune', 'in', 'is', 'mind', 'nobler',
'not', 'of', 'or', 'outrageous', 'question', 'slings', 'suffer',
'that', 'the', 'tis', 'to', 'whether']
print(vectorizer.vocabulary_)
{'to': 18, 'be': 2, 'or': 10, 'not': 8, 'that': 15, 'is': 5, 'th<br>e': 16, 'question': 12, 'whether': 19, 'tis': 17, 'nobler': 7, 'i<br>n': 4, 'mind': 6, 'suffer': 14, 'slings': 13, 'and': 0, 'arrows':<br>1, 'of': 9, 'outrageous': 11, 'fortune': 3}
1
0
0
343
WORD IMPORTANCE
If you look at words like "the", "and" or "of", you will see see that they will occur in nearly all English texts. If
you keep in mind that our ultimate goal will be to differentiate between texts and attribute them to classes,
words like the previously mentioned ones will bear hardly any meaning. If you look at the following corpus,
you can see words like "you", "I" or important words like "Python", "lottery" or "Programmer":
from sklearn.feature_extraction import text
corpus = ["It does not matter what you are doing, just do it!",
"Would you work if you won the lottery?",
"You like Python, he likes Python, we like Python, every
body loves Python!"
"You said: 'I wish I were a Python programmer'",
"You can stay here, if you want to. I would, if I were y
ou."
]
vectorizer = text.CountVectorizer()
vectorizer.fit(corpus)
token_count_matrix = vectorizer.transform(corpus)
print(token_count_matrix)
344
(0,(0,(0,(0,(0,(0,(0,(0,(0,(0,(1,(1,(1,(1,(1,(1,(1,(2,(2,(2,(2,(2,(2,(2,(2,(2,(2,(2,(2,(3,(3,(3,(3,(3,(3,(3,(3,(3,0)
2)
3)
4)
9)
10)
15)
16)
26)
31)
8)
13)
21)
28)
29)
30)
31)
5)
6)
11)
12)
14)
17)
18)
19)
24)
25)
27)
31)
1)
7)
8)
20)
22)
23)
25)
30)
31)
1
1
1
1
2
1
1
1
1
1
1
1
1
1
1
1
2
1
1
2
1
1
1
5
1
1
1
1
2
1
1
2
1
1
1
1
1
3
tf_idf = text.TfidfTransformer()
tf_idf.fit(token_count_matrix)
tf_idf.idf_
345
Output:array([1.91629073, 1.91629073, 1.91629073, 1.91629073, 1.9162
9073,
1.91629073, 1.91629073, 1.91629073, 1.51082562, 1.9162
9073,
1.91629073, 1.91629073, 1.91629073, 1.91629073, 1.9162
9073,
1.91629073, 1.91629073, 1.91629073, 1.91629073, 1.9162
9073,
1.91629073, 1.91629073, 1.91629073, 1.91629073, 1.9162
9073,
1.51082562, 1.91629073, 1.91629073, 1.91629073, 1.9162
9073,
1.51082562, 1.
])
tf_idf.idf_[vectorizer.vocabulary_['python']]
Output:1.916290731874155
da = vectorizer.transform(corpus).toarray()
i = 0
# check how often the word 'would' occurs in the the i'th sentenc
e:
#vectorizer.vocabulary_['would']
word_ind = vectorizer.vocabulary_['would']
da[i][word_ind]
da[:,word_ind]
Output:array([0, 1, 0, 1])
word_weight_list = list(zip(vectorizer.get_feature_names(), tf_id
f.idf_))
word_weight_list.sort(key=lambda x:x[1]) # sort list by the weigh
ts (2nd component)
for word, idf_weight in word_weight_list:
print(f"{word:15s}: {idf_weight:4.3f}")
346
you
if
were
would
are
can
do
does
doing
everybody
he
here
it
just
like
likes
lottery
loves
matter
not
programmer
python
said
stay
the
to
want
we
what
wish
won
work
::::::::::::::::::::::::::::::::1.000
1.511
1.511
1.511
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
from numpy import log
from sklearn.feature_extraction import text
corpus = ["It does not matter what you are doing, just do it!",
"Would you work if you won the lottery?",
"You like Python, he likes Python, we like Python, every
body loves Python!"
"You said: 'I wish I were a Python programmer'",
"You can stay here, if you want to. I would, if I were y
ou."
]
n = len(corpus)
347
# the following variables are used globally (as free variables) i
n the functions
vectorizer = text.CountVectorizer()
vectorizer.fit(corpus)
da = vectorizer.transform(corpus).toarray()
TERM FREQUENCY
We will first define a function for the term frequency.
Some notations:
• f t , d denotes the number of times that a term t occurs in document d
• wc denotes the number of words in a document d
dThe simplest choice to define tf(t,d) is to use the raw count of a term in a document, i.e., the number of times
that term t occurs in document d, which we can denote as f t , d
We can define tf(t, d) in different ways:
••••raw count of a term: tf(t, d) = f t , d
f t , d
term frequency adjusted for document length: tf(t, d) =wc
d
logarithmically scaled frequency: tf(t, d) = log(1 + f t , d)
augmented frequency, to prevent a bias towards longer documents, e.g. raw frequency of the
term divided by the raw frequency of the most occurring term in the document:
ft , d
tf(t, d) = 0.5 + 0.5 ⋅max t ′
∈ d { f t ′ , d }
def tf(t, d, mode="raw"):
""" The Term Frequency 'tf' calculates how often a term 't'
occurs in a document 'd'. ('d': document index)
If t_in_d = Number of times a term t appears in a documen
t d
and no_terms_d = Total number of terms in the document,
tf(t, d) = t_in_d / no_terms_d
"""
if t in vectorizer.vocabulary_:
word_ind = vectorizer.vocabulary_[t]
t_occurences = da[d, word_ind]
# 'd' is the document in
348
dex
else:
t_occurences = 0
if mode == "raw":
result = t_occurences
elif mode == "length":
all_terms = (da[d] > 0).sum() # calculate number of diffe
rent terms in d
result = t_occurences / all_terms
elif mode == "log":
result = log(1 + t_occurences)
elif mode == "augfreq":
result = 0.5 + 0.5 * t_occurences / da[d].max()
return result
We will check the word frequencies for some words:
print("
raw
length log
augmented freq")
for term in ['matter', 'python', 'would']:
for docu_index in range(len(corpus)):
d = corpus[docu_index]
print(f"\n'{term}' in '{d}''")
for mode in ['raw', 'length', 'log', 'augfreq']:
x = tf(term, docu_index, mode=mode)
print(f"{x:7.2f}", end="")
349
raw
length log
augmented freq
'matter' in 'It does not matter what you are doing, just do it!''
1.00
0.10
0.69
0.75
'matter' in 'Would you work if you won the lottery?''
0.00
0.00
0.00
0.50
'matter' in 'You like Python, he likes Python, we like Python, eve
rybody loves Python!You said: 'I wish I were a Python programme
r'''
0.00
0.00
0.00
0.50
'matter' in 'You can stay here, if you want to. I would, if I wer
e you.''
0.00
0.00
0.00
0.50
'python' in 'It does not matter what you are doing, just do it!''
0.00
0.00
0.00
0.50
'python' in 'Would you work if you won the lottery?''
0.00
0.00
0.00
0.50
'python' in 'You like Python, he likes Python, we like Python, eve
rybody loves Python!You said: 'I wish I were a Python programme
r'''
5.00
0.42
1.79
1.00
'python' in 'You can stay here, if you want to. I would, if I wer
e you.''
0.00
0.00
0.00
0.50
'would' in 'It does not matter what you are doing, just do it!''
0.00
0.00
0.00
0.50
'would' in 'Would you work if you won the lottery?''
1.00
0.14
0.69
0.75
'would' in 'You like Python, he likes Python, we like Python, ever
ybody loves Python!You said: 'I wish I were a Python programmer'''
0.00
0.00
0.00
0.50
'would' in 'You can stay here, if you want to. I would, if I were
you.''
1.00
0.11
0.69
0.67
DOCUMENT FREQUENCY
The document frequency df of a term t is defined as the number of documents in the document set that contain
the term t.
df(t) = | {d ∈ D : t ∈ d} |
350
INVERSE DOCUMENT FREQUENCY
The inverse document frequency is a measure of how much information the word provides, i.e., if it's common
or rare across all documents. It is the logarithmically scaled inverse fraction of the document frequency. The
effect of adding 1 to the idf in the equation above is that terms with zero idf, i.e., terms that occur in all
documents in a training set, will not be entirely ignored.
n
idf(t) = log + 1
df ( t )n is the number of documents in the corpus n = | D |
(Note that the idf formula above differs from the standard textbook notation that defines the idf as
n
idf(t) = log.)
df ( t ) + 1The formula above is used, when TfidfTransformer() is called with smooth_idf=False ! If it is called
with smooth_idf=True (the default) the constant 1 is added to the numerator and denominator of the
idf as if an extra document was seen containing every term in the collection exactly once, which prevents zero
divisions:
n +1
idf(t) = log + 1
df ( t ) + 1TERM FREQUENCY–INVERSE DOCUMENT FREQUENCY
tf idf is calculated as the product of tf(t, d) and idf(t):
tf idf(t, d) = tf(t, d) ⋅ idf(t)
A high value of tf–idf means that the term has a high "term frequency" in the given document and a low
"document frequency" in the other documents of the corpus. This means that this wieght can be used to filter
out common terms.
We will program the tf_idf function now:
The helpfile of text.TfidfTransformer explains how tf_idf is calculated:
We will manually program these functions in the following:
def df(t):
""" df(t) is the document frequency of t; the document frequen
cy is
the number of documents in the document set that contain
the term t. """
351
word_ind = vectorizer.vocabulary_[t]
tf_in_docus = da[:, word_ind] # vector with the freqencies of
word_ind in all docus
existence_in_docus = tf_in_docus > 0 # binary vector, existenc
e of word in docus
return existence_in_docus.sum()
#df("would", vectorizer)
def idf(t, smooth_idf=True):
""" idf """
if smooth_idf:
return log((1 + n) / (1 + df(t)) ) + 1
else:
return log(n / df(t) ) + 1
def tf_idf(t, d):
return idf(t) * tf(t, d)
res_idf = []
for word in vectorizer.get_feature_names():
tf_docus = []
res_idf.append([word, idf(word)])
res_idf.sort(key=lambda x:x[1])
for item in res_idf:
print(item)
352
['you', 1.0]
['if', 1.5108256237659907]
['were', 1.5108256237659907]
['would', 1.5108256237659907]
['are', 1.916290731874155]
['can', 1.916290731874155]
['do', 1.916290731874155]
['does', 1.916290731874155]
['doing', 1.916290731874155]
['everybody', 1.916290731874155]
['he', 1.916290731874155]
['here', 1.916290731874155]
['it', 1.916290731874155]
['just', 1.916290731874155]
['like', 1.916290731874155]
['likes', 1.916290731874155]
['lottery', 1.916290731874155]
['loves', 1.916290731874155]
['matter', 1.916290731874155]
['not', 1.916290731874155]
['programmer', 1.916290731874155]
['python', 1.916290731874155]
['said', 1.916290731874155]
['stay', 1.916290731874155]
['the', 1.916290731874155]
['to', 1.916290731874155]
['want', 1.916290731874155]
['we', 1.916290731874155]
['what', 1.916290731874155]
['wish', 1.916290731874155]
['won', 1.916290731874155]
['work', 1.916290731874155]
corpus
Output:['It does not matter what you are doing, just do it!',
'Would you work if you won the lottery?',
"You like Python, he likes Python, we like Python, everybod
y loves Python!You said: 'I wish I were a Python programme
r'",
'You can stay here, if you want to. I would, if I were yo
u.']
for word, word_index in vectorizer.vocabulary_.items():
print(f"\n{word:12s}: ", end="")
for d_index in range(len(corpus)):
353
print(f"{d_index:1d} {tf_idf(word, d_index):3.2f}, ",
d="" )
en
it
does
not
matter
what
you
are
doing
just
do
would
work
if
won
the
lottery
like
python
he
likes
we
everybody
loves
said
wish
were
programmer
can
stay
here
want
to
: 0 3.83, 1 0.00, 2 0.00, 3 0.00,
: 0 1.92, 1 0.00, 2 0.00, 3 0.00,
: 0 1.92, 1 0.00, 2 0.00, 3 0.00,
: 0 1.92, 1 0.00, 2 0.00, 3 0.00,
: 0 1.92, 1 0.00, 2 0.00, 3 0.00,
: 0 1.00, 1 2.00, 2 2.00, 3 3.00,
: 0 1.92, 1 0.00, 2 0.00, 3 0.00,
: 0 1.92, 1 0.00, 2 0.00, 3 0.00,
: 0 1.92, 1 0.00, 2 0.00, 3 0.00,
: 0 1.92, 1 0.00, 2 0.00, 3 0.00,
: 0 0.00, 1 1.51, 2 0.00, 3 1.51,
: 0 0.00, 1 1.92, 2 0.00, 3 0.00,
: 0 0.00, 1 1.51, 2 0.00, 3 3.02,
: 0 0.00, 1 1.92, 2 0.00, 3 0.00,
: 0 0.00, 1 1.92, 2 0.00, 3 0.00,
: 0 0.00, 1 1.92, 2 0.00, 3 0.00,
: 0 0.00, 1 0.00, 2 3.83, 3 0.00,
: 0 0.00, 1 0.00, 2 9.58, 3 0.00,
: 0 0.00, 1 0.00, 2 1.92, 3 0.00,
: 0 0.00, 1 0.00, 2 1.92, 3 0.00,
: 0 0.00, 1 0.00, 2 1.92, 3 0.00,
: 0 0.00, 1 0.00, 2 1.92, 3 0.00,
: 0 0.00, 1 0.00, 2 1.92, 3 0.00,
: 0 0.00, 1 0.00, 2 1.92, 3 0.00,
: 0 0.00, 1 0.00, 2 1.92, 3 0.00,
: 0 0.00, 1 0.00, 2 1.51, 3 1.51,
: 0 0.00, 1 0.00, 2 1.92, 3 0.00,
: 0 0.00, 1 0.00, 2 0.00, 3 1.92,
: 0 0.00, 1 0.00, 2 0.00, 3 1.92,
: 0 0.00, 1 0.00, 2 0.00, 3 1.92,
: 0 0.00, 1 0.00, 2 0.00, 3 1.92,
: 0 0.00, 1 0.00, 2 0.00, 3 1.92,
ANOTHER SIMPLE EXAMPLE
We will use another simple example to illustrate the previously introduced concepts. We use a sentence which
contains solely different words. The corpus consists of this sentence and reduced versions of it, i.e. cutting of
words from the end of the sentence.
from sklearn.feature_extraction import text
words = "Cold wind blows over the cornfields".split()
354
corpus = []
for i in range(1, len(words)+1):
corpus.append(" ".join(words[:i]))
print(corpus)
['Cold', 'Cold wind', 'Cold wind blows', 'Cold wind blows over',
'Cold wind blows over the', 'Cold wind blows over the cornfields']
vectorizer = text.CountVectorizer()
vectorizer = vectorizer.fit(corpus)
vectorized_text = vectorizer.transform(corpus)
tf_idf = text.TfidfTransformer()
tf_idf.fit(vectorized_text)
tf_idf.idf_
Output:array([1.33647224, 1.
9786,
1.15415068])
, 2.25276297, 1.55961579, 1.8472
word_weight_list = list(zip(vectorizer.get_feature_names(), tf_id
f.idf_))
word_weight_list.sort(key=lambda x:x[1]) # sort list by the weigh
ts (2nd component)
for word, idf_weight in word_weight_list:
print(f"{word:15s}: {idf_weight:4.3f}")
cold
wind
blows
over
the
cornfields
::::::1.000
1.154
1.336
1.560
1.847
2.253
TfidF = text.TfidfTransformer(smooth_idf=True, use_idf=True)
tfidf = TfidF.fit_transform(vectorized_text)
word_weight_list = list(zip(vectorizer.get_feature_names(), tf_id
f.idf_))
word_weight_list.sort(key=lambda x:x[1]) # sort list by the weigh
ts (2nd component)
for word, idf_weight in word_weight_list:
355
print(f"{word:15s}: {idf_weight:4.3f}")
cold
wind
blows
over
the
cornfields
::::::1.000
1.154
1.336
1.560
1.847
2.253
WORKING WITH REAL DATA
scikit-learn contains a dataset from real newsgroups, which can be used for our purposes:
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer
import numpy as np
# Create our vectorizer
vectorizer = CountVectorizer()
# Let's fetch all the possible text data
newsgroups_data = fetch_20newsgroups()
Let us have a closer look at this data. As with all the other data sets in sklearnunder the attribute data :
print(newsgroups_data.data[0])
we can find the actual data
356
From: lerxst@wam.umd.edu (where's my thing)
Subject: WHAT car is this!?
Nntp-Posting-Host: rac3.wam.umd.edu
Organization: University of Maryland, College Park
Lines: 15
I was wondering if anyone out there could enlighten me on this ca
r I saw
the other day. It was a 2-door sports car, looked to be from the l
ate 60s/
early 70s. It was called a Bricklin. The doors were really small.
In addition,
the front bumper was separate from the rest of the body. This is
all I know. If anyone can tellme a model name, engine specs, years
of production, where this car is made, history, or whatever info y
ou
have on this funky looking car, please e-mail.
Thanks,
- IL
---- brought to you by your neighborhood Lerxst ----
print(newsgroups_data.data[200])
357
Subject: Re: "Proper gun control?" What is proper gun cont
From: kim39@scws8.harvard.edu (John Kim)
Organization: Harvard University Science Center
Nntp-Posting-Host: scws8.harvard.edu
Lines: 17
In article <C5JGz5.34J@SSD.intel.com> hays@ssd.intel.com (Kirk Hay
s) writes:
>I'd like to point out that I was in error - "Terminator" began po
sting only
>six months before he purchased his first firearm, according to pr
ivate email
>from him.
>I can't produce an archived posting of his earlier than January 1
992,
>and he purchased his first firearm in March 1992.
>I guess it only seemed like years.
>Kirk Hays - NRA Life, seventh generation.
I first read and consulted rec.guns in the summer of 1991. I
just purchased my first firearm in early March of this year.
NOt for lack of desire for a firearm, you understand.
I could
have purchased a rifle or shotgun but didn't want one.
-Case Kim
We create the vectorizer :
vectorizer.fit(newsgroups_data.data)
Output:CountVectorizer()
Let's have a look at the first n words:
counter = 0
n = 10
for word, index in vectorizer.vocabulary_.items():
print(word, index)
counter += 1
if counter > n:
break
358
from 56979
lerxst 75358
wam 123162
umd 118280
edu 50527
where 124031
my 85354
thing 114688
subject 111322
what 123984
car 37780
We can turn the newsgroup postings into arrays. We do it with the first one:
a = vectorizer.transform([newsgroups_data.data[0]]).toarray()[0]
print(a)
[0 0 0 ... 0 0 0]
The vocabulary is huge This is why we see mostly zeros.
len(vectorizer.vocabulary_)
Output:130107
There are a lot of 'rubbish' words in this vocabulary. rubish means seen from the perspective of machine
learning. For machine learning purposes words like 'Subject', 'From', 'Organization', 'Nntp-Posting-Host',
'Lines' and many others are useless, because they occur in all or in most postings. The technical 'garbage' from
the newsgroup can be easily stripped off. We can fetch it differently. Stating that we do not want 'headers',
'footers' and 'quotes':
newsgroups_data_cleaned = fetch_20newsgroups(remove=('headers', 'f
ooters', 'quotes'))
print(newsgroups_data_cleaned.data[0])
359
I was wondering if anyone out there could enlighten me on this ca
r I saw
the other day. It was a 2-door sports car, looked to be from the l
ate 60s/
early 70s. It was called a Bricklin. The doors were really small.
In addition,
the front bumper was separate from the rest of the body. This is
all I know. If anyone can tellme a model name, engine specs, years
of production, where this car is made, history, or whatever info y
ou
have on this funky looking car, please e-mail.
Let's have a look at the complete posting:
print(newsgroups_data.data[0])
From: lerxst@wam.umd.edu (where's my thing)
Subject: WHAT car is this!?
Nntp-Posting-Host: rac3.wam.umd.edu
Organization: University of Maryland, College Park
Lines: 15
I was wondering if anyone out there could enlighten me on this ca
r I saw
the other day. It was a 2-door sports car, looked to be from the l
ate 60s/
early 70s. It was called a Bricklin. The doors were really small.
In addition,
the front bumper was separate from the rest of the body. This is
all I know. If anyone can tellme a model name, engine specs, years
of production, where this car is made, history, or whatever info y
ou
have on this funky looking car, please e-mail.
Thanks,
- IL
---- brought to you by your neighborhood Lerxst ----
vectorizer_cleaned = vectorizer.fit(newsgroups_data_cleaned.data)
len(vectorizer_cleaned.vocabulary_)
360
Output:101631
So, we got rid of more than 30000 words, but with more than a 100000 words is it still very large.
We can also directly separate the newsgroup feeds into a train and test set:
newsgroups_train = fetch_20newsgroups(subset='train',
remove=('headers', 'footer
s', 'quotes'))
newsgroups_test = fetch_20newsgroups(subset='test',
remove=('headers', 'footer
s', 'quotes'))
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
vectorizer = CountVectorizer()
train_data = vectorizer.fit_transform(newsgroups_train.data)
# creating a classifier
classifier = MultinomialNB(alpha=.01)
classifier.fit(train_data, newsgroups_train.target)
test_data = vectorizer.transform(newsgroups_test.data)
predictions = classifier.predict(test_data)
accuracy_score = metrics.accuracy_score(newsgroups_test.target,
predictions)
f1_score = metrics.f1_score(newsgroups_test.target,
predictions,
average='macro')
print("Accuracy score: ", accuracy_score)
print("F1 score: ", f1_score)
Accuracy score: 0.6460435475305364
F1 score: 0.6203806145034193
361
STOP WORDS
So far we added all the words to the vocabulary. However, it is questionable whether words like "the", "am",
"were" or similar words should be included at all, since they usually do not provide any significant semantic
contribution for a text. In other words: They have limited predictive power. It would therefore make sense to
exclude such words from editing, i.e. inclusion in the dictionary. This means we have to provide a list of
words which should be neglected, i.e. being filtered out before or after processing text. In natural text
recognition such words are usually called "stop words". There is no single universal list of stop words defined,
which could be used by all natural language processing tools. Usually, stop words consist of the most
frequently used words in a language. "Stop words" can be individually chosen for a given task.
By the way, stop words are an idea which is quite old. It goes back to 1959 and Hans Peter Luhn, one of the
pioneers in information retrieval.
There are different ways to provide stop words in sklearn :
• Explicit list of stop words
• Automatically created stop words
We will start with individual stop words:
INDIVUDUAL STOP WORDS
from sklearn.feature_extraction.text import CountVectorizer
corpus = ["A horse, a horse, my kingdom for a horse!",
"Horse sense is the thing a horse has which keeps it fro
m betting on people."
"I’ve often said there is nothing better for the inside
of the man, than the outside of the horse.",
362
"A man on a horse is spiritually, as well as physicall
y, bigger then a man on foot.",
"No heaven can heaven be, if my horse isn’t there to wel
come me."]
cv = CountVectorizer(input=corpus,
stop_words=["my", "for","the", "has", "tha
n", "if",
"from", "on", "of", "it", "ther
e", "ve",
"as", "no", "be", "which", "is
n", "to",
"me", "is", "can", "then"])
count_vector = cv.fit_transform(corpus)
count_vector.shape
cv.vocabulary_
Output:{'horse': 5,<br>'kingdom': 8,<br>'sense': 16,<br>'thing': 18,<br>'keeps': 7,<br>'betting': 1,<br>'people': 13,<br>'often': 11,<br>'said': 15,<br>'nothing': 10,<br>'better': 0,<br>'inside': 6,<br>'man': 9,<br>'outside': 12,<br>'spiritually':'well': 20,<br>'physically': 14,<br>'bigger': 2,<br>'foot': 3,<br>'heaven': 4,<br>'welcome': 19}
17,
sklearn contains default stop words, which are implemented as a frozenset and it can be accessed
with text.ENGLISH_STOP_WORDS :
from sklearn.feature_extraction import text
n = 25
363
print(str + " arbitrary words from ENGLISH_STOP_WORDS:")
counter = 0
for word in text.ENGLISH_STOP_WORDS:
if counter == n - 1:
print(word)
break
print(word, end=", ")
counter += 1
25 arbitrary words from ENGLISH_STOP_WORDS:
over, it, anywhere, all, toward, every, inc, had, been, being, wit
hout, thence, mine, whole, by, below, when, beside, nevertheless,
at, beforehand, after, several, throughout, eg
We can use stop words in our 20newsgroups classification problem:
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
vectorizer = CountVectorizer(stop_words=text.ENGLISH_STOP_WORDS)
vectors = vectorizer.fit_transform(newsgroups_train.data)
# creating a classifier
classifier = MultinomialNB(alpha=.01)
classifier.fit(vectors, newsgroups_train.target)
vectors_test = vectorizer.transform(newsgroups_test.data)
predictions = classifier.predict(vectors_test)
accuracy_score = metrics.accuracy_score(newsgroups_test.target,
predictions)
f1_score = metrics.f1_score(newsgroups_test.target,
predictions,
average='macro')
print("accuracy score: ", accuracy_score)
print("F1-score: ", f1_score)
accuracy score: 0.6526818906001062
F1-score: 0.6268816896587931
364
AUTOMATICALLY CREATED STOP WORDS
As in many other cases, it is a good idea to look for ways to automatically define a list of stop words. A list
that is or should be ideally adapted to the problem.
To automatically create a stop word list, we will start with the parameter min_df of
CountVectorizer . When you set this threshold parameter, terms that have a document frequency strictly
lower than the given threshold will be ignored. This value is also called cut-off in the literature. If a float value
in the range of [0.0, 1.0] is used, the parameter represents a proportion of documents. An integer will be
treated as absolute counts. This parameter is ignored if vocabulary is not None.
corpus = ["""People say you cannot live without love,
but I think oxygen is more important""",
"Sometimes, when you close your eyes, you cannot see."
"A horse, a horse, my kingdom for a horse!",
"""Horse sense is the thing a horse has which
keeps it from betting on people."""
"""I’ve often said there is nothing better for
the inside of the man, than the outside of the hors
e.""",
"""A man on a horse is spiritually, as well as physicall
y,
bigger then a man on foot.""",
"""No heaven can heaven be, if my horse isn’t there
to welcome me."""]
cv = CountVectorizer(input=corpus,
min_df=2)
count_vector = cv.fit_transform(corpus)
cv.vocabulary_
Output:{'people': 7,<br>'you': 9,<br>'cannot': 0,<br>'is': 3,<br>'horse': 2,<br>'my': 5,<br>'for': 1,<br>'on': 6,<br>'there': 8,<br>'man': 4}
Hardly any words from our corpus text are left. Because we have only few documents (strings) in our corpus
and also because these texts are very short, the number of words which occur in less then two documents is
very high. We eliminated all the words which occur in less two documents.
365
We can also see the words which have been chosen as stopwords by looking at cv.stop_words_ :
cv.stop_words_
366
Output:{'as',<br>'be',<br>'better',<br>'betting',<br>'bigger',<br>'but',<br>'can',<br>'close',<br>'eyes',<br>'foot',<br>'from',<br>'has',<br>'heaven',<br>'if',<br>'important',<br>'inside',<br>'isn',<br>'it',<br>'keeps',<br>'kingdom',<br>'live',<br>'love',<br>'me',<br>'more',<br>'no',<br>'nothing',<br>'of',<br>'often',<br>'outside',<br>'oxygen',<br>'physically',<br>'said',<br>'say',<br>'see',<br>'sense',<br>'sometimes',<br>'spiritually',<br>'than',<br>'the',<br>'then',<br>'thing',<br>'think',<br>'to',<br>'ve',<br>'welcome',<br>'well',<br>367<br>'when',<br>'which',<br>'without',<br>'your'}
print("number of docus, size of vocabulary, stop_words list size")
for i in range(len(corpus)):
cv = CountVectorizer(input=corpus,
min_df=i)
count_vector = cv.fit_transform(corpus)
len_voc = len(cv.vocabulary_)
len_stop_words = len(cv.stop_words_)
print(f"{i:10d} {len_voc:15d} {len_stop_words:19d}")
number of docus, size of vocabulary, stop_words list size
0
42192
0
1
42192
0
2
17066
25126
3
10403
31789
4
6637
35555
5
4174
38018
Another parameter of CountVectorizer with which we can create a corpus-specific stop_words_list is
max_df . It can be a float values between 0.0 and 1.0 or an integer. the default value is 1.0, i.e. the float
value 1.0 and not an integer 1! When building the vocabulary all terms that have a document frequency strictly
higher than the given threshold will be ignored. If this parameter is given as a float betwenn 0.0 and 1.0., the
parameter represents a proportion of documents. This parameter is ignored if vocabulary is not None.
Let us use again our previous corpus for an example.
cv = CountVectorizer(input=corpus,
max_df=0.20)
count_vector = cv.fit_transform(corpus)
cv.stop_words_
Output:{'jumped',<br>'remains',<br>'swart',<br>'pendant',<br>'pier',<br>'felicity',<br>'senor',<br>'solidity',<br>'regularly',<br>'escape',<br>'adds',<br>'dirty',<br>'struggled',<br>'meadow',<br>'differences',<br>'poser',<br>'comparative',<br>'jerkin',<br>'pleasant',<br>'principal',<br>'hangs',<br>'spiral',<br>'connection',<br>'diametrically',<br>'xxviii',<br>'magistrate',<br>'wickedly',<br>'battened',<br>'willy',<br>'breakfasting',<br>'invented',<br>'ejaculation',<br>'confer',<br>'anderson',<br>'pupils',<br>'92',<br>'click',<br>'alight',<br>'hoofs',<br>'disasters',<br>'monosyllables',<br>'admirers',<br>'traffic',<br>'ushered',<br>'littleness',<br>'labors',<br>369<br>'telegraph',<br>'disembodied',<br>'delude',<br>'lawless',<br>'conduct',<br>'belie',<br>'morning',<br>'deeds',<br>'manners',<br>'foot',<br>'politeness',<br>'persia',<br>'ruler',<br>'divorced',<br>'vainly',<br>'opens',<br>'pellet',<br>'palace',<br>'chanson',<br>'result',<br>'wipe',<br>'passed',<br>'hoot',<br>'daringly',<br>'beforehand',<br>'qualifying',<br>'gazers',<br>'exported',<br>'chuckling',<br>'shaven',<br>'prostitute',<br>'grudging',<br>'barque',<br>'companies',<br>'birthright',<br>'analysis',<br>'reserved',<br>'pre',<br>'swagger',<br>'walls',<br>'unquestionable',<br>'unutterable',<br>'drive',<br>'willingness',<br>'attempts',<br>'helplessly',<br>370<br>'serge',<br>'eaters',<br>'tear',<br>'sooty',<br>'friar',<br>'insertions',<br>'prosper',<br>'pennies',<br>'tilt',<br>'christians',<br>'cultured',<br>'accursed',<br>'entrusted',<br>'coat',<br>'traced',<br>'piers',<br>'healthier',<br>'garbage',<br>'tougher',<br>'jogs',<br>'glows',<br>'starved',<br>'vitiated',<br>'hails',<br>'scan',<br>'measured',<br>'diamond',<br>'lot',<br>'enough',<br>'predominating',<br>'unaware',<br>'embalming',<br>'abounded',<br>'jawed',<br>'ptolemy',<br>'usefully',<br>'theatre',<br>'transports',<br>'snuffed',<br>'weeps',<br>'friendship',<br>'cloths',<br>'snowy',<br>'absorb',<br>'partnership',<br>'assurances',<br>371<br>'infanticide',<br>'wondrously',<br>'arrogance',<br>'allegiance',<br>'feebly',<br>'temperament',<br>'operas',<br>'ample',<br>'darkening',<br>'fascination',<br>'churches',<br>'whispers',<br>'highlander',<br>'protestant',<br>'ludicrous',<br>'bravery',<br>'commented',<br>'ham',<br>'79',<br>'hoops',<br>'turtle',<br>'pretences',<br>'bloodiest',<br>'turnips',<br>'priest',<br>'precipitous',<br>'murmured',<br>'endless',<br>'imagining',<br>'icebergs',<br>'grounds',<br>'cruise',<br>'madame',<br>'witty',<br>'implicit',<br>'squeeze',<br>'itself',<br>'splintered',<br>'waterloo',<br>'overjoyed',<br>'undertook',<br>'vibration',<br>'distinguishable',<br>'retirement',<br>'diverting',<br>'actions',<br>372<br>'tied',<br>'academy',<br>'respectfully',<br>'asses',<br>'laugh',<br>'peas',<br>'stabs',<br>'daughters',<br>'identified',<br>'unrelenting',<br>'inverted',<br>'inn',<br>'improvement',<br>'sucklings',<br>'conceals',<br>'tiptoe',<br>'displaced',<br>'allowing',<br>'baton',<br>'superior',<br>'softly',<br>'introspective',<br>'breakers',<br>'affectionately',<br>'hamlet',<br>'blaming',<br>'bondage',<br>'card',<br>'calculations',<br>'fix',<br>'manservant',<br>'muscles',<br>'armada',<br>'sacrificed',<br>'choke',<br>'invoking',<br>'freed',<br>'cricket',<br>'catalogue',<br>'oatmeal',<br>'excursion',<br>'cans',<br>'displays',<br>'bulb',<br>'ventilated',<br>'follies',<br>373<br>'filth',<br>'stunned',<br>'brasses',<br>'japanese',<br>'calling',<br>'rail',<br>'possession',<br>'wrist',<br>'sustained',<br>'rammed',<br>'estate',<br>'blurted',<br>'pavements',<br>'finds',<br>'250',<br>'steeple',<br>'enlarged',<br>'blew',<br>'throng',<br>'nasty',<br>'stiffness',<br>'landslip',<br>'wailing',<br>'past',<br>'navel',<br>'bedside',<br>'slunk',<br>'lapland',<br>'carriage',<br>'victoria',<br>'adoration',<br>'narration',<br>'contraction',<br>'prelude',<br>'breaths',<br>'energetically',<br>'hail',<br>'darker',<br>'bawl',<br>'reasonably',<br>'contracting',<br>'miraculously',<br>'48',<br>'entertaining',<br>'consistently',<br>'fond',<br>374<br>'groaned',<br>'characteristics',<br>'smelt',<br>'buzz',<br>'gums',<br>'unmatched',<br>'get',<br>'watchful',<br>'cities',<br>'suit',<br>'conference',<br>'wax',<br>'preparing',<br>'overdone',<br>'wretched',<br>'striving',<br>'della',<br>'drudged',<br>'stolid',<br>'pierce',<br>'sorrowing',<br>'kink',<br>'slit',<br>'audible',<br>'entertainments',<br>'gradations',<br>'excessively',<br>'indolence',<br>'ballrooms',<br>'tolerably',<br>'midsummer',<br>'spanish',<br>'fiendish',<br>'distraction',<br>'defect',<br>'leaps',<br>'21',<br>'flexible',<br>'token',<br>'stammered',<br>'positively',<br>'create',<br>'cobweb',<br>'thinks',<br>'started',<br>'punishments',<br>375<br>'parallel',<br>'needs',<br>'alive',<br>'drudgery',<br>'protecting',<br>'generous',<br>'cant',<br>'stung',<br>'fallow',<br>'iv',<br>'thunderbolts',<br>'plainly',<br>'sounding',<br>'assist',<br>'quiver',<br>'slightly',<br>'apprehension',<br>'cheated',<br>'flippancy',<br>'essentially',<br>'suggest',<br>'startling',<br>'positive',<br>'lipped',<br>'escapes',<br>'dazzling',<br>'immensity',<br>'dining',<br>'plums',<br>'creed',<br>'conventionality',<br>'lavish',<br>'retraced',<br>'resembled',<br>'forgiveness',<br>'avis',<br>'grounded',<br>'seen',<br>'recoiled',<br>'sometime',<br>'pollen',<br>'scalding',<br>'foresaw',<br>'disorder',<br>'worst',<br>'sheepish',<br>376<br>'proportionate',<br>'immaterial',<br>'squander',<br>'occasions',<br>'pulpy',<br>'researches',<br>'chestnut',<br>'peer',<br>'muddled',<br>'prospect',<br>'sails',<br>'beat',<br>'stab',<br>'settees',<br>'expectancy',<br>'thump',<br>'dizzily',<br>'lose',<br>'abode',<br>'advertising',<br>'paces',<br>'st',<br>'solicited',<br>'workmen',<br>'exert',<br>'discharged',<br>'relapsed',<br>'observe',<br>'implored',<br>'ter',<br>'deformed',<br>'keep',<br>'dominance',<br>'journeys',<br>'buffalo',<br>'humbly',<br>'harp',<br>'wasted',<br>'grammar',<br>'err',<br>'assurance',<br>'oiled',<br>'frayed',<br>'fowls',<br>'imperatively',<br>'threatened',<br>377<br>'notepaper',<br>'unsuccessful',<br>'practices',<br>'disagree',<br>'solomon',<br>'design',<br>'graved',<br>'handing',<br>'kee',<br>'sanctity',<br>'incumbent',<br>'precipitate',<br>'approval',<br>'promoting',<br>'obliquity',<br>'comfort',<br>'lowers',<br>'escaped',<br>'withhold',<br>'stretching',<br>'lacking',<br>'policeman',<br>'grouped',<br>'opposite',<br>'arena',<br>'stubbs',<br>'honest',<br>'vestige',<br>'travellers',<br>'groan',<br>'hypothesis',<br>'persist',<br>'levers',<br>'happened',<br>'pearson',<br>'snort',<br>'duly',<br>'bernard',<br>'tightly',<br>'mature',<br>'balloon',<br>'obscurity',<br>'undaunted',<br>'soiled',<br>'justify',<br>'buttered',<br>378<br>'gilbert',<br>'reversed',<br>'restrain',<br>'intellect',<br>'limitations',<br>'difference',<br>'squares',<br>'tortoise',<br>'merits',<br>'jump',<br>'belvedere',<br>'brightness',<br>'coupled',<br>'objection',<br>'spruce',<br>'circuit',<br>'sunk',<br>'paused',<br>'cramped',<br>'medical',<br>'gallons',<br>'hoisted',<br>'moonlit',<br>'penned',<br>'spear',<br>'obedience',<br>'uncontrollable',<br>'blithe',<br>'feats',<br>'bony',<br>'stroll',<br>'complained',<br>'ornamented',<br>'albatrosses',<br>'baptismal',<br>'careering',<br>'hiss',<br>'certain',<br>'powers',<br>'swamped',<br>'aback',<br>'margaret',<br>'characters',<br>'ragged',<br>'visitors',<br>'propriety',<br>379<br>'index',<br>'mare',<br>'anew',<br>'laurel',<br>'frenzy',<br>'symbols',<br>'babyish',<br>'cheaply',<br>'meals',<br>'specially',<br>'ourselves',<br>'sounds',<br>'secret',<br>'cursing',<br>'noon',<br>'archbishop',<br>'miseries',<br>'mistakes',<br>'vaughan',<br>'flaming',<br>'meanings',<br>'shock',<br>'deepest',<br>'afterwards',<br>'bounced',<br>'caramba',<br>'conceal',<br>'delusions',<br>'worth',<br>'section',<br>'fullness',<br>'privileged',<br>'barrow',<br>'compile',<br>'manage',<br>'animosity',<br>'recognise',<br>'uninteresting',<br>'systems',<br>'riches',<br>'endeavours',<br>'diddled',<br>'investigations',<br>'southerly',<br>'flats',<br>'realizing',<br>380<br>'situated',<br>'proximity',<br>'stays',<br>'slogan',<br>'staring',<br>'ineffectually',<br>'burn',<br>'fickle',<br>'oath',<br>'homecoming',<br>'weekly',<br>'record',<br>'likewise',<br>'winks',<br>'xxxiv',<br>'conception',<br>'haunts',<br>'athenian',<br>'nourishment',<br>'beard',<br>'audience',<br>'genesis',<br>'timely',<br>'observing',<br>'entreaty',<br>'eclipsed',<br>'reappeared',<br>'salted',<br>'shaky',<br>'virgin',<br>'majesty',<br>'alterations',<br>'masculine',<br>'strained',<br>'puddings',<br>'oxford',<br>'algebra',<br>'flannelette',<br>'shall',<br>'reckoning',<br>'newspapers',<br>'proclaimed',<br>'lament',<br>'curdling',<br>'frustrate',<br>'professors',<br>381<br>'lectures',<br>'phrase',<br>'exacted',<br>'basso',<br>'strait',<br>'climbing',<br>'avail',<br>'weather',<br>'long',<br>'abroad',<br>'impassive',<br>'painted',<br>'haters',<br>'philip',<br>'broken',<br>'ignoring',<br>'swore',<br>'worry',<br>'extension',<br>'longest',<br>'bareheaded',<br>'bog',<br>'meet',<br>'yonder',<br>'accompany',<br>'lovable',<br>'drawn',<br>'regular',<br>'demon',<br>'die',<br>'wouldst',<br>'unrest',<br>'fancied',<br>'dangled',<br>'listens',<br>'list',<br>'smoked',<br>'doubtfully',<br>'masses',<br>'learned',<br>'incomprehensible',<br>'grass',<br>'loth',<br>'tract',<br>'greetings',<br>'misgiving',<br>382<br>'literature',<br>'stain',<br>'trent',<br>'determination',<br>'sufficiency',<br>'bangle',<br>'hurried',<br>'spur',<br>'metropolis',<br>'king',<br>'inconsistent',<br>'clown',<br>'hopelessness',<br>'ticked',<br>'eldest',<br>'interested',<br>'suburban',<br>'lisp',<br>'youths',<br>'raptures',<br>'partitions',<br>'poverty',<br>'effigy',<br>'dawn',<br>'existence',<br>'clatter',<br>'lt',<br>'tiresome',<br>'credited',<br>'howled',<br>'besides',<br>'borrow',<br>'gnawing',<br>'treason',<br>'speaking',<br>'film',<br>'hysterical',<br>'razor',<br>'rabble',<br>'thirds',<br>'flour',<br>'smiled',<br>'twas',<br>'beastly',<br>'feeding',<br>'female',<br>383<br>'amiable',<br>'renewed',<br>'established',<br>'unmarried',<br>'railing',<br>'fluttered',<br>'stole',<br>'confinement',<br>'pouch',<br>'slay',<br>'india',<br>'relentless',<br>'sweep',<br>'upbraid',<br>'disdain',<br>'broadcloth',<br>'poet',<br>'antarctic',<br>'bottomless',<br>'accidentally',<br>'snores',<br>'imps',<br>'quarts',<br>'divert',<br>'sceptical',<br>'strength',<br>'neighbor',<br>'ends',<br>'initiated',<br>'reprimand',<br>'whaler',<br>'soothed',<br>'blimey',<br>'friends',<br>'passionate',<br>'whereupon',<br>'terrors',<br>'redoubled',<br>'kindle',<br>'finance',<br>'pico',<br>'hand',<br>'excellency',<br>'drugged',<br>'inspired',<br>'warehouses',<br>384<br>'apoplectic',<br>'expanse',<br>'furled',<br>'stronger',<br>'stretched',<br>'bursts',<br>'celebration',<br>'heathen',<br>'circumpolar',<br>'encased',<br>'twins',<br>'graham',<br>'surveys',<br>'embassy',<br>'fundamentals',<br>'author',<br>'scope',<br>'eulogy',<br>'thanking',<br>'graves',<br>'steer',<br>'inhabit',<br>'solvency',<br>'talked',<br>'withdrew',<br>'risked',<br>'slanted',<br>'dane',<br>'cove',<br>'obtain',<br>'belt',<br>'tasting',<br>'forfeited',<br>'ugly',<br>'term',<br>'routine',<br>'curving',<br>'immaculate',<br>'instead',<br>'trophies',<br>'sunday',<br>'ridicule',<br>'skirted',<br>'launch',<br>'greasy',<br>'homely',<br>385<br>'peacock',<br>'firearms',<br>'swelling',<br>'promise',<br>'cheerfully',<br>'interest',<br>'numbers',<br>'sou',<br>'whitened',<br>'distrustful',<br>'beaker',<br>'stiffening',<br>'malt',<br>'insanity',<br>'rooms',<br>'circle',<br>'rags',<br>'originals',<br>'blemish',<br>'breakfasts',<br>'butler',<br>'sugary',<br>'sheathed',<br>'scar',<br>'sew',<br>'venom',<br>'chiselled',<br>'indispensable',<br>'winning',<br>'splinter',<br>'open',<br>'calamity',<br>'mendelssohn',<br>'angelo',<br>'presses',<br>'indications',<br>'infallibly',<br>'congregational',<br>'chrysanthemums',<br>'unexpectedness',<br>'conceive',<br>'involves',<br>'bounds',<br>'passenger',<br>'builds',<br>'duke',<br>386<br>'exceeded',<br>'yells',<br>'survived',<br>'market',<br>'prize',<br>'slinking',<br>'begets',<br>'british',<br>'pikes',<br>'pipes',<br>'pieties',<br>'blank',<br>'least',<br>'tom',<br>'burglars',<br>'sternness',<br>'crops',<br>'villainy',<br>'herring',<br>'cobbler',<br>'shallowest',<br>'lifting',<br>'reaped',<br>'respite',<br>'ganders',<br>'crow',<br>'robin',<br>'rude',<br>'purely',<br>'actress',<br>'surrey',<br>'fooling',<br>'dilating',<br>'lagoons',<br>'rod',<br>'chaplain',<br>'contact',<br>'blotch',<br>'unanswerable',<br>'deplorable',<br>'arrested',<br>'azure',<br>'tottenham',<br>'confirmation',<br>'phil',<br>'gangs',<br>387<br>'mermaids',<br>'paled',<br>'quietude',<br>'moody',<br>'imperious',<br>'replacing',<br>'seized',<br>'lasted',<br>'restricted',<br>'nobody',<br>'braiding',<br>'illustrations',<br>'suspended',<br>'distinct',<br>'gilt',<br>'happen',<br>'australia',<br>'lotion',<br>'absence',<br>'contradicting',<br>'note',<br>'phrased',<br>'dashing',<br>'magnifying',<br>'pursed',<br>'infinitesimal',<br>'service',<br>'gout',<br>'deciphered',<br>'furnishing',<br>'hollow',<br>'youngest',<br>'police',<br>'multitudinous',<br>'brains',<br>'flows',<br>'vernacular',<br>'virtue',<br>'nurtured',<br>'cheeks',<br>'delivered',<br>'elderly',<br>'magical',<br>'salutes',<br>'despising',<br>'moods',<br>388<br>'correctness',<br>'habit',<br>'outwardly',<br>'darwin',<br>'someone',<br>'derelict',<br>'embodied',<br>'wonderful',<br>'pussy',<br>'1846',<br>'4d',<br>'sheep',<br>'extent',<br>'wapping',<br>'bundling',<br>'smeared',<br>'toilet',<br>'inconsiderate',<br>'bountifully',<br>'incandescence',<br>'smoking',<br>'trust',<br>'father',<br>'backwards',<br>'thee',<br>'tornado',<br>'avenger',<br>'plumped',<br>'grouse',<br>'secrets',<br>'majority',<br>'staves',<br>'crutch',<br>'wakes',<br>'saddened',<br>'kine',<br>'nods',<br>'indifferently',<br>'butteries',<br>'charades',<br>'feelings',<br>'locking',<br>'librarian',<br>'greying',<br>'house',<br>'grudgingly',<br>389<br>'much',<br>'expound',<br>'marshalled',<br>'stillness',<br>'mirth',<br>'hours',<br>'everlasting',<br>'surf',<br>'appellation',<br>'trampled',<br>'porch',<br>'looping',<br>'justification',<br>'honestly',<br>'lamentable',<br>'musical',<br>'prodding',<br>'captain',<br>'procrastination',<br>'sneaking',<br>'smiles',<br>'tranquil',<br>'preservation',<br>'navigator',<br>'technically',<br>'daisy',<br>'boredom',<br>'twisting',<br>'speed',<br>'creamy',<br>'documents',<br>'tum',<br>'82',<br>'unwieldy',<br>...}
EXERCISES
EXERCISE 1
In the subdirectory 'books' you will find some books:
• Virginia Woolf: Night and Day
• Samuel Butler: The Way of all Flesh
390
•
•
•
•
Herman Melville: Moby Dick
David Herbert Lawrence: Sons and Lovers
Daniel Defoe: The Life and Adventures of Robinson Crusoe
James Joyce: Ulysses
Use these novels as the corpus and create a word count vector.
EXERCISE 2
Turn the previously calculated 'word count vector' into a dense ndarray representation.
EXERCISE 3
Let us have another example with a different corpus. The five strings are famous quotes from
1.
2.
3.
4.
5.
William Shakespeare
W.C. Fields
Ronald Reagan
John Steinbeck
Author unknown
Compute the IDF values!
quotes = ["A horse, a horse, my kingdom for a horse!",
"Horse sense is the thing a horse has which keeps it fro
m betting on people."
"I’ve often said there is nothing better for the inside
of the man, than the outside of the horse.",
"A man on a horse is spiritually, as well as physicall
y, bigger then a man on foot.",
"No heaven can heaven be, if my horse isn’t there to wel
come me."]
SOLUTIONS
SOLUTION TO EXERCISE 1
corpus = []
books = ["night_and_day_virginia_woolf.txt",
"the_way_of_all_flash_butler.txt",
"moby_dick_melville.txt",
"sons_and_lovers_lawrence.txt",
"robinson_crusoe_defoe.txt",
391
"james_joyce_ulysses.txt"]
path = "books"
corpus = []
for book in books:
txt = open(path + "/" + book).read()
corpus.append(txt)
[book[:30] for book in corpus]
Output:['The Project Gutenberg EBook of',
'The Project Gutenberg eBook, T',
'\nThe Project Gutenberg EBook o',
'The Project Gutenberg EBook of',
'The Project Gutenberg eBook, T',
'\nThe Project Gutenberg EBook o']
We have to get rid of the Gutenberg header and footer, because it doesn't belong to the novels. We can see by
looking at the texts that the authors works begins after lines of the following kind
***START OF THIS PROJECT GUTENBERG ... ***
The footer of the texts start with this line:
***END OF THIS PROJECT GUTENBERG EBOOK ...***
There may or may not be a space after the first three stars or instead of "the" there may be "this".
We can use regular expressions to find the starting point of the novels:
from sklearn.feature_extraction import text
import re
corpus = []
books = ["night_and_day_virginia_woolf.txt",
"the_way_of_all_flash_butler.txt",
"moby_dick_melville.txt",
"sons_and_lovers_lawrence.txt",
"robinson_crusoe_defoe.txt",
"james_joyce_ulysses.txt"]
path = "books"
corpus = []
for book in books:
txt = open(path + "/" + book).read()
text_begin = re.search(r"\*\*\* ?START OF (THE|THIS) PROJEC
392
T.*?\*\*\*", txt, re.DOTALL)
text_end = re.search(r"\*\*\* ?END OF (THE|THIS) PROJEC
T.*?\*\*\*", txt, re.DOTALL)
corpus.append(txt[text_begin.end():text_end.start()])
vectorizer = text.CountVectorizer()
vectorizer.fit(corpus)
token_count_matrix = vectorizer.transform(corpus)
print(token_count_matrix)
393
(0,(0,(0,(0,(0,(0,(0,(0,(0,(0,(0,(0,(0,(0,(0,(0,(0,(0,(0,(0,(0,(0,(0,(0,(0,:
(5,(5,(5,(5,(5,(5,(5,(5,(5,(5,(5,(5,(5,(5,(5,(5,(5,(5,(5,(5,4)
35)
60)
79)
131)
221)
724)
731)
734)
743)
761)
773)
779)
780)
781)
790)
804)
809)
810)
817)
823)
824)
825)
828)
829)
:
42156)
42157)
42158)
42159)
42160)
42161)
42165)
42166)
42167)
42172)
42173)
42174)
42175)
42176)
42177)
42178)
42181)
42182)
42183)
42184)
2
1
1
1
1
1
6
5
1
5
1
1
1
1
23
1
1
412
36
2
4
19
3
11
1
5
1
1
2
2
106
1
2
1
2
4
1
1
1
1
3
1
1
3
1
394
(5,(5,(5,(5,(5,42185)
42186)
42187)
42188)
42189)
2
1
1
2
1
print("Number of words in vocabulary: ", len(vectorizer.vocabular
y_))
Number of words in vocabulary:
42192
SOLUTION TO EXERCISE 2
All you have to do is applying the method toarray to get the token_count_matrix :
token_count_matrix.toarray()
Output:array([[ 0,
0,
0, ...,
0,
0,
0],
[19,
0,
0, ...,
0,
0,
0],
[20,
0,
0, ...,
0,
1,
1],
[ 0,
0,
1, ...,
0,
0,
0],
[ 0,
0,
0, ...,
0,
0,
0],
[11,
1,
0, ...,
1,
0,
0]])
SOLUTION TO EXERCISE 3
from sklearn.feature_extraction import text
# our corpus:
quotes = ["A horse, a horse, my kingdom for a horse!",
"Horse sense is the thing a horse has which keeps it fro
m betting on people."
"I’ve often said there is nothing better for the inside
of the man, than the outside of the horse.",
"A man on a horse is spiritually, as well as physicall
y, bigger then a man on foot.",
"No heaven can heaven be, if my horse isn’t there to wel
come me."]
vectorizer = text.CountVectorizer()
vectorizer.fit(quotes)
vectorized_text = vectorizer.fit_transform(quotes)
tfidf_transformer = text.TfidfTransformer(smooth_idf=True,use_id
395
f=True)
tfidf_transformer.fit(vectorized_text)
"""
alternative way to output the data:
import pandas as pd
df_idf = pd.DataFrame(tfidf_transformer.idf_,
index=vectorizer.get_feature_names(),
columns=["idf_weight"])
df_idf.sort_values(by=['idf_weights']) # sorting data
print(df_idf)
"""
print(f"{'word':15s}: idf_weight")
word_weight_list = list(zip(vectorizer.get_feature_names(), tfid
f_transformer.idf_))
word_weight_list.sort(key=lambda x:x[1]) # sort list by the weigh
ts (2nd component)
for word, idf_weight in word_weight_list:
print(f"{word:15s}: {idf_weight:4.3f}")
396
word
horse
for
is
man
my
on
there
as
be
better
betting
bigger
can
foot
from
has
heaven
if
inside
isn
it
keeps
kingdom
me
no
nothing
of
often
outside
people
physically
said
sense
spiritually
than
the
then
thing
to
ve
welcome
well
which
::::::::::::::::::::::::::::::::::::::::::::idf_weight
1.000
1.511
1.511
1.511
1.511
1.511
1.511
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
1.916
397
FOOTNOTES
1Logically
toarray and todense are the same thing, but toarray returns an ndarray whereas
todense returns a matrix . If you consider, what the official Numpy documentation has to say about the
numpy.matrix class, you shouldn't use todense ! "It is no longer recommended to use this class, even
for linear algebra. Instead use regular arrays. The class may be removed in the future." (numpy.matrix) (back)