任务管理
章节大纲
-
任务管理 (Task Management)
简介
“工作流”部分介绍了如何以松散耦合的方式运行研究工作流。但当你使用 qrun 时,它只能执行一个任务。为了自动生成和执行不同的任务,任务管理提供了一个完整的流程,包括任务生成、任务存储、任务训练和任务收集。有了这个模块,用户可以在不同时期、不同损失函数甚至不同模型下自动运行他们的任务。任务生成、模型训练以及合并和收集数据的过程如下图所示。
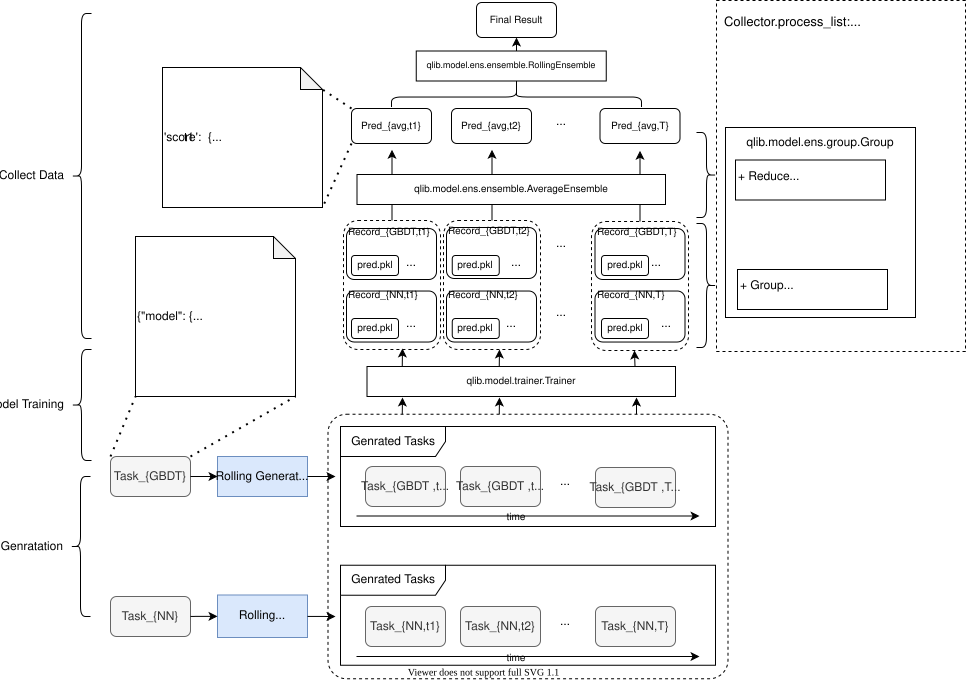
这个完整的流程可以在在线服务中使用。
一个完整流程的示例在这里。
任务生成 (Task Generating)
一个任务由 Model、Dataset、Record 或用户添加的任何内容组成。具体的任务模板可以在任务部分查看。即使任务模板是固定的,用户也可以自定义他们的
TaskGen,通过任务模板生成不同的任务。这是 TaskGen 的基类:
class qlib.workflow.task.gen.TaskGen
生成不同任务的基类。
-
示例 1:
-
输入:一个特定的任务模板和滚动步长。
-
输出:任务的滚动版本。
-
-
示例 2:
-
输入:一个特定的任务模板和损失列表。
-
输出:一组具有不同损失的任务。
-
abstract generate(task: dict) -> List[dict]
根据任务模板生成不同的任务。
参数:
-
task (dict) – 任务模板。
返回:
一个任务列表。
返回类型:List[dict]
Qlib 提供了一个
RollingGen类,用于在不同日期段生成一个数据集的任务列表。这个类允许用户在一个实验中验证不同时期的数据对模型的影响。更多信息在这里。
任务存储 (Task Storing)
为了实现更高的效率和集群操作的可能性,任务管理将把所有任务存储在 MongoDB 中。
TaskManager可以自动获取未完成的任务,并通过错误处理管理一组任务的生命周期。使用此模块时,用户必须完成 MongoDB 的配置。用户需要提供 MongoDB URL 和数据库名称才能在初始化中使用
TaskManager,或者像这样进行声明。Pythonfrom qlib.config import CC CC["mongo"] = { "task_url" : "mongodb://localhost:27017/", # 你的 MongoDB URL "task_db_name" : "rolling_db" # 数据库名称 }class qlib.workflow.task.manage.TaskManager(task_pool: str)
这是任务由 TaskManager 创建后的样子:
JSON{ 'def': pickle 序列化的任务定义。使用 pickle 会使其更简单。 'filter': 类似 json 的数据。这用于筛选任务。 'status': 'waiting' | 'running' | 'done' 'res': pickle 序列化的任务结果。 }任务管理器假定你只会更新你获取的任务。MongoDB 的“fetch one and update”将使其数据更新安全。
这个类可以用作命令行工具。以下是几个示例。您可以使用以下命令查看 manage 模块的帮助:
-
python -m qlib.workflow.task.manage -h# 显示manage模块 CLI 的手册 -
python -m qlib.workflow.task.manage wait -h# 显示manage的wait命令手册 -
python -m qlib.workflow.task.manage -t <pool_name> wait -
python -m qlib.workflow.task.manage -t <pool_name> task_stat
注意
-
假设:MongoDB 中的数据已编码,MongoDB 之外的数据已解码。
这里有四种状态:
-
STATUS_WAITING:等待训练。 -
STATUS_RUNNING:正在训练。 -
STATUS_PART_DONE:完成了一些步骤,正在等待下一步。 -
STATUS_DONE:所有工作完成。
__init__(task_pool: str)
初始化任务管理器,请记住首先进行 MongoDB url 和数据库名称的声明。一个 TaskManager 实例服务于一个特定的任务池。此模块的静态方法服务于整个 MongoDB。
参数:
-
task_pool(str) – MongoDB 中 Collection 的名称。
static list() -> list
列出数据库的所有 Collection (task_pool)。
返回:list
replace_task(task, new_task)
使用一个新任务替换旧任务。
参数:
-
task– 旧任务。 -
new_task– 新任务。
insert_task(task)
插入一个任务。
参数:
-
task – 等待插入的任务。
返回:pymongo.results.InsertOneResult
insert_task_def(task_def)
向 task_pool 插入一个任务。
参数:
-
task_def (dict) – 任务定义。
返回类型:pymongo.results.InsertOneResult
create_task(task_def_l, dry_run=False, print_nt=False) -> List[str]
如果 task_def_l 中的任务是新的,则将新任务插入 task_pool 并记录 inserted_id。如果任务不是新的,则只查询其 _id。
参数:
-
task_def_l(list) – 一个任务列表。 -
dry_run(bool) – 是否将这些新任务插入任务池。 -
print_nt (bool) – 是否打印新任务。
返回:
task_def_l 的 _id 列表。
返回类型:List[str]
fetch_task(query={}, status='waiting') -> dict
使用 query 获取任务。
参数:
-
query(dict,optional) – 查询字典。默认为{}。 -
status (str, optional) – [描述]。默认为 STATUS_WAITING。
返回:
一个解码后的任务(collection 中的 document)。
返回类型:dict
safe_fetch_task(query={}, status='waiting')
使用 contextmanager 从 task_pool 中获取任务。
参数:
-
query (dict) – 查询字典。
返回:
一个解码后的任务(collection 中的 document)。
返回类型:dict
query(query={}, decode=True)
在 collection 中查询任务。如果迭代生成器花费太长时间,此函数可能会引发异常 pymongo.errors.CursorNotFound: cursor id not found。
-
python -m qlib.workflow.task.manage -t <your task pool> query ‘{“_id”: “615498be837d0053acbc5d58”}’
参数:
-
query(dict) – 查询字典。 -
decode (bool) –
返回:
一个解码后的任务(collection 中的 document)。
返回类型:dict
re_query(_id) -> dict
使用 _id 查询任务。
参数:
-
_id (str) – document 的 _id。
返回:
一个解码后的任务(collection 中的 document)。
返回类型:dict
commit_task_res(task, res, status='done')
将结果提交到 task['res']。
参数:
-
task([类型]) – [描述]。 -
res(object) – 您想要保存的结果。 -
status(str,optional) –STATUS_WAITING,STATUS_RUNNING,STATUS_DONE,STATUS_PART_DONE。默认为STATUS_DONE。
return_task(task, status='waiting')
将任务返回到某个状态。通常用于错误处理。
参数:
-
task([类型]) – [描述]。 -
status(str,optional) –STATUS_WAITING,STATUS_RUNNING,STATUS_DONE,STATUS_PART_DONE。默认为STATUS_WAITING。
remove(query={})
使用 query 删除任务。
参数:
-
query(dict) – 查询字典。
task_stat(query={}) -> dict
统计每个状态下的任务数。
参数:
-
query (dict, optional) – 查询字典。默认为 {}。
返回:dict
reset_waiting(query={})
将所有正在运行的任务重置为等待状态。当某些正在运行的任务意外退出时可以使用。
参数:
-
query(dict,optional) – 查询字典。默认为{}。
prioritize(task, priority: int)
为任务设置优先级。
参数:
-
task(dict) – 从数据库查询到的任务。 -
priority(int) – 目标优先级。
wait(query={})
当多进程时,主进程可能从 TaskManager 中获取不到任何东西,因为仍然有一些正在运行的任务。因此,主进程应该等待所有任务都被其他进程或机器训练好。
参数:
-
query(dict,optional) – 查询字典。默认为{}。
有关任务管理的更多信息,可以在这里找到。
任务训练 (Task Training)
在生成和存储这些任务之后,是时候运行处于
WAITING状态的任务了。Qlib 提供了一个名为run_task的方法来运行任务池中的任务,但是,用户也可以自定义任务的执行方式。获取task_func的简单方法是直接使用qlib.model.trainer.task_train。它将运行由任务定义的整个工作流,其中包括Model、Dataset和Record。qlib.workflow.task.manage.run_task(task_func: Callable, task_pool: str, query: dict = {}, force_release: bool = False, before_status: str = 'waiting', after_status: str = 'done', **kwargs)
当任务池不为空(有 WAITING 任务)时,使用 task_func 获取并运行 task_pool 中的任务。
运行此方法后,有 4 种情况(before_status -> after_status):
-
STATUS_WAITING->STATUS_DONE:使用task["def"]作为task_func参数,表示任务尚未开始。 -
STATUS_WAITING->STATUS_PART_DONE:使用task["def"]作为task_func参数。 -
STATUS_PART_DONE->STATUS_PART_DONE:使用task["res"]作为task_func参数,表示任务已开始但未完成。 -
STATUS_PART_DONE -> STATUS_DONE:使用 task["res"] 作为 task_func 参数。
参数:
-
task_func(Callable) –-
def (task_def, **kwargs) -> <res which will be committed> -
运行任务的函数。
-
-
task_pool(str) – 任务池的名称(MongoDB 中的 Collection)。 -
query(dict) – 获取任务时将使用此字典查询task_pool。 -
force_release(bool) – 程序是否强制释放资源。 -
before_status(str) –before_status中的任务将被获取和训练。可以是STATUS_WAITING、STATUS_PART_DONE。 -
after_status(str) – 训练后的任务将变为after_status。可以是STATUS_WAITING、STATUS_PART_DONE。 -
kwargs–task_func的参数。
同时,Qlib 提供了一个名为
Trainer的模块。class qlib.model.trainer.Trainer
训练器可以训练一个模型列表。有 Trainer 和 DelayTrainer,它们可以根据何时完成实际训练来区分。
__init__()train(tasks: list, *args, **kwargs) -> list
给定一个任务定义列表,开始训练并返回模型。
对于 Trainer,它在此方法中完成实际训练。对于 DelayTrainer,它仅在此方法中进行一些准备工作。
参数:
-
tasks – 任务列表。
返回:
一个模型列表。
返回类型:list
end_train(models: list, *args, **kwargs) -> list
给定一个模型列表,如果需要,在训练结束时完成一些收尾工作。模型可以是 Recorder、文本文件、数据库等。
对于 Trainer,它在此方法中进行一些收尾工作。对于 DelayTrainer,它在此方法中完成实际训练。
参数:
-
models – 模型列表。
返回:
一个模型列表。
返回类型:list
is_delay() -> bool
如果训练器将延迟完成 end_train。
返回:
如果是 DelayTrainer。
返回类型:bool
has_worker() -> bool
一些训练器有后端 worker 来支持并行训练。此方法可以告诉我们 worker 是否已启用。
返回:
如果 worker 已启用。
返回类型:bool
worker()
启动 worker。
引发:
-
NotImplementedError:如果不支持 worker。
Trainer将训练一个任务列表并返回一个模型记录器列表。Qlib 提供两种Trainer,TrainerR是最简单的方式,TrainerRM基于TaskManager帮助自动管理任务生命周期。如果你不想使用任务管理来管理任务,那么使用TrainerR来训练由TaskGen生成的任务列表就足够了。这里有关于不同Trainer的详细信息。
任务收集 (Task Collecting)
在收集模型训练结果之前,你需要使用
qlib.init指定mlruns的路径。为了在训练后收集任务的结果,Qlib 提供了
Collector、Group和Ensemble,以可读、可扩展和松散耦合的方式收集结果。-
Collector可以从任何地方收集对象并对其进行处理,例如合并、分组、求平均等。它有 2 个步骤动作,包括collect(将任何内容收集到字典中)和process_collect(处理收集到的字典)。 -
Group也有 2 个步骤,包括group(可以根据group_func对一组对象进行分组并将其更改为字典)和reduce(可以根据某些规则使字典成为一个集合)。例如:{(A,B,C1): object, (A,B,C2): object} —group—> {(A,B): {C1: object, C2: object}} —reduce—> {(A,B): object}。 -
Ensemble可以合并集合中的对象。例如:{C1: object, C2: object} —Ensemble—> object。你可以在Collector的process_list中设置你想要的集合。常见的集合包括AverageEnsemble和RollingEnsemble。AverageEnsemble用于合并同一时间段内不同模型的结果。RollingEnsemble用于合并同一时间段内不同模型的结果。
因此,层次结构是:
Collector的第二步对应于Group。而Group的第二步对应于Ensemble。欲了解更多信息,请参阅 Collector、Group 和 Ensemble,或示例。
-