Qlib-巨人級的AI量化投資平台
章节大纲
-
引言
Qlib 是一个面向人工智能的量化投资平台,旨在发掘人工智能技术在量化投资领域的潜力、助力研究并创造价值。
通过 Qlib,用户可以轻松尝试他们的想法,以创建更好的量化投资策略。
框架
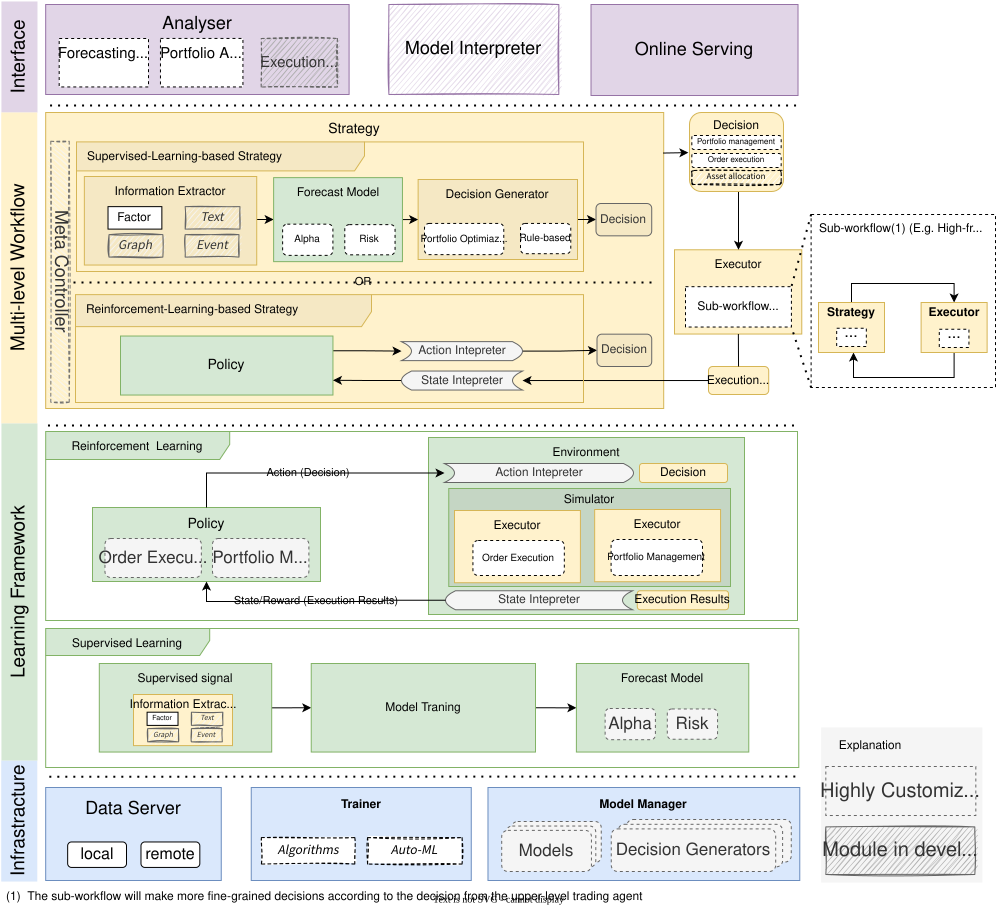
从模块层面来看,Qlib 是一个由上述组件构成的平台。这些组件被设计成松散耦合的模块,每个组件都可以独立使用。
这个框架对于 Qlib 新用户来说可能有些难以理解。它试图尽可能准确地包含 Qlib 设计的许多细节。对于新用户,你可以先跳过这部分,稍后再回来阅读。
名称 描述 基础设施层 基础设施层为量化研究提供底层支持。DataServer(数据服务器)为用户提供高性能的基础设施,用于管理和检索原始数据。Trainer(训练器)提供灵活的接口来控制模型的训练过程,从而使算法能够控制训练过程。 学习框架层 预测模型和交易代理都是可训练的。它们基于学习框架层进行训练,然后应用于工作流层中的多个场景。支持的学习范式可分为强化学习和监督学习。该学习框架也利用了工作流层(例如,共享信息提取器、基于执行环境创建环境)。 工作流层 工作流层涵盖了量化投资的整个工作流程。它支持基于监督学习和基于强化学习的策略。信息提取器为模型提取数据。预测模型专注于为其他模块生成各种预测信号(例如阿尔法、风险)。有了这些信号,决策生成器将生成目标交易决策(即投资组合、订单)。如果采用基于强化学习的策略,策略将以端到端的方式学习,并直接生成交易决策。决策将由执行环境(即交易市场)执行。可能存在多个级别的策略和执行器(例如,订单执行交易策略和盘中订单执行器可以像一个盘间交易循环,并嵌套在日常投资组合管理交易策略和盘间交易执行器交易循环中)。 接口层 接口层试图为底层系统提供一个用户友好的界面。分析器模块将为用户提供预测信号、投资组合和执行结果的详细分析报告。
-
以手绘风格展示的模块正在开发中,未来将会发布。
-
带有虚线边框的模块是高度可定制和可扩展的。
-
(附:框架图是用 https://draw.io/ 创建的。)
活动:0 -
-
Quick Start (快速上手)
简介
本篇快速上手指南旨在展示如何利用 Qlib 轻松构建完整的量化研究工作流,并验证用户的想法。
本指南将演示,即使是使用公开数据和简单的模型,机器学习技术在实际的量化投资中也能发挥很好的作用。
安装
用户可以按照以下步骤轻松安装 Qlib:
在从源代码安装 Qlib 之前,需要先安装一些依赖项:
pip install numpy pip install --upgrade cython克隆代码仓库并安装 Qlib:
git clone https://github.com/microsoft/qlib.git && cd qlib python setup.py install要了解更多关于安装的信息,请参阅 Qlib 安装。
准备数据
运行以下代码加载并准备数据:
python scripts/get_data.py qlib_data --target_dir ~/.qlib/qlib_data/cn_data --region cn该数据集是通过
scripts/data_collector/中的爬虫脚本收集的公开数据创建的,这些脚本已在同一个代码仓库中发布。用户可以使用这些脚本创建相同的数据集。要了解更多关于准备数据的信息,请参阅 数据准备。
自动化量化研究工作流
Qlib 提供了一个名为
qrun的工具,可以自动运行整个工作流(包括构建数据集、训练模型、回测和评估)。用户可以按照以下步骤启动自动化量化研究工作流并获得图形化报告分析:量化研究工作流:
使用 LightGBM 模型的配置文件
workflow_config_lightgbm.yaml运行qrun,如下所示。cd examples # 避免在包含 `qlib` 的目录下运行程序 qrun benchmarks/LightGBM/workflow_config_lightgbm.yaml工作流结果
qrun的结果如下,这也是预测模型 (alpha) 的典型结果。有关结果的更多详细信息,请参阅 盘中交易。risk excess_return_without_cost mean 0.000605 std 0.005481 annualized_return 0.152373 information_ratio 1.751319 max_drawdown -0.059055 excess_return_with_cost mean 0.000410 std 0.005478 annualized_return 0.103265 information_ratio 1.187411 max_drawdown -0.075024要了解更多关于工作流和
qrun的信息,请参阅 工作流:工作流管理。图形化报告分析:
使用 jupyter notebook 运行
examples/workflow_by_code.ipynb。用户可以通过运行
examples/workflow_by_code.ipynb进行投资组合分析或预测得分(模型预测)分析。图形化报告
用户可以获得关于分析的图形化报告,更多详细信息请参阅 分析:评估与结果分析。
自定义模型集成
Qlib 提供了一系列模型(例如 lightGBM 和 MLP 模型)作为预测模型的示例。除了默认模型,用户还可以将自己的自定义模型集成到 Qlib 中。如果用户对自定义模型感兴趣,请参阅 自定义模型集成。
活动:0 -
安装
Qlib 安装
注意
Qlib 支持 Windows 和 Linux 操作系统,但建议在 Linux 系统上使用。Qlib 支持 Python 3,最高版本为 Python 3.8。
用户可以通过
pip轻松安装 Qlib,只需运行以下命令:pip install pyqlib此外,用户还可以通过源代码安装 Qlib,步骤如下:
进入 Qlib 的根目录,也就是
setup.py文件所在的目录。然后,执行以下命令来安装环境依赖和 Qlib:
$ pip install numpy $ pip install --upgrade cython $ git clone https://github.com/microsoft/qlib.git && cd qlib $ python setup.py install注意
建议使用 Anaconda/Miniconda 来设置环境。Qlib 需要 lightgbm 和 pytorch 这两个包,请使用
pip来安装它们。使用以下代码来验证安装是否成功:
import qlib qlib.__version__ <LATEST VERSION>活动:0 -
Qlib 初始化
初始化
请按照以下步骤初始化 Qlib。
-
下载并准备数据:执行以下命令下载股票数据。请注意,这些数据是从 Yahoo Finance 收集的,可能并不完美。如果您有高质量的数据集,我们建议您准备自己的数据。有关自定义数据集的更多信息,请参阅数据部分。
python scripts/get_data.py qlib_data --target_dir ~/.qlib/qlib_data/cn_data --region cn有关
get_data.py的更多信息,请参阅数据准备。 -
在调用其他 API 之前初始化 Qlib:在 Python 中运行以下代码。
Pythonimport qlib # region in [REG_CN, REG_US] from qlib.constant import REG_CN provider_uri = "~/.qlib/qlib_data/cn_data" # 你的目标目录 qlib.init(provider_uri=provider_uri, region=REG_CN)
注意
请不要在 Qlib 的代码仓库目录中导入
qlib包,否则可能会出现错误。
参数
除了
provider_uri和region之外,qlib.init还有其他参数。以下是qlib.init的几个重要参数(Qlib 有很多配置,这里只列出部分参数。更详细的设置请参阅这里):-
provider_uri:类型为str。Qlib 数据的 URI。例如,它可以是get_data.py加载数据后存储的目录。 -
region:类型为str,可选参数(默认为qlib.constant.REG_CN)。目前支持qlib.constant.REG_US('us') 和qlib.constant.REG_CN('cn')。不同的region值会对应不同的股票市场模式。-
qlib.constant.REG_US:美股市场。 -
qlib.constant.REG_CN:A股市场。
不同的模式会导致不同的交易限制和成本。
region只是用于定义一系列配置的快捷方式,包括最小交易单位(trade_unit)、交易限制(limit_threshold)等。它不是必需的,如果现有区域设置无法满足您的需求,您可以手动设置关键配置。 -
-
redis_host:类型为str,可选参数(默认为 "127.0.0.1"),redis的主机名。锁定和缓存机制依赖于redis。 -
redis_port:类型为int,可选参数(默认为 6379),redis的端口号。
注意
region的值应与provider_uri中存储的数据保持一致。目前,scripts/get_data.py只提供 A股市场数据。如果用户想使用美股市场数据,他们应该在provider_uri中准备自己的美股数据,并切换到美股模式。注意
如果 Qlib 无法通过
redis_host和redis_port连接到 Redis,将不会使用缓存机制!详情请参阅缓存。-
exp_manager:类型为dict,可选参数,用于在qlib中使用的实验管理器设置。用户可以指定一个实验管理器类,以及所有实验的追踪 URI。但是,请注意,我们只支持以下样式的字典作为exp_manager的输入。有关exp_manager的更多信息,用户可以参考记录器:实验管理。Python# 例如,如果你想将你的 tracking_uri 设置为一个 <特定文件夹>,你可以如下初始化 qlib qlib.init(provider_uri=provider_uri, region=REG_CN, exp_manager= { "class": "MLflowExpManager", "module_path": "qlib.workflow.expm", "kwargs": { "uri": "python_execution_path/mlruns", "default_exp_name": "Experiment", }}) -
mongo:类型为dict,可选参数,用于 MongoDB 的设置,这将在某些功能(如任务管理)中使用,以实现高性能和集群处理。用户需要首先按照安装中的步骤安装 MongoDB,然后通过 URI 访问它。用户可以通过将 "task_url" 设置为 "mongodb://%s:%s@%s" % (user, pwd, host + ":" + port) 这样的字符串,使用凭证访问 MongoDB。Python# 例如,你可以如下初始化 qlib qlib.init(provider_uri=provider_uri, region=REG_CN, mongo={ "task_url": "mongodb://localhost:27017/", # 你的 mongo url "task_db_name": "rolling_db", # 任务管理的数据库名称 }) -
logging_level:系统的日志级别。 -
kernels:在 Qlib 的表达式引擎中计算特征时使用的进程数。在调试表达式计算异常时,将其设置为 1 是非常有帮助的。
活动:0 -
-
数据检索
简介
用户可以使用 Qlib 获取股票数据。以下示例展示了其基本的用户界面。
示例
QLib 初始化:
注意
为了获取数据,用户需要先使用
qlib.init初始化 Qlib。请参阅初始化。如果用户按照初始化中的步骤下载了数据,则应使用以下代码初始化 qlib:
Python>> import qlib >> qlib.init(provider_uri='~/.qlib/qlib_data/cn_data')加载指定时间范围和频率的交易日历:
Python>> from qlib.data import D >> D.calendar(start_time='2010-01-01', end_time='2017-12-31', freq='day')[:2] [Timestamp('2010-01-04 00:00:00'), Timestamp('2010-01-05 00:00:00')]将给定的市场名称解析为股票池配置:
Python>> from qlib.data import D >> D.instruments(market='all') {'market': 'all', 'filter_pipe': []}加载指定时间范围内的特定股票池的成分股:
Python>> from qlib.data import D >> instruments = D.instruments(market='csi300') >> D.list_instruments(instruments=instruments, start_time='2010-01-01', end_time='2017-12-31', as_list=True)[:6] ['SH600036', 'SH600110', 'SH600087', 'SH600900', 'SH600089', 'SZ000912']根据名称过滤器从基础市场加载动态成分股:
Python>> from qlib.data import D >> from qlib.data.filter import NameDFilter >> nameDFilter = NameDFilter(name_rule_re='SH[0-9]{4}55') >> instruments = D.instruments(market='csi300', filter_pipe=[nameDFilter]) >> D.list_instruments(instruments=instruments, start_time='2015-01-01', end_time='2016-02-15', as_list=True) ['SH600655', 'SH601555']根据表达式过滤器从基础市场加载动态成分股:
Python>> from qlib.data import D >> from qlib.data.filter import ExpressionDFilter >> expressionDFilter = ExpressionDFilter(rule_expression='$close>2000') >> instruments = D.instruments(market='csi300', filter_pipe=[expressionDFilter]) >> D.list_instruments(instruments=instruments, start_time='2015-01-01', end_time='2016-02-15', as_list=True) ['SZ000651', 'SZ000002', 'SH600655', 'SH600570']有关过滤器的更多详细信息,请参阅过滤器 API。
加载指定时间范围内特定成分股的特征:
Python>> from qlib.data import D >> instruments = ['SH600000'] >> fields = ['$close', '$volume', 'Ref($close, 1)', 'Mean($close, 3)', '$high-$low'] >> D.features(instruments, fields, start_time='2010-01-01', end_time='2017-12-31', freq='day').head().to_string() ' $close $volume Ref($close, 1) Mean($close, 3) $high-$low... instrument datetime... SH600000 2010-01-04 86.778313 16162960.0 88.825928 88.061483 2.907631... 2010-01-05 87.433578 28117442.0 86.778313 87.679273 3.235252... 2010-01-06 85.713585 23632884.0 87.433578 86.641825 1.720009... 2010-01-07 83.788803 20813402.0 85.713585 85.645322 3.030487... 2010-01-08 84.730675 16044853.0 83.788803 84.744354 2.047623'加载指定时间范围内特定股票池的特征:
注意
启用缓存后,qlib 数据服务器将为请求的股票池和字段始终缓存数据,这可能会导致首次处理请求的时间比没有缓存时更长。但第一次之后,即使请求的时间段发生变化,具有相同股票池和字段的请求也会命中缓存并处理得更快。
Python>> from qlib.data import D >> from qlib.data.filter import NameDFilter, ExpressionDFilter >> nameDFilter = NameDFilter(name_rule_re='SH[0-9]{4}55') >> expressionDFilter = ExpressionDFilter(rule_expression='$close>Ref($close,1)') >> instruments = D.instruments(market='csi300', filter_pipe=[nameDFilter, expressionDFilter]) >> fields = ['$close', '$volume', 'Ref($close, 1)', 'Mean($close, 3)', '$high-$low'] >> D.features(instruments, fields, start_time='2010-01-01', end_time='2017-12-31', freq='day').head().to_string() ' $close $volume Ref($close, 1) Mean($close, 3) $high-$low... instrument datetime... SH600655 2010-01-04 2699.567383 158193.328125 2619.070312 2626.097738 124.580566... 2010-01-08 2612.359619 77501.406250 2584.567627 2623.220133 83.373047... 2010-01-11 2712.982422 160852.390625 2612.359619 2636.636556 146.621582... 2010-01-12 2788.688232 164587.937500 2712.982422 2704.676758 128.413818... 2010-01-13 2790.604004 145460.453125 2788.688232 2764.091553 128.413818'有关特征的更多详细信息,请参阅特征 API。
注意
在客户端调用
D.features()时,使用参数disk_cache=0跳过数据集缓存,使用disk_cache=1生成并使用数据集缓存。此外,在服务器端调用时,用户可以使用disk_cache=2更新数据集缓存。当您构建复杂的表达式时,在一个字符串中实现所有表达式可能并不容易。例如,它看起来相当长且复杂:
Python>> from qlib.data import D >> data = D.features(["sh600519"], ["(($high / $close) + ($open / $close)) * (($high / $close) + ($open / $close)) / (($high / $close) + ($open / $close))"], start_time="20200101")但使用字符串并不是实现表达式的唯一方法。您也可以通过代码实现表达式。下面是一个与上面示例做同样事情的例子。
Python>> from qlib.data.ops import * >> f1 = Feature("high") / Feature("close") >> f2 = Feature("open") / Feature("close") >> f3 = f1 + f2 >> f4 = f3 * f3 / f3 >> data = D.features(["sh600519"], [f4], start_time="20200101") >> data.head()API
要了解如何使用数据,请转到 API 参考:数据 API。
活动:0 -
自定义模型集成
简介
Qlib 的模型库 (Model Zoo) 包含 LightGBM、MLP、LSTM 等模型。这些模型都是预测模型的示例。除了 Qlib 提供的默认模型,用户还可以将自己的自定义模型集成到 Qlib 中。
用户可以按照以下步骤集成自己的自定义模型:
-
定义一个自定义模型类,该类应为
qlib.model.base.Model的子类。 -
编写一个描述自定义模型路径和参数的配置文件。
-
测试自定义模型。
自定义模型类
自定义模型需要继承
qlib.model.base.Model并重写其中的方法。重写
__init__方法Qlib 会将初始化参数传递给
__init__方法。配置文件中模型的超参数必须与
__init__方法中定义的参数保持一致。代码示例:在以下示例中,配置文件中模型的超参数应包含
loss: mse等参数。Pythondef __init__(self, loss='mse', **kwargs): if loss not in {'mse', 'binary'}: raise NotImplementedError self._scorer = mean_squared_error if loss == 'mse' else roc_auc_score self._params.update(objective=loss, **kwargs) self._model = None重写
fit方法Qlib 调用
fit方法来训练模型。参数必须包括训练特征
dataset,这是在接口中设计的。参数可以包含一些具有默认值的可选参数,例如 GBDT 的
num_boost_round = 1000。代码示例:在以下示例中,
num_boost_round = 1000是一个可选参数。Pythondef fit(self, dataset: DatasetH, num_boost_round = 1000, **kwargs): # prepare dataset for lgb training and evaluation df_train, df_valid = dataset.prepare( ["train", "valid"], col_set=["feature", "label"], data_key=DataHandlerLP.DK_L ) x_train, y_train = df_train["feature"], df_train["label"] x_valid, y_valid = df_valid["feature"], df_valid["label"] # Lightgbm need 1D array as its label if y_train.values.ndim == 2 and y_train.values.shape[1] == 1: y_train, y_valid = np.squeeze(y_train.values), np.squeeze(y_valid.values) else: raise ValueError("LightGBM doesn't support multi-label training") dtrain = lgb.Dataset(x_train.values, label=y_train) dvalid = lgb.Dataset(x_valid.values, label=y_valid) # fit the model self.model = lgb.train( self.params, dtrain, num_boost_round=num_boost_round, valid_sets=[dtrain, dvalid], valid_names=["train", "valid"], early_stopping_rounds=early_stopping_rounds, verbose_eval=verbose_eval, evals_result=evals_result, **kwargs )重写
predict方法参数必须包含
dataset参数,该参数将用于获取测试数据集。返回预测得分。
有关
fit方法的参数类型,请参阅模型 API。代码示例:在以下示例中,用户需要使用 LightGBM 预测测试数据
x_test的标签(例如preds)并返回。Pythondef predict(self, dataset: DatasetH, **kwargs)-> pandas.Series: if self.model is None: raise ValueError("model is not fitted yet!") x_test = dataset.prepare("test", col_set="feature", data_key=DataHandlerLP.DK_I) return pd.Series(self.model.predict(x_test.values), index=x_test.index)重写
finetune方法(可选)此方法对用户是可选的。当用户希望在自己的模型上使用此方法时,他们应该继承
ModelFT基类,该基类包含了finetune的接口。参数必须包含
dataset参数。代码示例:在以下示例中,用户将使用 LightGBM 作为模型并对其进行微调。
Pythondef finetune(self, dataset: DatasetH, num_boost_round=10, verbose_eval=20): # Based on existing model and finetune by train more rounds dtrain, _ = self._prepare_data(dataset) self.model = lgb.train( self.params, dtrain, num_boost_round=num_boost_round, init_model=self.model, valid_sets=[dtrain], valid_names=["train"], verbose_eval=verbose_eval, )
配置文件
配置文件在工作流文档中有详细描述。为了将自定义模型集成到 Qlib 中,用户需要修改配置文件中的 “model” 字段。该配置描述了要使用哪个模型以及如何初始化它。
示例:以下示例描述了上述自定义 lightgbm 模型的配置文件中的
model字段,其中module_path是模块路径,class是类名,args是传递给__init__方法的超参数。字段中的所有参数都通过__init__中的**kwargs传递给self._params,除了loss = mse。model: class: LGBModel module_path: qlib.contrib.model.gbdt args: loss: mse colsample_bytree: 0.8879 learning_rate: 0.0421 subsample: 0.8789 lambda_l1: 205.6999 lambda_l2: 580.9768 max_depth: 8 num_leaves: 210 num_threads: 20用户可以在
examples/benchmarks中找到模型基准的配置文件。所有不同模型的配置都列在相应的模型文件夹下。
模型测试
假设配置文件是
examples/benchmarks/LightGBM/workflow_config_lightgbm.yaml,用户可以运行以下命令来测试自定义模型:cd examples # 避免在包含 `qlib` 的目录下运行程序 qrun benchmarks/LightGBM/workflow_config_lightgbm.yaml注意
qrun是 Qlib 的一个内置命令。此外,模型也可以作为单个模块进行测试。
examples/workflow_by_code.ipynb中给出了一个示例。
参考
要了解更多关于预测模型的信息,请参阅预测模型:模型训练与预测和模型 API。
活动:0 -
-
工作流:工作流管理
简介
Qlib 框架中的组件是松散耦合设计的。用户可以像示例中那样,使用这些组件构建自己的量化研究工作流。
此外,Qlib 还提供了更友好的接口
qrun,用于自动运行由配置定义好的整个工作流。运行整个工作流被称为一次执行。通过qrun,用户可以轻松启动一次执行,其中包含以下步骤:-
数据
-
加载
-
处理
-
切片
-
-
模型
-
训练和推断
-
保存和加载
-
-
评估
-
预测信号分析
-
回测
-
对于每一次执行,Qlib 都有一个完整的系统来跟踪在训练、推断和评估阶段生成的所有信息和工件。有关 Qlib 如何处理这些内容的更多信息,请参阅相关文档:记录器:实验管理。
完整示例
在深入细节之前,这里有一个
qrun的完整示例,它定义了典型的量化研究工作流。以下是一个典型的qrun配置文件。YAMLqlib_init: provider_uri: "~/.qlib/qlib_data/cn_data" region: cn market: &market csi300 benchmark: &benchmark SH000300 data_handler_config: &data_handler_config start_time: 2008-01-01 end_time: 2020-08-01 fit_start_time: 2008-01-01 fit_end_time: 2014-12-31 instruments: *market port_analysis_config: &port_analysis_config strategy: class: TopkDropoutStrategy module_path: qlib.contrib.strategy.strategy kwargs: topk: 50 n_drop: 5 signal: <PRED> backtest: start_time: 2017-01-01 end_time: 2020-08-01 account: 100000000 benchmark: *benchmark exchange_kwargs: limit_threshold: 0.095 deal_price: close open_cost: 0.0005 close_cost: 0.0015 min_cost: 5 task: model: class: LGBModel module_path: qlib.contrib.model.gbdt kwargs: loss: mse colsample_bytree: 0.8879 learning_rate: 0.0421 subsample: 0.8789 lambda_l1: 205.6999 lambda_l2: 580.9768 max_depth: 8 num_leaves: 210 num_threads: 20 dataset: class: DatasetH module_path: qlib.data.dataset kwargs: handler: class: Alpha158 module_path: qlib.contrib.data.handler kwargs: *data_handler_config segments: train: [2008-01-01, 2014-12-31] valid: [2015-01-01, 2016-12-31] test: [2017-01-01, 2020-08-01] record: - class: SignalRecord module_path: qlib.workflow.record_temp kwargs: {} - class: PortAnaRecord module_path: qlib.workflow.record_temp kwargs: config: *port_analysis_config将配置保存到
configuration.yaml后,用户只需一条命令即可启动工作流并测试他们的想法:qrun configuration.yaml如果用户想在调试模式下使用
qrun,请使用以下命令:python -m pdb qlib/workflow/cli.py examples/benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml注意
安装 Qlib 后,
qrun将位于您的$PATH目录中。注意
yaml文件中的符号&表示一个字段的锚点,当其他字段包含该参数作为值的一部分时非常有用。以上述配置文件为例,用户可以直接更改market和benchmark的值,而无需遍历整个配置文件。
配置文件
本节将详细介绍
qrun。在使用qrun之前,用户需要准备一个配置文件。以下内容展示了如何准备配置文件的每个部分。配置文件的设计逻辑非常简单。它预定义了固定的工作流,并为用户提供这个
yaml接口来定义如何初始化每个组件。它遵循init_instance_by_config的设计。它定义了 Qlib 每个组件的初始化,通常包括类和初始化参数。例如,以下
yaml和代码是等价的。YAMLmodel: class: LGBModel module_path: qlib.contrib.model.gbdt kwargs: loss: mse colsample_bytree: 0.8879 learning_rate: 0.0421 subsample: 0.8789 lambda_l1: 205.6999 lambda_l2: 580.9768 max_depth: 8 num_leaves: 210 num_threads: 20Pythonfrom qlib.contrib.model.gbdt import LGBModel kwargs = { "loss": "mse" , "colsample_bytree": 0.8879, "learning_rate": 0.0421, "subsample": 0.8789, "lambda_l1": 205.6999, "lambda_l2": 580.9768, "max_depth": 8, "num_leaves": 210, "num_threads": 20, } LGBModel(kwargs)Qlib 初始化部分
首先,配置文件需要包含几个用于 Qlib 初始化的基本参数。
YAMLprovider_uri: "~/.qlib/qlib_data/cn_data" region: cn每个字段的含义如下:
-
provider_uri:类型为str。Qlib 数据的 URI。例如,它可以是get_data.py加载数据后存储的目录。 -
region:-
如果
region == "us",Qlib 将以美股模式初始化。 -
如果
region == "cn",Qlib 将以 A股模式初始化。
-
注意
region的值应与provider_uri中存储的数据保持一致。任务部分
配置中的
task字段对应一个任务,其中包含三个不同子部分的参数:Model、Dataset 和 Record。模型部分
在
task字段中,model部分描述了用于训练和推断的模型的参数。有关基础 Model 类的更多信息,请参阅 Qlib 模型。YAMLmodel: class: LGBModel module_path: qlib.contrib.model.gbdt kwargs: loss: mse colsample_bytree: 0.8879 learning_rate: 0.0421 subsample: 0.8789 lambda_l1: 205.6999 lambda_l2: 580.9768 max_depth: 8 num_leaves: 210 num_threads: 20每个字段的含义如下:
-
class:类型为str。模型类的名称。 -
module_path:类型为str。模型在qlib中的路径。 -
kwargs:模型的关键字参数。有关更多信息,请参阅特定模型的实现:models。
注意
Qlib 提供了一个名为
init_instance_by_config的实用工具,用于使用包含class、module_path和kwargs字段的配置来初始化 Qlib 中的任何类。数据集部分
dataset字段描述了 Qlib 中 Dataset 模块的参数,以及 DataHandler 模块的参数。有关 Dataset 模块的更多信息,请参阅 Qlib 数据。DataHandler 的关键字参数配置如下:
YAMLdata_handler_config: &data_handler_config start_time: 2008-01-01 end_time: 2020-08-01 fit_start_time: 2008-01-01 fit_end_time: 2014-12-31 instruments: *market用户可以参考 DataHandler 的文档,以获取配置中每个字段的含义。
这是 Dataset 模块的配置,该模块将在训练和测试阶段负责数据预处理和切片。
YAMLdataset: class: DatasetH module_path: qlib.data.dataset kwargs: handler: class: Alpha158 module_path: qlib.contrib.data.handler kwargs: *data_handler_config segments: train: [2008-01-01, 2014-12-31] valid: [2015-01-01, 2016-12-31] test: [2017-01-01, 2020-08-01]记录部分
record字段是关于 Qlib 中 Record 模块的参数。Record 负责以标准格式跟踪训练过程和结果,例如信息系数 (IC) 和回测。以下脚本是回测及其使用的策略的配置:
YAMLport_analysis_config: &port_analysis_config strategy: class: TopkDropoutStrategy module_path: qlib.contrib.strategy.strategy kwargs: topk: 50 n_drop: 5 signal: <PRED> backtest: limit_threshold: 0.095 account: 100000000 benchmark: *benchmark deal_price: close open_cost: 0.0005 close_cost: 0.0015 min_cost: 5有关策略和回测配置中每个字段的含义,用户可以查阅文档:策略和回测。
这是不同记录模板(如
SignalRecord和PortAnaRecord)的配置详细信息:YAMLrecord: - class: SignalRecord module_path: qlib.workflow.record_temp kwargs: {} - class: PortAnaRecord module_path: qlib.workflow.record_temp kwargs: config: *port_analysis_config有关 Qlib 中 Record 模块的更多信息,用户可以参阅相关文档:记录。
活动:0 -
-
数据层:数据框架与使用
简介
数据层提供了用户友好的 API 来管理和检索数据。它提供了高性能的数据基础设施。
它专为量化投资而设计。例如,用户可以轻松地使用数据层构建公式化因子 (alphas)。有关更多详细信息,请参阅构建公式化因子。
数据层的介绍包括以下几个部分:
-
数据准备
-
数据 API
-
数据加载器
-
数据处理器
-
数据集
-
缓存
-
数据和缓存文件结构
下面是 Qlib 数据工作流的一个典型示例:
-
用户下载数据并将其转换为 Qlib 格式(文件名后缀为 .bin)。在此步骤中,通常只有一些基本数据(例如 OHLCV)存储在磁盘上。
-
基于 Qlib 的表达式引擎创建一些基本特征(例如 “Ref($close, 60) / $close”,即过去 60 个交易日的收益)。表达式引擎中支持的运算符可以在这里找到。此步骤通常在 Qlib 的数据加载器中实现,它是数据处理器的一个组件。
-
如果用户需要更复杂的数据处理(例如数据归一化),数据处理器支持用户自定义的处理器来处理数据(一些预定义的处理器可以在这里找到)。这些处理器与表达式引擎中的运算符不同。它专为一些难以在表达式引擎中用运算符支持的复杂数据处理方法而设计。
-
最后,数据集负责从数据处理器处理过的数据中为特定模型准备数据集。
数据准备
Qlib 格式数据
我们专门设计了一种数据结构来管理金融数据,有关详细信息,请参阅 Qlib 论文中的文件存储设计部分。此类数据将以
.bin为文件名后缀存储(我们将称之为 .bin 文件、.bin 格式或 Qlib 格式)。.bin 文件专为金融数据的科学计算而设计。Qlib 提供了两个现成的数据集,可通过此链接访问:
数据集 美股市场 A股市场 Alpha360 √ √ Alpha158 √ √ 此外,Qlib 还提供了一个高频数据集。用户可以通过此链接运行高频数据集示例。
Qlib 格式数据集
Qlib 提供了一个 .bin 格式的现成数据集,用户可以使用
scripts/get_data.py脚本下载 A股数据集,如下所示。用户还可以使用 numpy 加载 .bin 文件来验证数据。价格和成交量数据看起来与实际成交价不同,因为它们是复权的(复权价格)。然后您可能会发现不同数据源的复权价格可能不同。这是因为不同的数据源在复权方式上可能有所不同。Qlib 在复权时将每只股票第一个交易日的价格归一化为 1。用户可以利用$factor获取原始交易价格(例如,$close / $factor获取原始收盘价)。以下是关于 Qlib 价格复权的一些讨论。
https://github.com/microsoft/qlib/issues/991#issuecomment-1075252402
# 下载日数据 python scripts/get_data.py qlib_data --target_dir ~/.qlib/qlib_data/cn_data --region cn # 下载1分钟数据 python scripts/get_data.py qlib_data --target_dir ~/.qlib/qlib_data/qlib_cn_1min --region cn --interval 1min除了 A股数据,Qlib 还包含一个美股数据集,可以通过以下命令下载:
python scripts/get_data.py qlib_data --target_dir ~/.qlib/qlib_data/us_data --region us运行上述命令后,用户可以在
~/.qlib/qlib_data/cn_data和~/.qlib/qlib_data/us_data目录中分别找到 Qlib 格式的 A股和美股数据。Qlib 还在
scripts/data_collector中提供了脚本,帮助用户抓取互联网上的最新数据并将其转换为 Qlib 格式。当使用该数据集初始化 Qlib 后,用户可以使用它构建和评估自己的模型。有关更多详细信息,请参阅初始化。
日频数据的自动更新
建议用户先手动更新一次数据(
--trading_date 2021-05-25),然后再设置为自动更新。更多信息请参阅:yahoo collector。
每个交易日自动更新数据到 "qlib" 目录 (Linux):
使用 crontab: crontab -e。
设置定时任务:
* * * * 1-5 python <script path> update_data_to_bin --qlib_data_1d_dir <user data dir>
脚本路径:scripts/data_collector/yahoo/collector.py
手动更新数据:
python scripts/data_collector/yahoo/collector.py update_data_to_bin --qlib_data_1d_dir <user data dir> --trading_date <start date> --end_date <end date>
trading_date: 交易日开始日期
end_date: 交易日结束日期(不包含)
将 CSV 格式转换为 Qlib 格式
Qlib 提供了
scripts/dump_bin.py脚本,可以将任何符合正确格式的 CSV 格式数据转换为 .bin 文件(Qlib 格式)。除了下载准备好的演示数据,用户还可以直接从 Collector 下载演示数据作为 CSV 格式的参考。以下是一些示例:
对于日频数据:
python scripts/get_data.py download_data --file_name csv_data_cn.zip --target_dir ~/.qlib/csv_data/cn_data
对于 1 分钟数据:
python scripts/data_collector/yahoo/collector.py download_data --source_dir ~/.qlib/stock_data/source/cn_1min --region CN --start 2021-05-20 --end 2021-05-23 --delay 0.1 --interval 1min --limit_nums 10
用户也可以提供自己的 CSV 格式数据。但是,CSV 数据必须满足以下标准:
-
CSV 文件以特定股票命名,或者 CSV 文件包含一个股票名称列。
-
以股票命名 CSV 文件:
SH600000.csv、AAPL.csv(不区分大小写)。 -
CSV 文件包含一个股票名称列。在转储数据时,用户必须指定列名。这是一个示例:
python scripts/dump_bin.py dump_all ... --symbol_field_name symbol
其中数据格式如下:
symbol,close
SH600000,120
-
-
CSV 文件必须包含一个日期列,并且在转储数据时,用户必须指定日期列名。这是一个示例:
python scripts/dump_bin.py dump_all ... --date_field_name date
其中数据格式如下:
symbol,date,close,open,volume
SH600000,2020-11-01,120,121,12300000
SH600000,2020-11-02,123,120,12300000
假设用户在目录
~/.qlib/csv_data/my_data中准备了他们的 CSV 格式数据,他们可以运行以下命令来开始转换。python scripts/dump_bin.py dump_all --csv_path ~/.qlib/csv_data/my_data --qlib_dir ~/.qlib/qlib_data/my_data --include_fields open,close,high,low,volume,factor对于转储数据到 .bin 文件时支持的其他参数,用户可以通过运行以下命令来获取信息:
python dump_bin.py dump_all --help
转换后,用户可以在
~/.qlib/qlib_data/my_data目录中找到他们的 Qlib 格式数据。注意
--include_fields的参数应与 CSV 文件的列名相对应。Qlib 提供的数据集的列名至少应包含open、close、high、low、volume和factor。-
open:复权开盘价 -
close:复权收盘价 -
high:复权最高价 -
low:复权最低价 -
volume:复权交易量 -
factor:复权因子。通常,factor = 复权价格 / 原始价格,复权价格参考:split adjusted。
在 Qlib 数据处理的约定中,如果股票停牌,
open、close、high、low、volume、money和factor将被设置为 NaN。如果您想使用无法通过 OCHLV 计算的自定义因子,如 PE、EPS 等,您可以将其与 OHCLV 一起添加到 CSV 文件中,然后将其转储为 Qlib 格式数据。检查数据健康状况
Qlib 提供了一个脚本来检查数据的健康状况。
主要检查点如下:
-
检查 DataFrame 中是否有任何数据缺失。
-
检查 OHLCV 列中是否有任何超出阈值的大幅阶跃变化。
-
检查 DataFrame 中是否缺少任何必需的列 (OLHCV)。
-
检查 DataFrame 中是否缺少
factor列。
您可以运行以下命令来检查数据是否健康。
对于日频数据:
python scripts/check_data_health.py check_data --qlib_dir ~/.qlib/qlib_data/cn_data
对于 1 分钟数据:
python scripts/check_data_health.py check_data --qlib_dir ~/.qlib/qlib_data/cn_data_1min --freq 1min
当然,您还可以添加一些参数来调整测试结果。
可用参数如下:
-
freq:数据频率。 -
large_step_threshold_price:允许的最大价格变化。 -
large_step_threshold_volume:允许的最大成交量变化。 -
missing_data_num:允许数据为空的最大值。
您可以运行以下命令来检查数据是否健康。
对于日频数据:
python scripts/check_data_health.py check_data --qlib_dir ~/.qlib/qlib_data/cn_data --missing_data_num 30055 --large_step_threshold_volume 94485 --large_step_threshold_price 20
对于 1 分钟数据:
python scripts/check_data_health.py check_data --qlib_dir ~/.qlib/qlib_data/cn_data --freq 1min --missing_data_num 35806 --large_step_threshold_volume 3205452000000 --large_step_threshold_price 0.91
股票池 (市场)
Qlib 将股票池定义为股票列表及其日期范围。可以按如下方式导入预定义的股票池(例如 csi300)。
python collector.py --index_name CSI300 --qlib_dir <user qlib data dir> --method parse_instruments多种股票模式
Qlib 现在为用户提供了两种不同的股票模式:A股模式和美股模式。这两种模式的一些不同设置如下:
区域 交易单位 涨跌幅限制阈值 A股 100 0.099 美股 1 None 交易单位定义了可用于交易的股票数量单位,涨跌幅限制阈值定义了股票涨跌百分比的界限。
如果用户在 A股模式下使用 Qlib,则需要 A股数据。用户可以按照以下步骤在 A股模式下使用 Qlib:
-
下载 Qlib 格式的 A股数据,请参阅 Qlib 格式数据集一节。
-
在 A股模式下初始化 Qlib。
假设用户将 Qlib 格式数据下载到 ~/.qlib/qlib_data/cn_data 目录中。用户只需按如下方式初始化 Qlib 即可。
Pythonfrom qlib.constant import REG_CN qlib.init(provider_uri='~/.qlib/qlib_data/cn_data', region=REG_CN)
如果用户在美股模式下使用 Qlib,则需要美股数据。Qlib 也提供了下载美股数据的脚本。用户可以按照以下步骤在美股模式下使用 Qlib:
-
下载 Qlib 格式的美股数据,请参阅 Qlib 格式数据集一节。
-
在美股模式下初始化 Qlib。
假设用户将 Qlib 格式数据准备在 ~/.qlib/qlib_data/us_data 目录中。用户只需按如下方式初始化 Qlib 即可。
Pythonfrom qlib.config import REG_US qlib.init(provider_uri='~/.qlib/qlib_data/us_data', region=REG_US)
注意
我们非常欢迎新的数据源的 PR!用户可以将抓取数据的代码作为 PR 提交,就像这里的示例一样。然后,我们将在我们的服务器上使用该代码创建数据缓存,其他用户可以直接使用。
数据 API
数据检索
用户可以使用
qlib.data中的 API 检索数据,请参阅数据检索。特征
Qlib 提供了
Feature和ExpressionOps以根据用户的需求获取特征。-
Feature:从数据提供者加载数据。用户可以获取$high、$low、$open、$close等特征,这些特征应与--include_fields的参数相对应,请参阅将 CSV 格式转换为 Qlib 格式一节。 -
ExpressionOps:ExpressionOps将使用运算符进行特征构建。要了解更多关于运算符的信息,请参阅运算符 API。此外,Qlib 支持用户定义自己的自定义运算符,tests/test_register_ops.py中给出了一个示例。
要了解更多关于特征的信息,请参阅特征 API。
过滤器
Qlib 提供了
NameDFilter和ExpressionDFilter来根据用户的需求过滤成分股。-
NameDFilter:动态名称过滤器。根据规范的名称格式过滤成分股。需要一个名称规则正则表达式。 -
ExpressionDFilter:动态表达式过滤器。根据某个表达式过滤成分股。需要一个表示某个特征字段的表达式规则。-
基本特征过滤器:
rule_expression = '$close/$open>5' -
横截面特征过滤器:
rule_expression = '$rank($close)<10' -
时间序列特征过滤器:
rule_expression = '$Ref($close, 3)>100'
-
下面是一个简单的示例,展示了如何在基本的 Qlib 工作流配置文件中使用过滤器:
YAMLfilter: &filter filter_type: ExpressionDFilter rule_expression: "Ref($close, -2) / Ref($close, -1) > 1" filter_start_time: 2010-01-01 filter_end_time: 2010-01-07 keep: False data_handler_config: &data_handler_config start_time: 2010-01-01 end_time: 2021-01-22 fit_start_time: 2010-01-01 fit_end_time: 2015-12-31 instruments: *market filter_pipe: [*filter]要了解更多关于过滤器的信息,请参阅过滤器 API。
参考
要了解更多关于数据 API 的信息,请参阅数据 API。
数据加载器
Qlib 中的数据加载器旨在从原始数据源加载原始数据。它将在数据处理器模块中加载和使用。
QlibDataLoader
Qlib 中的
QlibDataLoader类是一个这样的接口,它允许用户从 Qlib 数据源加载原始数据。StaticDataLoader
Qlib 中的
StaticDataLoader类是一个这样的接口,它允许用户从文件或作为提供的数据加载原始数据。接口
以下是
QlibDataLoader类的一些接口:class qlib.data.dataset.loader.DataLoaderDataLoader旨在从原始数据源加载原始数据。abstract load(instruments, start_time=None, end_time=None) -> DataFrame将数据作为
pd.DataFrame加载。数据示例(列的多级索引是可选的):
feature label
$close $volume Ref($close, 1) Mean($close, 3) $high-$low LABEL0
datetime instrument
2010-01-04 SH600000 81.807068 17145150.0 83.737389 83.016739 2.741058 0.0032
SH600004 13.313329 11800983.0 13.313329 13.317701 0.183632 0.0042
SH600005 37.796539 12231662.0 38.258602 37.919757 0.970325 0.0289
参数:
-
instruments(str或dict) – 可以是市场名称,也可以是InstrumentProvider生成的成分股配置文件。如果instruments的值为None,则表示不进行过滤。 -
start_time(str) – 时间范围的开始。 -
end_time(str) – 时间范围的结束。
返回:
从底层源加载的数据。
返回类型:
pd.DataFrame
引发:
KeyError – 如果不支持成分股过滤器,则引发 KeyError。
API
要了解更多关于数据加载器的信息,请参阅数据加载器 API。
数据处理器
Qlib 中的数据处理器模块旨在处理大多数模型将使用的常见数据处理方法。
用户可以通过
qrun在自动化工作流中使用数据处理器,有关更多详细信息,请参阅工作流:工作流管理。DataHandlerLP
除了在
qrun的自动化工作流中使用数据处理器外,数据处理器还可以作为一个独立的模块使用,用户可以通过它轻松地预处理数据(标准化、删除 NaN 等)和构建数据集。为了实现这一点,Qlib 提供了一个基类
qlib.data.dataset.DataHandlerLP。这个类的核心思想是:我们将拥有一些可学习的处理器(Processors),它们可以学习数据处理的参数(例如,zscore 归一化的参数)。当新数据到来时,这些训练过的处理器可以处理新数据,从而可以高效地处理实时数据。有关处理器的更多信息,将在下一小节中列出。接口
以下是
DataHandlerLP提供的一些重要接口:class qlib.data.dataset.handler.DataHandlerLP(instruments=None, start_time=None, end_time=None, data_loader: dict | str | DataLoader | None = None, infer_processors: List = [], learn_processors: List = [], shared_processors: List = [], process_type='append', drop_raw=False, **kwargs)带**(L)可学习 (P)处理器**的数据处理器。
此处理器将生成三部分
pd.DataFrame格式的数据。-
DK_R / self._data: 从加载器加载的原始数据 -
DK_I / self._infer: 为推断处理的数据 -
DK_L / self._learn: 为学习模型处理的数据
使用不同的处理器工作流进行学习和推断的动机是多方面的。以下是一些例子:
-
学习和推断的成分股范围可能不同。
-
某些样本的处理可能依赖于标签(例如,一些达到涨跌停的样本可能需要额外处理或被删除)。
-
这些处理器仅适用于学习阶段。
数据处理器提示:
为了减少内存开销:
drop_raw=True: 这将就地修改原始数据;
请注意,self._infer 或 self._learn 等处理过的数据与 Qlib 数据集中的 segments(如“train”和“test”)是不同的概念。
-
self._infer或self._learn等处理过的数据是使用不同处理器处理的底层数据。 -
Qlib 数据集中的 segments(如“train”和“test”)只是查询数据时的时间分段(“train”在时间上通常位于“test”之前)。
例如,您可以在“train”时间分段中查询由 infer_processors 处理的 data._infer。
__init__(instruments=None, start_time=None, end_time=None, data_loader: dict | str | DataLoader | None = None, infer_processors: List = [], learn_processors: List = [], shared_processors: List = [], process_type='append', drop_raw=False, **kwargs)参数:
-
infer_processors (list) –
用于生成推断数据的一系列处理器描述信息。
描述信息的示例:
-
类名和 kwargs:
JSON{ "class": "MinMaxNorm", "kwargs": { "fit_start_time": "20080101", "fit_end_time": "20121231" } }-
仅类名:
"DropnaFeature" -
处理器对象实例
-
-
learn_processors(list) – 类似于infer_processors,但用于生成模型学习数据。 -
process_type(str) –-
PTYPE_I = 'independent'-
self._infer将由infer_processors处理 -
self._learn将由learn_processors处理
-
-
PTYPE_A = 'append'-
self._infer将由infer_processors处理 -
self._learn将由infer_processors + learn_processors处理 -
(例如
self._infer由learn_processors处理)
-
-
-
drop_raw(bool) – 是否删除原始数据。
fit():不处理数据,仅拟合数据。
fit_process_data():拟合并处理数据。前一个处理器的输出将作为 fit 的输入。
process_data(with_fit: bool = False):处理数据。如有必要,运行 processor.fit。
符号:
(data) [processor]# self.process_type == DataHandlerLP.PTYPE_I 的数据处理流程 (self._data)-[shared_processors]-(_shared_df)-[learn_processors]-(_learn_df) \ -[infer_processors]-(_infer_df) # self.process_type == DataHandlerLP.PTYPE_A 的数据处理流程 (self._data)-[shared_processors]-(_shared_df)-[infer_processors]-(_infer_df)-[learn_processors]-(_learn_df)参数:
-
with_fit(bool) – 前一个处理器的输出将作为fit的输入。
config(processor_kwargs: dict | None = None, **kwargs)
数据配置。# 从数据源加载哪些数据。
此方法将在从数据集加载腌制(pickled)处理器时使用。数据将使用不同的时间范围进行初始化。
setup_data(init_type: str = 'fit_seq', **kwargs)
在多次运行初始化时设置数据。
参数:
-
init_type(str) – 上面列出的IT_*类型。 -
enable_cache (bool) –
默认值为 false:
如果 enable_cache == True:处理过的数据将保存在磁盘上,当下次调用 init 时,处理器将直接从磁盘加载缓存的数据。
fetch(selector: Timestamp | slice | str = slice(None, None, None), level: str | int = 'datetime', col_set='__all', data_key: Literal['raw', 'infer', 'learn'] = 'infer', squeeze: bool = False, proc_func: Callable | None = None) -> DataFrame
从底层数据源获取数据。
参数:
-
selector(Union[pd.Timestamp, slice, str]) – 描述如何按索引选择数据。 -
level(Union[str, int]) – 选择哪个索引级别的数据。 -
col_set(str) – 选择一组有意义的列(例如 features, columns)。 -
data_key(str) – 获取的数据:DK_*。 -
proc_func(Callable) – 请参阅DataHandler.fetch的文档。
返回类型:pd.DataFrame
引发:NotImplementedError –
get_cols(col_set='__all', data_key: Literal['raw', 'infer', 'learn'] = 'infer') -> list
获取列名。
参数:
-
col_set(str) – 选择一组有意义的列(例如 features, columns)。 -
data_key(DATA_KEY_TYPE) – 获取的数据:DK_*。
返回:
列名列表。
返回类型:
list
classmethod cast(handler: DataHandlerLP) -> DataHandlerLP
动机:
用户在他的自定义包中创建了一个数据处理器。然后,他想将处理过的处理器分享给其他用户,而无需引入包依赖和复杂的数据处理逻辑。这个类通过将类转换为 DataHandlerLP 并仅保留处理过的数据来实现这一点。
参数:
-
handler (DataHandlerLP) – DataHandlerLP 的子类。
返回:
转换后的处理过的数据。
返回类型:
DataHandlerLP
classmethod from_df(df: DataFrame) -> DataHandlerLP
动机:当用户想要快速获取一个数据处理器时。
创建的数据处理器将只有一个共享 DataFrame,不带处理器。创建处理器后,用户通常会想将其转储以供重用。这是一个典型的用例:
Pythonfrom qlib.data.dataset import DataHandlerLP dh = DataHandlerLP.from_df(df) dh.to_pickle(fname, dump_all=True)TODO: -
StaticDataLoader相当慢。它不必再次复制数据…如果用户想通过配置加载特征和标签,可以定义一个新的处理器并调用 qlib.contrib.data.handler.Alpha158 的静态方法 parse_config_to_fields。
此外,用户还可以将 qlib.contrib.data.processor.ConfigSectionProcessor 传递给新的处理器,它提供了一些用于通过配置定义的特征的预处理方法。
处理器
Qlib 中的处理器模块被设计为可学习的,它负责处理数据处理,例如归一化和删除空/NaN 特征/标签。
Qlib 提供了以下处理器:
-
DropnaProcessor:删除 N/A 特征的处理器。 -
DropnaLabel:删除 N/A 标签的处理器。 -
TanhProcess:使用tanh处理噪声数据的处理器。 -
ProcessInf:处理无穷大值的处理器,它将被替换为该列的平均值。 -
Fillna:处理 N/A 值的处理器,它将用 0 或其他给定数字填充 N/A 值。 -
MinMaxNorm:应用 Min-Max 归一化的处理器。 -
ZscoreNorm:应用 Z-score 归一化的处理器。 -
RobustZScoreNorm:应用鲁棒 Z-score 归一化的处理器。 -
CSZScoreNorm:应用横截面 Z-score 归一化的处理器。 -
CSRankNorm:应用横截面排名归一化的处理器。 -
CSZFillna:以横截面方式用该列的平均值填充 N/A 值的处理器。
用户还可以通过继承 Processor 的基类来创建自己的处理器。有关更多信息,请参阅所有处理器的实现(处理器链接)。
要了解更多关于处理器的信息,请参阅处理器 API。
示例
数据处理器可以通过修改配置文件与 qrun 一起运行,也可以作为一个独立的模块使用。
要了解更多关于如何与 qrun 一起运行数据处理器的信息,请参阅工作流:工作流管理。
Qlib 提供了已实现的数据处理器
Alpha158。以下示例展示了如何将Alpha158作为一个独立的模块运行。注意
用户需要先用
qlib.init初始化 Qlib,请参阅初始化。Pythonimport qlib from qlib.contrib.data.handler import Alpha158 data_handler_config = { "start_time": "2008-01-01", "end_time": "2020-08-01", "fit_start_time": "2008-01-01", "fit_end_time": "2014-12-31", "instruments": "csi300", } if __name__ == "__main__": qlib.init() h = Alpha158(**data_handler_config) # 获取数据的所有列 print(h.get_cols()) # 获取所有标签 print(h.fetch(col_set="label")) # 获取所有特征 print(h.fetch(col_set="feature"))注意
在 Alpha158 中,Qlib 使用的标签是
Ref($close, -2)/Ref($close, -1) - 1,这意味着从 T+1 到 T+2 的变化,而不是Ref($close, -1)/$close - 1。原因是在获取 A股的 T 日收盘价时,股票可以在 T+1 日买入,在 T+2 日卖出。API
要了解更多关于数据处理器的信息,请参阅数据处理器 API。
数据集
Qlib 中的数据集模块旨在为模型训练和推断准备数据。
该模块的动机是我们希望最大化不同模型处理适合其自身的数据的灵活性。该模块赋予模型以独特方式处理其数据的灵活性。例如,像 GBDT 这样的模型可能在包含
nan或None值的数据上运行良好,而像 MLP 这样的神经网络模型则会因此崩溃。如果用户的模型需要以不同的方式处理数据,用户可以实现自己的 Dataset 类。如果模型的数据处理不特殊,则可以直接使用
DatasetH。DatasetH类是带有数据处理器的数据集。这是该类最重要的接口:class qlib.data.dataset.__init__.DatasetH(handler: Dict | DataHandler, segments: Dict[str, Tuple], fetch_kwargs: Dict = {}, **kwargs)带数据处理器的数据集。
用户应尽量将数据预处理功能放入处理器中。只有以下数据处理功能应放在数据集中:
-
与特定模型相关的处理。
-
与数据拆分相关的处理。
__init__(handler: Dict | DataHandler, segments: Dict[str, Tuple], fetch_kwargs: Dict = {}, **kwargs)
设置底层数据。
参数:
-
handler (Union[dict, DataHandler]) –
处理器可以是:
-
DataHandler的实例 -
DataHandler的配置。请参阅数据处理器
-
-
segments (dict) –
描述如何分割数据。以下是一些示例:
-
'segments': {
'train': ("2008-01-01", "2014-12-31"),
'valid': ("2017-01-01", "2020-08-01",),
'test': ("2015-01-01", "2016-12-31",),
}
-
'segments': {
'insample': ("2008-01-01", "2014-12-31"),
'outsample': ("2017-01-01", "2020-08-01",),
}
-
-
config(handler_kwargs: dict | None = None, **kwargs)
初始化 DatasetH
参数:
-
handler_kwargs (dict) –
DataHandler 的配置,可以包括以下参数:
-
DataHandler.conf_data的参数,例如instruments、start_time和end_time。
-
-
kwargs (dict) –
DatasetH 的配置,例如:
-
segmentsdict-
segments的配置与self.__init__中的相同。
-
-
-
-
setup_data(handler_kwargs: dict | None = None, **kwargs)
设置数据。
参数:
-
handler_kwargs (dict) –
DataHandler 的初始化参数,可以包括以下参数:
-
init_type:Handler的初始化类型 -
enable_cache: 是否启用缓存
-
-
-
prepare(segments: List[str] | Tuple[str] | str | slice | Index, col_set='__all', data_key='infer', **kwargs) -> List[DataFrame] | DataFrame
为学习和推断准备数据。
参数:
-
segments (Union[List[Text], Tuple[Text], Text, slice]) –
描述要准备的数据的范围。以下是一些示例:
-
'train' -
['train', 'valid']
-
-
col_set (str) –
获取数据时将传递给 self.handler。TODO:使其自动化:
-
为测试数据选择
DK_I -
为训练数据选择
DK_L
-
-
data_key(str) – 要获取的数据:DK_*。默认是DK_I,表示获取用于推断的数据。 -
kwargs –
kwargs 可能包含的参数:
-
flt_colstr-
它只存在于 TSDatasetH 中,可用于添加一个数据列(True 或 False)来过滤数据。此参数仅在它是 TSDatasetH 的实例时受支持。
返回类型:Union[List[pd.DataFrame], pd.DataFrame]
引发:NotImplementedError –
-
-
-
API
要了解更多关于数据集的信息,请参阅数据集 API。
缓存
缓存是一个可选模块,通过将一些常用数据保存为缓存文件来帮助加速数据提供。Qlib 提供了一个
Memcache类来缓存内存中最常用的数据,一个可继承的ExpressionCache类,以及一个可继承的DatasetCache类。全局内存缓存
Memcache是一个全局内存缓存机制,由三个MemCacheUnit实例组成,用于缓存日历、成分股和特征。MemCache在cache.py中全局定义为H。用户可以使用H['c'],H['i'],H['f']来获取/设置内存缓存。class qlib.data.cache.MemCacheUnit(*args, **kwargs)
内存缓存单元。
__init__(*args, **kwargs)
property limited
内存缓存是否受限。
class qlib.data.cache.MemCache(mem_cache_size_limit=None, limit_type='length')
内存缓存。
__init__(mem_cache_size_limit=None, limit_type='length')
参数:
-
mem_cache_size_limit– 缓存的最大大小。 -
limit_type–length或sizeof;length(调用函数:len),size(调用函数:sys.getsizeof)。
表达式缓存
ExpressionCache是一个缓存机制,用于保存Mean($close, 5)等表达式。用户可以继承这个基类来定义自己的缓存机制,以保存表达式,步骤如下。-
重写
self._uri方法以定义如何生成缓存文件路径。 -
重写
self._expression方法以定义将缓存哪些数据以及如何缓存。
以下是接口的详细信息:
class qlib.data.cache.ExpressionCache(provider)
表达式缓存机制基类。
此类用于使用自定义的表达式缓存机制封装表达式提供者。
注意
重写 _uri 和 _expression 方法来创建您自己的表达式缓存机制。
expression(instrument, field, start_time, end_time, freq)
获取表达式数据。
注意
与表达式提供者中的 expression 方法接口相同。
update(cache_uri: str | Path, freq: str = 'day')
将表达式缓存更新到最新的日历。
重写此方法以定义如何根据用户自己的缓存机制更新表达式缓存。
参数:
-
cache_uri(str或Path) – 表达式缓存文件的完整 URI(包括目录路径)。 -
freq(str) –
返回:
0(更新成功)/ 1(无需更新)/ 2(更新失败)。
返回类型:int
Qlib 目前提供了已实现的磁盘缓存
DiskExpressionCache,它继承自ExpressionCache。表达式数据将存储在磁盘上。数据集缓存
DatasetCache是一个缓存机制,用于保存数据集。一个特定的数据集由股票池配置(或一系列成分股,尽管不推荐)、表达式列表或静态特征字段、所收集特征的开始时间和结束时间以及频率来规范。用户可以继承这个基类来定义自己的缓存机制,以保存数据集,步骤如下。-
重写
self._uri方法以定义如何生成缓存文件路径。 -
重写
self._expression方法以定义将缓存哪些数据以及如何缓存。
以下是接口的详细信息:
class qlib.data.cache.DatasetCache(provider)
数据集缓存机制基类。
此类用于使用自定义的数据集缓存机制封装数据集提供者。
注意
重写 _uri 和 _dataset 方法来创建您自己的数据集缓存机制。
dataset(instruments, fields, start_time=None, end_time=None, freq='day', disk_cache=1, inst_processors=[])
获取特征数据集。
注意
与数据集提供者中的 dataset 方法接口相同。
注意
服务器使用 redis_lock 来确保不会触发读写冲突,但客户端读取器不在考虑范围内。
update(cache_uri: str | Path, freq: str = 'day')
将数据集缓存更新到最新的日历。
重写此方法以定义如何根据用户自己的缓存机制更新数据集缓存。
参数:
-
cache_uri(str或Path) – 数据集缓存文件的完整 URI(包括目录路径)。 -
freq(str) –
返回:
0(更新成功)/ 1(无需更新)/ 2(更新失败)。
返回类型:int
static cache_to_origin_data(data, fields)
将缓存数据转换为原始数据。
参数:
-
data–pd.DataFrame,缓存数据。 -
fields – 特征字段。
返回:
pd.DataFrame。
static normalize_uri_args(instruments, fields, freq)
规范化 URI 参数。
Qlib 目前提供了已实现的磁盘缓存
DiskDatasetCache,它继承自DatasetCache。数据集数据将存储在磁盘上。
数据和缓存文件结构
我们专门设计了一种文件结构来管理数据和缓存,有关详细信息,请参阅 Qlib 论文中的文件存储设计部分。数据和缓存的文件结构如下。
-
data/-
[raw data]由数据提供者更新-
calendars/-
day.txt
-
-
instruments/-
all.txt -
csi500.txt -
...
-
-
features/-
sh600000/-
open.day.bin -
close.day.bin -
...
-
-
...
-
-
-
[cached data]原始数据更新时更新-
calculated features/-
sh600000/-
[hash(instrtument, field_expression, freq)]-
all-time expression -cache data file(全时间表达式缓存数据文件) -
.meta:一个辅助元文件,记录成分股名称、字段名称、频率和访问次数。
-
-
-
...
-
-
cache/-
[hash(stockpool_config, field_expression_list, freq)]-
all-time Dataset-cache data file(全时间数据集缓存数据文件) -
.meta:一个辅助元文件,记录股票池配置、字段名称和访问次数。 -
.index:一个辅助索引文件,记录所有日历的行索引。
-
-
...
-
-
-
活动:0 -
-
预测模型:模型训练与预测
简介
预测模型旨在为股票生成预测分数。用户可以通过
qrun在自动化工作流中使用预测模型,请参阅工作流:工作流管理。由于 Qlib 中的组件采用松散耦合的设计,预测模型也可以作为一个独立的模块使用。
基类与接口
Qlib 提供了一个基类
qlib.model.base.Model,所有模型都应继承自该类。该基类提供了以下接口:
class qlib.model.base.Model
可学习的模型
fit(dataset: Dataset, reweighter: Reweighter)
从基础模型中学习模型。
注意
学习到的模型的属性名称不应以 _ 开头。这样模型就可以被转储到磁盘。
以下代码示例展示了如何从数据集中检索
x_train、y_train和w_train:Python# get features and labels df_train, df_valid = dataset.prepare( ["train", "valid"], col_set=["feature", "label"], data_key=DataHandlerLP.DK_L) x_train, y_train = df_train["feature"], df_train["label"] x_valid, y_valid = df_valid["feature"], df_valid["label"] # get weights try: wdf_train, wdf_valid = dataset.prepare(["train", "valid"], col_set=["weight"], data_key=DataHandlerLP.DK_L) w_train, w_valid = wdf_train["weight"], wdf_valid["weight"] except KeyError as e: w_train = pd.DataFrame(np.ones_like(y_train.values), index=y_train.index) w_valid = pd.DataFrame(np.ones_like(y_valid.values), index=y_valid.index)参数:
-
dataset(Dataset) – 数据集将生成用于模型训练的处理过的数据。
abstract predict(dataset: Dataset, segment: str | slice = 'test') -> object
给定数据集进行预测。
参数:
-
dataset(Dataset) – 数据集将生成用于模型训练的处理过的数据集。 -
segment (Text or slice) – 数据集将使用此分段来准备数据。(默认为 test)
返回类型:
具有特定类型(例如 pandas.Series)的预测结果。
Qlib 还提供了一个基类
qlib.model.base.ModelFT,其中包含了微调模型的方法。对于
finetune等其他接口,请参阅模型 API。
示例
Qlib 的模型库 (Model Zoo) 包含 LightGBM、MLP、LSTM 等模型。这些模型被视为预测模型的基线。以下步骤展示了如何将
LightGBM作为独立模块运行。-
首先,使用
qlib.init初始化 Qlib,请参阅初始化。 -
运行以下代码以获取预测分数
pred_score。
Pythonfrom qlib.contrib.model.gbdt import LGBModel from qlib.contrib.data.handler import Alpha158 from qlib.utils import init_instance_by_config, flatten_dict from qlib.workflow import R from qlib.workflow.record_temp import SignalRecord, PortAnaRecord market = "csi300" benchmark = "SH000300" data_handler_config = { "start_time": "2008-01-01", "end_time": "2020-08-01", "fit_start_time": "2008-01-01", "fit_end_time": "2014-12-31", "instruments": market, } task = { "model": { "class": "LGBModel", "module_path": "qlib.contrib.model.gbdt", "kwargs": { "loss": "mse", "colsample_bytree": 0.8879, "learning_rate": 0.0421, "subsample": 0.8789, "lambda_l1": 205.6999, "lambda_l2": 580.9768, "max_depth": 8, "num_leaves": 210, "num_threads": 20, }, }, "dataset": { "class": "DatasetH", "module_path": "qlib.data.dataset", "kwargs": { "handler": { "class": "Alpha158", "module_path": "qlib.contrib.data.handler", "kwargs": data_handler_config, }, "segments": { "train": ("2008-01-01", "2014-12-31"), "valid": ("2015-01-01", "2016-12-31"), "test": ("2017-01-01", "2020-08-01"), }, }, }, } # 模型初始化 model = init_instance_by_config(task["model"]) dataset = init_instance_by_config(task["dataset"]) # 开始实验 with R.start(experiment_name="workflow"): # 训练 R.log_params(**flatten_dict(task)) model.fit(dataset) # 预测 recorder = R.get_recorder() sr = SignalRecord(model, dataset, recorder) sr.generate()注意
Alpha158 是 Qlib 提供的数据处理器,请参阅数据处理器。SignalRecord 是 Qlib 中的记录模板,请参阅工作流。
此外,上述示例已在
examples/train_backtest_analyze.ipynb中给出。从技术上讲,模型预测的含义取决于用户设计的标签设置。默认情况下,分数的含义通常是预测模型对成分股的评级。分数越高,成分股的利润潜力越大。
自定义模型
Qlib 支持自定义模型。如果用户有兴趣自定义自己的模型并将其集成到 Qlib 中,请参阅自定义模型集成。
API
请参阅模型 API。
活动:0 -
-
投资组合策略:投资组合管理
简介
投资组合策略旨在采用不同的投资组合策略,这意味着用户可以基于预测模型的预测分数采用不同的算法来生成投资组合。用户可以通过 Workflow 模块在自动化工作流中使用投资组合策略,请参阅工作流:工作流管理。
由于 Qlib 中的组件采用松散耦合的设计,投资组合策略也可以作为一个独立的模块使用。
Qlib 提供了几种已实现的投资组合策略。此外,Qlib 支持自定义策略,用户可以根据自己的需求自定义策略。
在用户指定模型(预测信号)和策略后,运行回测将帮助用户检查自定义模型(预测信号)/策略的性能。
基类与接口
BaseStrategy
Qlib 提供了一个基类
qlib.strategy.base.BaseStrategy。所有策略类都需要继承该基类并实现其接口。generate_trade_decision:
generate_trade_decision 是一个关键接口,它在每个交易时段生成交易决策。调用此方法的频率取决于执行器频率("time_per_step" 默认为 "day")。但交易频率可以由用户的实现决定。例如,如果用户希望每周交易,而执行器中的 time_per_step 是 "day",则用户可以每周返回非空的 TradeDecision(否则返回空,像这样)。
用户可以继承
BaseStrategy来自定义他们的策略类。WeightStrategyBase
Qlib 还提供了一个类
qlib.contrib.strategy.WeightStrategyBase,它是BaseStrategy的子类。WeightStrategyBase只关注目标头寸,并根据头寸自动生成订单列表。它提供了generate_target_weight_position接口。generate_target_weight_position:
根据当前头寸和交易日期生成目标头寸。输出的权重分布不考虑现金。
返回目标头寸。
注意
这里的目标头寸是指总资产的目标百分比。
WeightStrategyBase实现了generate_order_list接口,其处理过程如下。-
调用
generate_target_weight_position方法生成目标头寸。 -
从目标头寸生成股票的目标数量。
-
从目标数量生成订单列表。
用户可以继承
WeightStrategyBase并实现generate_target_weight_position接口来自定义他们的策略类,该策略类只关注目标头寸。
已实现的策略
Qlib 提供了一个名为
TopkDropoutStrategy的已实现的策略类。TopkDropoutStrategy
TopkDropoutStrategy是BaseStrategy的子类,并实现了generate_order_list接口,其过程如下。-
采用 Topk-Drop 算法计算每只股票的目标数量。
注意
Topk-Drop 算法有两个参数:
-
Topk:持有的股票数量。 -
Drop:每个交易日卖出的股票数量。
通常,当前持有的股票数量是 Topk,除了交易开始时期为零。对于每个交易日,设 d 是当前持有的股票中,按预测分数从高到低排名时排名 gt K 的股票数量。然后将卖出当前持有的 d 只预测分数最差的股票,并买入相同数量的未持有但预测分数最佳的股票。
通常,d = Drop,尤其是在候选股票池很大,K 很大且 Drop 很小的情况下。
在大多数情况下,TopkDrop 算法每天卖出和买入 Drop 只股票,这使得换手率为 2 * Drop / K。
下图说明了一个典型的场景。
-
-
从目标数量生成订单列表。
EnhancedIndexingStrategy
EnhancedIndexingStrategy 增强型指数化结合了主动管理和被动管理的艺术,旨在在控制风险敞口(又称跟踪误差)的同时,在投资组合回报方面跑赢基准指数(例如,标准普尔 500 指数)。
更多信息请参阅 qlib.contrib.strategy.signal_strategy.EnhancedIndexingStrategy 和 qlib.contrib.strategy.optimizer.enhanced_indexing.EnhancedIndexingOptimizer。
用法与示例
首先,用户可以创建一个模型来获取交易信号(在以下情况下变量名为
pred_score)。预测分数
预测分数是一个 pandas DataFrame。它的索引是 <datetime(pd.Timestamp), instrument(str)>,并且它必须包含一个 score 列。
预测样本如下所示。
datetime instrument score 2019-01-04 SH600000 -0.505488 2019-01-04 SZ002531 -0.320391 2019-01-04 SZ000999 0.583808 2019-01-04 SZ300569 0.819628 2019-01-04 SZ001696 -0.137140 ... ... ... 2019-04-30 SZ000996 -1.027618 2019-04-30 SH603127 0.225677 2019-04-30 SH603126 0.462443 2019-04-30 SH603133 -0.302460 2019-04-30 SZ300760 -0.126383 预测模型模块可以进行预测,请参阅预测模型:模型训练与预测。
通常,预测分数是模型的输出。但有些模型是从不同尺度的标签中学习的。因此,预测分数的尺度可能与您的预期(例如,成分股的收益)不同。
Qlib 没有添加一个步骤来将预测分数统一缩放到一个尺度,原因如下。
-
因为并非每个交易策略都关心尺度(例如,
TopkDropoutStrategy只关心排名)。因此,策略有责任重新缩放预测分数(例如,一些基于投资组合优化的策略可能需要有意义的尺度)。 -
模型可以灵活地定义目标、损失和数据处理。因此,我们不认为仅仅基于模型的输出来直接重新缩放它有一个万能的方法。如果您想将其重新缩放到一些有意义的值(例如,股票收益),一个直观的解决方案是为您模型的近期输出和您近期的目标值创建一个回归模型。
运行回测
在大多数情况下,用户可以使用
backtest_daily回测他们的投资组合管理策略。Pythonfrom pprint import pprint import qlib import pandas as pd from qlib.utils.time import Freq from qlib.utils import flatten_dict from qlib.contrib.evaluate import backtest_daily from qlib.contrib.evaluate import risk_analysis from qlib.contrib.strategy import TopkDropoutStrategy # init qlib qlib.init(provider_uri=<qlib data dir>) CSI300_BENCH = "SH000300" STRATEGY_CONFIG = { "topk": 50, "n_drop": 5, # pred_score, pd.Series "signal": pred_score, } strategy_obj = TopkDropoutStrategy(**STRATEGY_CONFIG) report_normal, positions_normal = backtest_daily( start_time="2017-01-01", end_time="2020-08-01", strategy=strategy_obj) analysis = dict() # default frequency will be daily (i.e. "day") analysis["excess_return_without_cost"] = risk_analysis(report_normal["return"] - report_normal["bench"]) analysis["excess_return_with_cost"] = risk_analysis(report_normal["return"] - report_normal["bench"] - report_normal["cost"]) analysis_df = pd.concat(analysis) # type: pd.DataFrame pprint(analysis_df)如果用户希望以更详细的方式控制他们的策略(例如,用户有一个更高级的执行器版本),用户可以遵循这个示例。
Pythonfrom pprint import pprint import qlib import pandas as pd from qlib.utils.time import Freq from qlib.utils import flatten_dict from qlib.backtest import backtest, executor from qlib.contrib.evaluate import risk_analysis from qlib.contrib.strategy import TopkDropoutStrategy # init qlib qlib.init(provider_uri=<qlib data dir>) CSI300_BENCH = "SH000300" # Benchmark 用于计算您的策略的超额收益。 # 它的数据格式将像**一个普通成分股**。 # 例如,您可以使用以下代码查询其数据 # `D.features(["SH000300"], ["$close"], start_time='2010-01-01', end_time='2017-12-31', freq='day')` # 它与参数 `market` 不同,`market` 表示一个股票池(例如,**一组**股票,如 csi300) # 例如,您可以使用以下代码查询股票市场的所有数据。 # `D.features(D.instruments(market='csi300'), ["$close"], start_time='2010-01-01', end_time='2017-12-31', freq='day')` FREQ = "day" STRATEGY_CONFIG = { "topk": 50, "n_drop": 5, # pred_score, pd.Series "signal": pred_score, } EXECUTOR_CONFIG = { "time_per_step": "day", "generate_portfolio_metrics": True, } backtest_config = { "start_time": "2017-01-01", "end_time": "2020-08-01", "account": 100000000, "benchmark": CSI300_BENCH, "exchange_kwargs": { "freq": FREQ, "limit_threshold": 0.095, "deal_price": "close", "open_cost": 0.0005, "close_cost": 0.0015, "min_cost": 5, }, } # 策略对象 strategy_obj = TopkDropoutStrategy(**STRATEGY_CONFIG) # 执行器对象 executor_obj = executor.SimulatorExecutor(**EXECUTOR_CONFIG) # 回测 portfolio_metric_dict, indicator_dict = backtest(executor=executor_obj, strategy=strategy_obj, **backtest_config) analysis_freq = "{0}{1}".format(*Freq.parse(FREQ)) # 回测信息 report_normal, positions_normal = portfolio_metric_dict.get(analysis_freq) # 分析 analysis = dict() analysis["excess_return_without_cost"] = risk_analysis( report_normal["return"] - report_normal["bench"], freq=analysis_freq) analysis["excess_return_with_cost"] = risk_analysis( report_normal["return"] - report_normal["bench"] - report_normal["cost"], freq=analysis_freq) analysis_df = pd.concat(analysis) # type: pd.DataFrame # 记录指标 analysis_dict = flatten_dict(analysis_df["risk"].unstack().T.to_dict()) # 打印结果 pprint(f"以下是基准收益({analysis_freq})的分析结果。") pprint(risk_analysis(report_normal["bench"], freq=analysis_freq)) pprint(f"以下是无成本超额收益({analysis_freq})的分析结果。") pprint(analysis["excess_return_without_cost"]) pprint(f"以下是有成本超额收益({analysis_freq})的分析结果。") pprint(analysis["excess_return_with_cost"])结果
回测结果采用以下形式:
risk
excess_return_without_cost mean 0.000605
std 0.005481
annualized_return 0.152373
information_ratio 1.751319
max_drawdown -0.059055
excess_return_with_cost mean 0.000410
std 0.005478
annualized_return 0.103265
information_ratio 1.187411
max_drawdown -0.075024
-
excess_return_without_cost-
mean:无成本的CAR(累计异常收益)的平均值。 -
std:无成本的CAR(累计异常收益)的标准差。 -
annualized_return:无成本的CAR(累计异常收益)的年化收益率。 -
information_ratio:无成本的信息比率。请参阅信息比率 – IR。 -
max_drawdown:无成本的CAR(累计异常收益)的最大回撤。请参阅最大回撤 (MDD)。
-
-
excess_return_with_cost-
mean:有成本的CAR(累计异常收益)系列的平均值。 -
std:有成本的CAR(累计异常收益)系列的标准差。 -
annualized_return:有成本的CAR(累计异常收益)的年化收益率。 -
information_ratio:有成本的信息比率。请参阅信息比率 – IR。 -
max_drawdown:有成本的CAR(累计异常收益)的最大回撤。请参阅最大回撤 (MDD)。
-
参考
要了解更多关于预测模型输出的预测分数
pred_score的信息,请参阅预测模型:模型训练与预测。活动:0 -
-
高频交易中的嵌套决策执行框架设计
简介
日内交易(例如投资组合管理)和盘中交易(例如订单执行)是量化投资中的两个热门话题,通常是分开研究的。
为了获得日内交易和盘中交易的联合交易表现,它们必须相互作用并联合运行回测。为了支持多个级别的联合回测策略,需要一个相应的框架。目前公开可用的高频交易框架都没有考虑多级别的联合交易,这使得上述回测不准确。
除了回测,不同级别的策略优化也不是独立的,它们会相互影响。例如,最佳投资组合管理策略可能会随着订单执行性能的变化而改变(例如,当我们改进订单执行策略时,换手率更高的投资组合可能会成为更好的选择)。为了实现整体良好的性能,有必要考虑不同级别策略之间的相互作用。
因此,为了解决上述各种问题,构建一个新的多级别交易框架变得很有必要。为此,我们设计了一个考虑策略相互作用的嵌套决策执行框架。
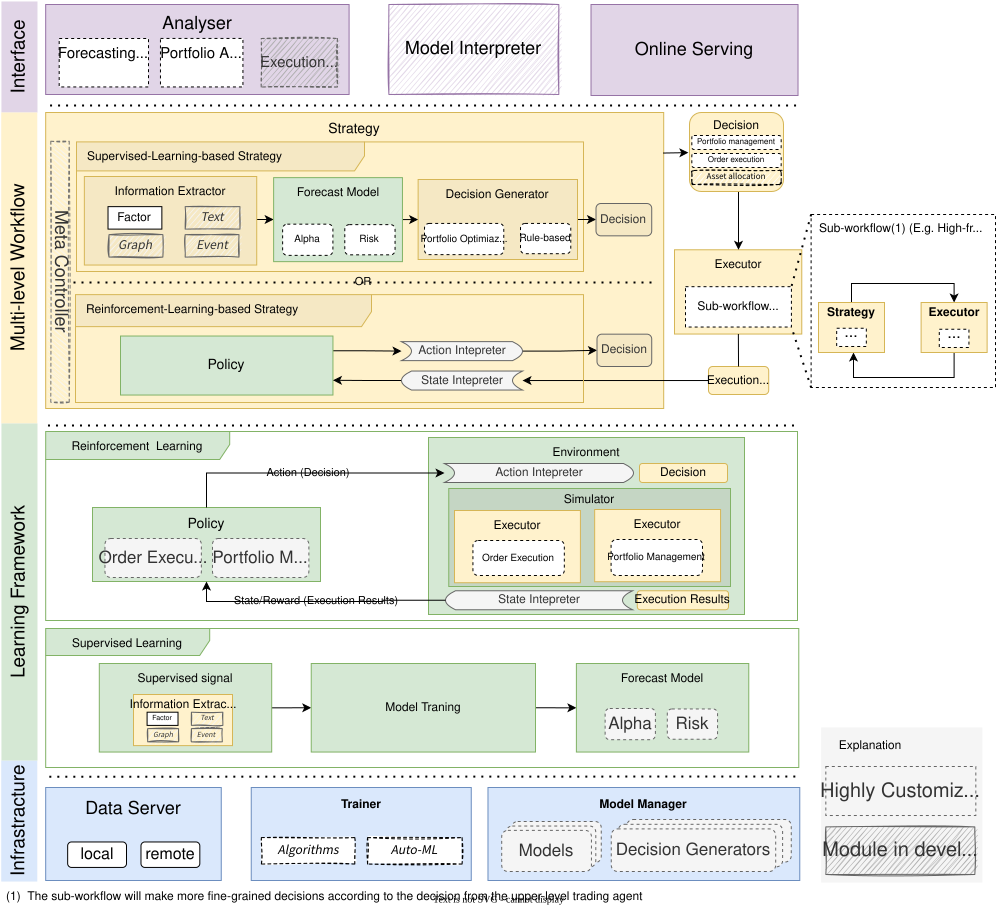
该框架的设计如上图中间的黄色部分所示。每个级别都由
Trading Agent和Execution Env组成。Trading Agent有其自己的数据处理模块 (Information Extractor)、预测模块 (Forecast Model) 和决策生成器 (Decision Generator)。交易算法根据Forecast Module输出的预测信号,通过Decision Generator生成决策,生成的决策被传递给Execution Env,后者返回执行结果。交易算法的频率、决策内容和执行环境可以由用户定制(例如,盘中交易、日频交易、周频交易),并且执行环境内部可以嵌套更细粒度的交易算法和执行环境(即图中的子工作流,例如,日频订单可以通过在日内拆分订单转换为更细粒度的决策)。嵌套决策执行框架的灵活性使用户可以轻松探索不同级别交易策略组合的效果,并打破不同级别交易算法之间的优化壁垒。
嵌套决策执行框架的优化可以在
QlibRL的支持下实现。要了解如何使用QlibRL的更多信息,请访问 API 参考:RL API。
示例
高频嵌套决策执行框架的示例可以在这里找到。
此外,除了上述示例,以下是一些关于 Qlib 中高频交易的其他相关工作。
-
使用高频数据进行预测
-
从非固定频率的高频数据中提取特征的示例。
-
一篇关于高频交易的论文。
活动:0 -
-
元控制器:元任务、元数据集与元模型
简介
元控制器为预测模型提供指导,其目的是学习一系列预测任务中的规律模式,并利用这些学习到的模式来指导未来的预测任务。用户可以基于 Meta Controller 模块实现自己的元模型实例。
元任务
元任务实例是元学习框架中的基本元素。它保存可供元模型使用的数据。多个元任务实例可能共享同一个
Data Handler,由元数据集控制。用户应该使用prepare_task_data()来获取可以直接输入元模型的数据。class qlib.model.meta.task.MetaTask(task: dict, meta_info: object, mode: str = 'full')
一个独立的元任务,一个元数据集包含一个元任务列表。它作为 MetaDatasetDS 中的一个组件。
数据处理方式不同:
-
训练和测试之间的处理输入可能不同。
-
训练时,训练任务中的
X、y、X_test、y_test是必需的(# PROC_MODE_FULL #),但在测试任务中不是必需的(# PROC_MODE_TEST #)。 -
当元模型可以转移到其他数据集时,只有
meta_info是必需的(# PROC_MODE_TRANSFER #)。
__init__(task: dict, meta_info: object, mode: str = 'full')
__init__ 函数负责:
-
存储任务。
-
存储原始输入数据。
-
处理元数据的输入数据。
参数:
-
task(dict) – 待元模型增强的任务。 -
meta_info(object) – 元模型的输入。
get_meta_input() -> object
返回处理过的 meta_info。
元数据集
元数据集控制元信息生成过程。它负责为训练元模型提供数据。用户应该使用
prepare_tasks来检索元任务实例列表。class qlib.model.meta.dataset.MetaTaskDataset(segments: Dict[str, Tuple] | float, *args, **kwargs)
一个在元级别获取数据的数据集。
元数据集负责:
-
输入任务(例如 Qlib 任务)并准备元任务。
-
元任务比普通任务包含更多信息(例如,元模型的输入数据)。
-
所学到的模式可以转移到其他元数据集。应支持以下情况:
-
在元数据集 A 上训练的元模型,然后应用于元数据集 B。
-
元数据集 A 和 B 之间共享一些模式,因此当元模型应用于元数据集 B 时,会使用元数据集 A 上的元输入。
-
__init__(segments: Dict[str, Tuple] | float, *args, **kwargs)
元数据集在初始化时维护一个元任务列表。
-
segments表示划分数据的方式。 -
MetaTaskDataset的__init__函数的职责是初始化任务。
prepare_tasks(segments: List[str] | str, *args, **kwargs) -> List[MetaTask]
准备每个元任务中的数据,并为训练做好准备。
以下代码示例展示了如何从元数据集中检索元任务列表:
Python# get the train segment and the test segment, both of them are lists train_meta_tasks, test_meta_tasks = meta_dataset.prepare_tasks(["train", "test"])参数:
-
segments (Union[List[Text], Tuple[Text], Text]) – 用于选择数据的信息。
返回:
一个元任务列表,其中包含用于训练元模型的每个元任务的已准备数据。对于多个分段 [seg1, seg2, ..., segN],返回的列表将是 [[seg1 中的任务], [seg2 中的任务], ..., [segN 中的任务]]。每个任务都是一个元任务。
返回类型:list
元模型
通用元模型
元模型实例是控制工作流的部分。元模型的用法包括:
-
用户使用
fit函数训练他们的元模型。 -
元模型实例通过
inference函数提供有用信息来指导工作流。
class qlib.model.meta.model.MetaModel
指导模型学习的元模型。
“指导”一词可以根据模型学习的阶段分为两类:
-
学习任务的定义:请参阅
MetaTaskModel的文档。 -
控制模型的学习过程:请参阅
MetaGuideModel的文档。
abstract fit(*args, **kwargs)
元模型的训练过程。
abstract inference(*args, **kwargs) -> object
元模型的推理过程。
返回:
一些用于指导模型学习的信息。
返回类型:object
元任务模型
此类元模型可能直接与任务定义交互。因此,元任务模型是它们要继承的类。它们通过修改基本任务定义来指导基本任务。
prepare_tasks函数可用于获取修改后的基本任务定义。class qlib.model.meta.model.MetaTaskModel
此类元模型处理基本任务定义。元模型在训练后为训练新的基本预测模型创建任务。prepare_tasks 直接修改任务定义。
fit(meta_dataset: MetaTaskDataset)
MetaTaskModel 应该从 meta_dataset 中获取已准备好的 MetaTask。然后,它将从元任务中学习知识。
inference(meta_dataset: MetaTaskDataset) -> List[dict]
MetaTaskModel 将对 meta_dataset 进行推理。MetaTaskModel 应该从 meta_dataset 中获取已准备好的 MetaTask。然后,它将创建带有 Qlib 格式的修改后的任务,这些任务可以由 Qlib 训练器执行。
返回:
一个修改后的任务定义列表。
返回类型:List[dict]
元指导模型
此类元模型参与基本预测模型的训练过程。元模型可以在基本预测模型的训练过程中指导它们,以提高其性能。
class qlib.model.meta.model.MetaGuideModel
此类元模型旨在指导基本模型的训练过程。元模型在基本预测模型的训练过程中与它们交互。
abstract fit(*args, **kwargs)
元模型的训练过程。
abstract inference(*args, **kwargs)
元模型的推理过程。
返回:
一些用于指导模型学习的信息。
返回类型:object
示例
Qlib 提供了一个名为 DDG-DA 的 Meta Model 模块实现,该模块可适应市场动态。
DDG-DA 包括四个步骤:
-
计算元信息并将其封装到
Meta Task实例中。所有元任务构成一个Meta Dataset实例。 -
基于元数据集的训练数据训练
DDG-DA。 -
对
DDG-DA进行推理以获取指导信息。 -
将指导信息应用于预测模型以提高其性能。
上述示例可以在
examples/benchmarks_dynamic/DDG-DA/workflow.py中找到。活动:0 -
-
Qlib 记录器:实验管理
简介
Qlib 包含一个名为 QlibRecorder 的实验管理系统,旨在帮助用户高效地处理实验和分析结果。
该系统由三个组件组成:
-
ExperimentManager:一个管理实验的类。
-
Experiment:一个实验类,每个实例负责一个单独的实验。
-
Recorder:一个记录器类,每个实例负责一个单独的运行。
以下是该系统结构的总体视图:
ExperimentManager - Experiment 1 - Recorder 1 - Recorder 2 - ... - Experiment 2 - Recorder 1 - Recorder 2 - ... - ...这个实验管理系统定义了一组接口并提供了一个具体的实现:MLflowExpManager,它基于机器学习平台 MLFlow。
如果用户将
ExpManager的实现设置为MLflowExpManager,他们可以使用mlflow ui命令来可视化和检查实验结果。有关更多信息,请参阅此处的相关文档。
Qlib 记录器
QlibRecorder 为用户提供了一个高级 API 来使用实验管理系统。接口被封装在 Qlib 中的变量
R中,用户可以直接使用R与系统交互。以下命令展示了如何在 Python 中导入R:Pythonfrom qlib.workflow import RQlibRecorder 包括几个用于在工作流中管理实验和记录器的常用 API。有关更多可用 API,请参阅下面关于实验管理器、实验和记录器的部分。
以下是 QlibRecorder 的可用接口:
class qlib.workflow.__init__.QlibRecorder(exp_manager: ExpManager)
一个帮助管理实验的全局系统。
__init__(exp_manager: ExpManager)start(*, experiment_id: str | None = None, experiment_name: str | None = None, recorder_id: str | None = None, recorder_name: str | None = None, uri: str | None = None, resume: bool = False)
启动实验的方法。此方法只能在 Python 的 with 语句中调用。以下是示例代码:
Python# start new experiment and recorder with R.start(experiment_name='test', recorder_name='recorder_1'): model.fit(dataset) R.log... ... # further operations # resume previous experiment and recorder with R.start(experiment_name='test', recorder_name='recorder_1', resume=True): # if users want to resume recorder, they have to specify the exact same name for experiment and recorder. ... # further operations参数:
-
experiment_id(str) – 要启动的实验 ID。 -
experiment_name(str) – 要启动的实验名称。 -
recorder_id(str) – 要在实验下启动的记录器 ID。 -
recorder_name(str) – 要在实验下启动的记录器名称。 -
uri(str) – 实验的跟踪 URI,所有工件/指标等都将存储在此处。默认 URI 在qlib.config中设置。请注意,此uri参数不会更改配置文件中定义的 URI。因此,下次用户在同一实验中调用此函数时,他们也必须指定相同值的此参数。否则,可能会出现不一致的 URI。 -
resume(bool) – 是否恢复给定实验下指定名称的记录器。
start_exp(*, experiment_id=None, experiment_name=None, recorder_id=None, recorder_name=None, uri=None, resume=False)
启动实验的底层方法。使用此方法时,应手动结束实验,并且记录器的状态可能无法正确处理。以下是示例代码:
PythonR.start_exp(experiment_name='test', recorder_name='recorder_1') ... # further operations R.end_exp('FINISHED') or R.end_exp(Recorder.STATUS_S)参数:
-
experiment_id(str) – 要启动的实验 ID。 -
experiment_name(str) – 要启动的实验名称。 -
recorder_id(str) – 要在实验下启动的记录器 ID。 -
recorder_name(str) – 要在实验下启动的记录器名称。 -
uri(str) – 实验的跟踪 URI,所有工件/指标等都将存储在此处。默认 URI 在qlib.config中设置。 -
resume (bool) – 是否恢复给定实验下指定名称的记录器。
返回类型:
一个已启动的实验实例。
end_exp(recorder_status='FINISHED')
手动结束实验的方法。它将结束当前活动的实验及其活动的记录器,并指定 status 类型。以下是此方法的示例代码:
PythonR.start_exp(experiment_name='test') ... # further operations R.end_exp('FINISHED') or R.end_exp(Recorder.STATUS_S)参数:
-
status(str) – 记录器的状态,可以是 SCHEDULED、RUNNING、FINISHED、FAILED。
search_records(experiment_ids, **kwargs)
获取符合搜索条件的记录的 pandas DataFrame。
此函数的参数不是固定的,它们会因 Qlib 中 ExpManager 的不同实现而异。Qlib 现在提供了 ExpManager 的 mlflow 实现,以下是使用 MLflowExpManager 的此方法的示例代码:
PythonR.log_metrics(m=2.50, step=0) records = R.search_records([experiment_id], order_by=["metrics.m DESC"])参数:
-
experiment_ids(list) – 实验 ID 列表。 -
filter_string(str) – 筛选查询字符串,默认为搜索所有运行。 -
run_view_type(int) – 枚举值 ACTIVE_ONLY、DELETED_ONLY 或 ALL 之一(例如在mlflow.entities.ViewType中)。 -
max_results(int) – 放入 DataFrame 的最大运行次数。 -
order_by (list) – 按列排序的列表(例如,“metrics.rmse”)。
返回:
一个 pandas.DataFrame 记录,其中每个指标、参数和标签分别扩展为名为 metrics.*、params.* 和 tags.* 的列。对于没有特定指标、参数或标签的记录,它们的值将分别为 (NumPy) Nan、None 或 None。
list_experiments()
列出所有现有实验的方法(已删除的除外)。
Pythonexps = R.list_experiments()返回类型:
一个存储的实验信息字典(名称 -> 实验)。
list_recorders(experiment_id=None, experiment_name=None)
列出具有给定 ID 或名称的实验的所有记录器的方法。
如果用户没有提供实验的 ID 或名称,此方法将尝试检索默认实验并列出默认实验的所有记录器。如果默认实验不存在,该方法将首先创建默认实验,然后在其下创建一个新的记录器。(有关默认实验的更多信息可以在此处找到)。
以下是示例代码:
Pythonrecorders = R.list_recorders(experiment_name='test')参数:
-
experiment_id(str) – 实验的 ID。 -
experiment_name (str) – 实验的名称。
返回类型:
一个存储的记录器信息字典(ID -> 记录器)。
get_exp(*, experiment_id=None, experiment_name=None, create: bool = True, start: bool = False) -> Experiment
使用给定 ID 或名称检索实验的方法。一旦将 create 参数设置为 True,如果找不到有效的实验,此方法将为您创建一个。否则,它只会检索特定的实验或引发错误。
如果 'create' 为 True:
-
如果活动实验存在:
-
未指定 ID 或名称,返回活动实验。
-
如果指定了 ID 或名称,则返回指定的实验。如果找不到此类实验,则使用给定 ID 或名称创建一个新实验。
-
-
如果活动实验不存在:
-
未指定 ID 或名称,创建默认实验,并将该实验设置为活动状态。
-
如果指定了 ID 或名称,则返回指定的实验。如果找不到此类实验,则使用给定名称或默认实验创建一个新实验。
否则,如果 'create' 为 False:
-
-
如果活动实验存在:
-
未指定 ID 或名称,返回活动实验。
-
如果指定了 ID 或名称,则返回指定的实验。如果找不到此类实验,则引发错误。
-
-
如果活动实验不存在:
-
未指定 ID 或名称。如果默认实验存在,则返回它,否则引发错误。
-
如果指定了 ID 或名称,则返回指定的实验。如果找不到此类实验,则引发错误。
以下是一些用例:
-
Python# Case 1 with R.start('test'): exp = R.get_exp() recorders = exp.list_recorders() # Case 2 with R.start('test'): exp = R.get_exp(experiment_name='test1') # Case 3 exp = R.get_exp() -> a default experiment. # Case 4 exp = R.get_exp(experiment_name='test') # Case 5 exp = R.get_exp(create=False) -> the default experiment if exists.参数:
-
experiment_id(str) – 实验的 ID。 -
experiment_name(str) – 实验的名称。 -
create(boolean) – 一个参数,用于确定如果实验之前未创建,该方法是否会自动根据用户的规范创建一个新实验。 -
start (bool) – 当 start 为 True 时,如果实验尚未启动(未激活),它将启动。它专为 R.log_params 自动启动实验而设计。
返回类型:
具有给定 ID 或名称的实验实例。
delete_exp(experiment_id=None, experiment_name=None)
删除具有给定 ID 或名称的实验的方法。必须至少提供 ID 或名称中的一个,否则会发生错误。
以下是示例代码:
PythonR.delete_exp(experiment_name='test')参数:
-
experiment_id(str) – 实验的 ID。 -
experiment_name(str) – 实验的名称。
get_uri()
检索当前实验管理器的 URI 的方法。
以下是示例代码:
Pythonuri = R.get_uri()返回类型:
当前实验管理器的 URI。
set_uri(uri: str | None)
重置当前实验管理器的默认 URI 的方法。
注意:
当 URI 指的是文件路径时,请使用绝对路径,而不是像 “~/mlruns/” 这样的字符串。后端不支持这样的字符串。
uri_context(uri: str)
暂时将 exp_manager 的 default_uri 设置为 uri。
注意:
-
请参阅 set_uri 中的注意。
参数:
-
uri(Text) – 临时 URI。
get_recorder(*, recorder_id=None, recorder_name=None, experiment_id=None, experiment_name=None) -> Recorder
检索记录器的方法。
-
如果活动记录器存在:
-
未指定 ID 或名称,返回活动记录器。
-
如果指定了 ID 或名称,则返回指定的记录器。
-
-
如果活动记录器不存在:
-
未指定 ID 或名称,引发错误。
-
如果指定了 ID 或名称,则必须提供相应的 experiment_name,返回指定的记录器。否则,引发错误。
记录器可用于进一步处理,例如 save_object、load_object、log_params、log_metrics 等。
以下是一些用例:
-
Python# Case 1 with R.start(experiment_name='test'): recorder = R.get_recorder() # Case 2 with R.start(experiment_name='test'): recorder = R.get_recorder(recorder_id='2e7a4efd66574fa49039e00ffaefa99d') # Case 3 recorder = R.get_recorder() -> Error # Case 4 recorder = R.get_recorder(recorder_id='2e7a4efd66574fa49039e00ffaefa99d') -> Error # Case 5 recorder = R.get_recorder(recorder_id='2e7a4efd66574fa49039e00ffaefa99d', experiment_name='test')用户可能会关心的一些问题:
-
问:如果多个记录器符合查询条件(例如,使用
experiment_name查询),它将返回哪个记录器? -
答:如果使用 mlflow 后端,将返回 start_time 最晚的记录器。因为 MLflow 的 search_runs 函数保证了这一点。
参数:
-
recorder_id(str) – 记录器的 ID。 -
recorder_name(str) – 记录器的名称。 -
experiment_name (str) – 实验的名称。
返回类型:
一个记录器实例。
delete_recorder(recorder_id=None, recorder_name=None)
删除具有给定 ID 或名称的记录器的方法。必须至少提供 ID 或名称中的一个,否则会发生错误。
以下是示例代码:
PythonR.delete_recorder(recorder_id='2e7a4efd66574fa49039e00ffaefa99d')参数:
-
recorder_id(str) – 实验的 ID。 -
recorder_name(str) – 实验的名称。
save_objects(local_path=None, artifact_path=None, **kwargs: Dict[str, Any])
将对象作为工件保存在实验中到 URI 的方法。它支持从本地文件/目录保存,或直接保存对象。用户可以使用有效的 Python 关键字参数来指定要保存的对象及其名称(名称:值)。
总而言之,此 API 旨在将对象保存到实验管理后端路径,
-
Qlib 提供两种方法来指定对象:
-
通过
**kwargs直接传入对象(例如R.save_objects(trained_model=model))。 -
传入对象的本地路径,即
local_path参数。
-
-
artifact_path 表示实验管理后端路径。
如果活动记录器存在:它将通过活动记录器保存对象。
如果活动记录器不存在:系统将创建一个默认实验和一个新的记录器,并在其下保存对象。
注意
如果想使用特定的记录器保存对象,建议先通过 get_recorder API 获取特定的记录器,然后使用该记录器保存对象。支持的参数与此方法相同。
以下是一些用例:
Python# Case 1 with R.start(experiment_name='test'): pred = model.predict(dataset) R.save_objects(**{"pred.pkl": pred}, artifact_path='prediction') rid = R.get_recorder().id ... R.get_recorder(recorder_id=rid).load_object("prediction/pred.pkl") # after saving objects, you can load the previous object with this api # Case 2 with R.start(experiment_name='test'): R.save_objects(local_path='results/pred.pkl', artifact_path="prediction") rid = R.get_recorder().id ... R.get_recorder(recorder_id=rid).load_object("prediction/pred.pkl") # after saving objects, you can load the previous object with this api参数:
-
local_path(str) – 如果提供,则将文件或目录保存到工件 URI。 -
artifact_path(str) – 要存储在 URI 中的工件的相对路径。 -
**kwargs(Dict[Text, Any]) – 要保存的对象。例如,{"pred.pkl": pred}。
load_object(name: str)
从 URI 中实验的工件中加载对象的方法。
log_params(**kwargs)
在实验期间记录参数的方法。除了使用 R,用户还可以在使用 get_recorder API 获取特定记录器后,记录到该记录器。
如果活动记录器存在:它将通过活动记录器记录参数。
如果活动记录器不存在:系统将创建一个默认实验和一个新的记录器,并在其下记录参数。
以下是一些用例:
Python# Case 1 with R.start('test'): R.log_params(learning_rate=0.01) # Case 2 R.log_params(learning_rate=0.01)参数:
-
argument(keyword) –name1=value1, name2=value2, ...。
log_metrics(step=None, **kwargs)
在实验期间记录指标的方法。除了使用 R,用户还可以在使用 get_recorder API 获取特定记录器后,记录到该记录器。
如果活动记录器存在:它将通过活动记录器记录指标。
如果活动记录器不存在:系统将创建一个默认实验和一个新的记录器,并在其下记录指标。
以下是一些用例:
Python# Case 1 with R.start('test'): R.log_metrics(train_loss=0.33, step=1) # Case 2 R.log_metrics(train_loss=0.33, step=1)参数:
-
argument(keyword) –name1=value1, name2=value2, ...。
log_artifact(local_path: str, artifact_path: str | None = None)
将本地文件或目录作为工件记录到当前活动的运行中。
如果活动记录器存在:它将通过活动记录器设置标签。
如果活动记录器不存在:系统将创建一个默认实验和一个新的记录器,并在其下设置标签。
参数:
-
local_path(str) – 要写入的文件路径。 -
artifact_path(Optional[str]) – 如果提供,则为要写入的artifact_uri中的目录。
download_artifact(path: str, dst_path: str | None = None) -> str
将工件文件或目录从运行下载到本地目录(如果适用),并返回其本地路径。
参数:
-
path(str) – 目标工件的相对源路径。 -
dst_path (Optional[str]) – 用于下载指定工件的本地文件系统目标目录的绝对路径。此目录必须已存在。如果未指定,工件将下载到本地文件系统上一个新创建的、具有唯一名称的目录中。
返回:
目标工件的本地路径。
返回类型:str
set_tags(**kwargs)
为记录器设置标签的方法。除了使用 R,用户还可以在使用 get_recorder API 获取特定记录器后,为该记录器设置标签。
如果活动记录器存在:它将通过活动记录器设置标签。
如果活动记录器不存在:系统将创建一个默认实验和一个新的记录器,并在其下设置标签。
以下是一些用例:
Python# Case 1 with R.start('test'): R.set_tags(release_version="2.2.0") # Case 2 R.set_tags(release_version="2.2.0")参数:
-
argument(keyword) –name1=value1, name2=value2, ...。
实验管理器 (Experiment Manager)
Qlib 中的
ExpManager模块负责管理不同的实验。ExpManager的大多数 API 与 QlibRecorder 类似,其中最重要的 API 是get_exp方法。用户可以直接参考上面的文档,获取有关如何使用get_exp方法的一些详细信息。class qlib.workflow.expm.ExpManager(uri: str, default_exp_name: str | None)
这是用于管理实验的 ExpManager 类。其 API 设计类似于 mlflow。(链接:https://mlflow.org/docs/latest/python_api/mlflow.html)
ExpManager 预期是一个单例(顺便说一下,我们可以有多个 URI 不同的 Experiment。用户可以从不同的 URI 获取不同的实验,然后比较它们的记录)。全局配置(即 C)也是一个单例。
因此,我们试图将它们对齐。它们共享同一个变量,称为 default uri。有关变量共享的详细信息,请参阅 ExpManager.default_uri。
当用户启动一个实验时,他们可能希望将 URI 设置为特定的 URI(在此期间它将覆盖 default uri),然后取消设置该特定 URI 并回退到默认 URI。ExpManager._active_exp_uri 就是那个特定 URI。
__init__(uri: str, default_exp_name: str | None)start_exp(*, experiment_id: str | None = None, experiment_name: str | None = None, recorder_id: str | None = None, recorder_name: str | None = None, uri: str | None = None, resume: bool = False, **kwargs) -> Experiment
启动一个实验。此方法首先获取或创建一个实验,然后将其设置为活动状态。
_active_exp_uri 的维护包含在 start_exp 中,其余实现应包含在子类中的 _end_exp 中。
参数:
-
experiment_id(str) – 活动实验的 ID。 -
experiment_name(str) – 活动实验的名称。 -
recorder_id(str) – 要启动的记录器 ID。 -
recorder_name(str) – 要启动的记录器名称。 -
uri(str) – 当前跟踪 URI。 -
resume (boolean) – 是否恢复实验和记录器。
返回类型:
一个活动实验。
end_exp(recorder_status: str = 'SCHEDULED', **kwargs)
结束一个活动实验。
_active_exp_uri 的维护包含在 end_exp 中,其余实现应包含在子类中的 _end_exp 中。
参数:
-
experiment_name(str) – 活动实验的名称。 -
recorder_status(str) – 实验中活动记录器的状态。
create_exp(experiment_name: str | None = None)
创建一个实验。
参数:
-
experiment_name (str) – 实验名称,必须是唯一的。
返回类型:
一个实验对象。
引发:
ExpAlreadyExistError –
search_records(experiment_ids=None, **kwargs)
获取符合实验搜索条件的记录的 pandas DataFrame。输入是用户想要应用的搜索条件。
返回:
一个 pandas.DataFrame 记录,其中每个指标、参数和标签分别扩展为名为 metrics.*、params.* 和 tags.* 的列。对于没有特定指标、参数或标签的记录,它们的值将分别为 (NumPy) Nan、None 或 None。
get_exp(*, experiment_id=None, experiment_name=None, create: bool = True, start: bool = False)
检索一个实验。此方法包括获取一个活动实验,以及获取或创建一个特定实验。
当用户指定实验 ID 和名称时,该方法将尝试返回特定实验。当用户未提供记录器 ID 或名称时,该方法将尝试返回当前活动实验。create 参数决定了如果实验之前未创建,该方法是否会自动根据用户的规范创建一个新实验。
如果 create 为 True:
-
如果活动实验存在:
-
未指定 ID 或名称,返回活动实验。
-
如果指定了 ID 或名称,则返回指定的实验。如果找不到此类实验,则使用给定 ID 或名称创建一个新实验。如果
start设置为True,则将实验设置为活动状态。
-
-
如果活动实验不存在:
-
未指定 ID 或名称,创建默认实验。
-
如果指定了 ID 或名称,则返回指定的实验。如果找不到此类实验,则使用给定 ID 或名称创建一个新实验。如果 start 设置为 True,则将实验设置为活动状态。
否则,如果 create 为 False:
-
-
如果活动实验存在:
-
未指定 ID 或名称,返回活动实验。
-
如果指定了 ID 或名称,则返回指定的实验。如果找不到此类实验,则引发错误。
-
-
如果活动实验不存在:
-
未指定 ID 或名称。如果默认实验存在,则返回它,否则引发错误。
-
如果指定了 ID 或名称,则返回指定的实验。如果找不到此类实验,则引发错误。
参数:
-
-
experiment_id(str) – 要返回的实验 ID。 -
experiment_name(str) – 要返回的实验名称。 -
create(boolean) – 如果实验之前未创建,则创建它。 -
start (boolean) – 如果创建了新实验,则启动它。
返回类型:
一个实验对象。
delete_exp(experiment_id=None, experiment_name=None)
删除一个实验。
参数:
-
experiment_id(str) – 实验 ID。 -
experiment_name(str) – 实验名称。
property default_uri
从 qlib.config.C 获取默认跟踪 URI。
property uri
获取默认跟踪 URI 或当前 URI。
返回类型:
跟踪 URI 字符串。
list_experiments()
列出所有现有实验。
返回类型:
一个存储的实验信息字典(名称 -> 实验)。
对于 create_exp、delete_exp 等其他接口,请参阅实验管理器 API。
实验 (Experiment)
Experiment类只负责一个单独的实验,它将处理与实验相关的任何操作。包括start、end实验等基本方法。此外,与记录器相关的方法也可用:此类方法包括get_recorder和list_recorders。class qlib.workflow.exp.Experiment(id, name)
这是每个正在运行的实验的 Experiment 类。其 API 设计类似于 mlflow。(链接:https://mlflow.org/docs/latest/python_api/mlflow.html)
__init__(id, name)start(*, recorder_id=None, recorder_name=None, resume=False)
启动实验并将其设置为活动状态。此方法还将启动一个新的记录器。
参数:
-
recorder_id(str) – 要创建的记录器 ID。 -
recorder_name(str) – 要创建的记录器名称。 -
resume (bool) – 是否恢复第一个记录器。
返回类型:
一个活动记录器。
end(recorder_status='SCHEDULED')
结束实验。
参数:
-
recorder_status(str) – 结束时要设置的记录器状态(SCHEDULED、RUNNING、FINISHED、FAILED)。
create_recorder(recorder_name=None)
为每个实验创建一个记录器。
参数:
-
recorder_name (str) – 要创建的记录器名称。
返回类型:
一个记录器对象。
search_records(**kwargs)
获取符合实验搜索条件的记录的 pandas DataFrame。输入是用户想要应用的搜索条件。
返回:
一个 pandas.DataFrame 记录,其中每个指标、参数和标签分别扩展为名为 metrics.*、params.* 和 tags.* 的列。对于没有特定指标、参数或标签的记录,它们的值将分别为 (NumPy) Nan、None 或 None。
delete_recorder(recorder_id)
为每个实验创建一个记录器。
参数:
-
recorder_id(str) – 要删除的记录器 ID。
get_recorder(recorder_id=None, recorder_name=None, create: bool = True, start: bool = False) -> Recorder
为用户检索记录器。当用户指定记录器 ID 和名称时,该方法将尝试返回特定记录器。当用户未提供记录器 ID 或名称时,该方法将尝试返回当前活动记录器。create 参数决定了如果记录器之前未创建,该方法是否会自动根据用户的规范创建一个新记录器。
如果 create 为 True:
-
如果活动记录器存在:
-
未指定 ID 或名称,返回活动记录器。
-
如果指定了 ID 或名称,则返回指定的记录器。如果找不到此类实验,则使用给定 ID 或名称创建一个新记录器。如果
start设置为True,则将记录器设置为活动状态。
-
-
如果活动记录器不存在:
-
未指定 ID 或名称,创建一个新的记录器。
-
如果指定了 ID 或名称,则返回指定的实验。如果找不到此类实验,则使用给定 ID 或名称创建一个新记录器。如果 start 设置为 True,则将记录器设置为活动状态。
否则,如果 create 为 False:
-
-
如果活动记录器存在:
-
未指定 ID 或名称,返回活动记录器。
-
如果指定了 ID 或名称,则返回指定的记录器。如果找不到此类实验,则引发错误。
-
-
如果活动记录器不存在:
-
未指定 ID 或名称,引发错误。
-
如果指定了 ID 或名称,则返回指定的记录器。如果找不到此类实验,则引发错误。
参数:
-
-
recorder_id(str) – 要删除的记录器 ID。 -
recorder_name(str) – 要删除的记录器名称。 -
create(boolean) – 如果记录器之前未创建,则创建它。 -
start (boolean) – 如果创建了新记录器,则启动它。
返回类型:
一个记录器对象。
list_recorders(rtype: Literal['dict', 'list'] = 'dict', **flt_kwargs) -> List[Recorder] | Dict[str, Recorder]
列出此实验的所有现有记录器。在调用此方法之前,请先获取实验实例。如果用户想使用 R.list_recorders() 方法,请参阅 QlibRecorder 中的相关 API 文档。
-
flt_kwargsdict-
按条件筛选记录器,例如 list_recorders(status=Recorder.STATUS_FI)
返回:
-
-
如果
rtype== "dict":-
一个存储的记录器信息字典(ID -> 记录器)。
-
-
如果
rtype== "list":-
一个 Recorder 列表。
返回类型:
返回类型取决于 rtype。
对于 search_records、delete_recorder 等其他接口,请参阅实验 API。
Qlib 还提供了一个默认的 Experiment,当用户使用 log_metrics 或 get_exp 等 API 时,在某些情况下会创建和使用它。如果使用默认的 Experiment,在运行 Qlib 时会有相关的日志信息。用户可以在 Qlib 的配置文件中或在 Qlib 的初始化期间更改默认 Experiment 的名称,该名称设置为“Experiment”。
-
记录器 (Recorder)
Recorder类负责一个单独的记录器。它将处理一些详细的操作,例如一次运行的log_metrics、log_params。它旨在帮助用户轻松跟踪在一次运行中生成的结果和事物。以下是一些未包含在 QlibRecorder 中的重要 API:
class qlib.workflow.recorder.Recorder(experiment_id, name)
这是用于记录实验的 Recorder 类。其 API 设计类似于 mlflow。(链接:https://mlflow.org/docs/latest/python_api/mlflow.html)
记录器的状态可以是 SCHEDULED、RUNNING、FINISHED、FAILED。
__init__(experiment_id, name)save_objects(local_path=None, artifact_path=None, **kwargs)
将预测文件或模型检查点等对象保存到工件 URI。用户可以通过关键字参数(名称:值)保存对象。
请参阅 qlib.workflow:R.save_objects 的文档。
参数:
-
local_path(str) – 如果提供,则将文件或目录保存到工件 URI。 -
artifact_path=None(str) – 要存储在 URI 中的工件的相对路径。
load_object(name)
加载预测文件或模型检查点等对象。
参数:
-
name (str) – 要加载的文件名。
返回类型:
保存的对象。
start_run()
启动或恢复记录器。返回值可以用作 with 块中的上下文管理器;否则,您必须调用 end_run() 来终止当前运行。(请参阅 mlflow 中的 ActiveRun 类)
返回类型:
一个活动运行对象(例如 mlflow.ActiveRun 对象)。
end_run()
结束一个活动记录器。
log_params(**kwargs)
为当前运行记录一批参数。
参数:
-
arguments(keyword) – 要记录为参数的键值对。
log_metrics(step=None, **kwargs)
为当前运行记录多个指标。
参数:
-
arguments(keyword) – 要记录为指标的键值对。
log_artifact(local_path: str, artifact_path: str | None = None)
将本地文件或目录作为工件记录到当前活动的运行中。
参数:
-
local_path(str) – 要写入的文件路径。 -
artifact_path(Optional[str]) – 如果提供,则为要写入的artifact_uri中的目录。
set_tags(**kwargs)
为当前运行记录一批标签。
参数:
-
arguments(keyword) – 要记录为标签的键值对。
delete_tags(*keys)
从运行中删除一些标签。
参数:
-
keys(series of strs of the keys) – 要删除的所有标签名称。
list_artifacts(artifact_path: str | None = None)
列出记录器的所有工件。
参数:
-
artifact_path (str) – 要存储在 URI 中的工件的相对路径。
返回类型:
一个存储的工件信息列表(名称、路径等)。
download_artifact(path: str, dst_path: str | None = None) -> str
将工件文件或目录从运行下载到本地目录(如果适用),并返回其本地路径。
参数:
-
path(str) – 目标工件的相对源路径。 -
dst_path (Optional[str]) – 用于下载指定工件的本地文件系统目标目录的绝对路径。此目录必须已存在。如果未指定,工件将下载到本地文件系统上一个新创建的、具有唯一名称的目录中。
返回:
目标工件的本地路径。
返回类型:str
list_metrics()
列出记录器的所有指标。
返回类型:
一个存储的指标字典。
list_params()
列出记录器的所有参数。
返回类型:
一个存储的参数字典。
list_tags()
列出记录器的所有标签。
返回类型:
一个存储的标签字典。
对于 save_objects、load_object 等其他接口,请参阅记录器 API。
记录模板 (Record Template)
RecordTemp类是一个能够以特定格式生成实验结果(例如 IC 和回测)的类。我们提供了三种不同的Record Template类:-
SignalRecord:此类生成模型的预测结果。
-
SigAnaRecord:此类生成模型的 IC、ICIR、Rank IC 和 Rank ICIR。
以下是 SigAnaRecord 中所做的一个简单示例,如果用户想用自己的预测和标签计算 IC、Rank IC、多空收益,可以参考:
Pythonfrom qlib.contrib.eva.alpha import calc_ic, calc_long_short_return ic, ric = calc_ic(pred.iloc[:, 0], label.iloc[:, 0]) long_short_r, long_avg_r = calc_long_short_return(pred.iloc[:, 0], label.iloc[:, 0]) -
PortAnaRecord:此类生成回测的结果。有关回测以及可用策略的详细信息,用户可以参阅策略和回测。
以下是 PortAnaRecord 中所做的一个简单示例,如果用户想基于自己的预测和标签进行回测,可以参考:
Pythonfrom qlib.contrib.strategy.strategy import TopkDropoutStrategy from qlib.contrib.evaluate import ( backtest as normal_backtest, risk_analysis, ) # backtest STRATEGY_CONFIG = { "topk": 50, "n_drop": 5, } BACKTEST_CONFIG = { "limit_threshold": 0.095, "account": 100000000, "benchmark": BENCHMARK, "deal_price": "close", "open_cost": 0.0005, "close_cost": 0.0015, "min_cost": 5, } strategy = TopkDropoutStrategy(**STRATEGY_CONFIG) report_normal, positions_normal = normal_backtest(pred_score, strategy=strategy, **BACKTEST_CONFIG) # analysis analysis = dict() analysis["excess_return_without_cost"] = risk_analysis(report_normal["return"] - report_normal["bench"]) analysis["excess_return_with_cost"] = risk_analysis(report_normal["return"] - report_normal["bench"] - report_normal["cost"]) analysis_df = pd.concat(analysis) # type: pd.DataFrame print(analysis_df)
有关 API 的更多信息,请参阅记录模板 API。
已知限制
Python 对象是基于 pickle 保存的,当转储对象和加载对象的环境不同时,可能会导致问题。
活动:0 -
-
分析:评估与结果分析
简介
分析旨在展示日内交易的图形化报告,帮助用户直观地评估和分析投资组合。以下是一些可供查看的图表:
-
analysis_position-
report_graph -
score_ic_graph -
cumulative_return_graph -
risk_analysis_graph -
rank_label_graph
-
-
analysis_model-
model_performance_graph
-
Qlib 中所有累积利润指标(例如,收益、最大回撤)都通过求和计算。这避免了指标或图表随时间呈指数级倾斜。
图形化报告
用户可以运行以下代码来获取所有支持的报告。
Python>> import qlib.contrib.report as qcr >> print(qcr.GRAPH_NAME_LIST) ['analysis_position.report_graph', 'analysis_position.score_ic_graph', 'analysis_position.cumulative_return_graph', 'analysis_position.risk_analysis_graph', 'analysis_position.rank_label_graph', 'analysis_model.model_performance_graph']注意
有关更多详细信息,请参阅函数文档:类似于 help(qcr.analysis_position.report_graph)。
用法与示例
analysis_position.report的用法API
图形结果
注意
-
X 轴:交易日
-
Y 轴:
-
cum bench:基准的累计收益系列。 -
cum return wo cost:无成本投资组合的累计收益系列。 -
cum return w cost:有成本投资组合的累计收益系列。 -
return wo mdd:无成本累计收益的最大回撤系列。 -
return w cost mdd:有成本累计收益的最大回撤系列。 -
cum ex return wo cost:无成本投资组合与基准相比的CAR(累计异常收益)系列。 -
cum ex return w cost:有成本投资组合与基准相比的CAR(累计异常收益)系列。 -
turnover:换手率系列。 -
cum ex return wo cost mdd:无成本CAR(累计异常收益)的回撤系列。 -
cum ex return w cost mdd:有成本CAR(累计异常收益)的回撤系列。
-
-
上方的阴影部分:对应于
cum return wo cost的最大回撤。 -
下方的阴影部分:对应于
cum ex return wo cost的最大回撤。
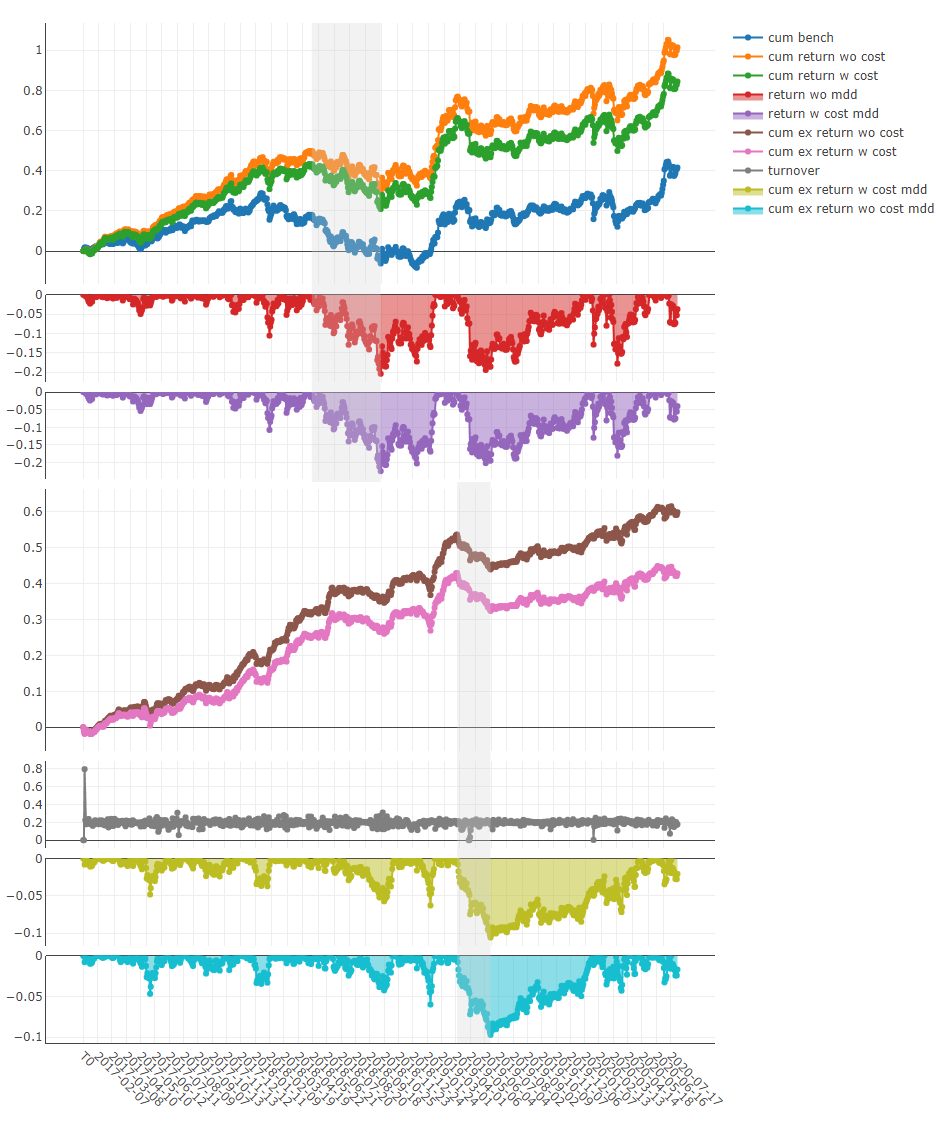
analysis_position.score_ic的用法API
图形结果
注意
-
X 轴:交易日
-
Y 轴:
-
ic:标签与预测分数之间的皮尔逊相关系数系列。在上面的示例中,标签被公式化为Ref($close, -2)/Ref($close, -1)-1。有关更多详细信息,请参阅数据特征。 -
rank_ic:标签与预测分数之间的斯皮尔曼等级相关系数系列。
-
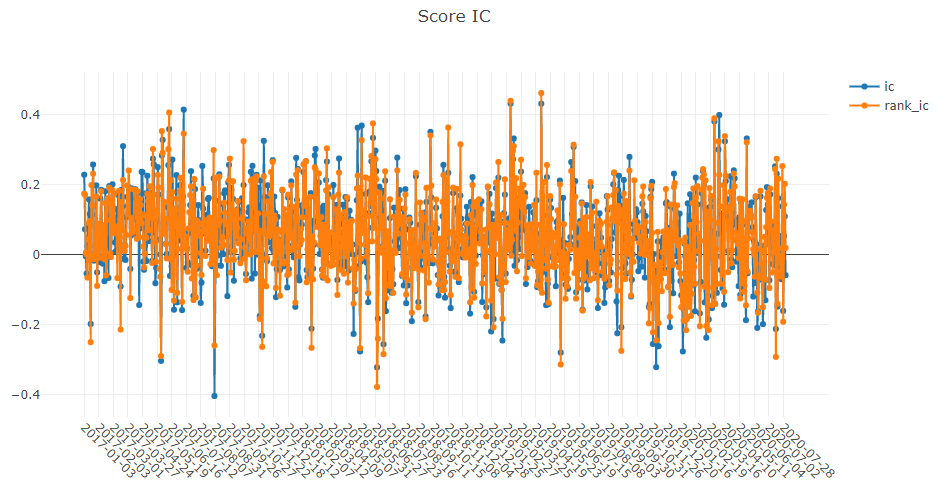
analysis_position.risk_analysis的用法API
图形结果
注意
-
总体图表
-
std-
excess_return_without_cost:无成本CAR(累计异常收益)的标准差。 -
excess_return_with_cost:有成本CAR(累计异常收益)的标准差。
-
-
annualized_return-
excess_return_without_cost:无成本CAR(累计异常收益)的年化收益率。 -
excess_return_with_cost:有成本CAR(累计异常收益)的年化收益率。
-
-
information_ratio-
excess_return_without_cost:无成本信息比率。 -
excess_return_with_cost:有成本信息比率。
要了解有关信息比率的更多信息,请参阅信息比率 – IR。
-
-
max_drawdown-
excess_return_without_cost:无成本CAR(累计异常收益)的最大回撤。 -
excess_return_with_cost:有成本 CAR(累计异常收益)的最大回撤。
-
-

注意
-
annualized_return/max_drawdown/information_ratio/std图表-
X 轴:按月分组的交易日
-
Y 轴:
-
annualized_return图表-
excess_return_without_cost_annualized_return:无成本月度CAR(累计异常收益)的年化收益率系列。 -
excess_return_with_cost_annualized_return:有成本月度CAR(累计异常收益)的年化收益率系列。
-
-
max_drawdown图表-
excess_return_without_cost_max_drawdown:无成本月度CAR(累计异常收益)的最大回撤系列。 -
excess_return_with_cost_max_drawdown:有成本月度CAR(累计异常收益)的最大回撤系列。
-
-
information_ratio图表-
excess_return_without_cost_information_ratio:无成本月度CAR(累计异常收益)的信息比率系列。 -
excess_return_with_cost_information_ratio:有成本月度CAR(累计异常收益)的信息比率系列。
-
-
std图表-
excess_return_without_cost_max_drawdown:无成本月度CAR(累计异常收益)的标准差系列。 -
excess_return_with_cost_max_drawdown:有成本月度CAR(累计异常收益)的标准差系列。
-
-
-
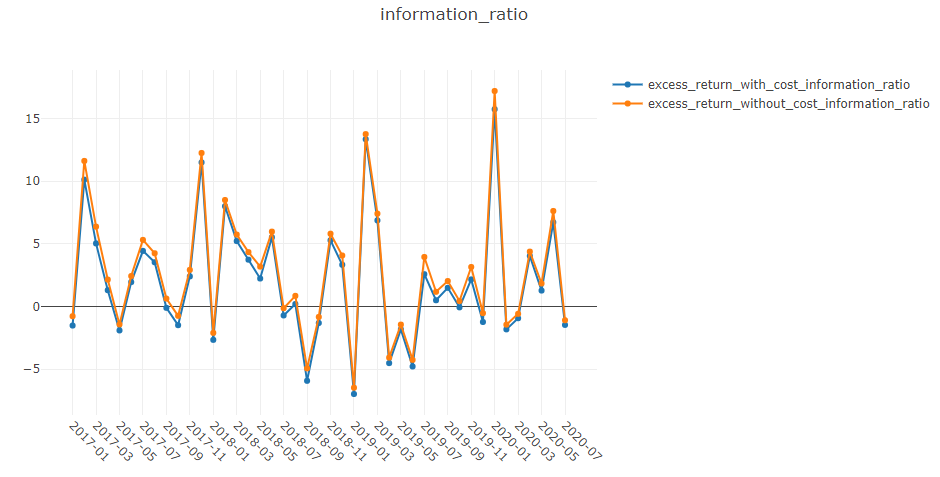
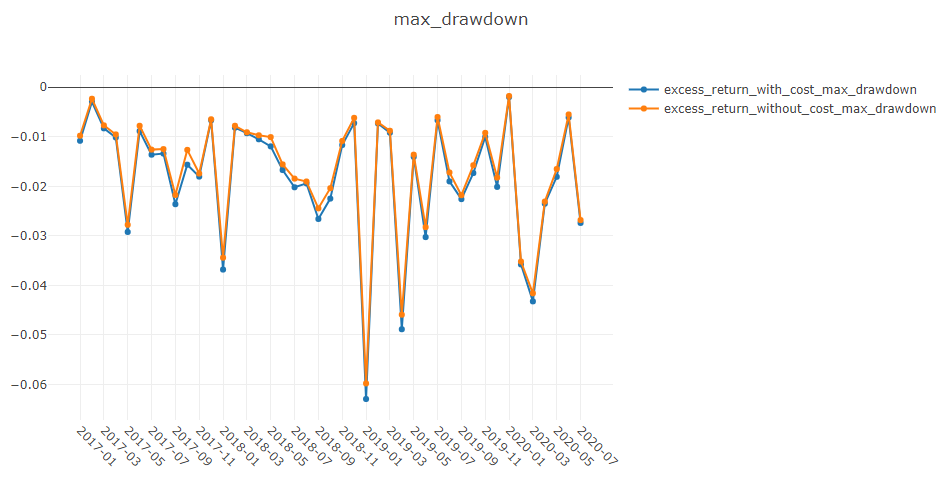
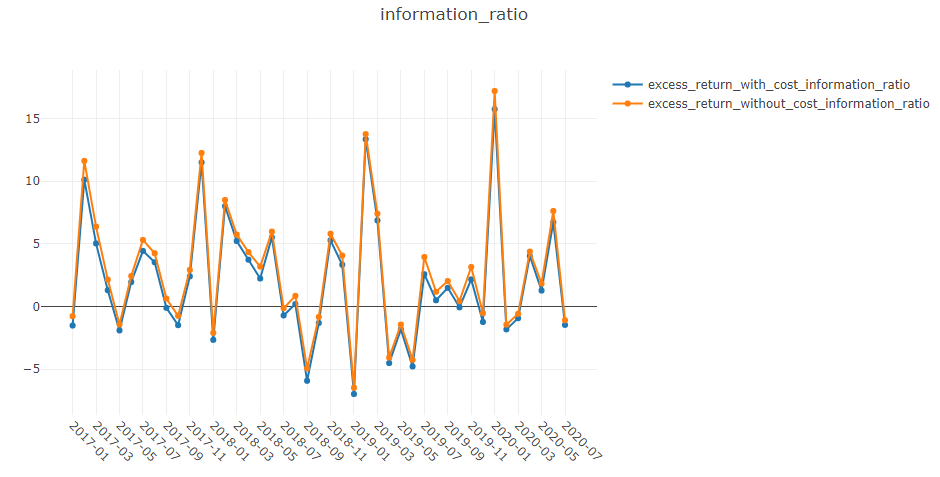
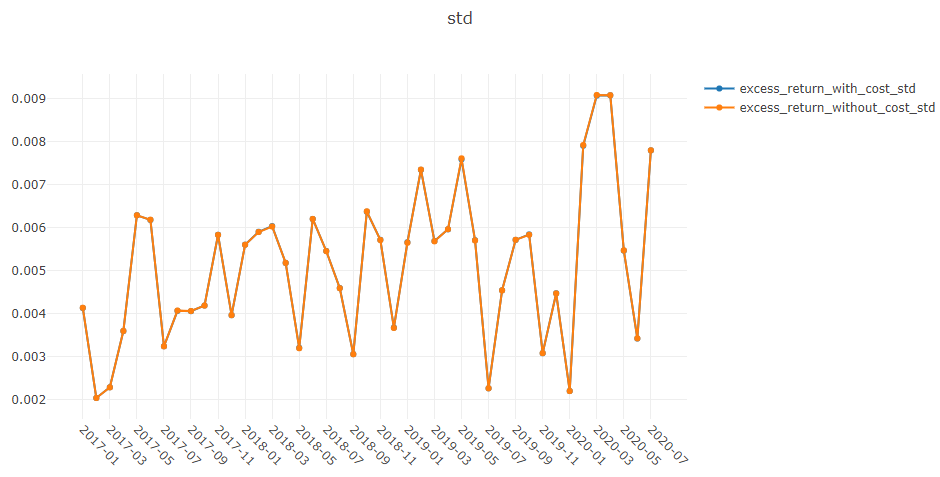
analysis_model.analysis_model_performance的用法API
图形结果
注意
-
累计收益图表
-
Group1:标签的(排名比例 <= 20%)的股票组的累计收益系列。
-
Group2:标签的(20% < 排名比例 <= 40%)的股票组的累计收益系列。
-
Group3:标签的(40% < 排名比例 <= 60%)的股票组的累计收益系列。
-
Group4:标签的(60% < 排名比例 <= 80%)的股票组的累计收益系列。
-
Group5:标签的(80% < 排名比例)的股票组的累计收益系列。
-
long-short:Group1的累计收益与Group5的累计收益之间的差异系列。 -
long-average:Group1的累计收益与所有股票的平均累计收益之间的差异系列。 -
排名比例可以公式化如下:
rankingratio=\(frac{Ascending Ranking of label}{Number of Stocks in the Portfolio}\)
-
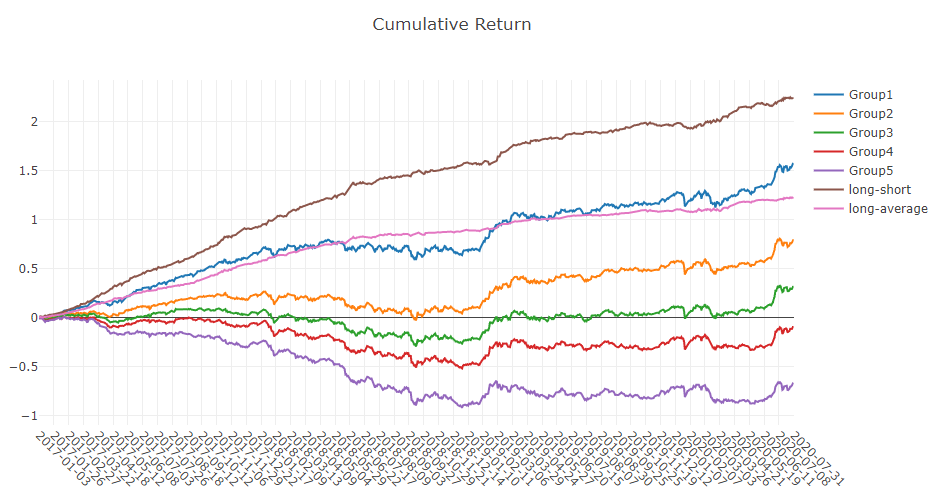
注意
-
long-short/long-average-
每天多空/多平均收益的分布。
-
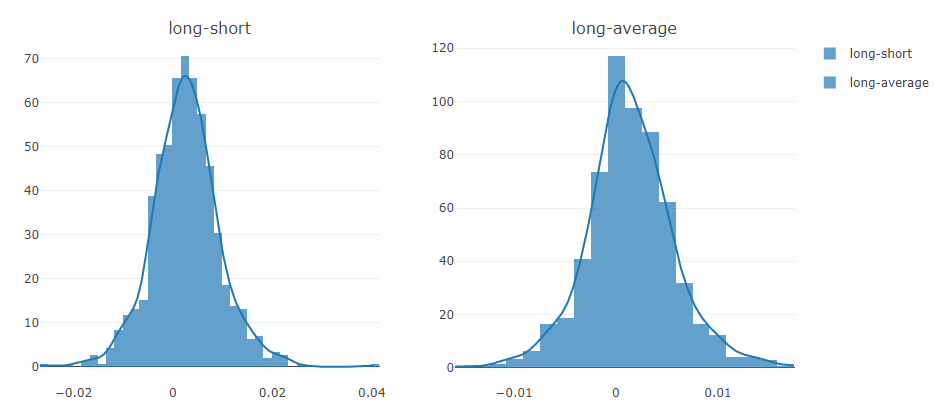
注意
-
信息系数 (Information Coefficient)
-
投资组合中股票的标签与预测分数之间的皮尔逊相关系数系列。
-
图形报告可用于评估预测分数。
-
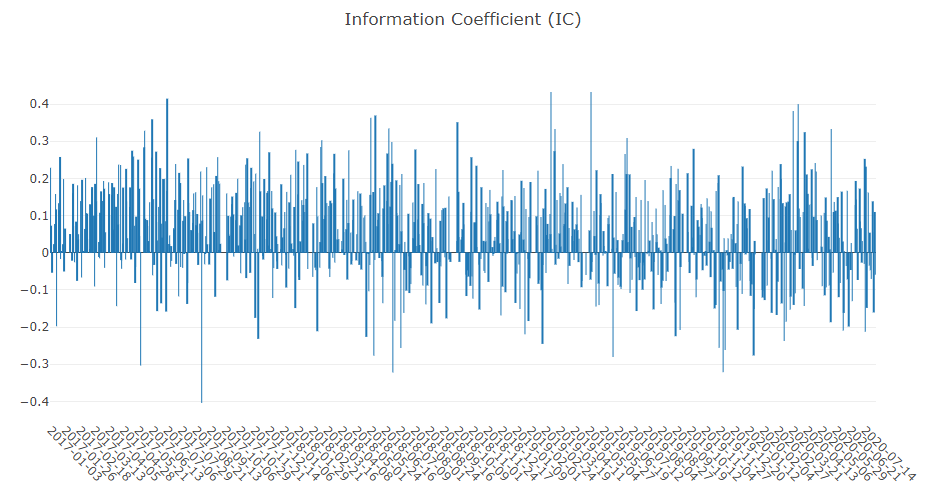
注意
-
月度 IC
-
信息系数的月度平均值。
-
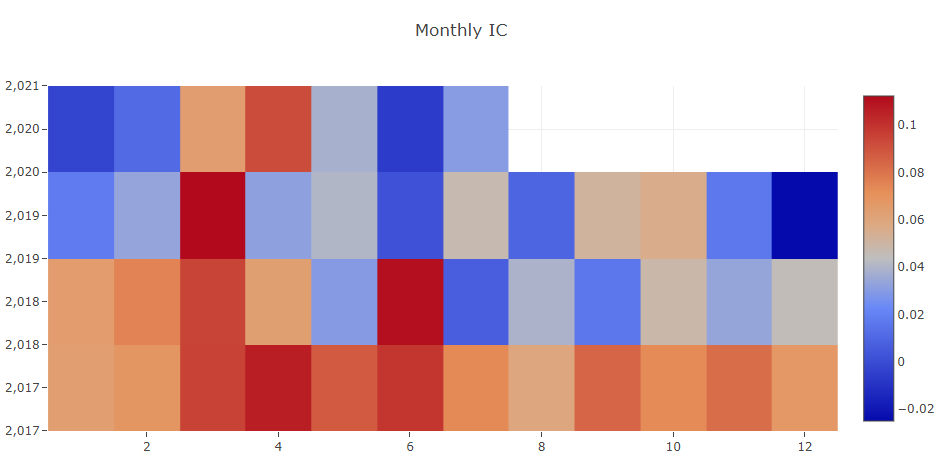
注意
-
IC
-
每天信息系数的分布。
-
-
IC Normal Dist. Q-Q
-
分位数-分位数图用于每天信息系数的正态分布。
-
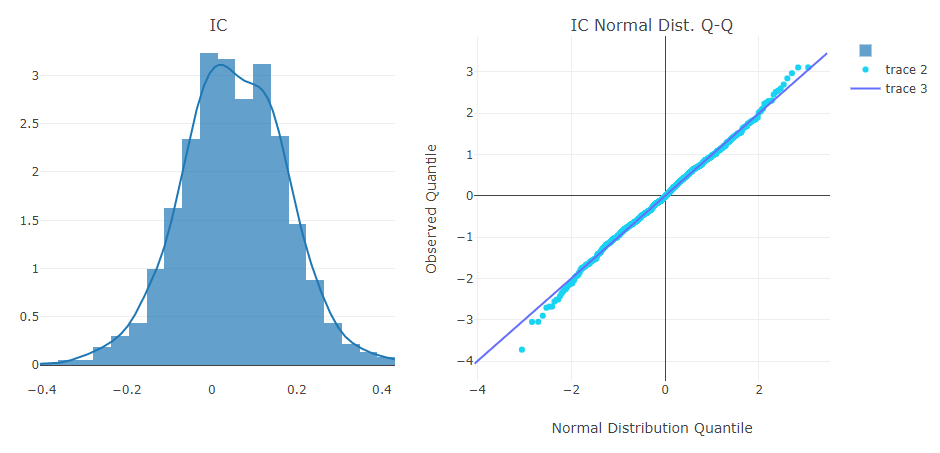
注意
-
自相关 (Auto Correlation)
-
每天投资组合中股票的最新预测分数与
lag天前的预测分数之间的皮尔逊相关系数系列。 -
图形报告可用于估计换手率。
-
 活动:0
活动:0 -
-
在线服务 (Online Serving)
简介
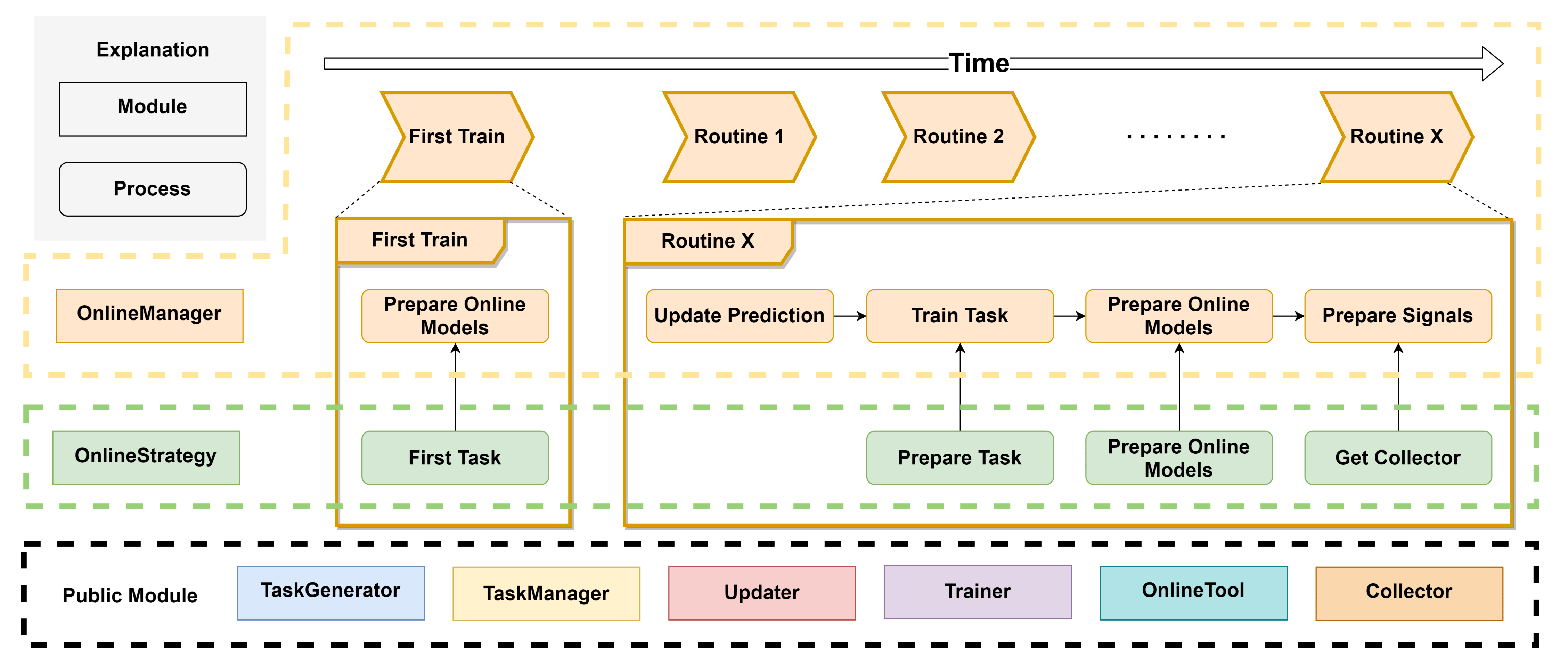
除了回测,检验模型有效性的一种方法是在真实市场条件下进行预测,甚至根据这些预测进行真实交易。在线服务是一套模块,用于使用最新数据进行在线模型预测,包括 Online Manager、Online Strategy、Online Tool 和 Updater。
此处有几个示例可供参考,它们展示了在线服务的不同功能。如果您有许多模型或任务需要管理,请考虑任务管理。这些示例基于任务管理中的一些组件,例如
TrainerRM或Collector。注意:用户应该保持其数据源更新,以支持在线服务。例如,Qlib 提供一批脚本来帮助用户更新 Yahoo 每日数据。
当前已知限制
-
目前支持下一个交易日的每日更新预测。但由于公共数据的限制,不支持为下一个交易日生成订单。
在线管理器 (Online Manager)
OnlineManager可以管理一组 Online Strategy 并动态运行它们。随着时间的变化,决定性的模型也会随之改变。在此模块中,我们将这些贡献模型称为在线模型。在每次例行程序(例如每天或每分钟)中,在线模型可能会发生变化,其预测需要更新。因此,该模块提供了一系列方法来控制此过程。
该模块还提供了一种在历史中模拟 Online Strategy 的方法。这意味着您可以验证您的策略或找到更好的策略。
在不同情况下使用不同的训练器总共有 4 种情况:
情况 描述 Online + Trainer 当您想执行真实例行程序时, Trainer将帮助您训练模型。它将逐个任务、逐个策略地训练模型。Online + DelayTrainer DelayTrainer将跳过具体的训练,直到所有任务都由不同的策略准备好。它让用户可以在routine或first_train结束时并行训练所有任务。否则,当每个策略准备任务时,这些函数会卡住。Simulation + Trainer 它的行为与 Online + Trainer 相同。唯一的区别是它用于模拟/回测而不是在线交易。 Simulation + DelayTrainer 当您的模型没有任何时间依赖性时,您可以使用 DelayTrainer来实现多任务处理。这意味着所有例行程序中的所有任务都可以在模拟结束时进行真实训练。信号将在不同的时间段(基于是否有新模型上线)准备好。以下是一些伪代码,展示了每种情况的工作流。
-
为简单起见
-
策略中只使用一个策略。
-
update_online_pred仅在在线模式下调用并被忽略。
-
Online + Trainer
Pythontasks = first_train() models = trainer.train(tasks) trainer.end_train(models) for day in online_trading_days: # OnlineManager.routine models = trainer.train(strategy.prepare_tasks()) # for each strategy strategy.prepare_online_models(models) # for each strategy trainer.end_train(models) prepare_signals() # prepare trading signals dailyOnline + DelayTrainer:工作流与Online + Trainer相同。Simulation + DelayTrainer
Python# simulate tasks = first_train() models = trainer.train(tasks) for day in historical_calendars: # OnlineManager.routine models = trainer.train(strategy.prepare_tasks()) # for each strategy strategy.prepare_online_models(models) # for each strategy # delay_prepare() # FIXME: Currently the delay_prepare is not implemented in a proper way. trainer.end_train(<for all previous models>) prepare_signals()我们能简化当前的工作流吗?
-
可以减少任务状态的数量吗?
-
对于每个任务,我们有三个阶段(即任务、部分训练的任务、最终训练的任务)。
class qlib.workflow.online.manager.OnlineManager(strategies: OnlineStrategy | List[OnlineStrategy], trainer: Trainer | None = None, begin_time: str | Timestamp | None = None, freq='day')
OnlineManager 可以通过 Online Strategy 管理在线模型。它还提供了一个历史记录,记录了在什么时间哪些模型在线。
__init__(strategies: OnlineStrategy | List[OnlineStrategy], trainer: Trainer | None = None, begin_time: str | Timestamp | None = None, freq='day')
初始化 OnlineManager。一个 OnlineManager 必须至少有一个 OnlineStrategy。
参数:
-
strategies(Union[OnlineStrategy, List[OnlineStrategy]]) –OnlineStrategy的一个实例或OnlineStrategy的一个列表。 -
begin_time(Union[str, pd.Timestamp],optional) –OnlineManager将在此时间开始。默认为None以使用最新日期。 -
trainer(qlib.model.trainer.Trainer) – 用于训练任务的训练器。None表示使用TrainerR。 -
freq(str,optional) – 数据频率。默认为“day”。
first_train(strategies: List[OnlineStrategy] | None = None, model_kwargs: dict = {})
从每个策略的 first_tasks 方法获取任务并训练它们。如果使用 DelayTrainer,它可以在每个策略的 first_tasks 之后一起完成所有训练。
参数:
-
strategies(List[OnlineStrategy]) – 策略列表(添加策略时需要此参数)。None表示使用默认策略。 -
model_kwargs(dict) –prepare_online_models的参数。
routine(cur_time: str | Timestamp | None = None, task_kwargs: dict = {}, model_kwargs: dict = {}, signal_kwargs: dict = {})
每个策略的典型更新过程并记录在线历史。
例行程序之后的典型更新过程,例如日复一日或月复一月。该过程是:更新预测 -> 准备任务 -> 准备在线模型 -> 准备信号。
如果使用 DelayTrainer,它可以在每个策略的 prepare_tasks 之后一起完成所有训练。
参数:
-
cur_time(Union[str, pd.Timestamp],optional) – 在此时间运行例行程序方法。默认为None。 -
task_kwargs(dict) –prepare_tasks的参数。 -
model_kwargs(dict) –prepare_online_models的参数。 -
signal_kwargs(dict) –prepare_signals的参数。
get_collector(**kwargs) -> MergeCollector
获取 Collector 的实例,以从每个策略收集结果。此收集器可以作为信号准备的基础。
参数:
-
**kwargs – get_collector 的参数。
返回:
用于合并其他收集器的收集器。
返回类型:MergeCollector
add_strategy(strategies: OnlineStrategy | List[OnlineStrategy])
向 OnlineManager 添加一些新策略。
参数:
-
strategy(Union[OnlineStrategy, List[OnlineStrategy]]) –OnlineStrategy的一个列表。
prepare_signals(prepare_func: ~typing.Callable = <qlib.model.ens.ensemble.AverageEnsemble object>, over_write=False)
在准备好上次例行程序的数据(箱形图中的一个框)之后,即例行程序结束时,我们可以为下一次例行程序准备交易信号。
注意:给定一组预测,所有在这些预测结束时间之前的信号都将准备好。即使最新的信号已经存在,最新的计算结果也会被覆盖。
注意
-
给定某个时间的预测,所有在此时间之前的信号都将准备好。
参数:
-
prepare_func(Callable,optional) – 从收集后的字典中获取信号。默认为AverageEnsemble(),MergeCollector收集的结果必须是{xxx:pred}。 -
over_write (bool, optional) – 如果为 True,新信号将覆盖。如果为 False,新信号将追加到信号末尾。默认为 False。
返回:
信号。
返回类型:pd.DataFrame
get_signals() -> Series | DataFrame
获取准备好的在线信号。
返回:
pd.Series 用于每个日期时间只有一个信号。pd.DataFrame 用于多个信号,例如,买入和卖出操作使用不同的交易信号。
返回类型:Union[pd.Series, pd.DataFrame]
simulate(end_time=None, frequency='day', task_kwargs={}, model_kwargs={}, signal_kwargs={}) -> Series | DataFrame
从当前时间开始,此方法将模拟 OnlineManager 中的每个例行程序,直到结束时间。
考虑到并行训练,模型和信号可以在所有例行程序模拟之后准备好。
延迟训练方式可以是 DelayTrainer,延迟准备信号方式可以是 delay_prepare。
参数:
-
end_time– 模拟将结束的时间。 -
frequency– 日历频率。 -
task_kwargs(dict) –prepare_tasks的参数。 -
model_kwargs(dict) –prepare_online_models的参数。 -
signal_kwargs (dict) – prepare_signals 的参数。
返回:
pd.Series 用于每个日期时间只有一个信号。pd.DataFrame 用于多个信号,例如,买入和卖出操作使用不同的交易信号。
返回类型:Union[pd.Series, pd.DataFrame]
delay_prepare(model_kwargs={}, signal_kwargs={})
如果某些东西正在等待准备,则准备所有模型和信号。
参数:
-
model_kwargs–end_train的参数。 -
signal_kwargs–prepare_signals的参数。
在线策略 (Online Strategy)
OnlineStrategy模块是在线服务的一个元素。class qlib.workflow.online.strategy.OnlineStrategy(name_id: str)
OnlineStrategy 与 Online Manager 协同工作,负责如何生成任务、更新模型和准备信号。
__init__(name_id: str)
初始化 OnlineStrategy。此模块必须使用 Trainer 来完成模型训练。
参数:
-
name_id(str) – 唯一的名称或 ID。 -
trainer(qlib.model.trainer.Trainer,optional) –Trainer的一个实例。默认为None。
prepare_tasks(cur_time, **kwargs) -> List[dict]
在例行程序结束之后,根据 cur_time(None 表示最新)检查我们是否需要准备和训练一些新任务。返回等待训练的新任务。
您可以通过 OnlineTool.online_models 找到上次在线的模型。
prepare_online_models(trained_models, cur_time=None) -> List[object]
从训练好的模型中选择一些模型并将其设置为在线模型。这是一个将所有训练好的模型上线的典型实现,您可以重写它以实现复杂的方法。如果您仍然需要上次在线的模型,可以通过 OnlineTool.online_models 找到它们。
注意:将所有在线模型重置为训练好的模型。如果没有训练好的模型,则什么也不做。
注意:
-
当前的实现非常简单。以下是一个更接近实际场景的更复杂情况。
-
在
test_start前一天(时间戳T)训练新模型。 -
在 test_start(通常是时间戳 T + 1)切换模型。
参数:
-
-
models(list) – 模型列表。 -
cur_time (pd.Dataframe) – 来自 OnlineManger 的当前时间。None 表示最新。
返回:
一个在线模型列表。
返回类型:List[object]
first_tasks() -> List[dict]
首先生成一系列任务并返回它们。
返回类型:List[dict]
get_collector() -> Collector
获取 Collector 的实例,以收集此策略的不同结果。
例如:
-
在
Recorder中收集预测。 -
在文本文件中收集信号。
返回:
Collector
class qlib.workflow.online.strategy.RollingStrategy(name_id: str, task_template: dict | List[dict], rolling_gen: RollingGen)
此示例策略始终使用最新的滚动模型作为在线模型。
__init__(name_id: str, task_template: dict | List[dict], rolling_gen: RollingGen)
初始化 RollingStrategy。
假设:name_id 的字符串、实验名称和训练器的实验名称相同。
参数:
-
name_id(str) – 唯一的名称或 ID。也将是实验的名称。 -
task_template(Union[dict, List[dict]]) –task_template的一个列表或单个模板,将用于使用rolling_gen生成许多任务。 -
rolling_gen(RollingGen) –RollingGen的一个实例。
get_collector(process_list=[<qlib.model.ens.group.RollingGroup object>], rec_key_func=None, rec_filter_func=None, artifacts_key=None)
获取 Collector 的实例以收集结果。返回的收集器必须区分不同模型中的结果。
假设:模型可以根据模型名称和滚动测试段进行区分。如果您不希望此假设成立,请实现您的方法或使用另一个 rec_key_func。
参数:
-
rec_key_func(Callable) – 获取记录器键的函数。如果为None,则使用记录器 ID。 -
rec_filter_func(Callable,optional) – 通过返回True或False来筛选记录器。默认为None。 -
artifacts_key(List[str],optional) – 您想要获取的工件键。如果为None,则获取所有工件。
first_tasks() -> List[dict]
使用 rolling_gen 根据 task_template 生成不同的任务。
返回:
任务列表。
返回类型:List[dict]
prepare_tasks(cur_time) -> List[dict]
根据 cur_time(None 表示最新)准备新任务。
您可以通过 OnlineToolR.online_models 找到上次在线的模型。
返回:
一个新任务列表。
返回类型:List[dict]
在线工具 (Online Tool)
OnlineTool是一个用于设置和取消设置一系列在线模型的模块。在线模型是在某些时间点具有决定性的模型,它们可以随着时间的变化而变化。这使我们能够随着市场风格的变化而使用高效的子模型。class qlib.workflow.online.utils.OnlineTool
OnlineTool 将在一个包含模型记录器的实验中管理在线模型。
__init__()
初始化 OnlineTool。
set_online_tag(tag, recorder: list | object)
为模型设置标签,以标记是否在线。
参数:
-
tag(str) –ONLINE_TAG、OFFLINE_TAG中的标签。 -
recorder(Union[list, object]) – 模型的记录器。
get_online_tag(recorder: object) -> str
给定一个模型记录器并返回其在线标签。
参数:
-
recorder (Object) – 模型的记录器。
返回:
在线标签。
返回类型:str
reset_online_tag(recorder: list | object)
将所有模型下线,并将记录器设置为“在线”。
参数:
-
recorder(Union[list, object]) – 您想要重置为“在线”的记录器。
online_models() -> list
获取当前在线模型。
返回:
一个在线模型列表。
返回类型:list
update_online_pred(to_date=None)
将在线模型的预测更新到 to_date。
参数:
-
to_date(pd.Timestamp) – 在此日期之前的预测将被更新。None表示更新到最新。
class qlib.workflow.online.utils.OnlineToolR(default_exp_name: str | None = None)
基于 (R)ecorder 的 OnlineTool 实现。
__init__(default_exp_name: str | None = None)
初始化 OnlineToolR。
参数:
-
default_exp_name(str) – 默认实验名称。
set_online_tag(tag, recorder: Recorder | List)
为模型的记录器设置标签,以标记是否在线。
参数:
-
tag(str) –ONLINE_TAG、NEXT_ONLINE_TAG、OFFLINE_TAG中的标签。 -
recorder(Union[Recorder, List]) –Recorder的一个列表或一个实例。
get_online_tag(recorder: Recorder) -> str
给定一个模型记录器并返回其在线标签。
参数:
-
recorder (Recorder) – 记录器的一个实例。
返回:
在线标签。
返回类型:str
reset_online_tag(recorder: Recorder | List, exp_name: str | None = None)
将所有模型下线,并将记录器设置为“在线”。
参数:
-
recorder(Union[Recorder, List]) – 您想要重置为“在线”的记录器。 -
exp_name(str) – 实验名称。如果为None,则使用default_exp_name。
online_models(exp_name: str | None = None) -> list
获取当前在线模型。
参数:
-
exp_name (str) – 实验名称。如果为 None,则使用 default_exp_name。
返回:
一个在线模型列表。
返回类型:list
update_online_pred(to_date=None, from_date=None, exp_name: str | None = None)
将在线模型的预测更新到 to_date。
参数:
-
to_date(pd.Timestamp) – 在此日期之前的预测将被更新。None表示更新到Calendar中的最新时间。 -
exp_name(str) – 实验名称。如果为None,则使用default_exp_name。
更新器 (Updater)
Updater是一个模块,用于在股票数据更新时更新预测等工件。class qlib.workflow.online.update.RMDLoader(rec: Recorder)
记录器模型数据集加载器。
__init__(rec: Recorder)get_dataset(start_time, end_time, segments=None, unprepared_dataset: DatasetH | None = None) -> DatasetH
加载、配置和设置数据集。
此数据集用于推理。
参数:
-
start_time– 基础数据的开始时间。 -
end_time– 基础数据的结束时间。 -
segments–dict数据集的分段配置。由于时间序列数据集 (TSDatasetH),测试段可能与start_time和end_time不同。 -
unprepared_dataset – Optional[DatasetH] 如果用户不想从记录器加载数据集,请指定用户的数据集。
返回:
DatasetH 的实例。
返回类型:DatasetH
class qlib.workflow.online.update.RecordUpdater(record: Recorder, *args, **kwargs)
更新特定的记录器。
__init__(record: Recorder, *args, **kwargs)abstract update(*args, **kwargs)
更新特定记录器的信息。
class qlib.workflow.online.update.DSBasedUpdater(record: ~qlib.workflow.recorder.Recorder, to_date=None, from_date=None, hist_ref: int | None = None, freq='day', fname='pred.pkl', loader_cls: type = <class 'qlib.workflow.online.update.RMDLoader'>)
基于数据集的更新器。
为基于 Qlib 数据集更新数据提供更新功能。
假设
-
基于 Qlib 数据集。
-
要更新的数据是多级索引的
pd.DataFrame。例如,标签、预测。
LABEL0 datetime instrument 2021-05-10 SH600000 0.006965 SH600004 0.003407 ... ... 2021-05-28 SZ300498 0.015748 SZ300676 -0.001321__init__(record: ~qlib.workflow.recorder.Recorder, to_date=None, from_date=None, hist_ref: int | None = None, freq='day', fname='pred.pkl', loader_cls: type = <class 'qlib.workflow.online.update.RMDLoader'>)
初始化 PredUpdater。
在以下情况下的预期行为:
-
如果
to_date大于日历中的最大日期,数据将更新到最新日期。 -
如果在 from_date 之前或 to_date 之后有数据,则只影响 from_date 和 to_date 之间的数据。
参数:
-
record–Recorder。 -
to_date–-
将预测更新到
to_date。 -
如果
to_date为None:数据将更新到最新日期。
-
-
from_date–-
更新将从
from_date开始。 -
如果
from_date为None:更新将发生在历史数据中最新数据之后的下一个刻度。
-
-
hist_ref–-
int有时,数据集会依赖于历史数据。将问题留给用户来设置历史依赖的长度。如果用户未指定此参数,Updater将尝试加载数据集以自动确定hist_ref。 -
注意:
start_time不包含在hist_ref中;因此在大多数情况下,hist_ref将是step_len - 1。
-
-
loader_cls–type用于加载模型和数据集的类。
prepare_data(unprepared_dataset: DatasetH | None = None) -> DatasetH
加载数据集:
-
如果指定了
unprepared_dataset,则直接准备数据集。 -
否则,...
-
分离此函数将使其更容易重用数据集。
返回:
DatasetH 的实例。
返回类型:DatasetH
update(dataset: DatasetH | None = None, write: bool = True, ret_new: bool = False) -> object | None
参数:
-
dataset(DatasetH) –DatasetH的实例。None表示再次准备它。 -
write(bool) – 是否执行写入操作。 -
ret_new (bool) – 是否返回更新后的数据。
返回:
更新后的数据集。
返回类型:Optional[object]
abstract get_update_data(dataset: Dataset) -> DataFrame
根据给定数据集返回更新后的数据。
get_update_data 和 update 之间的区别:
-
update_date只包含一些特定于数据的功能。 -
update包含一些通用的例行步骤(例如,准备数据集、检查)。
class qlib.workflow.online.update.PredUpdater(record: ~qlib.workflow.recorder.Recorder, to_date=None, from_date=None, hist_ref: int | None = None, freq='day', fname='pred.pkl', loader_cls: type = <class 'qlib.workflow.online.update.RMDLoader'>)
更新 Recorder 中的预测。
get_update_data(dataset: Dataset) -> DataFrame
根据给定数据集返回更新后的数据。
get_update_data 和 update 之间的区别:
-
update_date只包含一些特定于数据的功能。 -
update包含一些通用的例行步骤(例如,准备数据集、检查)。
class qlib.workflow.online.update.LabelUpdater(record: Recorder, to_date=None, **kwargs)
更新记录器中的标签。
假设
-
标签是从
record_temp.SignalRecord生成的。
__init__(record: Recorder, to_date=None, **kwargs)
初始化 PredUpdater。
在以下情况下的预期行为:
-
如果
to_date大于日历中的最大日期,数据将更新到最新日期。 -
如果在 from_date 之前或 to_date 之后有数据,则只影响 from_date 和 to_date 之间的数据。
参数:
-
record–Recorder。 -
to_date–-
将预测更新到
to_date。 -
如果
to_date为None:数据将更新到最新日期。
-
-
from_date–-
更新将从
from_date开始。 -
如果
from_date为None:更新将发生在历史数据中最新数据之后的下一个刻度。
-
-
hist_ref–-
int有时,数据集会依赖于历史数据。将问题留给用户来设置历史依赖的长度。如果用户未指定此参数,Updater将尝试加载数据集以自动确定hist_ref。 -
注意:
start_time不包含在hist_ref中;因此在大多数情况下,hist_ref将是step_len - 1。
-
-
loader_cls–type用于加载模型和数据集的类。
get_update_data(dataset: Dataset) -> DataFrame
根据给定数据集返回更新后的数据。
get_update_data 和 update 之间的区别:
-
update_date只包含一些特定于数据的功能。 -
update包含一些通用的例行步骤(例如,准备数据集、检查)。
活动:0 -
-
构建公式化因子 (Formulaic Alphas)
简介
在量化交易实践中,设计新颖的因子来解释和预测未来的资产回报对于策略的盈利能力至关重要。这类因子通常被称为 alpha 因子,或简称 alpha。
顾名思义,公式化因子是一种可以用公式或数学表达式表示的因子。
在 Qlib 中构建公式化因子
在 Qlib 中,用户可以轻松构建公式化因子。
示例
MACD,即平滑异同移动平均线,是一种用于股票价格技术分析的公式化因子。它旨在揭示股票价格趋势的强度、方向、动量和持续时间的变化。
MACD 可以用以下公式表示:
\(\text{DIF} = \frac{\text{EMA}(close, 12) - \text{EMA}(close,26)}{\text{CLOSE}}\)
\(\text{DEA}=\frac{\text{EMA}(\text{DIF},9)}{\text{CLOSE}}\)
\(\text{MACD}=(\text{DIF}−\text{DEA})\times 2\)
注意
-
DIF 表示异同值,即 12 日 EMA 减去 26 日 EMA。
-
DEA 表示 DIF 的 9 日 EMA。
用户可以使用 Data Handler 在 Qlib 中构建公式化因子 MACD:
注意
-
用户需要首先使用
qlib.init初始化 Qlib。请参阅初始化。
Python>> from qlib.data.dataset.loader import QlibDataLoader >> MACD_EXP = '(EMA($close, 12) - EMA($close, 26))/$close - EMA((EMA($close, 12) - EMA($close, 26))/$close, 9)/$close' >> fields = [MACD_EXP] # MACD >> names = ['MACD'] >> labels = ['Ref($close, -2)/Ref($close, -1) - 1'] # label >> label_names = ['LABEL'] >> data_loader_config = { .. <span class="hljs-string">"feature"</span>: (fields, names), .. <span class="hljs-string">"label"</span>: (labels, label_names) .. } >> data_loader = QlibDataLoader(config=data_loader_config) >> df = data_loader.load(instruments='csi300', start_time='2010-01-01', end_time='2017-12-31') >> print(df) feature label MACD LABEL datetime instrument 2010-01-04 SH600000 -0.011547 -0.019672 SH600004 0.002745 -0.014721 SH600006 0.010133 0.002911 SH600008 -0.001113 0.009818 SH600009 0.025878 -0.017758 ... ... ... 2017-12-29 SZ300124 0.007306 -0.005074 SZ300136 -0.013492 0.056352 SZ300144 -0.000966 0.011853 SZ300251 0.004383 0.021739 SZ300315 -0.030557 0.012455参考
-
要了解有关 Data Loader 的更多信息,请参阅 Data Loader。
-
要了解有关 Data API 的更多信息,请参阅 Data API。
活动:0 -
-
在线与离线模式
简介
Qlib 支持在线模式和离线模式。本文档只介绍了离线模式。
在线模式旨在解决以下问题:
-
以集中方式管理数据,用户无需管理不同版本的数据。
-
减少需要生成的缓存量。
-
使数据能够以远程方式访问。
Qlib-Server
Qlib-Server 是 Qlib 的配套服务器系统,它利用 Qlib 进行基本计算,并提供强大的服务器系统和缓存机制。通过 Qlib-Server,为 Qlib 提供的数据可以得到集中管理。有了 Qlib-Server,用户就可以使用 Qlib 的在线模式。
参考
如果用户对 Qlib-Server 和在线模式感兴趣,请参阅 Qlib-Server 项目 和 Qlib-Server 文档。
活动:0 -
-
序列化
简介
Qlib 支持将
DataHandler、DataSet、Processor和Model等的状态转储到磁盘并重新加载。可序列化类
Qlib 提供了一个基类
qlib.utils.serial.Serializable,其状态可以以pickle格式转储到磁盘或从磁盘加载。当用户转储Serializable实例的状态时,实例中名称不以_开头的属性将被保存到磁盘上。然而,用户可以使用config方法或覆盖default_dump_all属性来阻止此功能。用户还可以覆盖
pickle_backend属性来选择pickle后端。支持的值是“pickle”(默认和常用)和“dill”(转储更多内容,例如函数,更多信息在这里)。示例
Qlib 的可序列化类包括
DataHandler、DataSet、Processor和Model等,它们是qlib.utils.serial.Serializable的子类。具体来说,qlib.data.dataset.DatasetH就是其中之一。用户可以按如下方式序列化DatasetH。Python##=============转储数据集============= dataset.to_pickle(path="dataset.pkl") # dataset 是 qlib.data.dataset.DatasetH 的一个实例 ##=============重新加载数据集============= with open("dataset.pkl", "rb") as file_dataset: dataset = pickle.load(file_dataset)注意
-
只有
DatasetH的状态应该保存到磁盘上,例如用于数据归一化的一些mean和variance等。 -
重新加载
DatasetH后,用户需要重新初始化它。这意味着用户可以重置DatasetH或QlibDataHandler的一些状态,例如instruments、start_time、end_time和segments等,并根据这些状态生成新数据(数据不是状态,不应该保存到磁盘上)。
更详细的示例可以在这个链接中找到。
API
请参阅 Serializable API。
活动:0 -
-
任务管理 (Task Management)
简介
“工作流”部分介绍了如何以松散耦合的方式运行研究工作流。但当你使用 qrun 时,它只能执行一个任务。为了自动生成和执行不同的任务,任务管理提供了一个完整的流程,包括任务生成、任务存储、任务训练和任务收集。有了这个模块,用户可以在不同时期、不同损失函数甚至不同模型下自动运行他们的任务。任务生成、模型训练以及合并和收集数据的过程如下图所示。
这个完整的流程可以在在线服务中使用。
一个完整流程的示例在这里。
任务生成 (Task Generating)
一个任务由 Model、Dataset、Record 或用户添加的任何内容组成。具体的任务模板可以在任务部分查看。即使任务模板是固定的,用户也可以自定义他们的
TaskGen,通过任务模板生成不同的任务。这是 TaskGen 的基类:
class qlib.workflow.task.gen.TaskGen
生成不同任务的基类。
-
示例 1:
-
输入:一个特定的任务模板和滚动步长。
-
输出:任务的滚动版本。
-
-
示例 2:
-
输入:一个特定的任务模板和损失列表。
-
输出:一组具有不同损失的任务。
-
abstract generate(task: dict) -> List[dict]
根据任务模板生成不同的任务。
参数:
-
task (dict) – 任务模板。
返回:
一个任务列表。
返回类型:List[dict]
Qlib 提供了一个
RollingGen类,用于在不同日期段生成一个数据集的任务列表。这个类允许用户在一个实验中验证不同时期的数据对模型的影响。更多信息在这里。
任务存储 (Task Storing)
为了实现更高的效率和集群操作的可能性,任务管理将把所有任务存储在 MongoDB 中。
TaskManager可以自动获取未完成的任务,并通过错误处理管理一组任务的生命周期。使用此模块时,用户必须完成 MongoDB 的配置。用户需要提供 MongoDB URL 和数据库名称才能在初始化中使用
TaskManager,或者像这样进行声明。Pythonfrom qlib.config import CC CC["mongo"] = { "task_url" : "mongodb://localhost:27017/", # 你的 MongoDB URL "task_db_name" : "rolling_db" # 数据库名称 }class qlib.workflow.task.manage.TaskManager(task_pool: str)
这是任务由 TaskManager 创建后的样子:
JSON{ 'def': pickle 序列化的任务定义。使用 pickle 会使其更简单。 'filter': 类似 json 的数据。这用于筛选任务。 'status': 'waiting' | 'running' | 'done' 'res': pickle 序列化的任务结果。 }任务管理器假定你只会更新你获取的任务。MongoDB 的“fetch one and update”将使其数据更新安全。
这个类可以用作命令行工具。以下是几个示例。您可以使用以下命令查看 manage 模块的帮助:
-
python -m qlib.workflow.task.manage -h# 显示manage模块 CLI 的手册 -
python -m qlib.workflow.task.manage wait -h# 显示manage的wait命令手册 -
python -m qlib.workflow.task.manage -t <pool_name> wait -
python -m qlib.workflow.task.manage -t <pool_name> task_stat
注意
-
假设:MongoDB 中的数据已编码,MongoDB 之外的数据已解码。
这里有四种状态:
-
STATUS_WAITING:等待训练。 -
STATUS_RUNNING:正在训练。 -
STATUS_PART_DONE:完成了一些步骤,正在等待下一步。 -
STATUS_DONE:所有工作完成。
__init__(task_pool: str)
初始化任务管理器,请记住首先进行 MongoDB url 和数据库名称的声明。一个 TaskManager 实例服务于一个特定的任务池。此模块的静态方法服务于整个 MongoDB。
参数:
-
task_pool(str) – MongoDB 中 Collection 的名称。
static list() -> list
列出数据库的所有 Collection (task_pool)。
返回:list
replace_task(task, new_task)
使用一个新任务替换旧任务。
参数:
-
task– 旧任务。 -
new_task– 新任务。
insert_task(task)
插入一个任务。
参数:
-
task – 等待插入的任务。
返回:pymongo.results.InsertOneResult
insert_task_def(task_def)
向 task_pool 插入一个任务。
参数:
-
task_def (dict) – 任务定义。
返回类型:pymongo.results.InsertOneResult
create_task(task_def_l, dry_run=False, print_nt=False) -> List[str]
如果 task_def_l 中的任务是新的,则将新任务插入 task_pool 并记录 inserted_id。如果任务不是新的,则只查询其 _id。
参数:
-
task_def_l(list) – 一个任务列表。 -
dry_run(bool) – 是否将这些新任务插入任务池。 -
print_nt (bool) – 是否打印新任务。
返回:
task_def_l 的 _id 列表。
返回类型:List[str]
fetch_task(query={}, status='waiting') -> dict
使用 query 获取任务。
参数:
-
query(dict,optional) – 查询字典。默认为{}。 -
status (str, optional) – [描述]。默认为 STATUS_WAITING。
返回:
一个解码后的任务(collection 中的 document)。
返回类型:dict
safe_fetch_task(query={}, status='waiting')
使用 contextmanager 从 task_pool 中获取任务。
参数:
-
query (dict) – 查询字典。
返回:
一个解码后的任务(collection 中的 document)。
返回类型:dict
query(query={}, decode=True)
在 collection 中查询任务。如果迭代生成器花费太长时间,此函数可能会引发异常 pymongo.errors.CursorNotFound: cursor id not found。
-
python -m qlib.workflow.task.manage -t <your task pool> query ‘{“_id”: “615498be837d0053acbc5d58”}’
参数:
-
query(dict) – 查询字典。 -
decode (bool) –
返回:
一个解码后的任务(collection 中的 document)。
返回类型:dict
re_query(_id) -> dict
使用 _id 查询任务。
参数:
-
_id (str) – document 的 _id。
返回:
一个解码后的任务(collection 中的 document)。
返回类型:dict
commit_task_res(task, res, status='done')
将结果提交到 task['res']。
参数:
-
task([类型]) – [描述]。 -
res(object) – 您想要保存的结果。 -
status(str,optional) –STATUS_WAITING,STATUS_RUNNING,STATUS_DONE,STATUS_PART_DONE。默认为STATUS_DONE。
return_task(task, status='waiting')
将任务返回到某个状态。通常用于错误处理。
参数:
-
task([类型]) – [描述]。 -
status(str,optional) –STATUS_WAITING,STATUS_RUNNING,STATUS_DONE,STATUS_PART_DONE。默认为STATUS_WAITING。
remove(query={})
使用 query 删除任务。
参数:
-
query(dict) – 查询字典。
task_stat(query={}) -> dict
统计每个状态下的任务数。
参数:
-
query (dict, optional) – 查询字典。默认为 {}。
返回:dict
reset_waiting(query={})
将所有正在运行的任务重置为等待状态。当某些正在运行的任务意外退出时可以使用。
参数:
-
query(dict,optional) – 查询字典。默认为{}。
prioritize(task, priority: int)
为任务设置优先级。
参数:
-
task(dict) – 从数据库查询到的任务。 -
priority(int) – 目标优先级。
wait(query={})
当多进程时,主进程可能从 TaskManager 中获取不到任何东西,因为仍然有一些正在运行的任务。因此,主进程应该等待所有任务都被其他进程或机器训练好。
参数:
-
query(dict,optional) – 查询字典。默认为{}。
有关任务管理的更多信息,可以在这里找到。
任务训练 (Task Training)
在生成和存储这些任务之后,是时候运行处于
WAITING状态的任务了。Qlib 提供了一个名为run_task的方法来运行任务池中的任务,但是,用户也可以自定义任务的执行方式。获取task_func的简单方法是直接使用qlib.model.trainer.task_train。它将运行由任务定义的整个工作流,其中包括Model、Dataset和Record。qlib.workflow.task.manage.run_task(task_func: Callable, task_pool: str, query: dict = {}, force_release: bool = False, before_status: str = 'waiting', after_status: str = 'done', **kwargs)
当任务池不为空(有 WAITING 任务)时,使用 task_func 获取并运行 task_pool 中的任务。
运行此方法后,有 4 种情况(before_status -> after_status):
-
STATUS_WAITING->STATUS_DONE:使用task["def"]作为task_func参数,表示任务尚未开始。 -
STATUS_WAITING->STATUS_PART_DONE:使用task["def"]作为task_func参数。 -
STATUS_PART_DONE->STATUS_PART_DONE:使用task["res"]作为task_func参数,表示任务已开始但未完成。 -
STATUS_PART_DONE -> STATUS_DONE:使用 task["res"] 作为 task_func 参数。
参数:
-
task_func(Callable) –-
def (task_def, **kwargs) -> <res which will be committed> -
运行任务的函数。
-
-
task_pool(str) – 任务池的名称(MongoDB 中的 Collection)。 -
query(dict) – 获取任务时将使用此字典查询task_pool。 -
force_release(bool) – 程序是否强制释放资源。 -
before_status(str) –before_status中的任务将被获取和训练。可以是STATUS_WAITING、STATUS_PART_DONE。 -
after_status(str) – 训练后的任务将变为after_status。可以是STATUS_WAITING、STATUS_PART_DONE。 -
kwargs–task_func的参数。
同时,Qlib 提供了一个名为
Trainer的模块。class qlib.model.trainer.Trainer
训练器可以训练一个模型列表。有 Trainer 和 DelayTrainer,它们可以根据何时完成实际训练来区分。
__init__()train(tasks: list, *args, **kwargs) -> list
给定一个任务定义列表,开始训练并返回模型。
对于 Trainer,它在此方法中完成实际训练。对于 DelayTrainer,它仅在此方法中进行一些准备工作。
参数:
-
tasks – 任务列表。
返回:
一个模型列表。
返回类型:list
end_train(models: list, *args, **kwargs) -> list
给定一个模型列表,如果需要,在训练结束时完成一些收尾工作。模型可以是 Recorder、文本文件、数据库等。
对于 Trainer,它在此方法中进行一些收尾工作。对于 DelayTrainer,它在此方法中完成实际训练。
参数:
-
models – 模型列表。
返回:
一个模型列表。
返回类型:list
is_delay() -> bool
如果训练器将延迟完成 end_train。
返回:
如果是 DelayTrainer。
返回类型:bool
has_worker() -> bool
一些训练器有后端 worker 来支持并行训练。此方法可以告诉我们 worker 是否已启用。
返回:
如果 worker 已启用。
返回类型:bool
worker()
启动 worker。
引发:
-
NotImplementedError:如果不支持 worker。
Trainer将训练一个任务列表并返回一个模型记录器列表。Qlib 提供两种Trainer,TrainerR是最简单的方式,TrainerRM基于TaskManager帮助自动管理任务生命周期。如果你不想使用任务管理来管理任务,那么使用TrainerR来训练由TaskGen生成的任务列表就足够了。这里有关于不同Trainer的详细信息。
任务收集 (Task Collecting)
在收集模型训练结果之前,你需要使用
qlib.init指定mlruns的路径。为了在训练后收集任务的结果,Qlib 提供了
Collector、Group和Ensemble,以可读、可扩展和松散耦合的方式收集结果。-
Collector可以从任何地方收集对象并对其进行处理,例如合并、分组、求平均等。它有 2 个步骤动作,包括collect(将任何内容收集到字典中)和process_collect(处理收集到的字典)。 -
Group也有 2 个步骤,包括group(可以根据group_func对一组对象进行分组并将其更改为字典)和reduce(可以根据某些规则使字典成为一个集合)。例如:{(A,B,C1): object, (A,B,C2): object} —group—> {(A,B): {C1: object, C2: object}} —reduce—> {(A,B): object}。 -
Ensemble可以合并集合中的对象。例如:{C1: object, C2: object} —Ensemble—> object。你可以在Collector的process_list中设置你想要的集合。常见的集合包括AverageEnsemble和RollingEnsemble。AverageEnsemble用于合并同一时间段内不同模型的结果。RollingEnsemble用于合并同一时间段内不同模型的结果。
因此,层次结构是:
Collector的第二步对应于Group。而Group的第二步对应于Ensemble。欲了解更多信息,请参阅 Collector、Group 和 Ensemble,或示例。
活动:0 -
-
时间点 (Point-in-Time) 数据库
简介
在进行任何形式的历史市场分析时,时间点数据是一个非常重要的考量因素。
例如,假设我们正在回测一个交易策略,并使用过去五年的历史数据作为输入。我们的模型假设每天收盘时交易一次,我们计算回测中 2020 年 1 月 1 日的交易信号。那时,我们应该只拥有 2020 年 1 月 1 日、2019 年 12 月 31 日、2019 年 12 月 30 日等的数据。
在金融数据(尤其是财务报告)中,同一份数据可能会随着时间的推移被多次修改。如果我们在历史回测中只使用最新版本的数据,就会发生数据泄露。时间点数据库旨在解决这个问题,以确保用户在任何历史时间戳都能获取正确版本的数据。它将保持在线交易和历史回测的性能一致。
数据准备
Qlib 提供了一个爬虫来帮助用户下载金融数据,然后是一个转换器将数据转储为 Qlib 格式。请按照
scripts/data_collector/pit/README.md下载和转换数据。此外,您还可以在那里找到一些额外的用法示例。PIT 数据的基于文件的设计
Qlib 为 PIT 数据提供了一种基于文件的存储方式。
对于每个特征,它包含 4 列,即 date、period、value 和 _next。每一行对应一个声明。
文件名类似
XXX_a.data的每个特征的含义:-
date:声明的发布日期。
-
period:声明所属的时期。(例如,在大多数市场中,这将是季度频率)
-
如果是年度,它将是一个对应年份的整数。
-
如果是季度,它将是一个类似
<year><index of quarter>的整数。最后两位小数表示季度索引。其他位表示年份。
-
-
value:描述的值。
-
_next:下一个字段出现的字节索引。
除了特征数据,还包含一个索引文件
XXX_a.index以加快查询性能。声明按 date 升序排列,从文件的开头开始。
# XXXX.data 的数据格式 array([(20070428, 200701, 0.090219 , 4294967295), (20070817, 200702, 0.13933 , 4294967295), (20071023, 200703, 0.24586301, 4294967295), (20080301, 200704, 0.3479 , 80), (20080313, 200704, 0.395989 , 4294967295), (20080422, 200801, 0.100724 , 4294967295), (20080828, 200802, 0.24996801, 4294967295), (20081027, 200803, 0.33412001, 4294967295), (20090325, 200804, 0.39011699, 4294967295), (20090421, 200901, 0.102675 , 4294967295), (20090807, 200902, 0.230712 , 4294967295), (20091024, 200903, 0.30072999, 4294967295), (20100402, 200904, 0.33546099, 4294967295), (20100426, 201001, 0.083825 , 4294967295), (20100812, 201002, 0.200545 , 4294967295), (20101029, 201003, 0.260986 , 4294967295), (20110321, 201004, 0.30739301, 4294967295), (20110423, 201101, 0.097411 , 4294967295), (20110831, 201102, 0.24825101, 4294967295), (20111018, 201103, 0.318919 , 4294967295), (20120323, 201104, 0.4039 , 420), (20120411, 201104, 0.403925 , 4294967295), (20120426, 201201, 0.112148 , 4294967295), (20120810, 201202, 0.26484701, 4294967295), (20121026, 201203, 0.370487 , 4294967295), (20130329, 201204, 0.45004699, 4294967295), (20130418, 201301, 0.099958 , 4294967295), (20130831, 201302, 0.21044201, 4294967295), (20131016, 201303, 0.30454299, 4294967295), (20140325, 201304, 0.394328 , 4294967295), (20140425, 201401, 0.083217 , 4294967295), (20140829, 201402, 0.16450299, 4294967295), (20141030, 201403, 0.23408499, 4294967295), (20150421, 201404, 0.319612 , 4294967295), (20150421, 201501, 0.078494 , 4294967295), (20150828, 201502, 0.137504 , 4294967295), (20151023, 201503, 0.201709 , 4294967295), (20160324, 201504, 0.26420501, 4294967295), (20160421, 201601, 0.073664 , 4294967295), (20160827, 201602, 0.136576 , 4294967295), (20161029, 201603, 0.188062 , 4294967295), (20170415, 201604, 0.244385 , 4294967295), (20170425, 201701, 0.080614 , 4294967295), (20170728, 201702, 0.15151 , 4294967295), (20171026, 201703, 0.25416601, 4294967295), (20180328, 201704, 0.32954201, 4294967295), (20180428, 201801, 0.088887 , 4294967295), (20180802, 201802, 0.170563 , 4294967295), (20181029, 201803, 0.25522 , 4294967295), (20190329, 201804, 0.34464401, 4294967295), (20190425, 201901, 0.094737 , 4294967295), (20190713, 201902, 0. , 1040), (20190718, 201902, 0.175322 , 4294967295), (20191016, 201903, 0.25581899, 4294967295)], dtype=[('date', '<u4'), ('period', '<u4'), ('value', '<f8'), ('_next', '<u4')]) # - 每行包含 20 字节 # XXXX.index 的数据格式。它由两部分组成 # 1) 数据的起始索引。所以信息的第一部分会像 2007 # 2) 剩余的索引数据会像下面的信息 # - 数据指示一个周期内第一次数据更新的**字节索引**。 # - 例如:因为字节 80 和 100 处的信息都对应 200704,所以记录了第一次出现的字节索引(即 100)。 array([ 0, 20, 40, 60, 100, 120, 140, 160, 180, 200, 220, 240, 260, 280, 300, 320, 340, 360, 380, 400, 440, 460, 480, 500, 520, 540, 560, 580, 600, 620, 640, 660, 680, 700, 720, 740, 760, 780, 800, 820, 840, 860, 880, 900, 920, 940, 960, 0, 1020, 1060, 4294967295], dtype=uint32)已知限制:
-
目前,PIT 数据库是为季度或年度因子设计的,可以处理大多数市场中财务报告的基本数据。
-
Qlib 利用文件名来识别数据类型。名称类似
XXX_q.data的文件对应于季度数据。名称类似XXX_a.data的文件对应于年度数据。 -
PIT 的计算并非以最佳方式执行。PIT 数据计算的性能有很大的提升潜力。
活动:0 -
-
代码规范
文档字符串 (Docstring)
请使用 Numpydoc 风格。
持续集成 (Continuous Integration)
持续集成 (CI) 工具通过在每次你提交新 commit 时运行测试并向拉取请求 (PR) 报告结果,来帮助你遵循质量标准。
当你提交 PR 请求时,你可以在网页底部的“检查”部分查看你的代码是否通过了 CI 测试。
Qlib 会使用 black 检查代码格式。如果你的代码不符合 Qlib 的标准(例如,一个常见错误是空格和制表符混用),PR 将会报错。
你可以通过在命令行中输入以下代码来修复错误:
Shellpip install black python -m black . -l 120Qlib 会使用 pylint 检查你的代码风格。检查命令在 github action workflow 中实现。有时 pylint 的限制并不那么合理。你可以像这样忽略特定的错误:
return -ICLoss()(pred, target, index) # pylint: disable=E1130
Qlib 会使用 flake8 检查你的代码风格。检查命令在 github action workflow 中实现。
你可以通过在命令行中输入以下代码来修复错误:
flake8 --ignore E501,F541,E402,F401,W503,E741,E266,E203,E302,E731,E262,F523,F821,F811,F841,E713,E265,W291,E712,E722,W293 qlib
Qlib 集成了 pre-commit,这将使开发者更容易格式化他们的代码。
只需运行以下两个命令,当执行 git commit 命令时,代码将使用 black 和 flake8 自动格式化。
Shellpip install -e .[dev] pre-commit install开发指南
作为一名开发者,你经常会想对 Qlib 进行修改,并希望这些修改能直接反映在你的环境中,而无需重新安装。你可以使用以下命令以可编辑模式安装 Qlib。[dev] 选项将帮助你在开发 Qlib 时安装一些相关的包(例如 pytest, sphinx)。
pip install -e ".[dev]"
活动:0 -
构建 Docker 镜像
Dockerfile
项目的根目录下有一个
Dockerfile文件,你可以用它来构建 Docker 镜像。Dockerfile中有两种构建方法可供选择。执行构建命令时,使用--build-arg参数来控制镜像版本。--build-arg参数默认值为yes,用于构建 Qlib 镜像的 stable 版本。-
对于 stable 版本,使用
pip install pyqlib来构建 Qlib 镜像。Shelldocker build --build-arg IS_STABLE=yes -t <image name> -f ./Dockerfile . # 或者使用默认值 docker build -t <image name> -f ./Dockerfile . -
对于 nightly 版本,使用当前源代码来构建 Qlib 镜像。
Shelldocker build --build-arg IS_STABLE=no -t <image name> -f ./Dockerfile .
Qlib 镜像的自动构建
项目的根目录下有一个
build_docker_image.sh文件,可用于自动构建 Docker 镜像并将其上传到你的 Docker Hub 仓库(可选,需要配置)。Shellsh build_docker_image.sh >>> Do you want to build the nightly version of the qlib image? (default is stable) (yes/no): >>> Is it uploaded to docker hub? (default is no) (yes/no):如果你想将构建的镜像上传到你的 Docker Hub 仓库,你需要先编辑
build_docker_image.sh文件,在文件中填写docker_user,然后执行此文件。如何使用 Qlib 镜像
启动一个新的 Docker 容器
Shelldocker run -it --name <container name> -v <Mounted local directory>:/app <image name>此时你已进入 Docker 环境,可以运行 Qlib 脚本了。例如:
Shell>>> python scripts/get_data.py qlib_data --name qlib_data_simple --target_dir ~/.qlib/qlib_data/cn_data --interval 1d --region cn >>> python qlib/workflow/cli.py examples/benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml退出容器
Shell>>> exit重启容器
Shelldocker start -i -a <container name>停止容器
Shelldocker stop -i -a <container name>删除容器
Shelldocker rm <container name>有关使用 Docker 的更多信息,请参阅 Docker 文档。
活动:0 -
-
API Reference
Here you can find all
Qlibinterfaces.Data
Provider
- classqlib.data.data.ProviderBackendMixin
-
This helper class tries to make the provider based on storage backend more convenient It is not necessary to inherent this class if that provider don’t rely on the backend storage
- classqlib.data.data.CalendarProvider
-
Calendar provider base class
Provide calendar data.
- calendar(start_time=None, end_time=None, freq='day', future=False)
-
Get calendar of certain market in given time range.
- Parameters:
-
-
start_time (str) – start of the time range.
-
end_time (str) – end of the time range.
-
freq (str) – time frequency, available: year/quarter/month/week/day.
-
future (bool) – whether including future trading day.
-
- Returns:
-
calendar list
- Return type:
-
list
- locate_index(start_time: Timestamp | str, end_time: Timestamp | str, freq: str, future: bool = False)
-
Locate the start time index and end time index in a calendar under certain frequency.
- Parameters:
-
-
start_time (pd.Timestamp) – start of the time range.
-
end_time (pd.Timestamp) – end of the time range.
-
freq (str) – time frequency, available: year/quarter/month/week/day.
-
future (bool) – whether including future trading day.
-
- Returns:
-
-
pd.Timestamp – the real start time.
-
pd.Timestamp – the real end time.
-
int – the index of start time.
-
int – the index of end time.
-
- load_calendar(freq, future)
-
Load original calendar timestamp from file.
- Parameters:
-
-
freq (str) – frequency of read calendar file.
-
future (bool) –
-
- Returns:
-
list of timestamps
- Return type:
-
list
- classqlib.data.data.InstrumentProvider
-
Instrument provider base class
Provide instrument data.
- staticinstruments(market: List | str = 'all', filter_pipe: List | None = None)
-
Get the general config dictionary for a base market adding several dynamic filters.
- Parameters:
-
-
market (Union[List, str]) –
- str:
-
market/industry/index shortname, e.g. all/sse/szse/sse50/csi300/csi500.
- list:
-
[“ID1”, “ID2”]. A list of stocks
-
filter_pipe (list) – the list of dynamic filters.
-
- Returns:
-
-
dict (if isinstance(market, str)) – dict of stockpool config.
{market => base market name, filter_pipe => list of filters}
example :
{'market': 'csi500', 'filter_pipe': [{'filter_type': 'ExpressionDFilter', 'rule_expression': '$open<40', 'filter_start_time': None, 'filter_end_time': None, 'keep': False}, {'filter_type': 'NameDFilter', 'name_rule_re': 'SH[0-9]{4}55', 'filter_start_time': None, 'filter_end_time': None}]}
-
list (if isinstance(market, list)) – just return the original list directly. NOTE: this will make the instruments compatible with more cases. The user code will be simpler.
-
- abstractlist_instruments(instruments, start_time=None, end_time=None, freq='day', as_list=False)
-
List the instruments based on a certain stockpool config.
- Parameters:
-
-
instruments (dict) – stockpool config.
-
start_time (str) – start of the time range.
-
end_time (str) – end of the time range.
-
as_list (bool) – return instruments as list or dict.
-
- Returns:
-
instruments list or dictionary with time spans
- Return type:
-
dict or list
- classqlib.data.data.FeatureProvider
-
Feature provider class
Provide feature data.
- abstractfeature(instrument, field, start_time, end_time, freq)
-
Get feature data.
- Parameters:
-
-
instrument (str) – a certain instrument.
-
field (str) – a certain field of feature.
-
start_time (str) – start of the time range.
-
end_time (str) – end of the time range.
-
freq (str) – time frequency, available: year/quarter/month/week/day.
-
- Returns:
-
data of a certain feature
- Return type:
-
pd.Series
- classqlib.data.data.PITProvider
-
- abstractperiod_feature(instrument, field, start_index: int, end_index: int, cur_time: Timestamp, period: int | None = None) Series
-
get the historical periods data series between start_index and end_index
- Parameters:
-
-
start_index (int) – start_index is a relative index to the latest period to cur_time
-
end_index (int) – end_index is a relative index to the latest period to cur_time in most cases, the start_index and end_index will be a non-positive values For example, start_index == -3 end_index == 0 and current period index is cur_idx, then the data between [start_index + cur_idx, end_index + cur_idx] will be retrieved.
-
period (int) – This is used for query specific period. The period is represented with int in Qlib. (e.g. 202001 may represent the first quarter in 2020) NOTE: period will override start_index and end_index
-
- Returns:
-
The index will be integers to indicate the periods of the data An typical examples will be TODO
- Return type:
-
pd.Series
- Raises:
-
FileNotFoundError – This exception will be raised if the queried data do not exist.
- classqlib.data.data.ExpressionProvider
-
Expression provider class
Provide Expression data.
- __init__()
- abstractexpression(instrument, field, start_time=None, end_time=None, freq='day') Series
-
Get Expression data.
The responsibility of expression - parse the field and load the according data. - When loading the data, it should handle the time dependency of the data. get_expression_instance is commonly used in this method
- Parameters:
-
-
instrument (str) – a certain instrument.
-
field (str) – a certain field of feature.
-
start_time (str) – start of the time range.
-
end_time (str) – end of the time range.
-
freq (str) – time frequency, available: year/quarter/month/week/day.
-
- Returns:
-
data of a certain expression
The data has two types of format
-
expression with datetime index
-
expression with integer index
-
because the datetime is not as good as
-
-
- Return type:
-
pd.Series
- classqlib.data.data.DatasetProvider
-
Dataset provider class
Provide Dataset data.
- abstractdataset(instruments, fields, start_time=None, end_time=None, freq='day', inst_processors=[])
-
Get dataset data.
- Parameters:
-
-
instruments (list or dict) – list/dict of instruments or dict of stockpool config.
-
fields (list) – list of feature instances.
-
start_time (str) – start of the time range.
-
end_time (str) – end of the time range.
-
freq (str) – time frequency.
-
inst_processors (Iterable[Union[dict, InstProcessor]]) – the operations performed on each instrument
-
- Returns:
-
a pandas dataframe with <instrument, datetime> index.
- Return type:
-
pd.DataFrame
- staticget_instruments_d(instruments, freq)
-
Parse different types of input instruments to output instruments_d Wrong format of input instruments will lead to exception.
- staticget_column_names(fields)
-
Get column names from input fields
- staticdataset_processor(instruments_d, column_names, start_time, end_time, freq, inst_processors=[])
-
Load and process the data, return the data set. - default using multi-kernel method.
- staticinst_calculator(inst, start_time, end_time, freq, column_names, spans=None, g_config=None, inst_processors=[])
-
Calculate the expressions for one instrument, return a df result. If the expression has been calculated before, load from cache.
return value: A data frame with index ‘datetime’ and other data columns.
- classqlib.data.data.LocalCalendarProvider(remote=False, backend={})
-
Local calendar data provider class
Provide calendar data from local data source.
- __init__(remote=False, backend={})
- load_calendar(freq, future)
-
Load original calendar timestamp from file.
- Parameters:
-
-
freq (str) – frequency of read calendar file.
-
future (bool) –
-
- Returns:
-
list of timestamps
- Return type:
-
list
- classqlib.data.data.LocalInstrumentProvider(backend={})
-
Local instrument data provider class
Provide instrument data from local data source.
- __init__(backend={}) None
- list_instruments(instruments, start_time=None, end_time=None, freq='day', as_list=False)
-
List the instruments based on a certain stockpool config.
- Parameters:
-
-
instruments (dict) – stockpool config.
-
start_time (str) – start of the time range.
-
end_time (str) – end of the time range.
-
as_list (bool) – return instruments as list or dict.
-
- Returns:
-
instruments list or dictionary with time spans
- Return type:
-
dict or list
- classqlib.data.data.LocalFeatureProvider(remote=False, backend={})
-
Local feature data provider class
Provide feature data from local data source.
- __init__(remote=False, backend={})
- feature(instrument, field, start_index, end_index, freq)
-
Get feature data.
- Parameters:
-
-
instrument (str) – a certain instrument.
-
field (str) – a certain field of feature.
-
start_time (str) – start of the time range.
-
end_time (str) – end of the time range.
-
freq (str) – time frequency, available: year/quarter/month/week/day.
-
- Returns:
-
data of a certain feature
- Return type:
-
pd.Series
- classqlib.data.data.LocalPITProvider
-
- period_feature(instrument, field, start_index, end_index, cur_time, period=None)
-
get the historical periods data series between start_index and end_index
- Parameters:
-
-
start_index (int) – start_index is a relative index to the latest period to cur_time
-
end_index (int) – end_index is a relative index to the latest period to cur_time in most cases, the start_index and end_index will be a non-positive values For example, start_index == -3 end_index == 0 and current period index is cur_idx, then the data between [start_index + cur_idx, end_index + cur_idx] will be retrieved.
-
period (int) – This is used for query specific period. The period is represented with int in Qlib. (e.g. 202001 may represent the first quarter in 2020) NOTE: period will override start_index and end_index
-
- Returns:
-
The index will be integers to indicate the periods of the data An typical examples will be TODO
- Return type:
-
pd.Series
- Raises:
-
FileNotFoundError – This exception will be raised if the queried data do not exist.
- classqlib.data.data.LocalExpressionProvider(time2idx=True)
-
Local expression data provider class
Provide expression data from local data source.
- __init__(time2idx=True)
- expression(instrument, field, start_time=None, end_time=None, freq='day')
-
Get Expression data.
The responsibility of expression - parse the field and load the according data. - When loading the data, it should handle the time dependency of the data. get_expression_instance is commonly used in this method
- Parameters:
-
-
instrument (str) – a certain instrument.
-
field (str) – a certain field of feature.
-
start_time (str) – start of the time range.
-
end_time (str) – end of the time range.
-
freq (str) – time frequency, available: year/quarter/month/week/day.
-
- Returns:
-
data of a certain expression
The data has two types of format
-
expression with datetime index
-
expression with integer index
-
because the datetime is not as good as
-
-
- Return type:
-
pd.Series
- classqlib.data.data.LocalDatasetProvider(align_time: bool = True)
-
Local dataset data provider class
Provide dataset data from local data source.
- __init__(align_time: bool = True)
-
- Parameters:
-
align_time (bool) –
Will we align the time to calendar the frequency is flexible in some dataset and can’t be aligned. For the data with fixed frequency with a shared calendar, the align data to the calendar will provides following benefits
-
Align queries to the same parameters, so the cache can be shared.
-
- dataset(instruments, fields, start_time=None, end_time=None, freq='day', inst_processors=[])
-
Get dataset data.
- Parameters:
-
-
instruments (list or dict) – list/dict of instruments or dict of stockpool config.
-
fields (list) – list of feature instances.
-
start_time (str) – start of the time range.
-
end_time (str) – end of the time range.
-
freq (str) – time frequency.
-
inst_processors (Iterable[Union[dict, InstProcessor]]) – the operations performed on each instrument
-
- Returns:
-
a pandas dataframe with <instrument, datetime> index.
- Return type:
-
pd.DataFrame
- staticmulti_cache_walker(instruments, fields, start_time=None, end_time=None, freq='day')
-
This method is used to prepare the expression cache for the client. Then the client will load the data from expression cache by itself.
- staticcache_walker(inst, start_time, end_time, freq, column_names)
-
If the expressions of one instrument haven’t been calculated before, calculate it and write it into expression cache.
- classqlib.data.data.ClientCalendarProvider
-
Client calendar data provider class
Provide calendar data by requesting data from server as a client.
- __init__()
- calendar(start_time=None, end_time=None, freq='day', future=False)
-
Get calendar of certain market in given time range.
- Parameters:
-
-
start_time (str) – start of the time range.
-
end_time (str) – end of the time range.
-
freq (str) – time frequency, available: year/quarter/month/week/day.
-
future (bool) – whether including future trading day.
-
- Returns:
-
calendar list
- Return type:
-
list
- classqlib.data.data.ClientInstrumentProvider
-
Client instrument data provider class
Provide instrument data by requesting data from server as a client.
- __init__()
- list_instruments(instruments, start_time=None, end_time=None, freq='day', as_list=False)
-
List the instruments based on a certain stockpool config.
- Parameters:
-
-
instruments (dict) – stockpool config.
-
start_time (str) – start of the time range.
-
end_time (str) – end of the time range.
-
as_list (bool) – return instruments as list or dict.
-
- Returns:
-
instruments list or dictionary with time spans
- Return type:
-
dict or list
- classqlib.data.data.ClientDatasetProvider
-
Client dataset data provider class
Provide dataset data by requesting data from server as a client.
- __init__()
- dataset(instruments, fields, start_time=None, end_time=None, freq='day', disk_cache=0, return_uri=False, inst_processors=[])
-
Get dataset data.
- Parameters:
-
-
instruments (list or dict) – list/dict of instruments or dict of stockpool config.
-
fields (list) – list of feature instances.
-
start_time (str) – start of the time range.
-
end_time (str) – end of the time range.
-
freq (str) – time frequency.
-
inst_processors (Iterable[Union[dict, InstProcessor]]) – the operations performed on each instrument
-
- Returns:
-
a pandas dataframe with <instrument, datetime> index.
- Return type:
-
pd.DataFrame
- classqlib.data.data.BaseProvider
-
Local provider class It is a set of interface that allow users to access data. Because PITD is not exposed publicly to users, so it is not included in the interface.
To keep compatible with old qlib provider.
- features(instruments, fields, start_time=None, end_time=None, freq='day', disk_cache=None, inst_processors=[])
-
- Parameters:
-
disk_cache (int) – whether to skip(0)/use(1)/replace(2) disk_cache
This function will try to use cache method which has a keyword disk_cache, and will use provider method if a type error is raised because the DatasetD instance is a provider class.
- classqlib.data.data.LocalProvider
-
- features_uri(instruments, fields, start_time, end_time, freq, disk_cache=1)
-
Return the uri of the generated cache of features/dataset
- Parameters:
-
-
disk_cache –
-
instruments –
-
fields –
-
start_time –
-
end_time –
-
freq –
-
- classqlib.data.data.ClientProvider
-
Client Provider
Requesting data from server as a client. Can propose requests:
-
Calendar : Directly respond a list of calendars
-
Instruments (without filter): Directly respond a list/dict of instruments
-
Instruments (with filters): Respond a list/dict of instruments
-
Features : Respond a cache uri
The general workflow is described as follows: When the user use client provider to propose a request, the client provider will connect the server and send the request. The client will start to wait for the response. The response will be made instantly indicating whether the cache is available. The waiting procedure will terminate only when the client get the response saying feature_available is true. BUG : Everytime we make request for certain data we need to connect to the server, wait for the response and disconnect from it. We can’t make a sequence of requests within one connection. You can refer to https://python-socketio.readthedocs.io/en/latest/client.html for documentation of python-socketIO client.
- __init__()
-
- qlib.data.data.CalendarProviderWrapper
-
alias of
CalendarProvider
- qlib.data.data.InstrumentProviderWrapper
-
alias of
InstrumentProvider
- qlib.data.data.FeatureProviderWrapper
-
alias of
FeatureProvider
- qlib.data.data.PITProviderWrapper
-
alias of
PITProvider
- qlib.data.data.ExpressionProviderWrapper
-
alias of
ExpressionProvider
- qlib.data.data.DatasetProviderWrapper
-
alias of
DatasetProvider
- qlib.data.data.BaseProviderWrapper
-
alias of
BaseProvider
- qlib.data.data.register_all_wrappers(C)
Filter
- classqlib.data.filter.BaseDFilter
-
Dynamic Instruments Filter Abstract class
Users can override this class to construct their own filter
Override __init__ to input filter regulations
Override filter_main to use the regulations to filter instruments
- __init__()
- staticfrom_config(config)
-
Construct an instance from config dict.
- Parameters:
-
config (dict) – dict of config parameters.
- abstractto_config()
-
Construct an instance from config dict.
- Returns:
-
return the dict of config parameters.
- Return type:
-
dict
- classqlib.data.filter.SeriesDFilter(fstart_time=None, fend_time=None, keep=False)
-
Dynamic Instruments Filter Abstract class to filter a series of certain features
Filters should provide parameters:
-
filter start time
-
filter end time
-
filter rule
Override __init__ to assign a certain rule to filter the series.
Override _getFilterSeries to use the rule to filter the series and get a dict of {inst => series}, or override filter_main for more advanced series filter rule
- __init__(fstart_time=None, fend_time=None, keep=False)
-
- Init function for filter base class.
-
Filter a set of instruments based on a certain rule within a certain period assigned by fstart_time and fend_time.
- Parameters:
-
-
fstart_time (str) – the time for the filter rule to start filter the instruments.
-
fend_time (str) – the time for the filter rule to stop filter the instruments.
-
keep (bool) – whether to keep the instruments of which features don’t exist in the filter time span.
-
- filter_main(instruments, start_time=None, end_time=None)
-
Implement this method to filter the instruments.
- Parameters:
-
-
instruments (dict) – input instruments to be filtered.
-
start_time (str) – start of the time range.
-
end_time (str) – end of the time range.
-
- Returns:
-
filtered instruments, same structure as input instruments.
- Return type:
-
dict
-
- classqlib.data.filter.NameDFilter(name_rule_re, fstart_time=None, fend_time=None)
-
Name dynamic instrument filter
Filter the instruments based on a regulated name format.
A name rule regular expression is required.
- __init__(name_rule_re, fstart_time=None, fend_time=None)
-
Init function for name filter class
- Parameters:
-
name_rule_re (str) – regular expression for the name rule.
- staticfrom_config(config)
-
Construct an instance from config dict.
- Parameters:
-
config (dict) – dict of config parameters.
- to_config()
-
Construct an instance from config dict.
- Returns:
-
return the dict of config parameters.
- Return type:
-
dict
- classqlib.data.filter.ExpressionDFilter(rule_expression, fstart_time=None, fend_time=None, keep=False)
-
Expression dynamic instrument filter
Filter the instruments based on a certain expression.
An expression rule indicating a certain feature field is required.
Examples
-
basic features filter : rule_expression = ‘$close/$open>5’
-
cross-sectional features filter : rule_expression = ‘$rank($close)<10’
-
time-sequence features filter : rule_expression = ‘$Ref($close, 3)>100’
- __init__(rule_expression, fstart_time=None, fend_time=None, keep=False)
-
Init function for expression filter class
- Parameters:
-
-
fstart_time (str) – filter the feature starting from this time.
-
fend_time (str) – filter the feature ending by this time.
-
rule_expression (str) – an input expression for the rule.
-
- staticfrom_config(config)
-
Construct an instance from config dict.
- Parameters:
-
config (dict) – dict of config parameters.
- to_config()
-
Construct an instance from config dict.
- Returns:
-
return the dict of config parameters.
- Return type:
-
dict
-
Class
- classqlib.data.base.Expression
-
Expression base class
Expression is designed to handle the calculation of data with the format below data with two dimension for each instrument,
-
feature
-
time: it could be observation time or period time.
-
period time is designed for Point-in-time database. For example, the period time maybe 2014Q4, its value can observed for multiple times(different value may be observed at different time due to amendment).
-
- load(instrument, start_index, end_index, *args)
-
load feature This function is responsible for loading feature/expression based on the expression engine.
The concrete implementation will be separated into two parts:
-
caching data, handle errors.
-
This part is shared by all the expressions and implemented in Expression
-
-
processing and calculating data based on the specific expression.
-
This part is different in each expression and implemented in each expression
-
Expression Engine is shared by different data. Different data will have different extra information for args.
- Parameters:
-
-
instrument (str) – instrument code.
-
start_index (str) – feature start index [in calendar].
-
end_index (str) – feature end index [in calendar].
-
information (*args may contain following) –
-
data (2) if is used in PIT) –
- freq: str
-
feature frequency.
-
arguments (it contains following) –
- freq: str
-
feature frequency.
-
data –
- cur_pit:
-
it is designed for the point-in-time data.
- period: int
-
This is used for query specific period. The period is represented with int in Qlib. (e.g. 202001 may represent the first quarter in 2020)
-
arguments –
- cur_pit:
-
it is designed for the point-in-time data.
- period: int
-
This is used for query specific period. The period is represented with int in Qlib. (e.g. 202001 may represent the first quarter in 2020)
-
- Returns:
-
feature series: The index of the series is the calendar index
- Return type:
-
pd.Series
-
- abstractget_longest_back_rolling()
-
Get the longest length of historical data the feature has accessed
This is designed for getting the needed range of the data to calculate the features in specific range at first. However, situations like Ref(Ref($close, -1), 1) can not be handled rightly.
So this will only used for detecting the length of historical data needed.
- abstractget_extended_window_size()
-
get_extend_window_size
For to calculate this Operator in range[start_index, end_index] We have to get the leaf feature in range[start_index - lft_etd, end_index + rght_etd].
- Returns:
-
lft_etd, rght_etd
- Return type:
-
(int, int)
-
- classqlib.data.base.Feature(name=None)
-
Static Expression
This kind of feature will load data from provider
- __init__(name=None)
- get_longest_back_rolling()
-
Get the longest length of historical data the feature has accessed
This is designed for getting the needed range of the data to calculate the features in specific range at first. However, situations like Ref(Ref($close, -1), 1) can not be handled rightly.
So this will only used for detecting the length of historical data needed.
- get_extended_window_size()
-
get_extend_window_size
For to calculate this Operator in range[start_index, end_index] We have to get the leaf feature in range[start_index - lft_etd, end_index + rght_etd].
- Returns:
-
lft_etd, rght_etd
- Return type:
-
(int, int)
- classqlib.data.base.PFeature(name=None)
- classqlib.data.base.ExpressionOps
-
Operator Expression
This kind of feature will use operator for feature construction on the fly.
Operator
- classqlib.data.ops.ElemOperator(feature)
-
Element-wise Operator
- Parameters:
-
feature (Expression) – feature instance
- Returns:
-
feature operation output
- Return type:
- __init__(feature)
- get_longest_back_rolling()
-
Get the longest length of historical data the feature has accessed
This is designed for getting the needed range of the data to calculate the features in specific range at first. However, situations like Ref(Ref($close, -1), 1) can not be handled rightly.
So this will only used for detecting the length of historical data needed.
- get_extended_window_size()
-
get_extend_window_size
For to calculate this Operator in range[start_index, end_index] We have to get the leaf feature in range[start_index - lft_etd, end_index + rght_etd].
- Returns:
-
lft_etd, rght_etd
- Return type:
-
(int, int)
- classqlib.data.ops.ChangeInstrument(instrument, feature)
-
Change Instrument Operator In some case, one may want to change to another instrument when calculating, for example, to calculate beta of a stock with respect to a market index. This would require changing the calculation of features from the stock (original instrument) to the index (reference instrument) :param instrument: i.e., SH000300 (CSI300 index), or ^GPSC (SP500 index). :type instrument: new instrument for which the downstream operations should be performed upon. :param feature: :type feature: the feature to be calculated for the new instrument.
- Returns:
-
feature operation output
- Return type:
- __init__(instrument, feature)
- load(instrument, start_index, end_index, *args)
-
load feature This function is responsible for loading feature/expression based on the expression engine.
The concrete implementation will be separated into two parts:
-
caching data, handle errors.
-
This part is shared by all the expressions and implemented in Expression
-
-
processing and calculating data based on the specific expression.
-
This part is different in each expression and implemented in each expression
-
Expression Engine is shared by different data. Different data will have different extra information for args.
- Parameters:
-
-
instrument (str) – instrument code.
-
start_index (str) – feature start index [in calendar].
-
end_index (str) – feature end index [in calendar].
-
information (*args may contain following) –
-
data (2) if is used in PIT) –
- freq: str
-
feature frequency.
-
arguments (it contains following) –
- freq: str
-
feature frequency.
-
data –
- cur_pit:
-
it is designed for the point-in-time data.
- period: int
-
This is used for query specific period. The period is represented with int in Qlib. (e.g. 202001 may represent the first quarter in 2020)
-
arguments –
- cur_pit:
-
it is designed for the point-in-time data.
- period: int
-
This is used for query specific period. The period is represented with int in Qlib. (e.g. 202001 may represent the first quarter in 2020)
-
- Returns:
-
feature series: The index of the series is the calendar index
- Return type:
-
pd.Series
-
- classqlib.data.ops.NpElemOperator(feature, func)
-
Numpy Element-wise Operator
- Parameters:
-
-
feature (Expression) – feature instance
-
func (str) – numpy feature operation method
-
- Returns:
-
feature operation output
- Return type:
- __init__(feature, func)
- classqlib.data.ops.Abs(feature)
-
Feature Absolute Value
- Parameters:
-
feature (Expression) – feature instance
- Returns:
-
a feature instance with absolute output
- Return type:
- __init__(feature)
- classqlib.data.ops.Sign(feature)
-
Feature Sign
- Parameters:
-
feature (Expression) – feature instance
- Returns:
-
a feature instance with sign
- Return type:
- __init__(feature)
- classqlib.data.ops.Log(feature)
-
Feature Log
- Parameters:
-
feature (Expression) – feature instance
- Returns:
-
a feature instance with log
- Return type:
- __init__(feature)
- classqlib.data.ops.Mask(feature, instrument)
-
Feature Mask
- Parameters:
-
-
feature (Expression) – feature instance
-
instrument (str) – instrument mask
-
- Returns:
-
a feature instance with masked instrument
- Return type:
- __init__(feature, instrument)
- classqlib.data.ops.Not(feature)
-
Not Operator
- Parameters:
-
feature (Expression) – feature instance
- Returns:
-
feature elementwise not output
- Return type:
- __init__(feature)
- classqlib.data.ops.PairOperator(feature_left, feature_right)
-
Pair-wise operator
- Parameters:
-
-
feature_left (Expression) – feature instance or numeric value
-
feature_right (Expression) – feature instance or numeric value
-
- Returns:
-
two features’ operation output
- Return type:
- __init__(feature_left, feature_right)
- get_longest_back_rolling()
-
Get the longest length of historical data the feature has accessed
This is designed for getting the needed range of the data to calculate the features in specific range at first. However, situations like Ref(Ref($close, -1), 1) can not be handled rightly.
So this will only used for detecting the length of historical data needed.
- get_extended_window_size()
-
get_extend_window_size
For to calculate this Operator in range[start_index, end_index] We have to get the leaf feature in range[start_index - lft_etd, end_index + rght_etd].
- Returns:
-
lft_etd, rght_etd
- Return type:
-
(int, int)
- classqlib.data.ops.NpPairOperator(feature_left, feature_right, func)
-
Numpy Pair-wise operator
- Parameters:
-
-
feature_left (Expression) – feature instance or numeric value
-
feature_right (Expression) – feature instance or numeric value
-
func (str) – operator function
-
- Returns:
-
two features’ operation output
- Return type:
- __init__(feature_left, feature_right, func)
- classqlib.data.ops.Power(feature_left, feature_right)
-
Power Operator
- Parameters:
-
-
feature_left (Expression) – feature instance
-
feature_right (Expression) – feature instance
-
- Returns:
-
The bases in feature_left raised to the exponents in feature_right
- Return type:
- __init__(feature_left, feature_right)
- classqlib.data.ops.Add(feature_left, feature_right)
-
Add Operator
- Parameters:
-
-
feature_left (Expression) – feature instance
-
feature_right (Expression) – feature instance
-
- Returns:
-
two features’ sum
- Return type:
- __init__(feature_left, feature_right)
- classqlib.data.ops.Sub(feature_left, feature_right)
-
Subtract Operator
- Parameters:
-
-
feature_left (Expression) – feature instance
-
feature_right (Expression) – feature instance
-
- Returns:
-
two features’ subtraction
- Return type:
- __init__(feature_left, feature_right)
- classqlib.data.ops.Mul(feature_left, feature_right)
-
Multiply Operator
- Parameters:
-
-
feature_left (Expression) – feature instance
-
feature_right (Expression) – feature instance
-
- Returns:
-
two features’ product
- Return type:
- __init__(feature_left, feature_right)
- classqlib.data.ops.Div(feature_left, feature_right)
-
Division Operator
- Parameters:
-
-
feature_left (Expression) – feature instance
-
feature_right (Expression) – feature instance
-
- Returns:
-
two features’ division
- Return type:
- __init__(feature_left, feature_right)
- classqlib.data.ops.Greater(feature_left, feature_right)
-
Greater Operator
- Parameters:
-
-
feature_left (Expression) – feature instance
-
feature_right (Expression) – feature instance
-
- Returns:
-
greater elements taken from the input two features
- Return type:
- __init__(feature_left, feature_right)
- classqlib.data.ops.Less(feature_left, feature_right)
-
Less Operator
- Parameters:
-
-
feature_left (Expression) – feature instance
-
feature_right (Expression) – feature instance
-
- Returns:
-
smaller elements taken from the input two features
- Return type:
- __init__(feature_left, feature_right)
- classqlib.data.ops.Gt(feature_left, feature_right)
-
Greater Than Operator
- Parameters:
-
-
feature_left (Expression) – feature instance
-
feature_right (Expression) – feature instance
-
- Returns:
-
bool series indicate left > right
- Return type:
- __init__(feature_left, feature_right)
- classqlib.data.ops.Ge(feature_left, feature_right)
-
Greater Equal Than Operator
- Parameters:
-
-
feature_left (Expression) – feature instance
-
feature_right (Expression) – feature instance
-
- Returns:
-
bool series indicate left >= right
- Return type:
- __init__(feature_left, feature_right)
- classqlib.data.ops.Lt(feature_left, feature_right)
-
Less Than Operator
- Parameters:
-
-
feature_left (Expression) – feature instance
-
feature_right (Expression) – feature instance
-
- Returns:
-
bool series indicate left < right
- Return type:
- __init__(feature_left, feature_right)
- classqlib.data.ops.Le(feature_left, feature_right)
-
Less Equal Than Operator
- Parameters:
-
-
feature_left (Expression) – feature instance
-
feature_right (Expression) – feature instance
-
- Returns:
-
bool series indicate left <= right
- Return type:
- __init__(feature_left, feature_right)
- classqlib.data.ops.Eq(feature_left, feature_right)
-
Equal Operator
- Parameters:
-
-
feature_left (Expression) – feature instance
-
feature_right (Expression) – feature instance
-
- Returns:
-
bool series indicate left == right
- Return type:
- __init__(feature_left, feature_right)
- classqlib.data.ops.Ne(feature_left, feature_right)
-
Not Equal Operator
- Parameters:
-
-
feature_left (Expression) – feature instance
-
feature_right (Expression) – feature instance
-
- Returns:
-
bool series indicate left != right
- Return type:
- __init__(feature_left, feature_right)
- classqlib.data.ops.And(feature_left, feature_right)
-
And Operator
- Parameters:
-
-
feature_left (Expression) – feature instance
-
feature_right (Expression) – feature instance
-
- Returns:
-
two features’ row by row & output
- Return type:
- __init__(feature_left, feature_right)
- classqlib.data.ops.Or(feature_left, feature_right)
-
Or Operator
- Parameters:
-
-
feature_left (Expression) – feature instance
-
feature_right (Expression) – feature instance
-
- Returns:
-
two features’ row by row | outputs
- Return type:
- __init__(feature_left, feature_right)
- classqlib.data.ops.If(condition, feature_left, feature_right)
-
If Operator
- Parameters:
-
-
condition (Expression) – feature instance with bool values as condition
-
feature_left (Expression) – feature instance
-
feature_right (Expression) – feature instance
-
- __init__(condition, feature_left, feature_right)
- get_longest_back_rolling()
-
Get the longest length of historical data the feature has accessed
This is designed for getting the needed range of the data to calculate the features in specific range at first. However, situations like Ref(Ref($close, -1), 1) can not be handled rightly.
So this will only used for detecting the length of historical data needed.
- get_extended_window_size()
-
get_extend_window_size
For to calculate this Operator in range[start_index, end_index] We have to get the leaf feature in range[start_index - lft_etd, end_index + rght_etd].
- Returns:
-
lft_etd, rght_etd
- Return type:
-
(int, int)
- classqlib.data.ops.Rolling(feature, N, func)
-
Rolling Operator The meaning of rolling and expanding is the same in pandas. When the window is set to 0, the behaviour of the operator should follow expanding Otherwise, it follows rolling
- Parameters:
-
-
feature (Expression) – feature instance
-
N (int) – rolling window size
-
func (str) – rolling method
-
- Returns:
-
rolling outputs
- Return type:
- __init__(feature, N, func)
- get_longest_back_rolling()
-
Get the longest length of historical data the feature has accessed
This is designed for getting the needed range of the data to calculate the features in specific range at first. However, situations like Ref(Ref($close, -1), 1) can not be handled rightly.
So this will only used for detecting the length of historical data needed.
- get_extended_window_size()
-
get_extend_window_size
For to calculate this Operator in range[start_index, end_index] We have to get the leaf feature in range[start_index - lft_etd, end_index + rght_etd].
- Returns:
-
lft_etd, rght_etd
- Return type:
-
(int, int)
- classqlib.data.ops.Ref(feature, N)
-
Feature Reference
- Parameters:
-
-
feature (Expression) – feature instance
-
N (int) – N = 0, retrieve the first data; N > 0, retrieve data of N periods ago; N < 0, future data
-
- Returns:
-
a feature instance with target reference
- Return type:
- __init__(feature, N)
- get_longest_back_rolling()
-
Get the longest length of historical data the feature has accessed
This is designed for getting the needed range of the data to calculate the features in specific range at first. However, situations like Ref(Ref($close, -1), 1) can not be handled rightly.
So this will only used for detecting the length of historical data needed.
- get_extended_window_size()
-
get_extend_window_size
For to calculate this Operator in range[start_index, end_index] We have to get the leaf feature in range[start_index - lft_etd, end_index + rght_etd].
- Returns:
-
lft_etd, rght_etd
- Return type:
-
(int, int)
- classqlib.data.ops.Mean(feature, N)
-
Rolling Mean (MA)
- Parameters:
-
-
feature (Expression) – feature instance
-
N (int) – rolling window size
-
- Returns:
-
a feature instance with rolling average
- Return type:
- __init__(feature, N)
- classqlib.data.ops.Sum(feature, N)
-
Rolling Sum
- Parameters:
-
-
feature (Expression) – feature instance
-
N (int) – rolling window size
-
- Returns:
-
a feature instance with rolling sum
- Return type:
- __init__(feature, N)
- classqlib.data.ops.Std(feature, N)
-
Rolling Std
- Parameters:
-
-
feature (Expression) – feature instance
-
N (int) – rolling window size
-
- Returns:
-
a feature instance with rolling std
- Return type:
- __init__(feature, N)
- classqlib.data.ops.Var(feature, N)
-
Rolling Variance
- Parameters:
-
-
feature (Expression) – feature instance
-
N (int) – rolling window size
-
- Returns:
-
a feature instance with rolling variance
- Return type:
- __init__(feature, N)
- classqlib.data.ops.Skew(feature, N)
-
Rolling Skewness
- Parameters:
-
-
feature (Expression) – feature instance
-
N (int) – rolling window size
-
- Returns:
-
a feature instance with rolling skewness
- Return type:
- __init__(feature, N)
- classqlib.data.ops.Kurt(feature, N)
-
Rolling Kurtosis
- Parameters:
-
-
feature (Expression) – feature instance
-
N (int) – rolling window size
-
- Returns:
-
a feature instance with rolling kurtosis
- Return type:
- __init__(feature, N)
- classqlib.data.ops.Max(feature, N)
-
Rolling Max
- Parameters:
-
-
feature (Expression) – feature instance
-
N (int) – rolling window size
-
- Returns:
-
a feature instance with rolling max
- Return type:
- __init__(feature, N)
- classqlib.data.ops.IdxMax(feature, N)
-
Rolling Max Index
- Parameters:
-
-
feature (Expression) – feature instance
-
N (int) – rolling window size
-
- Returns:
-
a feature instance with rolling max index
- Return type:
- __init__(feature, N)
- classqlib.data.ops.Min(feature, N)
-
Rolling Min
- Parameters:
-
-
feature (Expression) – feature instance
-
N (int) – rolling window size
-
- Returns:
-
a feature instance with rolling min
- Return type:
- __init__(feature, N)
- classqlib.data.ops.IdxMin(feature, N)
-
Rolling Min Index
- Parameters:
-
-
feature (Expression) – feature instance
-
N (int) – rolling window size
-
- Returns:
-
a feature instance with rolling min index
- Return type:
- __init__(feature, N)
- classqlib.data.ops.Quantile(feature, N, qscore)
-
Rolling Quantile
- Parameters:
-
-
feature (Expression) – feature instance
-
N (int) – rolling window size
-
- Returns:
-
a feature instance with rolling quantile
- Return type:
- __init__(feature, N, qscore)
- classqlib.data.ops.Med(feature, N)
-
Rolling Median
- Parameters:
-
-
feature (Expression) – feature instance
-
N (int) – rolling window size
-
- Returns:
-
a feature instance with rolling median
- Return type:
- __init__(feature, N)
- classqlib.data.ops.Mad(feature, N)
-
Rolling Mean Absolute Deviation
- Parameters:
-
-
feature (Expression) – feature instance
-
N (int) – rolling window size
-
- Returns:
-
a feature instance with rolling mean absolute deviation
- Return type:
- __init__(feature, N)
- classqlib.data.ops.Rank(feature, N)
-
Rolling Rank (Percentile)
- Parameters:
-
-
feature (Expression) – feature instance
-
N (int) – rolling window size
-
- Returns:
-
a feature instance with rolling rank
- Return type:
- __init__(feature, N)
- classqlib.data.ops.Count(feature, N)
-
Rolling Count
- Parameters:
-
-
feature (Expression) – feature instance
-
N (int) – rolling window size
-
- Returns:
-
a feature instance with rolling count of number of non-NaN elements
- Return type:
- __init__(feature, N)
- classqlib.data.ops.Delta(feature, N)
-
Rolling Delta
- Parameters:
-
-
feature (Expression) – feature instance
-
N (int) – rolling window size
-
- Returns:
-
a feature instance with end minus start in rolling window
- Return type:
- __init__(feature, N)
- classqlib.data.ops.Slope(feature, N)
-
Rolling Slope This operator calculate the slope between idx and feature. (e.g. [<feature_t1>, <feature_t2>, <feature_t3>] and [1, 2, 3])
Usage Example: - “Slope($close, %d)/$close”
# TODO: # Some users may want pair-wise rolling like Slope(A, B, N)
- Parameters:
-
-
feature (Expression) – feature instance
-
N (int) – rolling window size
-
- Returns:
-
a feature instance with linear regression slope of given window
- Return type:
- __init__(feature, N)
- classqlib.data.ops.Rsquare(feature, N)
-
Rolling R-value Square
- Parameters:
-
-
feature (Expression) – feature instance
-
N (int) – rolling window size
-
- Returns:
-
a feature instance with linear regression r-value square of given window
- Return type:
- __init__(feature, N)
- classqlib.data.ops.Resi(feature, N)
-
Rolling Regression Residuals
- Parameters:
-
-
feature (Expression) – feature instance
-
N (int) – rolling window size
-
- Returns:
-
a feature instance with regression residuals of given window
- Return type:
- __init__(feature, N)
- classqlib.data.ops.WMA(feature, N)
-
Rolling WMA
- Parameters:
-
-
feature (Expression) – feature instance
-
N (int) – rolling window size
-
- Returns:
-
a feature instance with weighted moving average output
- Return type:
- __init__(feature, N)
- classqlib.data.ops.EMA(feature, N)
-
Rolling Exponential Mean (EMA)
- Parameters:
-
-
feature (Expression) – feature instance
-
N (int, float) – rolling window size
-
- Returns:
-
a feature instance with regression r-value square of given window
- Return type:
- __init__(feature, N)
- classqlib.data.ops.PairRolling(feature_left, feature_right, N, func)
-
Pair Rolling Operator
- Parameters:
-
-
feature_left (Expression) – feature instance
-
feature_right (Expression) – feature instance
-
N (int) – rolling window size
-
- Returns:
-
a feature instance with rolling output of two input features
- Return type:
- __init__(feature_left, feature_right, N, func)
- get_longest_back_rolling()
-
Get the longest length of historical data the feature has accessed
This is designed for getting the needed range of the data to calculate the features in specific range at first. However, situations like Ref(Ref($close, -1), 1) can not be handled rightly.
So this will only used for detecting the length of historical data needed.
- get_extended_window_size()
-
get_extend_window_size
For to calculate this Operator in range[start_index, end_index] We have to get the leaf feature in range[start_index - lft_etd, end_index + rght_etd].
- Returns:
-
lft_etd, rght_etd
- Return type:
-
(int, int)
- classqlib.data.ops.Corr(feature_left, feature_right, N)
-
Rolling Correlation
- Parameters:
-
-
feature_left (Expression) – feature instance
-
feature_right (Expression) – feature instance
-
N (int) – rolling window size
-
- Returns:
-
a feature instance with rolling correlation of two input features
- Return type:
- __init__(feature_left, feature_right, N)
- classqlib.data.ops.Cov(feature_left, feature_right, N)
-
Rolling Covariance
- Parameters:
-
-
feature_left (Expression) – feature instance
-
feature_right (Expression) – feature instance
-
N (int) – rolling window size
-
- Returns:
-
a feature instance with rolling max of two input features
- Return type:
- __init__(feature_left, feature_right, N)
- classqlib.data.ops.TResample(feature, freq, func)
-
- __init__(feature, freq, func)
-
Resampling the data to target frequency. The resample function of pandas is used.
-
the timestamp will be at the start of the time span after resample.
- Parameters:
-
-
feature (Expression) – An expression for calculating the feature
-
freq (str) – It will be passed into the resample method for resampling basedn on given frequency
-
func (method) – The method to get the resampled values Some expression are high frequently used
-
-
- classqlib.data.ops.OpsWrapper
-
Ops Wrapper
- __init__()
- register(ops_list: List[Type[ExpressionOps] | dict])
-
register operator
- Parameters:
-
ops_list (List[Union[Type[ExpressionOps], dict]]) –
-
if type(ops_list) is List[Type[ExpressionOps]], each element of ops_list represents the operator class, which should be the subclass of ExpressionOps.
-
if type(ops_list) is List[dict], each element of ops_list represents the config of operator, which has the following format:
{ "class": class_name, "module_path": path, }Note: class should be the class name of operator, module_path should be a python module or path of file.
-
- qlib.data.ops.register_all_ops(C)
-
register all operator
Cache
- classqlib.data.cache.MemCacheUnit(*args, **kwargs)
-
Memory Cache Unit.
- __init__(*args, **kwargs)
- propertylimited
-
whether memory cache is limited
- classqlib.data.cache.MemCache(mem_cache_size_limit=None, limit_type='length')
-
Memory cache.
- __init__(mem_cache_size_limit=None, limit_type='length')
-
- Parameters:
-
-
mem_cache_size_limit – cache max size.
-
limit_type – length or sizeof; length(call fun: len), size(call fun: sys.getsizeof).
-
- classqlib.data.cache.ExpressionCache(provider)
-
Expression cache mechanism base class.
This class is used to wrap expression provider with self-defined expression cache mechanism.
Note
Override the _uri and _expression method to create your own expression cache mechanism.
- expression(instrument, field, start_time, end_time, freq)
-
Get expression data.
Note
Same interface as expression method in expression provider
- update(cache_uri: str | Path, freq: str = 'day')
-
Update expression cache to latest calendar.
Override this method to define how to update expression cache corresponding to users’ own cache mechanism.
- Parameters:
-
-
cache_uri (str or Path) – the complete uri of expression cache file (include dir path).
-
freq (str) –
-
- Returns:
-
0(successful update)/ 1(no need to update)/ 2(update failure).
- Return type:
-
int
- classqlib.data.cache.DatasetCache(provider)
-
Dataset cache mechanism base class.
This class is used to wrap dataset provider with self-defined dataset cache mechanism.
Note
Override the _uri and _dataset method to create your own dataset cache mechanism.
- dataset(instruments, fields, start_time=None, end_time=None, freq='day', disk_cache=1, inst_processors=[])
-
Get feature dataset.
Note
Same interface as dataset method in dataset provider
Note
The server use redis_lock to make sure read-write conflicts will not be triggered but client readers are not considered.
- update(cache_uri: str | Path, freq: str = 'day')
-
Update dataset cache to latest calendar.
Override this method to define how to update dataset cache corresponding to users’ own cache mechanism.
- Parameters:
-
-
cache_uri (str or Path) – the complete uri of dataset cache file (include dir path).
-
freq (str) –
-
- Returns:
-
0(successful update)/ 1(no need to update)/ 2(update failure)
- Return type:
-
int
- staticcache_to_origin_data(data, fields)
-
cache data to origin data
- Parameters:
-
-
data – pd.DataFrame, cache data.
-
fields – feature fields.
-
- Returns:
-
pd.DataFrame.
- staticnormalize_uri_args(instruments, fields, freq)
-
normalize uri args
- classqlib.data.cache.DiskExpressionCache(provider, **kwargs)
-
Prepared cache mechanism for server.
- __init__(provider, **kwargs)
- gen_expression_cache(expression_data, cache_path, instrument, field, freq, last_update)
-
use bin file to save like feature-data.
- update(sid, cache_uri, freq: str = 'day')
-
Update expression cache to latest calendar.
Override this method to define how to update expression cache corresponding to users’ own cache mechanism.
- Parameters:
-
-
cache_uri (str or Path) – the complete uri of expression cache file (include dir path).
-
freq (str) –
-
- Returns:
-
0(successful update)/ 1(no need to update)/ 2(update failure).
- Return type:
-
int
- classqlib.data.cache.DiskDatasetCache(provider, **kwargs)
-
Prepared cache mechanism for server.
- __init__(provider, **kwargs)
- classmethodread_data_from_cache(cache_path: str | Path, start_time, end_time, fields)
-
read_cache_from
This function can read data from the disk cache dataset
- Parameters:
-
-
cache_path –
-
start_time –
-
end_time –
-
fields – The fields order of the dataset cache is sorted. So rearrange the columns to make it consistent.
-
- Returns:
- classIndexManager(cache_path: str | Path)
-
The lock is not considered in the class. Please consider the lock outside the code. This class is the proxy of the disk data.
- __init__(cache_path: str | Path)
- gen_dataset_cache(cache_path: str | Path, instruments, fields, freq, inst_processors=[])
-
Note
This function does not consider the cache read write lock. Please acquire the lock outside this function
The format the cache contains 3 parts(followed by typical filename).
-
index : cache/d41366901e25de3ec47297f12e2ba11d.index
-
The content of the file may be in following format(pandas.Series)
start end 1999-11-10 00:00:00 0 1 1999-11-11 00:00:00 1 2 1999-11-12 00:00:00 2 3 ...
Note
The start is closed. The end is open!!!!!
-
Each line contains two element <start_index, end_index> with a timestamp as its index.
-
It indicates the start_index (included) and end_index (excluded) of the data for timestamp
-
-
meta data: cache/d41366901e25de3ec47297f12e2ba11d.meta
-
data : cache/d41366901e25de3ec47297f12e2ba11d
-
This is a hdf file sorted by datetime
-
- Parameters:
-
-
cache_path – The path to store the cache.
-
instruments – The instruments to store the cache.
-
fields – The fields to store the cache.
-
freq – The freq to store the cache.
-
inst_processors – Instrument processors.
-
:return type pd.DataFrame; The fields of the returned DataFrame are consistent with the parameters of the function.
-
- update(cache_uri, freq: str = 'day')
-
Update dataset cache to latest calendar.
Override this method to define how to update dataset cache corresponding to users’ own cache mechanism.
- Parameters:
-
-
cache_uri (str or Path) – the complete uri of dataset cache file (include dir path).
-
freq (str) –
-
- Returns:
-
0(successful update)/ 1(no need to update)/ 2(update failure)
- Return type:
-
int
Storage
- classqlib.data.storage.storage.BaseStorage
- classqlib.data.storage.storage.CalendarStorage(freq: str, future: bool, **kwargs)
-
The behavior of CalendarStorage’s methods and List’s methods of the same name remain consistent
- __init__(freq: str, future: bool, **kwargs)
- propertydata: Iterable[str]
-
get all data
- Raises:
-
ValueError – If the data(storage) does not exist, raise ValueError
- index(value: str) int
-
- Raises:
-
ValueError – If the data(storage) does not exist, raise ValueError
- classqlib.data.storage.storage.InstrumentStorage(market: str, freq: str, **kwargs)
-
- __init__(market: str, freq: str, **kwargs)
- propertydata: Dict[str, List[Tuple[str, str]]]
-
get all data
- Raises:
-
ValueError – If the data(storage) does not exist, raise ValueError
- update([E, ]**F) None. Update D from mapping/iterable E and F.
-
Notes
If E present and has a .keys() method, does: for k in E: D[k] = E[k]
If E present and lacks .keys() method, does: for (k, v) in E: D[k] = v
In either case, this is followed by: for k, v in F.items(): D[k] = v
- classqlib.data.storage.storage.FeatureStorage(instrument: str, field: str, freq: str, **kwargs)
-
- __init__(instrument: str, field: str, freq: str, **kwargs)
- propertydata: Series
-
get all data
Notes
if data(storage) does not exist, return empty pd.Series: return pd.Series(dtype=np.float32)
- propertystart_index: int | None
-
get FeatureStorage start index
Notes
If the data(storage) does not exist, return None
- propertyend_index: int | None
-
get FeatureStorage end index
Notes
The right index of the data range (both sides are closed)
The next data appending point will be end_index + 1
If the data(storage) does not exist, return None
- write(data_array: List | ndarray | Tuple, index: int | None = None)
-
Write data_array to FeatureStorage starting from index.
Notes
If index is None, append data_array to feature.
If len(data_array) == 0; return
If (index - self.end_index) >= 1, self[end_index+1: index] will be filled with np.nan
Examples
feature: 3 4 4 5 5 6 >>> self.write([6, 7], index=6) feature: 3 4 4 5 5 6 6 6 7 7 >>> self.write([8], index=9) feature: 3 4 4 5 5 6 6 6 7 7 8 np.nan 9 8 >>> self.write([1, np.nan], index=3) feature: 3 1 4 np.nan 5 6 6 6 7 7 8 np.nan 9 8
- rebase(start_index: int | None = None, end_index: int | None = None)
-
Rebase the start_index and end_index of the FeatureStorage.
start_index and end_index are closed intervals: [start_index, end_index]
Examples
feature: 3 4 4 5 5 6 >>> self.rebase(start_index=4) feature: 4 5 5 6 >>> self.rebase(start_index=3) feature: 3 np.nan 4 5 5 6 >>> self.write([3], index=3) feature: 3 3 4 5 5 6 >>> self.rebase(end_index=4) feature: 3 3 4 5 >>> self.write([6, 7, 8], index=4) feature: 3 3 4 6 5 7 6 8 >>> self.rebase(start_index=4, end_index=5) feature: 4 6 5 7
- rewrite(data: List | ndarray | Tuple, index: int)
-
overwrite all data in FeatureStorage with data
- Parameters:
-
-
data (Union[List, np.ndarray, Tuple]) – data
-
index (int) – data start index
-
- classqlib.data.storage.file_storage.FileStorageMixin
-
FileStorageMixin, applicable to FileXXXStorage Subclasses need to have provider_uri, freq, storage_name, file_name attributes
- check()
-
check self.uri
- Raises:
-
ValueError –
- classqlib.data.storage.file_storage.FileCalendarStorage(freq: str, future: bool, provider_uri: dict | None = None, **kwargs)
-
- __init__(freq: str, future: bool, provider_uri: dict | None = None, **kwargs)
- propertydata: List[str]
-
get all data
- Raises:
-
ValueError – If the data(storage) does not exist, raise ValueError
- index(value: str) int
-
- Raises:
-
ValueError – If the data(storage) does not exist, raise ValueError
- classqlib.data.storage.file_storage.FileInstrumentStorage(market: str, freq: str, provider_uri: dict | None = None, **kwargs)
-
- __init__(market: str, freq: str, provider_uri: dict | None = None, **kwargs)
- propertydata: Dict[str, List[Tuple[str, str]]]
-
get all data
- Raises:
-
ValueError – If the data(storage) does not exist, raise ValueError
- update([E, ]**F) None. Update D from mapping/iterable E and F.
-
Notes
If E present and has a .keys() method, does: for k in E: D[k] = E[k]
If E present and lacks .keys() method, does: for (k, v) in E: D[k] = v
In either case, this is followed by: for k, v in F.items(): D[k] = v
- classqlib.data.storage.file_storage.FileFeatureStorage(instrument: str, field: str, freq: str, provider_uri: dict | None = None, **kwargs)
-
- __init__(instrument: str, field: str, freq: str, provider_uri: dict | None = None, **kwargs)
- propertydata: Series
-
get all data
Notes
if data(storage) does not exist, return empty pd.Series: return pd.Series(dtype=np.float32)
- write(data_array: List | ndarray, index: int | None = None) None
-
Write data_array to FeatureStorage starting from index.
Notes
If index is None, append data_array to feature.
If len(data_array) == 0; return
If (index - self.end_index) >= 1, self[end_index+1: index] will be filled with np.nan
Examples
feature: 3 4 4 5 5 6 >>> self.write([6, 7], index=6) feature: 3 4 4 5 5 6 6 6 7 7 >>> self.write([8], index=9) feature: 3 4 4 5 5 6 6 6 7 7 8 np.nan 9 8 >>> self.write([1, np.nan], index=3) feature: 3 1 4 np.nan 5 6 6 6 7 7 8 np.nan 9 8
- propertystart_index: int | None
-
get FeatureStorage start index
Notes
If the data(storage) does not exist, return None
- propertyend_index: int | None
-
get FeatureStorage end index
Notes
The right index of the data range (both sides are closed)
The next data appending point will be end_index + 1
If the data(storage) does not exist, return None
Dataset
Dataset Class
- classqlib.data.dataset.__init__.Dataset(**kwargs)
-
Preparing data for model training and inferencing.
- __init__(**kwargs)
-
init is designed to finish following steps:
-
- init the sub instance and the state of the dataset(info to prepare the data)
-
-
The name of essential state for preparing data should not start with ‘_’ so that it could be serialized on disk when serializing.
-
-
- setup data
-
-
The data related attributes’ names should start with ‘_’ so that it will not be saved on disk when serializing.
-
The data could specify the info to calculate the essential data for preparation
-
- config(**kwargs)
-
config is designed to configure and parameters that cannot be learned from the data
- setup_data(**kwargs)
-
Setup the data.
We split the setup_data function for following situation:
-
User have a Dataset object with learned status on disk.
-
User load the Dataset object from the disk.
-
User call setup_data to load new data.
-
User prepare data for model based on previous status.
-
- prepare(**kwargs) object
-
The type of dataset depends on the model. (It could be pd.DataFrame, pytorch.DataLoader, etc.) The parameters should specify the scope for the prepared data The method should: - process the data
-
return the processed data
- Returns:
-
return the object
- Return type:
-
object
-
- classqlib.data.dataset.__init__.DatasetH(handler: Dict | DataHandler, segments: Dict[str, Tuple], fetch_kwargs: Dict = {}, **kwargs)
-
Dataset with Data(H)andler
User should try to put the data preprocessing functions into handler. Only following data processing functions should be placed in Dataset:
-
The processing is related to specific model.
-
The processing is related to data split.
- __init__(handler: Dict | DataHandler, segments: Dict[str, Tuple], fetch_kwargs: Dict = {}, **kwargs)
-
Setup the underlying data.
- Parameters:
-
-
handler (Union[dict, DataHandler]) –
handler could be:
-
instance of DataHandler
-
config of DataHandler. Please refer to DataHandler
-
-
segments (dict) –
Describe the options to segment the data. Here are some examples:
1) 'segments': { 'train': ("2008-01-01", "2014-12-31"), 'valid': ("2017-01-01", "2020-08-01",), 'test': ("2015-01-01", "2016-12-31",), } 2) 'segments': { 'insample': ("2008-01-01", "2014-12-31"), 'outsample': ("2017-01-01", "2020-08-01",), }
-
- config(handler_kwargs: dict | None = None, **kwargs)
-
Initialize the DatasetH
- Parameters:
-
-
handler_kwargs (dict) –
Config of DataHandler, which could include the following arguments:
-
arguments of DataHandler.conf_data, such as ‘instruments’, ‘start_time’ and ‘end_time’.
-
-
kwargs (dict) –
Config of DatasetH, such as
-
- segmentsdict
-
Config of segments which is same as ‘segments’ in self.__init__
-
-
- setup_data(handler_kwargs: dict | None = None, **kwargs)
-
Setup the Data
- Parameters:
-
handler_kwargs (dict) –
init arguments of DataHandler, which could include the following arguments:
-
init_type : Init Type of Handler
-
enable_cache : whether to enable cache
-
- prepare(segments: List[str] | Tuple[str] | str | slice | Index, col_set='__all', data_key='infer', **kwargs) List[DataFrame] | DataFrame
-
Prepare the data for learning and inference.
- Parameters:
-
-
segments (Union[List[Text], Tuple[Text], Text, slice]) –
Describe the scope of the data to be prepared Here are some examples:
-
’train’
-
[‘train’, ‘valid’]
-
-
col_set (str) –
The col_set will be passed to self.handler when fetching data. TODO: make it automatic:
-
select DK_I for test data
-
select DK_L for training data.
-
-
data_key (str) – The data to fetch: DK_* Default is DK_I, which indicate fetching data for inference.
-
kwargs –
- The parameters that kwargs may contain:
-
- flt_colstr
-
It only exists in TSDatasetH, can be used to add a column of data(True or False) to filter data. This parameter is only supported when it is an instance of TSDatasetH.
-
- Return type:
-
Union[List[pd.DataFrame], pd.DataFrame]
- Raises:
-
NotImplementedError: –
-
Data Loader
- classqlib.data.dataset.loader.DataLoader
-
DataLoader is designed for loading raw data from original data source.
- abstractload(instruments, start_time=None, end_time=None) DataFrame
-
load the data as pd.DataFrame.
Example of the data (The multi-index of the columns is optional.):
feature label $close $volume Ref($close, 1) Mean($close, 3) $high-$low LABEL0 datetime instrument 2010-01-04 SH600000 81.807068 17145150.0 83.737389 83.016739 2.741058 0.0032 SH600004 13.313329 11800983.0 13.313329 13.317701 0.183632 0.0042 SH600005 37.796539 12231662.0 38.258602 37.919757 0.970325 0.0289- Parameters:
-
-
instruments (str or dict) – it can either be the market name or the config file of instruments generated by InstrumentProvider. If the value of instruments is None, it means that no filtering is done.
-
start_time (str) – start of the time range.
-
end_time (str) – end of the time range.
-
- Returns:
-
data load from the under layer source
- Return type:
-
pd.DataFrame
- Raises:
-
KeyError: – if the instruments filter is not supported, raise KeyError
- classqlib.data.dataset.loader.DLWParser(config: list | tuple | dict)
-
(D)ata(L)oader (W)ith (P)arser for features and names
Extracting this class so that QlibDataLoader and other dataloaders(such as QdbDataLoader) can share the fields.
- __init__(config: list | tuple | dict)
-
- Parameters:
-
config (Union[list, tuple, dict]) –
Config will be used to describe the fields and column names
<config> := { "group_name1": <fields_info1> "group_name2": <fields_info2> } or <config> := <fields_info> <fields_info> := ["expr", ...] | (["expr", ...], ["col_name", ...]) # NOTE: list or tuple will be treated as the things when parsing
- abstractload_group_df(instruments, exprs: list, names: list, start_time: str | Timestamp | None = None, end_time: str | Timestamp | None = None, gp_name: str | None = None) DataFrame
-
load the dataframe for specific group
- Parameters:
-
-
instruments – the instruments.
-
exprs (list) – the expressions to describe the content of the data.
-
names (list) – the name of the data.
-
- Returns:
-
the queried dataframe.
- Return type:
-
pd.DataFrame
- load(instruments=None, start_time=None, end_time=None) DataFrame
-
load the data as pd.DataFrame.
Example of the data (The multi-index of the columns is optional.):
feature label $close $volume Ref($close, 1) Mean($close, 3) $high-$low LABEL0 datetime instrument 2010-01-04 SH600000 81.807068 17145150.0 83.737389 83.016739 2.741058 0.0032 SH600004 13.313329 11800983.0 13.313329 13.317701 0.183632 0.0042 SH600005 37.796539 12231662.0 38.258602 37.919757 0.970325 0.0289- Parameters:
-
-
instruments (str or dict) – it can either be the market name or the config file of instruments generated by InstrumentProvider. If the value of instruments is None, it means that no filtering is done.
-
start_time (str) – start of the time range.
-
end_time (str) – end of the time range.
-
- Returns:
-
data load from the under layer source
- Return type:
-
pd.DataFrame
- Raises:
-
KeyError: – if the instruments filter is not supported, raise KeyError
- classqlib.data.dataset.loader.QlibDataLoader(config: Tuple[list, tuple, dict], filter_pipe: List | None = None, swap_level: bool = True, freq: str | dict = 'day', inst_processors: dict | list | None = None)
-
Same as QlibDataLoader. The fields can be define by config
- __init__(config: Tuple[list, tuple, dict], filter_pipe: List | None = None, swap_level: bool = True, freq: str | dict = 'day', inst_processors: dict | list | None = None)
-
- Parameters:
-
-
config (Tuple[list, tuple, dict]) – Please refer to the doc of DLWParser
-
filter_pipe – Filter pipe for the instruments
-
swap_level – Whether to swap level of MultiIndex
-
freq (dict or str) – If type(config) == dict and type(freq) == str, load config data using freq. If type(config) == dict and type(freq) == dict, load config[<group_name>] data using freq[<group_name>]
-
inst_processors (dict | list) – If inst_processors is not None and type(config) == dict; load config[<group_name>] data using inst_processors[<group_name>] If inst_processors is a list, then it will be applied to all groups.
-
- load_group_df(instruments, exprs: list, names: list, start_time: str | Timestamp | None = None, end_time: str | Timestamp | None = None, gp_name: str | None = None) DataFrame
-
load the dataframe for specific group
- Parameters:
-
-
instruments – the instruments.
-
exprs (list) – the expressions to describe the content of the data.
-
names (list) – the name of the data.
-
- Returns:
-
the queried dataframe.
- Return type:
-
pd.DataFrame
- classqlib.data.dataset.loader.StaticDataLoader(config: dict | str | DataFrame, join='outer')
-
DataLoader that supports loading data from file or as provided.
- __init__(config: dict | str | DataFrame, join='outer')
-
- Parameters:
-
-
config (dict) – {fields_group: <path or object>}
-
join (str) – How to align different dataframes
-
- load(instruments=None, start_time=None, end_time=None) DataFrame
-
load the data as pd.DataFrame.
Example of the data (The multi-index of the columns is optional.):
feature label $close $volume Ref($close, 1) Mean($close, 3) $high-$low LABEL0 datetime instrument 2010-01-04 SH600000 81.807068 17145150.0 83.737389 83.016739 2.741058 0.0032 SH600004 13.313329 11800983.0 13.313329 13.317701 0.183632 0.0042 SH600005 37.796539 12231662.0 38.258602 37.919757 0.970325 0.0289- Parameters:
-
-
instruments (str or dict) – it can either be the market name or the config file of instruments generated by InstrumentProvider. If the value of instruments is None, it means that no filtering is done.
-
start_time (str) – start of the time range.
-
end_time (str) – end of the time range.
-
- Returns:
-
data load from the under layer source
- Return type:
-
pd.DataFrame
- Raises:
-
KeyError: – if the instruments filter is not supported, raise KeyError
- classqlib.data.dataset.loader.NestedDataLoader(dataloader_l: List[Dict], join='left')
-
We have multiple DataLoader, we can use this class to combine them.
- __init__(dataloader_l: List[Dict], join='left') None
-
- Parameters:
-
-
dataloader_l (list[dict]) –
A list of dataloader, for exmaple
nd = NestedDataLoader( dataloader_l=[ { "class": "qlib.contrib.data.loader.Alpha158DL", }, { "class": "qlib.contrib.data.loader.Alpha360DL", "kwargs": { "config": { "label": ( ["Ref($close, -2)/Ref($close, -1) - 1"], ["LABEL0"]) } } } ] )
-
join – it will pass to pd.concat when merging it.
-
- load(instruments=None, start_time=None, end_time=None) DataFrame
-
load the data as pd.DataFrame.
Example of the data (The multi-index of the columns is optional.):
feature label $close $volume Ref($close, 1) Mean($close, 3) $high-$low LABEL0 datetime instrument 2010-01-04 SH600000 81.807068 17145150.0 83.737389 83.016739 2.741058 0.0032 SH600004 13.313329 11800983.0 13.313329 13.317701 0.183632 0.0042 SH600005 37.796539 12231662.0 38.258602 37.919757 0.970325 0.0289- Parameters:
-
-
instruments (str or dict) – it can either be the market name or the config file of instruments generated by InstrumentProvider. If the value of instruments is None, it means that no filtering is done.
-
start_time (str) – start of the time range.
-
end_time (str) – end of the time range.
-
- Returns:
-
data load from the under layer source
- Return type:
-
pd.DataFrame
- Raises:
-
KeyError: – if the instruments filter is not supported, raise KeyError
- classqlib.data.dataset.loader.DataLoaderDH(handler_config: dict, fetch_kwargs: dict = {}, is_group=False)
-
DataLoader based on (D)ata (H)andler It is designed to load multiple data from data handler - If you just want to load data from single datahandler, you can write them in single data handler
TODO: What make this module not that easy to use.
-
For online scenario
-
The underlayer data handler should be configured. But data loader doesn’t provide such interface & hook.
-
- __init__(handler_config: dict, fetch_kwargs: dict = {}, is_group=False)
-
- Parameters:
-
-
handler_config (dict) –
handler_config will be used to describe the handlers
<handler_config> := { "group_name1": <handler> "group_name2": <handler> } or <handler_config> := <handler> <handler> := DataHandler Instance | DataHandler Config
-
fetch_kwargs (dict) – fetch_kwargs will be used to describe the different arguments of fetch method, such as col_set, squeeze, data_key, etc.
-
is_group (bool) – is_group will be used to describe whether the key of handler_config is group
-
- load(instruments=None, start_time=None, end_time=None) DataFrame
-
load the data as pd.DataFrame.
Example of the data (The multi-index of the columns is optional.):
feature label $close $volume Ref($close, 1) Mean($close, 3) $high-$low LABEL0 datetime instrument 2010-01-04 SH600000 81.807068 17145150.0 83.737389 83.016739 2.741058 0.0032 SH600004 13.313329 11800983.0 13.313329 13.317701 0.183632 0.0042 SH600005 37.796539 12231662.0 38.258602 37.919757 0.970325 0.0289- Parameters:
-
-
instruments (str or dict) – it can either be the market name or the config file of instruments generated by InstrumentProvider. If the value of instruments is None, it means that no filtering is done.
-
start_time (str) – start of the time range.
-
end_time (str) – end of the time range.
-
- Returns:
-
data load from the under layer source
- Return type:
-
pd.DataFrame
- Raises:
-
KeyError: – if the instruments filter is not supported, raise KeyError
-
Data Handler
- classqlib.data.dataset.handler.DataHandler(instruments=None, start_time=None, end_time=None, data_loader: dict | str | DataLoader | None = None, init_data=True, fetch_orig=True)
-
The steps to using a handler 1. initialized data handler (call by init). 2. use the data.
The data handler try to maintain a handler with 2 level. datetime & instruments.
Any order of the index level can be supported (The order will be implied in the data). The order <datetime, instruments> will be used when the dataframe index name is missed.
Example of the data: The multi-index of the columns is optional.
feature label $close $volume Ref($close, 1) Mean($close, 3) $high-$low LABEL0 datetime instrument 2010-01-04 SH600000 81.807068 17145150.0 83.737389 83.016739 2.741058 0.0032 SH600004 13.313329 11800983.0 13.313329 13.317701 0.183632 0.0042 SH600005 37.796539 12231662.0 38.258602 37.919757 0.970325 0.0289Tips for improving the performance of datahandler - Fetching data with col_set=CS_RAW will return the raw data and may avoid pandas from copying the data when calling loc
- __init__(instruments=None, start_time=None, end_time=None, data_loader: dict | str | DataLoader | None = None, init_data=True, fetch_orig=True)
-
- Parameters:
-
-
instruments – The stock list to retrieve.
-
start_time – start_time of the original data.
-
end_time – end_time of the original data.
-
data_loader (Union[dict, str, DataLoader]) – data loader to load the data.
-
init_data – initialize the original data in the constructor.
-
fetch_orig (bool) – Return the original data instead of copy if possible.
-
- config(**kwargs)
-
configuration of data. # what data to be loaded from data source
This method will be used when loading pickled handler from dataset. The data will be initialized with different time range.
- setup_data(enable_cache: bool = False)
-
Set Up the data in case of running initialization for multiple time
It is responsible for maintaining following variable 1) self._data
- Parameters:
-
enable_cache (bool) –
default value is false:
-
if enable_cache == True:
the processed data will be saved on disk, and handler will load the cached data from the disk directly when we call init next time
-
- fetch(selector: Timestamp | slice | str | Index = slice(None, None, None), level: str | int = 'datetime', col_set: str | List[str] = '__all', squeeze: bool = False, proc_func: Callable | None = None) DataFrame
-
fetch data from underlying data source
Design motivation: - providing a unified interface for underlying data. - Potential to make the interface more friendly. - User can improve performance when fetching data in this extra layer
- Parameters:
-
-
selector (Union[pd.Timestamp, slice, str]) –
describe how to select data by index It can be categories as following
-
fetch single index
-
fetch a range of index
-
a slice range
-
pd.Index for specific indexes
-
Following conflicts may occur
-
Does [“20200101”, “20210101”] mean selecting this slice or these two days?
-
slice have higher priorities
-
-
-
level (Union[str, int]) – which index level to select the data
-
col_set (Union[str, List[str]]) –
-
if isinstance(col_set, str):
select a set of meaningful, pd.Index columns.(e.g. features, columns)
-
if col_set == CS_RAW:
the raw dataset will be returned.
-
-
if isinstance(col_set, List[str]):
select several sets of meaningful columns, the returned data has multiple levels
-
-
proc_func (Callable) –
-
Give a hook for processing data before fetching
-
An example to explain the necessity of the hook:
-
A Dataset learned some processors to process data which is related to data segmentation
-
It will apply them every time when preparing data.
-
The learned processor require the dataframe remains the same format when fitting and applying
-
However the data format will change according to the parameters.
-
So the processors should be applied to the underlayer data.
-
-
-
squeeze (bool) – whether squeeze columns and index
-
- Return type:
-
pd.DataFrame.
- get_cols(col_set='__all') list
-
get the column names
- Parameters:
-
col_set (str) – select a set of meaningful columns.(e.g. features, columns)
- Returns:
-
list of column names
- Return type:
-
list
- get_range_selector(cur_date: Timestamp | str, periods: int) slice
-
get range selector by number of periods
- Parameters:
-
-
cur_date (pd.Timestamp or str) – current date
-
periods (int) – number of periods
-
- get_range_iterator(periods: int, min_periods: int | None = None, **kwargs) Iterator[Tuple[Timestamp, DataFrame]]
-
get an iterator of sliced data with given periods
- Parameters:
-
-
periods (int) – number of periods.
-
min_periods (int) – minimum periods for sliced dataframe.
-
kwargs (dict) – will be passed to self.fetch.
-
- classqlib.data.dataset.handler.DataHandlerLP(instruments=None, start_time=None, end_time=None, data_loader: dict | str | DataLoader | None = None, infer_processors: List = [], learn_processors: List = [], shared_processors: List = [], process_type='append', drop_raw=False, **kwargs)
-
DataHandler with (L)earnable (P)rocessor
This handler will produce three pieces of data in pd.DataFrame format.
-
DK_R / self._data: the raw data loaded from the loader
-
DK_I / self._infer: the data processed for inference
-
DK_L / self._learn: the data processed for learning model.
The motivation of using different processor workflows for learning and inference Here are some examples.
-
The instrument universe for learning and inference may be different.
-
The processing of some samples may rely on label (for example, some samples hit the limit may need extra processing or be dropped).
-
These processors only apply to the learning phase.
-
Tips for data handler
-
To reduce the memory cost
-
drop_raw=True: this will modify the data inplace on raw data;
-
-
Please note processed data like self._infer or self._learn are concepts different from segments in Qlib’s Dataset like “train” and “test”
-
Processed data like self._infer or self._learn are underlying data processed with different processors
-
segments in Qlib’s Dataset like “train” and “test” are simply the time segmentations when querying data(“train” are often before “test” in time-series).
-
For example, you can query data._infer processed by infer_processors in the “train” time segmentation.
-
- __init__(instruments=None, start_time=None, end_time=None, data_loader: dict | str | DataLoader | None = None, infer_processors: List = [], learn_processors: List = [], shared_processors: List = [], process_type='append', drop_raw=False, **kwargs)
-
- Parameters:
-
-
infer_processors (list) –
-
list of <description info> of processors to generate data for inference
-
example of <description info>:
1) classname & kwargs: { "class": "MinMaxNorm", "kwargs": { "fit_start_time": "20080101", "fit_end_time": "20121231" } } 2) Only classname: "DropnaFeature" 3) object instance of Processor
-
-
learn_processors (list) – similar to infer_processors, but for generating data for learning models
-
process_type (str) –
PTYPE_I = ‘independent’
-
self._infer will be processed by infer_processors
-
self._learn will be processed by learn_processors
PTYPE_A = ‘append’
-
self._infer will be processed by infer_processors
-
self._learn will be processed by infer_processors + learn_processors
-
(e.g. self._infer processed by learn_processors )
-
-
-
drop_raw (bool) – Whether to drop the raw data
-
- fit()
-
fit data without processing the data
- fit_process_data()
-
fit and process data
The input of the fit will be the output of the previous processor
- process_data(with_fit: bool = False)
-
process_data data. Fun processor.fit if necessary
Notation: (data) [processor]
# data processing flow of self.process_type == DataHandlerLP.PTYPE_I
(self._data)-[shared_processors]-(_shared_df)-[learn_processors]-(_learn_df) \ -[infer_processors]-(_infer_df)# data processing flow of self.process_type == DataHandlerLP.PTYPE_A
(self._data)-[shared_processors]-(_shared_df)-[infer_processors]-(_infer_df)-[learn_processors]-(_learn_df)
- Parameters:
-
with_fit (bool) – The input of the fit will be the output of the previous processor
- config(processor_kwargs: dict | None = None, **kwargs)
-
configuration of data. # what data to be loaded from data source
This method will be used when loading pickled handler from dataset. The data will be initialized with different time range.
- setup_data(init_type: str = 'fit_seq', **kwargs)
-
Set up the data in case of running initialization for multiple time
- Parameters:
-
-
init_type (str) – The type IT_* listed above.
-
enable_cache (bool) –
default value is false:
-
if enable_cache == True:
the processed data will be saved on disk, and handler will load the cached data from the disk directly when we call init next time
-
-
- fetch(selector: Timestamp | slice | str = slice(None, None, None), level: str | int = 'datetime', col_set='__all', data_key: Literal['raw', 'infer', 'learn'] = 'infer', squeeze: bool = False, proc_func: Callable | None = None) DataFrame
-
fetch data from underlying data source
- Parameters:
-
-
selector (Union[pd.Timestamp, slice, str]) – describe how to select data by index.
-
level (Union[str, int]) – which index level to select the data.
-
col_set (str) – select a set of meaningful columns.(e.g. features, columns).
-
data_key (str) – the data to fetch: DK_*.
-
proc_func (Callable) – please refer to the doc of DataHandler.fetch
-
- Return type:
-
pd.DataFrame
- get_cols(col_set='__all', data_key: Literal['raw', 'infer', 'learn'] = 'infer') list
-
get the column names
- Parameters:
-
-
col_set (str) – select a set of meaningful columns.(e.g. features, columns).
-
data_key (DATA_KEY_TYPE) – the data to fetch: DK_*.
-
- Returns:
-
list of column names
- Return type:
-
list
- classmethodcast(handler: DataHandlerLP) DataHandlerLP
-
Motivation
-
A user creates a datahandler in his customized package. Then he wants to share the processed handler to other users without introduce the package dependency and complicated data processing logic.
-
This class make it possible by casting the class to DataHandlerLP and only keep the processed data
- Parameters:
-
handler (DataHandlerLP) – A subclass of DataHandlerLP
- Returns:
-
the converted processed data
- Return type:
-
- classmethodfrom_df(df: DataFrame) DataHandlerLP
-
Motivation: - When user want to get a quick data handler.
The created data handler will have only one shared Dataframe without processors. After creating the handler, user may often want to dump the handler for reuse Here is a typical use case
from qlib.data.dataset import DataHandlerLP dh = DataHandlerLP.from_df(df) dh.to_pickle(fname, dump_all=True)
TODO: - The StaticDataLoader is quite slow. It don’t have to copy the data again…
-
Processor
- qlib.data.dataset.processor.get_group_columns(df: DataFrame, group: str | None)
-
get a group of columns from multi-index columns DataFrame
- Parameters:
-
-
df (pd.DataFrame) – with multi of columns.
-
group (str) – the name of the feature group, i.e. the first level value of the group index.
-
- classqlib.data.dataset.processor.Processor
-
- fit(df: DataFrame | None = None)
-
learn data processing parameters
- Parameters:
-
df (pd.DataFrame) – When we fit and process data with processor one by one. The fit function reiles on the output of previous processor, i.e. df.
- is_for_infer() bool
-
Is this processor usable for inference Some processors are not usable for inference.
- Returns:
-
if it is usable for infenrece.
- Return type:
-
bool
- readonly() bool
-
Does the processor treat the input data readonly (i.e. does not write the input data) when processing
Knowning the readonly information is helpful to the Handler to avoid uncessary copy
- config(**kwargs)
-
configure the serializable object
- Parameters:
-
-
keys (kwargs may include following) –
- dump_allbool
-
will the object dump all object
- excludelist
-
What attribute will not be dumped
- includelist
-
What attribute will be dumped
-
recursive (bool) – will the configuration be recursive
-
- classqlib.data.dataset.processor.DropnaProcessor(fields_group=None)
-
- __init__(fields_group=None)
- readonly()
-
Does the processor treat the input data readonly (i.e. does not write the input data) when processing
Knowning the readonly information is helpful to the Handler to avoid uncessary copy
- classqlib.data.dataset.processor.DropnaLabel(fields_group='label')
-
- __init__(fields_group='label')
- is_for_infer() bool
-
The samples are dropped according to label. So it is not usable for inference
- classqlib.data.dataset.processor.DropCol(col_list=[])
-
- __init__(col_list=[])
- readonly()
-
Does the processor treat the input data readonly (i.e. does not write the input data) when processing
Knowning the readonly information is helpful to the Handler to avoid uncessary copy
- classqlib.data.dataset.processor.FilterCol(fields_group='feature', col_list=[])
-
- __init__(fields_group='feature', col_list=[])
- readonly()
-
Does the processor treat the input data readonly (i.e. does not write the input data) when processing
Knowning the readonly information is helpful to the Handler to avoid uncessary copy
- classqlib.data.dataset.processor.TanhProcess
-
Use tanh to process noise data
- classqlib.data.dataset.processor.ProcessInf
-
Process infinity
- classqlib.data.dataset.processor.Fillna(fields_group=None, fill_value=0)
-
Process NaN
- __init__(fields_group=None, fill_value=0)
- classqlib.data.dataset.processor.MinMaxNorm(fit_start_time, fit_end_time, fields_group=None)
-
- __init__(fit_start_time, fit_end_time, fields_group=None)
- fit(df: DataFrame | None = None)
-
learn data processing parameters
- Parameters:
-
df (pd.DataFrame) – When we fit and process data with processor one by one. The fit function reiles on the output of previous processor, i.e. df.
- classqlib.data.dataset.processor.ZScoreNorm(fit_start_time, fit_end_time, fields_group=None)
-
ZScore Normalization
- __init__(fit_start_time, fit_end_time, fields_group=None)
- fit(df: DataFrame | None = None)
-
learn data processing parameters
- Parameters:
-
df (pd.DataFrame) – When we fit and process data with processor one by one. The fit function reiles on the output of previous processor, i.e. df.
- classqlib.data.dataset.processor.RobustZScoreNorm(fit_start_time, fit_end_time, fields_group=None, clip_outlier=True)
-
Robust ZScore Normalization
- Use robust statistics for Z-Score normalization:
-
mean(x) = median(x) std(x) = MAD(x) * 1.4826
- Reference:
- __init__(fit_start_time, fit_end_time, fields_group=None, clip_outlier=True)
- fit(df: DataFrame | None = None)
-
learn data processing parameters
- Parameters:
-
df (pd.DataFrame) – When we fit and process data with processor one by one. The fit function reiles on the output of previous processor, i.e. df.
- classqlib.data.dataset.processor.CSZScoreNorm(fields_group=None, method='zscore')
-
Cross Sectional ZScore Normalization
- __init__(fields_group=None, method='zscore')
- classqlib.data.dataset.processor.CSRankNorm(fields_group=None)
-
Cross Sectional Rank Normalization. “Cross Sectional” is often used to describe data operations. The operations across different stocks are often called Cross Sectional Operation.
For example, CSRankNorm is an operation that grouping the data by each day and rank across all the stocks in each day.
Explanation about 3.46 & 0.5
import numpy as np import pandas as pd x = np.random.random(10000) # for any variable x_rank = pd.Series(x).rank(pct=True) # if it is converted to rank, it will be a uniform distributed x_rank_norm = (x_rank - x_rank.mean()) / x_rank.std() # Normally, we will normalize it to make it like normal distribution x_rank.mean() # accounts for 0.5 1 / x_rank.std() # accounts for 3.46
- __init__(fields_group=None)
- classqlib.data.dataset.processor.CSZFillna(fields_group=None)
-
Cross Sectional Fill Nan
- __init__(fields_group=None)
- classqlib.data.dataset.processor.HashStockFormat
-
Process the storage of from df into hasing stock format
- classqlib.data.dataset.processor.TimeRangeFlt(start_time: Timestamp | str | None = None, end_time: Timestamp | str | None = None, freq: str = 'day')
-
This is a filter to filter stock. Only keep the data that exist from start_time to end_time (the existence in the middle is not checked.) WARNING: It may induce leakage!!!
- __init__(start_time: Timestamp | str | None = None, end_time: Timestamp | str | None = None, freq: str = 'day')
-
- Parameters:
-
-
start_time (Optional[Union[pd.Timestamp, str]]) – The data must start earlier (or equal) than start_time None indicates data will not be filtered based on start_time
-
end_time (Optional[Union[pd.Timestamp, str]]) – similar to start_time
-
freq (str) – The frequency of the calendar
-
Contrib
Model
- classqlib.model.base.BaseModel
-
Modeling things
- abstractpredict(*args, **kwargs) object
-
Make predictions after modeling things
- classqlib.model.base.Model
-
Learnable Models
- fit(dataset: Dataset, reweighter: Reweighter)
-
Learn model from the base model
Note
The attribute names of learned model should not start with ‘_’. So that the model could be dumped to disk.
The following code example shows how to retrieve x_train, y_train and w_train from the dataset:
# get features and labels df_train, df_valid = dataset.prepare( ["train", "valid"], col_set=["feature", "label"], data_key=DataHandlerLP.DK_L ) x_train, y_train = df_train["feature"], df_train["label"] x_valid, y_valid = df_valid["feature"], df_valid["label"] # get weights try: wdf_train, wdf_valid = dataset.prepare(["train", "valid"], col_set=["weight"], data_key=DataHandlerLP.DK_L) w_train, w_valid = wdf_train["weight"], wdf_valid["weight"] except KeyError as e: w_train = pd.DataFrame(np.ones_like(y_train.values), index=y_train.index) w_valid = pd.DataFrame(np.ones_like(y_valid.values), index=y_valid.index)
- Parameters:
-
dataset (Dataset) – dataset will generate the processed data from model training.
- abstractpredict(dataset: Dataset, segment: str | slice = 'test') object
-
give prediction given Dataset
- Parameters:
-
-
dataset (Dataset) – dataset will generate the processed dataset from model training.
-
segment (Text or slice) – dataset will use this segment to prepare data. (default=test)
-
- Return type:
-
Prediction results with certain type such as pandas.Series.
- classqlib.model.base.ModelFT
-
Model (F)ine(t)unable
- abstractfinetune(dataset: Dataset)
-
finetune model based given dataset
A typical use case of finetuning model with qlib.workflow.R
# start exp to train init model with R.start(experiment_name="init models"): model.fit(dataset) R.save_objects(init_model=model) rid = R.get_recorder().id # Finetune model based on previous trained model with R.start(experiment_name="finetune model"): recorder = R.get_recorder(recorder_id=rid, experiment_name="init models") model = recorder.load_object("init_model") model.finetune(dataset, num_boost_round=10)
- Parameters:
-
dataset (Dataset) – dataset will generate the processed dataset from model training.
Strategy
- classqlib.contrib.strategy.TopkDropoutStrategy(*, topk, n_drop, method_sell='bottom', method_buy='top', hold_thresh=1, only_tradable=False, forbid_all_trade_at_limit=True, **kwargs)
-
- __init__(*, topk, n_drop, method_sell='bottom', method_buy='top', hold_thresh=1, only_tradable=False, forbid_all_trade_at_limit=True, **kwargs)
-
- Parameters:
-
-
topk (int) – the number of stocks in the portfolio.
-
n_drop (int) – number of stocks to be replaced in each trading date.
-
method_sell (str) – dropout method_sell, random/bottom.
-
method_buy (str) – dropout method_buy, random/top.
-
hold_thresh (int) – minimum holding days before sell stock , will check current.get_stock_count(order.stock_id) >= self.hold_thresh.
-
only_tradable (bool) –
will the strategy only consider the tradable stock when buying and selling.
if only_tradable:
strategy will make decision with the tradable state of the stock info and avoid buy and sell them.
else:
strategy will make buy sell decision without checking the tradable state of the stock.
-
forbid_all_trade_at_limit (bool) –
if forbid all trades when limit_up or limit_down reached.
if forbid_all_trade_at_limit:
strategy will not do any trade when price reaches limit up/down, even not sell at limit up nor buy at limit down, though allowed in reality.
else:
strategy will sell at limit up and buy ad limit down.
-
- generate_trade_decision(execute_result=None)
-
Generate trade decision in each trading bar
- Parameters:
-
execute_result (List[object], optional) –
the executed result for trade decision, by default None
-
When call the generate_trade_decision firstly, execute_result could be None
-
- classqlib.contrib.strategy.WeightStrategyBase(*, order_generator_cls_or_obj=<class 'qlib.contrib.strategy.order_generator.OrderGenWOInteract'>, **kwargs)
-
- __init__(*, order_generator_cls_or_obj=<class 'qlib.contrib.strategy.order_generator.OrderGenWOInteract'>, **kwargs)
-
- signal :
-
the information to describe a signal. Please refer to the docs of qlib.backtest.signal.create_signal_from the decision of the strategy will base on the given signal
- trade_exchangeExchange
-
exchange that provides market info, used to deal order and generate report
-
If trade_exchange is None, self.trade_exchange will be set with common_infra
-
It allowes different trade_exchanges is used in different executions.
-
For example:
-
In daily execution, both daily exchange and minutely are usable, but the daily exchange is recommended because it runs faster.
-
In minutely execution, the daily exchange is not usable, only the minutely exchange is recommended.
-
-
- generate_target_weight_position(score, current, trade_start_time, trade_end_time)
-
Generate target position from score for this date and the current position.The cash is not considered in the position
- Parameters:
-
-
score (pd.Series) – pred score for this trade date, index is stock_id, contain ‘score’ column.
-
current (Position()) – current position.
-
trade_start_time (pd.Timestamp) –
-
trade_end_time (pd.Timestamp) –
-
- generate_trade_decision(execute_result=None)
-
Generate trade decision in each trading bar
- Parameters:
-
execute_result (List[object], optional) –
the executed result for trade decision, by default None
-
When call the generate_trade_decision firstly, execute_result could be None
-
- classqlib.contrib.strategy.EnhancedIndexingStrategy(*, riskmodel_root, market='csi500', turn_limit=None, name_mapping={}, optimizer_kwargs={}, verbose=False, **kwargs)
-
Enhanced Indexing Strategy
Enhanced indexing combines the arts of active management and passive management, with the aim of outperforming a benchmark index (e.g., S&P 500) in terms of portfolio return while controlling the risk exposure (a.k.a. tracking error).
Users need to prepare their risk model data like below:
├── /path/to/riskmodel ├──── 20210101 ├────── factor_exp.{csv|pkl|h5} ├────── factor_cov.{csv|pkl|h5} ├────── specific_risk.{csv|pkl|h5} ├────── blacklist.{csv|pkl|h5} # optionalThe risk model data can be obtained from risk data provider. You can also use qlib.model.riskmodel.structured.StructuredCovEstimator to prepare these data.
- Parameters:
-
-
riskmodel_path (str) – risk model path
-
name_mapping (dict) – alternative file names
-
- __init__(*, riskmodel_root, market='csi500', turn_limit=None, name_mapping={}, optimizer_kwargs={}, verbose=False, **kwargs)
-
- signal :
-
the information to describe a signal. Please refer to the docs of qlib.backtest.signal.create_signal_from the decision of the strategy will base on the given signal
- trade_exchangeExchange
-
exchange that provides market info, used to deal order and generate report
-
If trade_exchange is None, self.trade_exchange will be set with common_infra
-
It allowes different trade_exchanges is used in different executions.
-
For example:
-
In daily execution, both daily exchange and minutely are usable, but the daily exchange is recommended because it runs faster.
-
In minutely execution, the daily exchange is not usable, only the minutely exchange is recommended.
-
-
- generate_target_weight_position(score, current, trade_start_time, trade_end_time)
-
Generate target position from score for this date and the current position.The cash is not considered in the position
- Parameters:
-
-
score (pd.Series) – pred score for this trade date, index is stock_id, contain ‘score’ column.
-
current (Position()) – current position.
-
trade_start_time (pd.Timestamp) –
-
trade_end_time (pd.Timestamp) –
-
- classqlib.contrib.strategy.TWAPStrategy(outer_trade_decision: BaseTradeDecision = None, level_infra: LevelInfrastructure = None, common_infra: CommonInfrastructure = None, trade_exchange: Exchange = None)
-
TWAP Strategy for trading
Note
-
This TWAP strategy will celling round when trading. This will make the TWAP trading strategy produce the order earlier when the total trade unit of amount is less than the trading step
- reset(outer_trade_decision: BaseTradeDecision | None = None, **kwargs)
-
- Parameters:
-
outer_trade_decision (BaseTradeDecision, optional) –
- generate_trade_decision(execute_result=None)
-
Generate trade decision in each trading bar
- Parameters:
-
execute_result (List[object], optional) –
the executed result for trade decision, by default None
-
When call the generate_trade_decision firstly, execute_result could be None
-
-
- classqlib.contrib.strategy.SBBStrategyBase(outer_trade_decision: BaseTradeDecision = None, level_infra: LevelInfrastructure = None, common_infra: CommonInfrastructure = None, trade_exchange: Exchange = None)
-
(S)elect the (B)etter one among every two adjacent trading (B)ars to sell or buy.
- reset(outer_trade_decision: BaseTradeDecision | None = None, **kwargs)
-
- Parameters:
-
outer_trade_decision (BaseTradeDecision, optional) –
- generate_trade_decision(execute_result=None)
-
Generate trade decision in each trading bar
- Parameters:
-
execute_result (List[object], optional) –
the executed result for trade decision, by default None
-
When call the generate_trade_decision firstly, execute_result could be None
-
- classqlib.contrib.strategy.SBBStrategyEMA(outer_trade_decision: BaseTradeDecision | None = None, instruments: List | str = 'csi300', freq: str = 'day', trade_exchange: Exchange | None = None, level_infra: LevelInfrastructure | None = None, common_infra: CommonInfrastructure | None = None, **kwargs)
-
(S)elect the (B)etter one among every two adjacent trading (B)ars to sell or buy with (EMA) signal.
- __init__(outer_trade_decision: BaseTradeDecision | None = None, instruments: List | str = 'csi300', freq: str = 'day', trade_exchange: Exchange | None = None, level_infra: LevelInfrastructure | None = None, common_infra: CommonInfrastructure | None = None, **kwargs)
-
- Parameters:
-
-
instruments (Union[List, str], optional) – instruments of EMA signal, by default “csi300”
-
freq (str, optional) – freq of EMA signal, by default “day” Note: freq may be different from time_per_step
-
- reset_level_infra(level_infra)
-
reset level-shared infra - After reset the trade calendar, the signal will be changed
- classqlib.contrib.strategy.SoftTopkStrategy(model, dataset, topk, order_generator_cls_or_obj=<class 'qlib.contrib.strategy.order_generator.OrderGenWInteract'>, max_sold_weight=1.0, risk_degree=0.95, buy_method='first_fill', trade_exchange=None, level_infra=None, common_infra=None, **kwargs)
-
- __init__(model, dataset, topk, order_generator_cls_or_obj=<class 'qlib.contrib.strategy.order_generator.OrderGenWInteract'>, max_sold_weight=1.0, risk_degree=0.95, buy_method='first_fill', trade_exchange=None, level_infra=None, common_infra=None, **kwargs)
-
- Parameters:
-
-
topk (int) – top-N stocks to buy
-
risk_degree (float) –
position percentage of total value buy_method:
rank_fill: assign the weight stocks that rank high first(1/topk max) average_fill: assign the weight to the stocks rank high averagely.
-
- get_risk_degree(trade_step=None)
-
Return the proportion of your total value you will used in investment. Dynamically risk_degree will result in Market timing
- generate_target_weight_position(score, current, trade_start_time, trade_end_time)
-
- Parameters:
-
-
score – pred score for this trade date, pd.Series, index is stock_id, contain ‘score’ column
-
current – current position, use Position() class
-
trade_date –
trade date
generate target position from score for this date and the current position
The cache is not considered in the position
-
Evaluate
- qlib.contrib.evaluate.risk_analysis(r, N: int | None = None, freq: str = 'day')
-
Risk Analysis NOTE: The calculation of annulaized return is different from the definition of annualized return. It is implemented by design. Qlib tries to cumulated returns by summation instead of production to avoid the cumulated curve being skewed exponentially. All the calculation of annualized returns follows this principle in Qlib.
TODO: add a parameter to enable calculating metrics with production accumulation of return.
- Parameters:
-
-
r (pandas.Series) – daily return series.
-
N (int) – scaler for annualizing information_ratio (day: 252, week: 50, month: 12), at least one of N and freq should exist
-
freq (str) – analysis frequency used for calculating the scaler, at least one of N and freq should exist
-
- qlib.contrib.evaluate.indicator_analysis(df, method='mean')
-
analyze statistical time-series indicators of trading
- Parameters:
-
-
df (pandas.DataFrame) –
- columns: like [‘pa’, ‘pos’, ‘ffr’, ‘deal_amount’, ‘value’].
-
- Necessary fields:
-
-
’pa’ is the price advantage in trade indicators
-
’pos’ is the positive rate in trade indicators
-
’ffr’ is the fulfill rate in trade indicators
-
- Optional fields:
-
-
’deal_amount’ is the total deal deal_amount, only necessary when method is ‘amount_weighted’
-
’value’ is the total trade value, only necessary when method is ‘value_weighted’
-
index: Index(datetime)
-
method (str, optional) –
statistics method of pa/ffr, by default “mean”
-
if method is ‘mean’, count the mean statistical value of each trade indicator
-
if method is ‘amount_weighted’, count the deal_amount weighted mean statistical value of each trade indicator
-
if method is ‘value_weighted’, count the value weighted mean statistical value of each trade indicator
Note: statistics method of pos is always “mean”
-
-
- Returns:
-
statistical value of each trade indicators
- Return type:
-
pd.DataFrame
- qlib.contrib.evaluate.backtest_daily(start_time: str | Timestamp, end_time: str | Timestamp, strategy: str | dict | BaseStrategy, executor: str | dict | BaseExecutor | None = None, account: float | int | Position = 100000000.0, benchmark: str = 'SH000300', exchange_kwargs: dict | None = None, pos_type: str = 'Position')
-
initialize the strategy and executor, then executor the backtest of daily frequency
- Parameters:
-
-
start_time (Union[str, pd.Timestamp]) – closed start time for backtest NOTE: This will be applied to the outmost executor’s calendar.
-
end_time (Union[str, pd.Timestamp]) – closed end time for backtest NOTE: This will be applied to the outmost executor’s calendar. E.g. Executor[day](Executor[1min]), setting end_time == 20XX0301 will include all the minutes on 20XX0301
-
strategy (Union[str, dict, BaseStrategy]) –
for initializing outermost portfolio strategy. Please refer to the docs of init_instance_by_config for more information.
E.g.
# dict strategy = { "class": "TopkDropoutStrategy", "module_path": "qlib.contrib.strategy.signal_strategy", "kwargs": { "signal": (model, dataset), "topk": 50, "n_drop": 5, }, } # BaseStrategy pred_score = pd.read_pickle("score.pkl")["score"] STRATEGY_CONFIG = { "topk": 50, "n_drop": 5, "signal": pred_score, } strategy = TopkDropoutStrategy(**STRATEGY_CONFIG) # str example. # 1) specify a pickle object # - path like 'file:///<path to pickle file>/obj.pkl' # 2) specify a class name # - "ClassName": getattr(module, "ClassName")() will be used. # 3) specify module path with class name # - "a.b.c.ClassName" getattr(<a.b.c.module>, "ClassName")() will be used.
-
executor (Union[str, dict, BaseExecutor]) – for initializing the outermost executor.
-
benchmark (str) – the benchmark for reporting.
-
account (Union[float, int, Position]) –
information for describing how to creating the account
For float or int:
Using Account with only initial cash
For Position:
Using Account with a Position
-
exchange_kwargs (dict) –
the kwargs for initializing Exchange E.g.
exchange_kwargs = { "freq": freq, "limit_threshold": None, # limit_threshold is None, using C.limit_threshold "deal_price": None, # deal_price is None, using C.deal_price "open_cost": 0.0005, "close_cost": 0.0015, "min_cost": 5, }
-
pos_type (str) – the type of Position.
-
- Returns:
-
-
report_normal (pd.DataFrame) – backtest report
-
positions_normal (pd.DataFrame) – backtest positions
-
- qlib.contrib.evaluate.long_short_backtest(pred, topk=50, deal_price=None, shift=1, open_cost=0, close_cost=0, trade_unit=None, limit_threshold=None, min_cost=5, subscribe_fields=[], extract_codes=False)
-
A backtest for long-short strategy
- Parameters:
-
-
pred – The trading signal produced on day T.
-
topk – The short topk securities and long topk securities.
-
deal_price – The price to deal the trading.
-
shift – Whether to shift prediction by one day. The trading day will be T+1 if shift==1.
-
open_cost – open transaction cost.
-
close_cost – close transaction cost.
-
trade_unit – 100 for China A.
-
limit_threshold – limit move 0.1 (10%) for example, long and short with same limit.
-
min_cost – min transaction cost.
-
subscribe_fields – subscribe fields.
-
extract_codes – bool. will we pass the codes extracted from the pred to the exchange. NOTE: This will be faster with offline qlib.
-
- Returns:
-
The result of backtest, it is represented by a dict. { “long”: long_returns(excess), “short”: short_returns(excess), “long_short”: long_short_returns}
Report
Workflow
Experiment Manager
- classqlib.workflow.expm.ExpManager(uri: str, default_exp_name: str | None)
-
This is the ExpManager class for managing experiments. The API is designed similar to mlflow. (The link: https://mlflow.org/docs/latest/python_api/mlflow.html)
The ExpManager is expected to be a singleton (btw, we can have multiple Experiment`s with different uri. user can get different experiments from different uri, and then compare records of them). Global Config (i.e. `C) is also a singleton.
So we try to align them together. They share the same variable, which is called default uri. Please refer to ExpManager.default_uri for details of variable sharing.
When the user starts an experiment, the user may want to set the uri to a specific uri (it will override default uri during this period), and then unset the specific uri and fallback to the default uri. ExpManager._active_exp_uri is that specific uri.
- __init__(uri: str, default_exp_name: str | None)
- start_exp(*, experiment_id: str | None = None, experiment_name: str | None = None, recorder_id: str | None = None, recorder_name: str | None = None, uri: str | None = None, resume: bool = False, **kwargs) Experiment
-
Start an experiment. This method includes first get_or_create an experiment, and then set it to be active.
Maintaining _active_exp_uri is included in start_exp, remaining implementation should be included in _end_exp in subclass
- Parameters:
-
-
experiment_id (str) – id of the active experiment.
-
experiment_name (str) – name of the active experiment.
-
recorder_id (str) – id of the recorder to be started.
-
recorder_name (str) – name of the recorder to be started.
-
uri (str) – the current tracking URI.
-
resume (boolean) – whether to resume the experiment and recorder.
-
- Return type:
-
An active experiment.
- end_exp(recorder_status: str = 'SCHEDULED', **kwargs)
-
End an active experiment.
Maintaining _active_exp_uri is included in end_exp, remaining implementation should be included in _end_exp in subclass
- Parameters:
-
-
experiment_name (str) – name of the active experiment.
-
recorder_status (str) – the status of the active recorder of the experiment.
-
- create_exp(experiment_name: str | None = None)
-
Create an experiment.
- Parameters:
-
experiment_name (str) – the experiment name, which must be unique.
- Return type:
-
An experiment object.
- Raises:
-
ExpAlreadyExistError –
- search_records(experiment_ids=None, **kwargs)
-
Get a pandas DataFrame of records that fit the search criteria of the experiment. Inputs are the search criteria user want to apply.
- Returns:
-
-
A pandas.DataFrame of records, where each metric, parameter, and tag
-
are expanded into their own columns named metrics., params.*, and tags.**
-
respectively. For records that don’t have a particular metric, parameter, or tag, their
-
value will be (NumPy) Nan, None, or None respectively.
-
- get_exp(*, experiment_id=None, experiment_name=None, create: bool = True, start: bool = False)
-
Retrieve an experiment. This method includes getting an active experiment, and get_or_create a specific experiment.
When user specify experiment id and name, the method will try to return the specific experiment. When user does not provide recorder id or name, the method will try to return the current active experiment. The create argument determines whether the method will automatically create a new experiment according to user’s specification if the experiment hasn’t been created before.
-
If create is True:
-
If active experiment exists:
-
no id or name specified, return the active experiment.
-
if id or name is specified, return the specified experiment. If no such exp found, create a new experiment with given id or name. If start is set to be True, the experiment is set to be active.
-
-
If active experiment not exists:
-
no id or name specified, create a default experiment.
-
if id or name is specified, return the specified experiment. If no such exp found, create a new experiment with given id or name. If start is set to be True, the experiment is set to be active.
-
-
-
Else If create is False:
-
If active experiment exists:
-
no id or name specified, return the active experiment.
-
if id or name is specified, return the specified experiment. If no such exp found, raise Error.
-
-
If active experiment not exists:
-
no id or name specified. If the default experiment exists, return it, otherwise, raise Error.
-
if id or name is specified, return the specified experiment. If no such exp found, raise Error.
-
-
- Parameters:
-
-
experiment_id (str) – id of the experiment to return.
-
experiment_name (str) – name of the experiment to return.
-
create (boolean) – create the experiment it if hasn’t been created before.
-
start (boolean) – start the new experiment if one is created.
-
- Return type:
-
An experiment object.
-
- delete_exp(experiment_id=None, experiment_name=None)
-
Delete an experiment.
- Parameters:
-
-
experiment_id (str) – the experiment id.
-
experiment_name (str) – the experiment name.
-
- propertydefault_uri
-
Get the default tracking URI from qlib.config.C
- propertyuri
-
Get the default tracking URI or current URI.
- Return type:
-
The tracking URI string.
- list_experiments()
-
List all the existing experiments.
- Return type:
-
A dictionary (name -> experiment) of experiments information that being stored.
Experiment
- classqlib.workflow.exp.Experiment(id, name)
-
This is the Experiment class for each experiment being run. The API is designed similar to mlflow. (The link: https://mlflow.org/docs/latest/python_api/mlflow.html)
- __init__(id, name)
- start(*, recorder_id=None, recorder_name=None, resume=False)
-
Start the experiment and set it to be active. This method will also start a new recorder.
- Parameters:
-
-
recorder_id (str) – the id of the recorder to be created.
-
recorder_name (str) – the name of the recorder to be created.
-
resume (bool) – whether to resume the first recorder
-
- Return type:
-
An active recorder.
- end(recorder_status='SCHEDULED')
-
End the experiment.
- Parameters:
-
recorder_status (str) – the status the recorder to be set with when ending (SCHEDULED, RUNNING, FINISHED, FAILED).
- create_recorder(recorder_name=None)
-
Create a recorder for each experiment.
- Parameters:
-
recorder_name (str) – the name of the recorder to be created.
- Return type:
-
A recorder object.
- search_records(**kwargs)
-
Get a pandas DataFrame of records that fit the search criteria of the experiment. Inputs are the search criteria user want to apply.
- Returns:
-
-
A pandas.DataFrame of records, where each metric, parameter, and tag
-
are expanded into their own columns named metrics., params.*, and tags.**
-
respectively. For records that don’t have a particular metric, parameter, or tag, their
-
value will be (NumPy) Nan, None, or None respectively.
-
- delete_recorder(recorder_id)
-
Create a recorder for each experiment.
- Parameters:
-
recorder_id (str) – the id of the recorder to be deleted.
- get_recorder(recorder_id=None, recorder_name=None, create: bool = True, start: bool = False) Recorder
-
Retrieve a Recorder for user. When user specify recorder id and name, the method will try to return the specific recorder. When user does not provide recorder id or name, the method will try to return the current active recorder. The create argument determines whether the method will automatically create a new recorder according to user’s specification if the recorder hasn’t been created before.
-
If create is True:
-
If active recorder exists:
-
no id or name specified, return the active recorder.
-
if id or name is specified, return the specified recorder. If no such exp found, create a new recorder with given id or name. If start is set to be True, the recorder is set to be active.
-
-
If active recorder not exists:
-
no id or name specified, create a new recorder.
-
if id or name is specified, return the specified experiment. If no such exp found, create a new recorder with given id or name. If start is set to be True, the recorder is set to be active.
-
-
-
Else If create is False:
-
If active recorder exists:
-
no id or name specified, return the active recorder.
-
if id or name is specified, return the specified recorder. If no such exp found, raise Error.
-
-
If active recorder not exists:
-
no id or name specified, raise Error.
-
if id or name is specified, return the specified recorder. If no such exp found, raise Error.
-
-
- Parameters:
-
-
recorder_id (str) – the id of the recorder to be deleted.
-
recorder_name (str) – the name of the recorder to be deleted.
-
create (boolean) – create the recorder if it hasn’t been created before.
-
start (boolean) – start the new recorder if one is created.
-
- Return type:
-
A recorder object.
-
- list_recorders(rtype: Literal['dict', 'list'] = 'dict', **flt_kwargs) List[Recorder] | Dict[str, Recorder]
-
List all the existing recorders of this experiment. Please first get the experiment instance before calling this method. If user want to use the method R.list_recorders(), please refer to the related API document in QlibRecorder.
- flt_kwargsdict
-
filter recorders by conditions e.g. list_recorders(status=Recorder.STATUS_FI)
- Returns:
-
- if rtype == “dict”:
-
A dictionary (id -> recorder) of recorder information that being stored.
- elif rtype == “list”:
-
A list of Recorder.
- Return type:
-
The return type depends on rtype
Recorder
- classqlib.workflow.recorder.Recorder(experiment_id, name)
-
This is the Recorder class for logging the experiments. The API is designed similar to mlflow. (The link: https://mlflow.org/docs/latest/python_api/mlflow.html)
The status of the recorder can be SCHEDULED, RUNNING, FINISHED, FAILED.
- __init__(experiment_id, name)
- save_objects(local_path=None, artifact_path=None, **kwargs)
-
Save objects such as prediction file or model checkpoints to the artifact URI. User can save object through keywords arguments (name:value).
Please refer to the docs of qlib.workflow:R.save_objects
- Parameters:
-
-
local_path (str) – if provided, them save the file or directory to the artifact URI.
-
artifact_path=None (str) – the relative path for the artifact to be stored in the URI.
-
- load_object(name)
-
Load objects such as prediction file or model checkpoints.
- Parameters:
-
name (str) – name of the file to be loaded.
- Return type:
-
The saved object.
- start_run()
-
Start running or resuming the Recorder. The return value can be used as a context manager within a with block; otherwise, you must call end_run() to terminate the current run. (See ActiveRun class in mlflow)
- Return type:
-
An active running object (e.g. mlflow.ActiveRun object).
- end_run()
-
End an active Recorder.
- log_params(**kwargs)
-
Log a batch of params for the current run.
- Parameters:
-
arguments (keyword) – key, value pair to be logged as parameters.
- log_metrics(step=None, **kwargs)
-
Log multiple metrics for the current run.
- Parameters:
-
arguments (keyword) – key, value pair to be logged as metrics.
- log_artifact(local_path: str, artifact_path: str | None = None)
-
Log a local file or directory as an artifact of the currently active run.
- Parameters:
-
-
local_path (str) – Path to the file to write.
-
artifact_path (Optional[str]) – If provided, the directory in
artifact_urito write to.
-
-
Log a batch of tags for the current run.
- Parameters:
-
arguments (keyword) – key, value pair to be logged as tags.
-
Delete some tags from a run.
- Parameters:
-
keys (series of strs of the keys) – all the name of the tag to be deleted.
- list_artifacts(artifact_path: str | None = None)
-
List all the artifacts of a recorder.
- Parameters:
-
artifact_path (str) – the relative path for the artifact to be stored in the URI.
- Return type:
-
A list of artifacts information (name, path, etc.) that being stored.
- download_artifact(path: str, dst_path: str | None = None) str
-
Download an artifact file or directory from a run to a local directory if applicable, and return a local path for it.
- Parameters:
-
-
path (str) – Relative source path to the desired artifact.
-
dst_path (Optional[str]) – Absolute path of the local filesystem destination directory to which to download the specified artifacts. This directory must already exist. If unspecified, the artifacts will either be downloaded to a new uniquely-named directory on the local filesystem.
-
- Returns:
-
Local path of desired artifact.
- Return type:
-
str
- list_metrics()
-
List all the metrics of a recorder.
- Return type:
-
A dictionary of metrics that being stored.
- list_params()
-
List all the params of a recorder.
- Return type:
-
A dictionary of params that being stored.
-
List all the tags of a recorder.
- Return type:
-
A dictionary of tags that being stored.
Record Template
- classqlib.workflow.record_temp.RecordTemp(recorder)
-
This is the Records Template class that enables user to generate experiment results such as IC and backtest in a certain format.
- save(**kwargs)
-
It behaves the same as self.recorder.save_objects. But it is an easier interface because users don’t have to care about get_path and artifact_path
- __init__(recorder)
- generate(**kwargs)
-
Generate certain records such as IC, backtest etc., and save them.
- Parameters:
-
kwargs –
- load(name: str, parents: bool = True)
-
It behaves the same as self.recorder.load_object. But it is an easier interface because users don’t have to care about get_path and artifact_path
- Parameters:
-
-
name (str) – the name for the file to be load.
-
parents (bool) – Each recorder has different artifact_path. So parents recursively find the path in parents Sub classes has higher priority
-
- Return type:
-
The stored records.
- list()
-
List the supported artifacts. Users don’t have to consider self.get_path
- Return type:
-
A list of all the supported artifacts.
- check(include_self: bool = False, parents: bool = True)
-
Check if the records is properly generated and saved. It is useful in following examples
-
checking if the dependant files complete before generating new things.
-
checking if the final files is completed
- Parameters:
-
-
include_self (bool) – is the file generated by self included
-
parents (bool) – will we check parents
-
- Raises:
-
FileNotFoundError – whether the records are stored properly.
-
- classqlib.workflow.record_temp.SignalRecord(model=None, dataset=None, recorder=None)
-
This is the Signal Record class that generates the signal prediction. This class inherits the
RecordTempclass.- __init__(model=None, dataset=None, recorder=None)
- generate(**kwargs)
-
Generate certain records such as IC, backtest etc., and save them.
- Parameters:
-
kwargs –
- list()
-
List the supported artifacts. Users don’t have to consider self.get_path
- Return type:
-
A list of all the supported artifacts.
- classqlib.workflow.record_temp.ACRecordTemp(recorder, skip_existing=False)
-
Automatically checking record template
- __init__(recorder, skip_existing=False)
- generate(*args, **kwargs)
-
automatically checking the files and then run the concrete generating task
- classqlib.workflow.record_temp.HFSignalRecord(recorder, **kwargs)
-
This is the Signal Analysis Record class that generates the analysis results such as IC and IR. This class inherits the
RecordTempclass.- depend_cls
-
alias of
SignalRecord
- __init__(recorder, **kwargs)
- generate()
-
Generate certain records such as IC, backtest etc., and save them.
- Parameters:
-
kwargs –
- list()
-
List the supported artifacts. Users don’t have to consider self.get_path
- Return type:
-
A list of all the supported artifacts.
- classqlib.workflow.record_temp.SigAnaRecord(recorder, ana_long_short=False, ann_scaler=252, label_col=0, skip_existing=False)
-
This is the Signal Analysis Record class that generates the analysis results such as IC and IR. This class inherits the
RecordTempclass.- depend_cls
-
alias of
SignalRecord
- __init__(recorder, ana_long_short=False, ann_scaler=252, label_col=0, skip_existing=False)
- list()
-
List the supported artifacts. Users don’t have to consider self.get_path
- Return type:
-
A list of all the supported artifacts.
- classqlib.workflow.record_temp.PortAnaRecord(recorder, config=None, risk_analysis_freq: List | str | None = None, indicator_analysis_freq: List | str | None = None, indicator_analysis_method=None, skip_existing=False, **kwargs)
-
This is the Portfolio Analysis Record class that generates the analysis results such as those of backtest. This class inherits the
RecordTempclass.The following files will be stored in recorder
-
report_normal.pkl & positions_normal.pkl:
-
The return report and detailed positions of the backtest, returned by qlib/contrib/evaluate.py:backtest
-
-
port_analysis.pkl : The risk analysis of your portfolio, returned by qlib/contrib/evaluate.py:risk_analysis
- depend_cls
-
alias of
SignalRecord
- __init__(recorder, config=None, risk_analysis_freq: List | str | None = None, indicator_analysis_freq: List | str | None = None, indicator_analysis_method=None, skip_existing=False, **kwargs)
-
- config[“strategy”]dict
-
define the strategy class as well as the kwargs.
- config[“executor”]dict
-
define the executor class as well as the kwargs.
- config[“backtest”]dict
-
define the backtest kwargs.
- risk_analysis_freqstr|List[str]
-
risk analysis freq of report
- indicator_analysis_freqstr|List[str]
-
indicator analysis freq of report
- indicator_analysis_methodstr, optional, default by None
-
the candidate values include ‘mean’, ‘amount_weighted’, ‘value_weighted’
- list()
-
List the supported artifacts. Users don’t have to consider self.get_path
- Return type:
-
A list of all the supported artifacts.
-
- classqlib.workflow.record_temp.MultiPassPortAnaRecord(recorder, pass_num=10, shuffle_init_score=True, **kwargs)
-
This is the Multiple Pass Portfolio Analysis Record class that run backtest multiple times and generates the analysis results such as those of backtest. This class inherits the
PortAnaRecordclass.If shuffle_init_score enabled, the prediction score of the first backtest date will be shuffled, so that initial position will be random. The shuffle_init_score will only works when the signal is used as <PRED> placeholder. The placeholder will be replaced by pred.pkl saved in recorder.
- Parameters:
-
-
recorder (Recorder) – The recorder used to save the backtest results.
-
pass_num (int) – The number of backtest passes.
-
shuffle_init_score (bool) – Whether to shuffle the prediction score of the first backtest date.
-
- depend_cls
-
alias of
SignalRecord
- __init__(recorder, pass_num=10, shuffle_init_score=True, **kwargs)
-
- Parameters:
-
-
recorder (Recorder) – The recorder used to save the backtest results.
-
pass_num (int) – The number of backtest passes.
-
shuffle_init_score (bool) – Whether to shuffle the prediction score of the first backtest date.
-
- list()
-
List the supported artifacts. Users don’t have to consider self.get_path
- Return type:
-
A list of all the supported artifacts.
Task Management
TaskGen
TaskGenerator module can generate many tasks based on TaskGen and some task templates.
- qlib.workflow.task.gen.task_generator(tasks, generators) list
-
Use a list of TaskGen and a list of task templates to generate different tasks.
For examples:
There are 3 task templates a,b,c and 2 TaskGen A,B. A will generates 2 tasks from a template and B will generates 3 tasks from a template. task_generator([a, b, c], [A, B]) will finally generate 3*2*3 = 18 tasks.
- classqlib.workflow.task.gen.TaskGen
-
The base class for generating different tasks
Example 1:
input: a specific task template and rolling steps
output: rolling version of the tasks
Example 2:
input: a specific task template and losses list
output: a set of tasks with different losses
- abstractgenerate(task: dict) List[dict]
-
Generate different tasks based on a task template
- Parameters:
-
task (dict) – a task template
- Returns:
-
A list of tasks
- Return type:
-
List[dict]
- qlib.workflow.task.gen.handler_mod(task: dict, rolling_gen)
-
Help to modify the handler end time when using RollingGen It try to handle the following case
-
Hander’s data end_time is earlier than dataset’s test_data’s segments.
-
To handle this, handler’s data’s end_time is extended.
-
If the handler’s end_time is None, then it is not necessary to change it’s end time.
- Parameters:
-
-
task (dict) – a task template
-
rg (RollingGen) – an instance of RollingGen
-
-
- qlib.workflow.task.gen.trunc_segments(ta: TimeAdjuster, segments: Dict[str, Timestamp], days, test_key='test')
-
To avoid the leakage of future information, the segments should be truncated according to the test start_time
Note
This function will change segments inplace
- classqlib.workflow.task.gen.RollingGen(step: int = 40, rtype: str = 'expanding', ds_extra_mod_func: None | ~typing.Callable = <function handler_mod>, test_key='test', train_key='train', trunc_days: int | None = None, task_copy_func: ~typing.Callable = <function deepcopy>)
-
- __init__(step: int = 40, rtype: str = 'expanding', ds_extra_mod_func: None | ~typing.Callable = <function handler_mod>, test_key='test', train_key='train', trunc_days: int | None = None, task_copy_func: ~typing.Callable = <function deepcopy>)
-
Generate tasks for rolling
- Parameters:
-
-
step (int) – step to rolling
-
rtype (str) – rolling type (expanding, sliding)
-
ds_extra_mod_func (Callable) – A method like: handler_mod(task: dict, rg: RollingGen) Do some extra action after generating a task. For example, use
handler_modto modify the end time of the handler of a dataset. -
trunc_days (int) – trunc some data to avoid future information leakage
-
task_copy_func (Callable) – the function to copy entire task. This is very useful when user want to share something between tasks
-
- gen_following_tasks(task: dict, test_end: Timestamp) List[dict]
-
generating following rolling tasks for task until test_end
- Parameters:
-
-
task (dict) – Qlib task format
-
test_end (pd.Timestamp) – the latest rolling task includes test_end
-
- Returns:
-
the following tasks of task`(`task itself is excluded)
- Return type:
-
List[dict]
- generate(task: dict) List[dict]
-
Converting the task into a rolling task.
- Parameters:
-
task (dict) –
A dict describing a task. For example.
DEFAULT_TASK = { "model": { "class": "LGBModel", "module_path": "qlib.contrib.model.gbdt", }, "dataset": { "class": "DatasetH", "module_path": "qlib.data.dataset", "kwargs": { "handler": { "class": "Alpha158", "module_path": "qlib.contrib.data.handler", "kwargs": { "start_time": "2008-01-01", "end_time": "2020-08-01", "fit_start_time": "2008-01-01", "fit_end_time": "2014-12-31", "instruments": "csi100", }, }, "segments": { "train": ("2008-01-01", "2014-12-31"), "valid": ("2015-01-01", "2016-12-20"), # Please avoid leaking the future test data into validation "test": ("2017-01-01", "2020-08-01"), }, }, }, "record": [ { "class": "SignalRecord", "module_path": "qlib.workflow.record_temp", }, ] }
- Returns:
-
List[dict]
- Return type:
-
a list of tasks
- classqlib.workflow.task.gen.MultiHorizonGenBase(horizon: List[int] = [5], label_leak_n=2)
-
- __init__(horizon: List[int] = [5], label_leak_n=2)
-
This task generator tries to generate tasks for different horizons based on an existing task
- Parameters:
-
-
horizon (List[int]) – the possible horizons of the tasks
-
label_leak_n (int) – How many future days it will take to get complete label after the day making prediction For example: - User make prediction on day T`(after getting the close price on `T) - The label is the return of buying stock on T + 1 and selling it on T + 2 - the label_leak_n will be 2 (e.g. two days of information is leaked to leverage this sample)
-
- abstractset_horizon(task: dict, hr: int)
-
This method is designed to change the task in place
- Parameters:
-
-
task (dict) – Qlib’s task
-
hr (int) – the horizon of task
-
- generate(task: dict)
-
Generate different tasks based on a task template
- Parameters:
-
task (dict) – a task template
- Returns:
-
A list of tasks
- Return type:
-
List[dict]
TaskManager
TaskManager can fetch unused tasks automatically and manage the lifecycle of a set of tasks with error handling. These features can run tasks concurrently and ensure every task will be used only once. Task Manager will store all tasks in MongoDB. Users MUST finished the configuration of MongoDB when using this module.
A task in TaskManager consists of 3 parts - tasks description: the desc will define the task - tasks status: the status of the task - tasks result: A user can get the task with the task description and task result.
- classqlib.workflow.task.manage.TaskManager(task_pool: str)
-
Here is what will a task looks like when it created by TaskManager
{ 'def': pickle serialized task definition. using pickle will make it easier 'filter': json-like data. This is for filtering the tasks. 'status': 'waiting' | 'running' | 'done' 'res': pickle serialized task result, }
The tasks manager assumes that you will only update the tasks you fetched. The mongo fetch one and update will make it date updating secure.
This class can be used as a tool from commandline. Here are several examples. You can view the help of manage module with the following commands: python -m qlib.workflow.task.manage -h # show manual of manage module CLI python -m qlib.workflow.task.manage wait -h # show manual of the wait command of manage
python -m qlib.workflow.task.manage -t <pool_name> wait python -m qlib.workflow.task.manage -t <pool_name> task_statNote
Assumption: the data in MongoDB was encoded and the data out of MongoDB was decoded
Here are four status which are:
STATUS_WAITING: waiting for training
STATUS_RUNNING: training
STATUS_PART_DONE: finished some step and waiting for next step
STATUS_DONE: all work done
- __init__(task_pool: str)
-
Init Task Manager, remember to make the statement of MongoDB url and database name firstly. A TaskManager instance serves a specific task pool. The static method of this module serves the whole MongoDB.
- Parameters:
-
task_pool (str) – the name of Collection in MongoDB
- staticlist() list
-
List the all collection(task_pool) of the db.
- Returns:
-
list
- replace_task(task, new_task)
-
Use a new task to replace a old one
- Parameters:
-
-
task – old task
-
new_task – new task
-
- insert_task(task)
-
Insert a task.
- Parameters:
-
task – the task waiting for insert
- Returns:
-
pymongo.results.InsertOneResult
- insert_task_def(task_def)
-
Insert a task to task_pool
- Parameters:
-
task_def (dict) – the task definition
- Return type:
-
pymongo.results.InsertOneResult
- create_task(task_def_l, dry_run=False, print_nt=False) List[str]
-
If the tasks in task_def_l are new, then insert new tasks into the task_pool, and record inserted_id. If a task is not new, then just query its _id.
- Parameters:
-
-
task_def_l (list) – a list of task
-
dry_run (bool) – if insert those new tasks to task pool
-
print_nt (bool) – if print new task
-
- Returns:
-
a list of the _id of task_def_l
- Return type:
-
List[str]
- fetch_task(query={}, status='waiting') dict
-
Use query to fetch tasks.
- Parameters:
-
-
query (dict, optional) – query dict. Defaults to {}.
-
status (str, optional) – [description]. Defaults to STATUS_WAITING.
-
- Returns:
-
a task(document in collection) after decoding
- Return type:
-
dict
- safe_fetch_task(query={}, status='waiting')
-
Fetch task from task_pool using query with contextmanager
- Parameters:
-
query (dict) – the dict of query
- Returns:
-
dict
- Return type:
-
a task(document in collection) after decoding
- query(query={}, decode=True)
-
Query task in collection. This function may raise exception pymongo.errors.CursorNotFound: cursor id not found if it takes too long to iterate the generator
python -m qlib.workflow.task.manage -t <your task pool> query ‘{“_id”: “615498be837d0053acbc5d58”}’
- Parameters:
-
-
query (dict) – the dict of query
-
decode (bool) –
-
- Returns:
-
dict
- Return type:
-
a task(document in collection) after decoding
- re_query(_id) dict
-
Use _id to query task.
- Parameters:
-
_id (str) – _id of a document
- Returns:
-
a task(document in collection) after decoding
- Return type:
-
dict
- commit_task_res(task, res, status='done')
-
Commit the result to task[‘res’].
- Parameters:
-
-
task ([type]) – [description]
-
res (object) – the result you want to save
-
status (str, optional) – STATUS_WAITING, STATUS_RUNNING, STATUS_DONE, STATUS_PART_DONE. Defaults to STATUS_DONE.
-
- return_task(task, status='waiting')
-
Return a task to status. Always using in error handling.
- Parameters:
-
-
task ([type]) – [description]
-
status (str, optional) – STATUS_WAITING, STATUS_RUNNING, STATUS_DONE, STATUS_PART_DONE. Defaults to STATUS_WAITING.
-
- remove(query={})
-
Remove the task using query
- Parameters:
-
query (dict) – the dict of query
- task_stat(query={}) dict
-
Count the tasks in every status.
- Parameters:
-
query (dict, optional) – the query dict. Defaults to {}.
- Returns:
-
dict
- reset_waiting(query={})
-
Reset all running task into waiting status. Can be used when some running task exit unexpected.
- Parameters:
-
query (dict, optional) – the query dict. Defaults to {}.
- prioritize(task, priority: int)
-
Set priority for task
- Parameters:
-
-
task (dict) – The task query from the database
-
priority (int) – the target priority
-
- wait(query={})
-
When multiprocessing, the main progress may fetch nothing from TaskManager because there are still some running tasks. So main progress should wait until all tasks are trained well by other progress or machines.
- Parameters:
-
query (dict, optional) – the query dict. Defaults to {}.
- qlib.workflow.task.manage.run_task(task_func: Callable, task_pool: str, query: dict = {}, force_release: bool = False, before_status: str = 'waiting', after_status: str = 'done', **kwargs)
-
While the task pool is not empty (has WAITING tasks), use task_func to fetch and run tasks in task_pool
After running this method, here are 4 situations (before_status -> after_status):
STATUS_WAITING -> STATUS_DONE: use task[“def”] as task_func param, it means that the task has not been started
STATUS_WAITING -> STATUS_PART_DONE: use task[“def”] as task_func param
STATUS_PART_DONE -> STATUS_PART_DONE: use task[“res”] as task_func param, it means that the task has been started but not completed
STATUS_PART_DONE -> STATUS_DONE: use task[“res”] as task_func param
- Parameters:
-
-
task_func (Callable) –
def (task_def, **kwargs) -> <res which will be committed>
the function to run the task
-
task_pool (str) – the name of the task pool (Collection in MongoDB)
-
query (dict) – will use this dict to query task_pool when fetching task
-
force_release (bool) – will the program force to release the resource
-
before_status (str:) – the tasks in before_status will be fetched and trained. Can be STATUS_WAITING, STATUS_PART_DONE.
-
after_status (str:) – the tasks after trained will become after_status. Can be STATUS_WAITING, STATUS_PART_DONE.
-
kwargs – the params for task_func
-
Trainer
The Trainer will train a list of tasks and return a list of model recorders. There are two steps in each Trainer including
train(make model recorder) andend_train(modify model recorder).This is a concept called
DelayTrainer, which can be used in online simulating for parallel training. InDelayTrainer, the first step is only to save some necessary info to model recorders, and the second step which will be finished in the end can do some concurrent and time-consuming operations such as model fitting.Qliboffer two kinds of Trainer,TrainerRis the simplest way andTrainerRMis based on TaskManager to help manager tasks lifecycle automatically.- qlib.model.trainer.begin_task_train(task_config: dict, experiment_name: str, recorder_name: str | None = None) Recorder
-
Begin task training to start a recorder and save the task config.
- Parameters:
-
-
task_config (dict) – the config of a task
-
experiment_name (str) – the name of experiment
-
recorder_name (str) – the given name will be the recorder name. None for using rid.
-
- Returns:
-
the model recorder
- Return type:
- qlib.model.trainer.end_task_train(rec: Recorder, experiment_name: str) Recorder
-
Finish task training with real model fitting and saving.
- qlib.model.trainer.task_train(task_config: dict, experiment_name: str, recorder_name: str | None = None) Recorder
-
Task based training, will be divided into two steps.
- Parameters:
-
-
task_config (dict) – The config of a task.
-
experiment_name (str) – The name of experiment
-
recorder_name (str) – The name of recorder
-
- Returns:
-
Recorder
- Return type:
-
The instance of the recorder
- classqlib.model.trainer.Trainer
-
The trainer can train a list of models. There are Trainer and DelayTrainer, which can be distinguished by when it will finish real training.
- __init__()
- train(tasks: list, *args, **kwargs) list
-
Given a list of task definitions, begin training, and return the models.
For Trainer, it finishes real training in this method. For DelayTrainer, it only does some preparation in this method.
- Parameters:
-
tasks – a list of tasks
- Returns:
-
a list of models
- Return type:
-
list
- end_train(models: list, *args, **kwargs) list
-
Given a list of models, finished something at the end of training if you need. The models may be Recorder, txt file, database, and so on.
For Trainer, it does some finishing touches in this method. For DelayTrainer, it finishes real training in this method.
- Parameters:
-
models – a list of models
- Returns:
-
a list of models
- Return type:
-
list
- is_delay() bool
-
If Trainer will delay finishing end_train.
- Returns:
-
if DelayTrainer
- Return type:
-
bool
- has_worker() bool
-
Some trainer has backend worker to support parallel training This method can tell if the worker is enabled.
- Returns:
-
if the worker is enabled
- Return type:
-
bool
- worker()
-
start the worker
- Raises:
-
NotImplementedError: – If the worker is not supported
- classqlib.model.trainer.TrainerR(experiment_name: str | None = None, train_func: ~typing.Callable = <function task_train>, call_in_subproc: bool = False, default_rec_name: str | None = None)
-
Trainer based on (R)ecorder. It will train a list of tasks and return a list of model recorders in a linear way.
Assumption: models were defined by task and the results will be saved to Recorder.
- __init__(experiment_name: str | None = None, train_func: ~typing.Callable = <function task_train>, call_in_subproc: bool = False, default_rec_name: str | None = None)
-
Init TrainerR.
- Parameters:
-
-
experiment_name (str, optional) – the default name of experiment.
-
train_func (Callable, optional) – default training method. Defaults to task_train.
-
call_in_subproc (bool) – call the process in subprocess to force memory release
-
- train(tasks: list, train_func: Callable | None = None, experiment_name: str | None = None, **kwargs) List[Recorder]
-
Given a list of tasks and return a list of trained Recorder. The order can be guaranteed.
- Parameters:
-
-
tasks (list) – a list of definitions based on task dict
-
train_func (Callable) – the training method which needs at least tasks and experiment_name. None for the default training method.
-
experiment_name (str) – the experiment name, None for use default name.
-
kwargs – the params for train_func.
-
- Returns:
-
a list of Recorders
- Return type:
-
List[Recorder]
- classqlib.model.trainer.DelayTrainerR(experiment_name: str | None = None, train_func=<function begin_task_train>, end_train_func=<function end_task_train>, **kwargs)
-
A delayed implementation based on TrainerR, which means train method may only do some preparation and end_train method can do the real model fitting.
- __init__(experiment_name: str | None = None, train_func=<function begin_task_train>, end_train_func=<function end_task_train>, **kwargs)
-
Init TrainerRM.
- Parameters:
-
-
experiment_name (str) – the default name of experiment.
-
train_func (Callable, optional) – default train method. Defaults to begin_task_train.
-
end_train_func (Callable, optional) – default end_train method. Defaults to end_task_train.
-
- end_train(models, end_train_func=None, experiment_name: str | None = None, **kwargs) List[Recorder]
-
Given a list of Recorder and return a list of trained Recorder. This class will finish real data loading and model fitting.
- Parameters:
-
-
models (list) – a list of Recorder, the tasks have been saved to them
-
end_train_func (Callable, optional) – the end_train method which needs at least recorders and experiment_name. Defaults to None for using self.end_train_func.
-
experiment_name (str) – the experiment name, None for use default name.
-
kwargs – the params for end_train_func.
-
- Returns:
-
a list of Recorders
- Return type:
-
List[Recorder]
- classqlib.model.trainer.TrainerRM(experiment_name: str | None = None, task_pool: str | None = None, train_func=<function task_train>, skip_run_task: bool = False, default_rec_name: str | None = None)
-
Trainer based on (R)ecorder and Task(M)anager. It can train a list of tasks and return a list of model recorders in a multiprocessing way.
Assumption: task will be saved to TaskManager and task will be fetched and trained from TaskManager
- __init__(experiment_name: str | None = None, task_pool: str | None = None, train_func=<function task_train>, skip_run_task: bool = False, default_rec_name: str | None = None)
-
Init TrainerR.
- Parameters:
-
-
experiment_name (str) – the default name of experiment.
-
task_pool (str) – task pool name in TaskManager. None for use same name as experiment_name.
-
train_func (Callable, optional) – default training method. Defaults to task_train.
-
skip_run_task (bool) – If skip_run_task == True: Only run_task in the worker. Otherwise skip run_task.
-
- train(tasks: list, train_func: Callable | None = None, experiment_name: str | None = None, before_status: str = 'waiting', after_status: str = 'done', default_rec_name: str | None = None, **kwargs) List[Recorder]
-
Given a list of tasks and return a list of trained Recorder. The order can be guaranteed.
This method defaults to a single process, but TaskManager offered a great way to parallel training. Users can customize their train_func to realize multiple processes or even multiple machines.
- Parameters:
-
-
tasks (list) – a list of definitions based on task dict
-
train_func (Callable) – the training method which needs at least tasks and experiment_name. None for the default training method.
-
experiment_name (str) – the experiment name, None for use default name.
-
before_status (str) – the tasks in before_status will be fetched and trained. Can be STATUS_WAITING, STATUS_PART_DONE.
-
after_status (str) – the tasks after trained will become after_status. Can be STATUS_WAITING, STATUS_PART_DONE.
-
kwargs – the params for train_func.
-
- Returns:
-
a list of Recorders
- Return type:
-
List[Recorder]
- end_train(recs: list, **kwargs) List[Recorder]
-
Set STATUS_END tag to the recorders.
- Parameters:
-
recs (list) – a list of trained recorders.
- Returns:
-
the same list as the param.
- Return type:
-
List[Recorder]
- worker(train_func: Callable | None = None, experiment_name: str | None = None)
-
The multiprocessing method for train. It can share a same task_pool with train and can run in other progress or other machines.
- Parameters:
-
-
train_func (Callable) – the training method which needs at least tasks and experiment_name. None for the default training method.
-
experiment_name (str) – the experiment name, None for use default name.
-
- has_worker() bool
-
Some trainer has backend worker to support parallel training This method can tell if the worker is enabled.
- Returns:
-
if the worker is enabled
- Return type:
-
bool
- classqlib.model.trainer.DelayTrainerRM(experiment_name: str | None = None, task_pool: str | None = None, train_func=<function begin_task_train>, end_train_func=<function end_task_train>, skip_run_task: bool = False, **kwargs)
-
A delayed implementation based on TrainerRM, which means train method may only do some preparation and end_train method can do the real model fitting.
- __init__(experiment_name: str | None = None, task_pool: str | None = None, train_func=<function begin_task_train>, end_train_func=<function end_task_train>, skip_run_task: bool = False, **kwargs)
-
Init DelayTrainerRM.
- Parameters:
-
-
experiment_name (str) – the default name of experiment.
-
task_pool (str) – task pool name in TaskManager. None for use same name as experiment_name.
-
train_func (Callable, optional) – default train method. Defaults to begin_task_train.
-
end_train_func (Callable, optional) – default end_train method. Defaults to end_task_train.
-
skip_run_task (bool) – If skip_run_task == True: Only run_task in the worker. Otherwise skip run_task. E.g. Starting trainer on a CPU VM and then waiting tasks to be finished on GPU VMs.
-
- train(tasks: list, train_func=None, experiment_name: str | None = None, **kwargs) List[Recorder]
-
Same as train of TrainerRM, after_status will be STATUS_PART_DONE.
- Parameters:
-
-
tasks (list) – a list of definition based on task dict
-
train_func (Callable) – the train method which need at least tasks and experiment_name. Defaults to None for using self.train_func.
-
experiment_name (str) – the experiment name, None for use default name.
-
- Returns:
-
a list of Recorders
- Return type:
-
List[Recorder]
- end_train(recs, end_train_func=None, experiment_name: str | None = None, **kwargs) List[Recorder]
-
Given a list of Recorder and return a list of trained Recorder. This class will finish real data loading and model fitting.
- Parameters:
-
-
recs (list) – a list of Recorder, the tasks have been saved to them.
-
end_train_func (Callable, optional) – the end_train method which need at least recorders and experiment_name. Defaults to None for using self.end_train_func.
-
experiment_name (str) – the experiment name, None for use default name.
-
kwargs – the params for end_train_func.
-
- Returns:
-
a list of Recorders
- Return type:
-
List[Recorder]
- worker(end_train_func=None, experiment_name: str | None = None)
-
The multiprocessing method for end_train. It can share a same task_pool with end_train and can run in other progress or other machines.
- Parameters:
-
-
end_train_func (Callable, optional) – the end_train method which need at least recorders and experiment_name. Defaults to None for using self.end_train_func.
-
experiment_name (str) – the experiment name, None for use default name.
-
- has_worker() bool
-
Some trainer has backend worker to support parallel training This method can tell if the worker is enabled.
- Returns:
-
if the worker is enabled
- Return type:
-
bool
Collector
Collector module can collect objects from everywhere and process them such as merging, grouping, averaging and so on.
- classqlib.workflow.task.collect.Collector(process_list=[])
-
The collector to collect different results
- __init__(process_list=[])
-
Init Collector.
- Parameters:
-
process_list (list or Callable) – the list of processors or the instance of a processor to process dict.
- collect() dict
-
Collect the results and return a dict like {key: things}
- Returns:
-
the dict after collecting.
For example:
{“prediction”: pd.Series}
{“IC”: {“Xgboost”: pd.Series, “LSTM”: pd.Series}}
…
- Return type:
-
dict
- staticprocess_collect(collected_dict, process_list=[], *args, **kwargs) dict
-
Do a series of processing to the dict returned by collect and return a dict like {key: things} For example, you can group and ensemble.
- Parameters:
-
-
collected_dict (dict) – the dict return by collect
-
process_list (list or Callable) – the list of processors or the instance of a processor to process dict. The processor order is the same as the list order. For example: [Group1(…, Ensemble1()), Group2(…, Ensemble2())]
-
- Returns:
-
the dict after processing.
- Return type:
-
dict
- classqlib.workflow.task.collect.MergeCollector(collector_dict: Dict[str, Collector], process_list: List[Callable] = [], merge_func=None)
-
A collector to collect the results of other Collectors
For example:
We have 2 collector, which named A and B. A can collect {“prediction”: pd.Series} and B can collect {“IC”: {“Xgboost”: pd.Series, “LSTM”: pd.Series}}. Then after this class’s collect, we can collect {“A_prediction”: pd.Series, “B_IC”: {“Xgboost”: pd.Series, “LSTM”: pd.Series}}
…
- __init__(collector_dict: Dict[str, Collector], process_list: List[Callable] = [], merge_func=None)
-
Init MergeCollector.
- Parameters:
-
-
collector_dict (Dict[str,Collector]) – the dict like {collector_key, Collector}
-
process_list (List[Callable]) – the list of processors or the instance of processor to process dict.
-
merge_func (Callable) – a method to generate outermost key. The given params are
collector_keyfrom collector_dict andkeyfrom every collector after collecting. None for using tuple to connect them, such as “ABC”+(“a”,”b”) -> (“ABC”, (“a”,”b”)).
-
- collect() dict
-
Collect all results of collector_dict and change the outermost key to a recombination key.
- Returns:
-
the dict after collecting.
- Return type:
-
dict
- classqlib.workflow.task.collect.RecorderCollector(experiment, process_list=[], rec_key_func=None, rec_filter_func=None, artifacts_path={'pred': 'pred.pkl'}, artifacts_key=None, list_kwargs={}, status: Iterable = {'FINISHED'})
-
- __init__(experiment, process_list=[], rec_key_func=None, rec_filter_func=None, artifacts_path={'pred': 'pred.pkl'}, artifacts_key=None, list_kwargs={}, status: Iterable = {'FINISHED'})
-
Init RecorderCollector.
- Parameters:
-
-
experiment – (Experiment or str): an instance of an Experiment or the name of an Experiment (Callable): an callable function, which returns a list of experiments
-
process_list (list or Callable) – the list of processors or the instance of a processor to process dict.
-
rec_key_func (Callable) – a function to get the key of a recorder. If None, use recorder id.
-
rec_filter_func (Callable, optional) – filter the recorder by return True or False. Defaults to None.
-
artifacts_path (dict, optional) – The artifacts name and its path in Recorder. Defaults to {“pred”: “pred.pkl”, “IC”: “sig_analysis/ic.pkl”}.
-
artifacts_key (str or List, optional) – the artifacts key you want to get. If None, get all artifacts.
-
list_kwargs (str) – arguments for list_recorders function.
-
status (Iterable) – only collect recorders with specific status. None indicating collecting all the recorders
-
- collect(artifacts_key=None, rec_filter_func=None, only_exist=True) dict
-
Collect different artifacts based on recorder after filtering.
- Parameters:
-
-
artifacts_key (str or List, optional) – the artifacts key you want to get. If None, use the default.
-
rec_filter_func (Callable, optional) – filter the recorder by return True or False. If None, use the default.
-
only_exist (bool, optional) – if only collect the artifacts when a recorder really has. If True, the recorder with exception when loading will not be collected. But if False, it will raise the exception.
-
- Returns:
-
the dict after collected like {artifact: {rec_key: object}}
- Return type:
-
dict
- get_exp_name() str
-
Get experiment name
- Returns:
-
experiment name
- Return type:
-
str
Group
Group can group a set of objects based on group_func and change them to a dict. After group, we provide a method to reduce them.
For example:
group: {(A,B,C1): object, (A,B,C2): object} -> {(A,B): {C1: object, C2: object}} reduce: {(A,B): {C1: object, C2: object}} -> {(A,B): object}
- classqlib.model.ens.group.Group(group_func=None, ens: Ensemble | None = None)
-
Group the objects based on dict
- __init__(group_func=None, ens: Ensemble | None = None)
-
Init Group.
- Parameters:
-
-
group_func (Callable, optional) –
Given a dict and return the group key and one of the group elements.
For example: {(A,B,C1): object, (A,B,C2): object} -> {(A,B): {C1: object, C2: object}}
-
None. (Defaults to) –
-
ens (Ensemble, optional) – If not None, do ensemble for grouped value after grouping.
-
- group(*args, **kwargs) dict
-
Group a set of objects and change them to a dict.
For example: {(A,B,C1): object, (A,B,C2): object} -> {(A,B): {C1: object, C2: object}}
- Returns:
-
grouped dict
- Return type:
-
dict
- reduce(*args, **kwargs) dict
-
Reduce grouped dict.
For example: {(A,B): {C1: object, C2: object}} -> {(A,B): object}
- Returns:
-
reduced dict
- Return type:
-
dict
- classqlib.model.ens.group.RollingGroup(ens=<qlib.model.ens.ensemble.RollingEnsemble object>)
-
Group the rolling dict
- group(rolling_dict: dict) dict
-
Given an rolling dict likes {(A,B,R): things}, return the grouped dict likes {(A,B): {R:things}}
NOTE: There is an assumption which is the rolling key is at the end of the key tuple, because the rolling results always need to be ensemble firstly.
- Parameters:
-
rolling_dict (dict) – an rolling dict. If the key is not a tuple, then do nothing.
- Returns:
-
grouped dict
- Return type:
-
dict
- __init__(ens=<qlib.model.ens.ensemble.RollingEnsemble object>)
-
Init Group.
- Parameters:
-
-
group_func (Callable, optional) –
Given a dict and return the group key and one of the group elements.
For example: {(A,B,C1): object, (A,B,C2): object} -> {(A,B): {C1: object, C2: object}}
-
None. (Defaults to) –
-
ens (Ensemble, optional) – If not None, do ensemble for grouped value after grouping.
-
Ensemble
Ensemble module can merge the objects in an Ensemble. For example, if there are many submodels predictions, we may need to merge them into an ensemble prediction.
- classqlib.model.ens.ensemble.Ensemble
-
Merge the ensemble_dict into an ensemble object.
For example: {Rollinga_b: object, Rollingb_c: object} -> object
When calling this class:
- Args:
-
ensemble_dict (dict): the ensemble dict like {name: things} waiting for merging
- Returns:
-
object: the ensemble object
- classqlib.model.ens.ensemble.SingleKeyEnsemble
-
Extract the object if there is only one key and value in the dict. Make the result more readable. {Only key: Only value} -> Only value
If there is more than 1 key or less than 1 key, then do nothing. Even you can run this recursively to make dict more readable.
NOTE: Default runs recursively.
When calling this class:
- Args:
-
ensemble_dict (dict): the dict. The key of the dict will be ignored.
- Returns:
-
dict: the readable dict.
- classqlib.model.ens.ensemble.RollingEnsemble
-
Merge a dict of rolling dataframe like prediction or IC into an ensemble.
NOTE: The values of dict must be pd.DataFrame, and have the index “datetime”.
When calling this class:
- Args:
-
ensemble_dict (dict): a dict like {“A”: pd.DataFrame, “B”: pd.DataFrame}. The key of the dict will be ignored.
- Returns:
-
pd.DataFrame: the complete result of rolling.
- classqlib.model.ens.ensemble.AverageEnsemble
-
Average and standardize a dict of same shape dataframe like prediction or IC into an ensemble.
NOTE: The values of dict must be pd.DataFrame, and have the index “datetime”. If it is a nested dict, then flat it.
When calling this class:
- Args:
-
ensemble_dict (dict): a dict like {“A”: pd.DataFrame, “B”: pd.DataFrame}. The key of the dict will be ignored.
- Returns:
-
pd.DataFrame: the complete result of averaging and standardizing.
Utils
Some tools for task management.
- qlib.workflow.task.utils.get_mongodb() Database
-
Get database in MongoDB, which means you need to declare the address and the name of a database at first.
For example:
Using qlib.init():
mongo_conf = { "task_url": task_url, # your MongoDB url "task_db_name": task_db_name, # database name } qlib.init(..., mongo=mongo_conf)
After qlib.init():
C["mongo"] = { "task_url" : "mongodb://localhost:27017/", "task_db_name" : "rolling_db" }
- Returns:
-
the Database instance
- Return type:
-
Database
- qlib.workflow.task.utils.list_recorders(experiment, rec_filter_func=None)
-
List all recorders which can pass the filter in an experiment.
- Parameters:
-
-
experiment (str or Experiment) – the name of an Experiment or an instance
-
rec_filter_func (Callable, optional) – return True to retain the given recorder. Defaults to None.
-
- Returns:
-
a dict {rid: recorder} after filtering.
- Return type:
-
dict
- classqlib.workflow.task.utils.TimeAdjuster(future=True, end_time=None)
-
Find appropriate date and adjust date.
- __init__(future=True, end_time=None)
- set_end_time(end_time=None)
-
Set end time. None for use calendar’s end time.
- Parameters:
-
end_time –
- get(idx: int)
-
Get datetime by index.
- Parameters:
-
idx (int) – index of the calendar
- max() Timestamp
-
Return the max calendar datetime
- align_idx(time_point, tp_type='start') int
-
Align the index of time_point in the calendar.
- Parameters:
-
-
time_point –
-
tp_type (str) –
-
- Returns:
-
index
- Return type:
-
int
- cal_interval(time_point_A, time_point_B) int
-
Calculate the trading day interval (time_point_A - time_point_B)
- Parameters:
-
-
time_point_A – time_point_A
-
time_point_B – time_point_B (is the past of time_point_A)
-
- Returns:
-
the interval between A and B
- Return type:
-
int
- align_time(time_point, tp_type='start') Timestamp
-
Align time_point to trade date of calendar
- Parameters:
-
-
time_point – Time point
-
tp_type – str time point type (“start”, “end”)
-
- Returns:
-
pd.Timestamp
- align_seg(segment: dict | tuple) dict | tuple
-
Align the given date to the trade date
for example:
input: {'train': ('2008-01-01', '2014-12-31'), 'valid': ('2015-01-01', '2016-12-31'), 'test': ('2017-01-01', '2020-08-01')} output: {'train': (Timestamp('2008-01-02 00:00:00'), Timestamp('2014-12-31 00:00:00')), 'valid': (Timestamp('2015-01-05 00:00:00'), Timestamp('2016-12-30 00:00:00')), 'test': (Timestamp('2017-01-03 00:00:00'), Timestamp('2020-07-31 00:00:00'))}
- Parameters:
-
segment –
- Returns:
-
Union[dict, tuple]
- Return type:
-
the start and end trade date (pd.Timestamp) between the given start and end date.
- truncate(segment: tuple, test_start, days: int) tuple
-
Truncate the segment based on the test_start date
- Parameters:
-
-
segment (tuple) – time segment
-
test_start –
-
days (int) – The trading days to be truncated the data in this segment may need ‘days’ data days are based on the test_start. For example, if the label contains the information of 2 days in the near future, the prediction horizon 1 day. (e.g. the prediction target is Ref($close, -2)/Ref($close, -1) - 1) the days should be 2 + 1 == 3 days.
-
- Returns:
-
tuple
- Return type:
-
new segment
- shift(seg: tuple, step: int, rtype='sliding') tuple
-
Shift the datetime of segment
If there are None (which indicates unbounded index) in the segment, this method will return None.
- Parameters:
-
-
seg – datetime segment
-
step (int) – rolling step
-
rtype (str) – rolling type (“sliding” or “expanding”)
-
- Returns:
-
tuple
- Return type:
-
new segment
- Raises:
-
KeyError: – shift will raise error if the index(both start and end) is out of self.cal
- qlib.workflow.task.utils.replace_task_handler_with_cache(task: dict, cache_dir: str | Path = '.') dict
-
Replace the handler in task with a cache handler. It will automatically cache the file and save it in cache_dir.
import qlib qlib.auto_init() import datetime # it is simplified task task = {"dataset": {"kwargs":{'handler': {'class': 'Alpha158', 'module_path': 'qlib.contrib.data.handler', 'kwargs': {'start_time': datetime.date(2008, 1, 1), 'end_time': datetime.date(2020, 8, 1), 'fit_start_time': datetime.date(2008, 1, 1), 'fit_end_time': datetime.date(2014, 12, 31), 'instruments': 'CSI300'}}}}} new_task = replace_task_handler_with_cache(task) print(new_task) {'dataset': {'kwargs': {'handler': 'file...Alpha158.3584f5f8b4.pkl'}}}
Online Serving
Online Manager
OnlineManager can manage a set of Online Strategy and run them dynamically.
With the change of time, the decisive models will be also changed. In this module, we call those contributing models online models. In every routine(such as every day or every minute), the online models may be changed and the prediction of them needs to be updated. So this module provides a series of methods to control this process.
This module also provides a method to simulate Online Strategy in history. Which means you can verify your strategy or find a better one.
There are 4 total situations for using different trainers in different situations:
Situations
Description
Online + Trainer
When you want to do a REAL routine, the Trainer will help you train the models. It will train models task by task and strategy by strategy.
Online + DelayTrainer
DelayTrainer will skip concrete training until all tasks have been prepared by different strategies. It makes users can parallelly train all tasks at the end of routine or first_train. Otherwise, these functions will get stuck when each strategy prepare tasks.
Simulation + Trainer
It will behave in the same way as Online + Trainer. The only difference is that it is for simulation/backtesting instead of online trading
Simulation + DelayTrainer
When your models don’t have any temporal dependence, you can use DelayTrainer for the ability to multitasking. It means all tasks in all routines can be REAL trained at the end of simulating. The signals will be prepared well at different time segments (based on whether or not any new model is online).
Here is some pseudo code that demonstrate the workflow of each situation
- For simplicity
-
-
Only one strategy is used in the strategy
-
update_online_pred is only called in the online mode and is ignored
-
-
Online + Trainer
tasks = first_train() models = trainer.train(tasks) trainer.end_train(models) for day in online_trading_days: # OnlineManager.routine models = trainer.train(strategy.prepare_tasks()) # for each strategy strategy.prepare_online_models(models) # for each strategy trainer.end_train(models) prepare_signals() # prepare trading signals daily
Online + DelayTrainer: the workflow is the same as Online + Trainer.
-
Simulation + DelayTrainer
# simulate tasks = first_train() models = trainer.train(tasks) for day in historical_calendars: # OnlineManager.routine models = trainer.train(strategy.prepare_tasks()) # for each strategy strategy.prepare_online_models(models) # for each strategy # delay_prepare() # FIXME: Currently the delay_prepare is not implemented in a proper way. trainer.end_train(<for all previous models>) prepare_signals()
# Can we simplify current workflow?
-
Can reduce the number of state of tasks?
-
For each task, we have three phases (i.e. task, partly trained task, final trained task)
-
- classqlib.workflow.online.manager.OnlineManager(strategies: OnlineStrategy | List[OnlineStrategy], trainer: Trainer | None = None, begin_time: str | Timestamp | None = None, freq='day')
-
OnlineManager can manage online models with Online Strategy. It also provides a history recording of which models are online at what time.
- __init__(strategies: OnlineStrategy | List[OnlineStrategy], trainer: Trainer | None = None, begin_time: str | Timestamp | None = None, freq='day')
-
Init OnlineManager. One OnlineManager must have at least one OnlineStrategy.
- Parameters:
-
-
strategies (Union[OnlineStrategy, List[OnlineStrategy]]) – an instance of OnlineStrategy or a list of OnlineStrategy
-
begin_time (Union[str,pd.Timestamp], optional) – the OnlineManager will begin at this time. Defaults to None for using the latest date.
-
trainer (qlib.model.trainer.Trainer) – the trainer to train task. None for using TrainerR.
-
freq (str, optional) – data frequency. Defaults to “day”.
-
- first_train(strategies: List[OnlineStrategy] | None = None, model_kwargs: dict = {})
-
Get tasks from every strategy’s first_tasks method and train them. If using DelayTrainer, it can finish training all together after every strategy’s first_tasks.
- Parameters:
-
-
strategies (List[OnlineStrategy]) – the strategies list (need this param when adding strategies). None for use default strategies.
-
model_kwargs (dict) – the params for prepare_online_models
-
- routine(cur_time: str | Timestamp | None = None, task_kwargs: dict = {}, model_kwargs: dict = {}, signal_kwargs: dict = {})
-
Typical update process for every strategy and record the online history.
The typical update process after a routine, such as day by day or month by month. The process is: Update predictions -> Prepare tasks -> Prepare online models -> Prepare signals.
If using DelayTrainer, it can finish training all together after every strategy’s prepare_tasks.
- Parameters:
-
-
cur_time (Union[str,pd.Timestamp], optional) – run routine method in this time. Defaults to None.
-
task_kwargs (dict) – the params for prepare_tasks
-
model_kwargs (dict) – the params for prepare_online_models
-
signal_kwargs (dict) – the params for prepare_signals
-
- get_collector(**kwargs) MergeCollector
-
Get the instance of Collector to collect results from every strategy. This collector can be a basis as the signals preparation.
- Parameters:
-
**kwargs – the params for get_collector.
- Returns:
-
the collector to merge other collectors.
- Return type:
- add_strategy(strategies: OnlineStrategy | List[OnlineStrategy])
-
Add some new strategies to OnlineManager.
- Parameters:
-
strategy (Union[OnlineStrategy, List[OnlineStrategy]]) – a list of OnlineStrategy
- prepare_signals(prepare_func: ~typing.Callable = <qlib.model.ens.ensemble.AverageEnsemble object>, over_write=False)
-
After preparing the data of the last routine (a box in box-plot) which means the end of the routine, we can prepare trading signals for the next routine.
NOTE: Given a set prediction, all signals before these prediction end times will be prepared well.
Even if the latest signal already exists, the latest calculation result will be overwritten.
Note
Given a prediction of a certain time, all signals before this time will be prepared well.
- Parameters:
-
-
prepare_func (Callable, optional) – Get signals from a dict after collecting. Defaults to AverageEnsemble(), the results collected by MergeCollector must be {xxx:pred}.
-
over_write (bool, optional) – If True, the new signals will overwrite. If False, the new signals will append to the end of signals. Defaults to False.
-
- Returns:
-
the signals.
- Return type:
-
pd.DataFrame
- get_signals() Series | DataFrame
-
Get prepared online signals.
- Returns:
-
pd.Series for only one signals every datetime. pd.DataFrame for multiple signals, for example, buy and sell operations use different trading signals.
- Return type:
-
Union[pd.Series, pd.DataFrame]
- simulate(end_time=None, frequency='day', task_kwargs={}, model_kwargs={}, signal_kwargs={}) Series | DataFrame
-
Starting from the current time, this method will simulate every routine in OnlineManager until the end time.
Considering the parallel training, the models and signals can be prepared after all routine simulating.
The delay training way can be
DelayTrainerand the delay preparing signals way can bedelay_prepare.- Parameters:
-
-
end_time – the time the simulation will end
-
frequency – the calendar frequency
-
task_kwargs (dict) – the params for prepare_tasks
-
model_kwargs (dict) – the params for prepare_online_models
-
signal_kwargs (dict) – the params for prepare_signals
-
- Returns:
-
pd.Series for only one signals every datetime. pd.DataFrame for multiple signals, for example, buy and sell operations use different trading signals.
- Return type:
-
Union[pd.Series, pd.DataFrame]
- delay_prepare(model_kwargs={}, signal_kwargs={})
-
Prepare all models and signals if something is waiting for preparation.
- Parameters:
-
-
model_kwargs – the params for end_train
-
signal_kwargs – the params for prepare_signals
-
Online Strategy
OnlineStrategy module is an element of online serving.
- classqlib.workflow.online.strategy.OnlineStrategy(name_id: str)
-
OnlineStrategy is working with Online Manager, responding to how the tasks are generated, the models are updated and signals are prepared.
- __init__(name_id: str)
-
Init OnlineStrategy. This module MUST use Trainer to finishing model training.
- Parameters:
-
-
name_id (str) – a unique name or id.
-
trainer (qlib.model.trainer.Trainer, optional) – a instance of Trainer. Defaults to None.
-
- prepare_tasks(cur_time, **kwargs) List[dict]
-
After the end of a routine, check whether we need to prepare and train some new tasks based on cur_time (None for latest).. Return the new tasks waiting for training.
You can find the last online models by OnlineTool.online_models.
- prepare_online_models(trained_models, cur_time=None) List[object]
-
Select some models from trained models and set them to online models. This is a typical implementation to online all trained models, you can override it to implement the complex method. You can find the last online models by OnlineTool.online_models if you still need them.
NOTE: Reset all online models to trained models. If there are no trained models, then do nothing.
- NOTE:
-
Current implementation is very naive. Here is a more complex situation which is more closer to the practical scenarios. 1. Train new models at the day before test_start (at time stamp T) 2. Switch models at the test_start (at time timestamp T + 1 typically)
- Parameters:
-
-
models (list) – a list of models.
-
cur_time (pd.Dataframe) – current time from OnlineManger. None for the latest.
-
- Returns:
-
a list of online models.
- Return type:
-
List[object]
- first_tasks() List[dict]
-
Generate a series of tasks firstly and return them.
- classqlib.workflow.online.strategy.RollingStrategy(name_id: str, task_template: dict | List[dict], rolling_gen: RollingGen)
-
This example strategy always uses the latest rolling model sas online models.
- __init__(name_id: str, task_template: dict | List[dict], rolling_gen: RollingGen)
-
Init RollingStrategy.
Assumption: the str of name_id, the experiment name, and the trainer’s experiment name are the same.
- Parameters:
-
-
name_id (str) – a unique name or id. Will be also the name of the Experiment.
-
task_template (Union[dict, List[dict]]) – a list of task_template or a single template, which will be used to generate many tasks using rolling_gen.
-
rolling_gen (RollingGen) – an instance of RollingGen
-
- get_collector(process_list=[<qlib.model.ens.group.RollingGroup object>], rec_key_func=None, rec_filter_func=None, artifacts_key=None)
-
Get the instance of Collector to collect results. The returned collector must distinguish results in different models.
Assumption: the models can be distinguished based on the model name and rolling test segments. If you do not want this assumption, please implement your method or use another rec_key_func.
- Parameters:
-
-
rec_key_func (Callable) – a function to get the key of a recorder. If None, use recorder id.
-
rec_filter_func (Callable, optional) – filter the recorder by return True or False. Defaults to None.
-
artifacts_key (List[str], optional) – the artifacts key you want to get. If None, get all artifacts.
-
- first_tasks() List[dict]
-
Use rolling_gen to generate different tasks based on task_template.
- Returns:
-
a list of tasks
- Return type:
-
List[dict]
- prepare_tasks(cur_time) List[dict]
-
Prepare new tasks based on cur_time (None for the latest).
You can find the last online models by OnlineToolR.online_models.
- Returns:
-
a list of new tasks.
- Return type:
-
List[dict]
Online Tool
OnlineTool is a module to set and unset a series of online models. The online models are some decisive models in some time points, which can be changed with the change of time. This allows us to use efficient submodels as the market-style changing.
- classqlib.workflow.online.utils.OnlineTool
-
OnlineTool will manage online models in an experiment that includes the model recorders.
- __init__()
-
Init OnlineTool.
- set_online_tag(tag, recorder: list | object)
-
Set tag to the model to sign whether online.
- Parameters:
-
-
tag (str) – the tags in ONLINE_TAG, OFFLINE_TAG
-
recorder (Union[list,object]) – the model’s recorder
-
- get_online_tag(recorder: object) str
-
Given a model recorder and return its online tag.
- Parameters:
-
recorder (Object) – the model’s recorder
- Returns:
-
the online tag
- Return type:
-
str
- reset_online_tag(recorder: list | object)
-
Offline all models and set the recorders to ‘online’.
- Parameters:
-
recorder (Union[list,object]) – the recorder you want to reset to ‘online’.
- online_models() list
-
Get current online models
- Returns:
-
a list of online models.
- Return type:
-
list
- update_online_pred(to_date=None)
-
Update the predictions of online models to to_date.
- Parameters:
-
to_date (pd.Timestamp) – the pred before this date will be updated. None for updating to the latest.
- classqlib.workflow.online.utils.OnlineToolR(default_exp_name: str | None = None)
-
The implementation of OnlineTool based on (R)ecorder.
- __init__(default_exp_name: str | None = None)
-
Init OnlineToolR.
- Parameters:
-
default_exp_name (str) – the default experiment name.
- set_online_tag(tag, recorder: Recorder | List)
-
Set tag to the model’s recorder to sign whether online.
- Parameters:
-
-
tag (str) – the tags in ONLINE_TAG, NEXT_ONLINE_TAG, OFFLINE_TAG
-
recorder (Union[Recorder, List]) – a list of Recorder or an instance of Recorder
-
- get_online_tag(recorder: Recorder) str
-
Given a model recorder and return its online tag.
- Parameters:
-
recorder (Recorder) – an instance of recorder
- Returns:
-
the online tag
- Return type:
-
str
- reset_online_tag(recorder: Recorder | List, exp_name: str | None = None)
-
Offline all models and set the recorders to ‘online’.
- Parameters:
-
-
recorder (Union[Recorder, List]) – the recorder you want to reset to ‘online’.
-
exp_name (str) – the experiment name. If None, then use default_exp_name.
-
- online_models(exp_name: str | None = None) list
-
Get current online models
- Parameters:
-
exp_name (str) – the experiment name. If None, then use default_exp_name.
- Returns:
-
a list of online models.
- Return type:
-
list
- update_online_pred(to_date=None, from_date=None, exp_name: str | None = None)
-
Update the predictions of online models to to_date.
- Parameters:
-
-
to_date (pd.Timestamp) – the pred before this date will be updated. None for updating to latest time in Calendar.
-
exp_name (str) – the experiment name. If None, then use default_exp_name.
-
RecordUpdater
Updater is a module to update artifacts such as predictions when the stock data is updating.
- classqlib.workflow.online.update.RMDLoader(rec: Recorder)
-
Recorder Model Dataset Loader
- __init__(rec: Recorder)
- get_dataset(start_time, end_time, segments=None, unprepared_dataset: DatasetH | None = None) DatasetH
-
Load, config and setup dataset.
This dataset is for inference.
- Parameters:
-
-
start_time – the start_time of underlying data
-
end_time – the end_time of underlying data
-
segments – dict the segments config for dataset Due to the time series dataset (TSDatasetH), the test segments maybe different from start_time and end_time
-
unprepared_dataset – Optional[DatasetH] if user don’t want to load dataset from recorder, please specify user’s dataset
-
- Returns:
-
the instance of DatasetH
- Return type:
- classqlib.workflow.online.update.RecordUpdater(record: Recorder, *args, **kwargs)
-
Update a specific recorders
- __init__(record: Recorder, *args, **kwargs)
- abstractupdate(*args, **kwargs)
-
Update info for specific recorder
- classqlib.workflow.online.update.DSBasedUpdater(record: ~qlib.workflow.recorder.Recorder, to_date=None, from_date=None, hist_ref: int | None = None, freq='day', fname='pred.pkl', loader_cls: type = <class 'qlib.workflow.online.update.RMDLoader'>)
-
Dataset-Based Updater
-
Providing updating feature for Updating data based on Qlib Dataset
Assumption
-
Based on Qlib dataset
-
The data to be updated is a multi-level index pd.DataFrame. For example label, prediction.
LABEL0 datetime instrument 2021-05-10 SH600000 0.006965 SH600004 0.003407 ... ... 2021-05-28 SZ300498 0.015748 SZ300676 -0.001321
- __init__(record: ~qlib.workflow.recorder.Recorder, to_date=None, from_date=None, hist_ref: int | None = None, freq='day', fname='pred.pkl', loader_cls: type = <class 'qlib.workflow.online.update.RMDLoader'>)
-
Init PredUpdater.
Expected behavior in following cases:
-
if to_date is greater than the max date in the calendar, the data will be updated to the latest date
-
if there are data before from_date or after to_date, only the data between from_date and to_date are affected.
- Parameters:
-
-
record – Recorder
-
to_date –
update to prediction to the to_date
if to_date is None:
data will updated to the latest date.
-
from_date –
the update will start from from_date
if from_date is None:
the updating will occur on the next tick after the latest data in historical data
-
hist_ref –
int Sometimes, the dataset will have historical depends. Leave the problem to users to set the length of historical dependency If user doesn’t specify this parameter, Updater will try to load dataset to automatically determine the hist_ref
Note
the start_time is not included in the hist_ref; So the hist_ref will be step_len - 1 in most cases
-
loader_cls – type the class to load the model and dataset
-
-
- prepare_data(unprepared_dataset: DatasetH | None = None) DatasetH
-
Load dataset - if unprepared_dataset is specified, then prepare the dataset directly - Otherwise,
Separating this function will make it easier to reuse the dataset
- Returns:
-
the instance of DatasetH
- Return type:
- update(dataset: DatasetH | None = None, write: bool = True, ret_new: bool = False) object | None
-
- Parameters:
-
-
dataset (DatasetH) – DatasetH: the instance of DatasetH. None for prepare it again.
-
write (bool) – will the the write action be executed
-
ret_new (bool) – will the updated data be returned
-
- Returns:
-
the updated dataset
- Return type:
-
Optional[object]
- abstractget_update_data(dataset: Dataset) DataFrame
-
return the updated data based on the given dataset
The difference between get_update_data and update - update_date only include some data specific feature - update include some general routine steps(e.g. prepare dataset, checking)
-
- classqlib.workflow.online.update.PredUpdater(record: ~qlib.workflow.recorder.Recorder, to_date=None, from_date=None, hist_ref: int | None = None, freq='day', fname='pred.pkl', loader_cls: type = <class 'qlib.workflow.online.update.RMDLoader'>)
-
Update the prediction in the Recorder
- get_update_data(dataset: Dataset) DataFrame
-
return the updated data based on the given dataset
The difference between get_update_data and update - update_date only include some data specific feature - update include some general routine steps(e.g. prepare dataset, checking)
- classqlib.workflow.online.update.LabelUpdater(record: Recorder, to_date=None, **kwargs)
-
Update the label in the recorder
Assumption - The label is generated from record_temp.SignalRecord.
- __init__(record: Recorder, to_date=None, **kwargs)
-
Init PredUpdater.
Expected behavior in following cases:
-
if to_date is greater than the max date in the calendar, the data will be updated to the latest date
-
if there are data before from_date or after to_date, only the data between from_date and to_date are affected.
- Parameters:
-
-
record – Recorder
-
to_date –
update to prediction to the to_date
if to_date is None:
data will updated to the latest date.
-
from_date –
the update will start from from_date
if from_date is None:
the updating will occur on the next tick after the latest data in historical data
-
hist_ref –
int Sometimes, the dataset will have historical depends. Leave the problem to users to set the length of historical dependency If user doesn’t specify this parameter, Updater will try to load dataset to automatically determine the hist_ref
Note
the start_time is not included in the hist_ref; So the hist_ref will be step_len - 1 in most cases
-
loader_cls – type the class to load the model and dataset
-
-
- get_update_data(dataset: Dataset) DataFrame
-
return the updated data based on the given dataset
The difference between get_update_data and update - update_date only include some data specific feature - update include some general routine steps(e.g. prepare dataset, checking)
Utils
Serializable
- classqlib.utils.serial.Serializable
-
Serializable will change the behaviors of pickle.
The rule to tell if a attribute will be kept or dropped when dumping. The rule with higher priorities is on the top - in the config attribute list -> always dropped - in the include attribute list -> always kept - in the exclude attribute list -> always dropped - name not starts with _ -> kept - name starts with _ -> kept if dump_all is true else dropped
It provides a syntactic sugar for distinguish the attributes which user doesn’t want. - For examples, a learnable Datahandler just wants to save the parameters without data when dumping to disk
- __init__()
- propertydump_all
-
will the object dump all object
- config(recursive=False, **kwargs)
-
configure the serializable object
- Parameters:
-
-
keys (kwargs may include following) –
- dump_allbool
-
will the object dump all object
- excludelist
-
What attribute will not be dumped
- includelist
-
What attribute will be dumped
-
recursive (bool) – will the configuration be recursive
-
- to_pickle(path: Path | str, **kwargs)
-
Dump self to a pickle file.
path (Union[Path, str]): the path to dump
kwargs may include following keys
- dump_allbool
-
will the object dump all object
- excludelist
-
What attribute will not be dumped
- includelist
-
What attribute will be dumped
- classmethodload(filepath)
-
Load the serializable class from a filepath.
- Parameters:
-
filepath (str) – the path of file
- Raises:
-
TypeError – the pickled file must be type(cls)
- Returns:
-
the instance of type(cls)
- Return type:
-
type(cls)
- classmethodget_backend()
-
Return the real backend of a Serializable class. The pickle_backend value can be “pickle” or “dill”.
- Returns:
-
pickle or dill module based on pickle_backend
- Return type:
-
module
- staticgeneral_dump(obj, path: Path | str)
-
A general dumping method for object
- Parameters:
-
-
obj (object) – the object to be dumped
-
path (Union[Path, str]) – the target path the data will be dumped
-
RL
Base Component
- classqlib.rl.Interpreter
-
Interpreter is a media between states produced by simulators and states needed by RL policies. Interpreters are two-way:
-
From simulator state to policy state (aka observation), see
StateInterpreter. -
From policy action to action accepted by simulator, see
ActionInterpreter.
Inherit one of the two sub-classes to define your own interpreter. This super-class is only used for isinstance check.
Interpreters are recommended to be stateless, meaning that storing temporary information with
self.xxxin interpreter is anti-pattern. In future, we might support register some interpreter-related states by callingself.env.register_state(), but it’s not planned for first iteration. -
- classqlib.rl.StateInterpreter(*args, **kwds)
-
State Interpreter that interpret execution result of qlib executor into rl env state
- validate(obs: ObsType) None
-
Validate whether an observation belongs to the pre-defined observation space.
- interpret(simulator_state: StateType) ObsType
-
Interpret the state of simulator.
- Parameters:
-
simulator_state – Retrieved with
simulator.get_state(). - Return type:
-
State needed by policy. Should conform with the state space defined in
observation_space.
- classqlib.rl.ActionInterpreter(*args, **kwds)
-
Action Interpreter that interpret rl agent action into qlib orders
- validate(action: PolicyActType) None
-
Validate whether an action belongs to the pre-defined action space.
- interpret(simulator_state: StateType, action: PolicyActType) ActType
-
Convert the policy action to simulator action.
- Parameters:
-
-
simulator_state – Retrieved with
simulator.get_state(). -
action – Raw action given by policy.
-
- Return type:
-
The action needed by simulator,
- classqlib.rl.Reward(*args, **kwds)
-
Reward calculation component that takes a single argument: state of simulator. Returns a real number: reward.
Subclass should implement
reward(simulator_state)to implement their own reward calculation recipe.- reward(simulator_state: SimulatorState) float
-
Implement this method for your own reward.
- classqlib.rl.RewardCombination(rewards: Dict[str, Tuple[Reward, float]])
-
Combination of multiple reward.
- __init__(rewards: Dict[str, Tuple[Reward, float]]) None
- reward(simulator_state: Any) float
-
Implement this method for your own reward.
- classqlib.rl.Simulator(initial: InitialStateType, **kwargs: Any)
-
Simulator that resets with
__init__, and transits withstep(action).To make the data-flow clear, we make the following restrictions to Simulator:
-
The only way to modify the inner status of a simulator is by using
step(action). -
External modules can read the status of a simulator by using
simulator.get_state(), and check whether the simulator is in the ending state by callingsimulator.done().
A simulator is defined to be bounded with three types:
-
InitialStateType that is the type of the data used to create the simulator.
-
StateType that is the type of the status (state) of the simulator.
-
ActType that is the type of the action, which is the input received in each step.
Different simulators might share the same StateType. For example, when they are dealing with the same task, but with different simulation implementation. With the same type, they can safely share other components in the MDP.
Simulators are ephemeral. The lifecycle of a simulator starts with an initial state, and ends with the trajectory. In another word, when the trajectory ends, simulator is recycled. If simulators want to share context between (e.g., for speed-up purposes), this could be done by accessing the weak reference of environment wrapper.
- env
-
A reference of env-wrapper, which could be useful in some corner cases. Simulators are discouraged to use this, because it’s prone to induce errors.
- Type:
-
Optional[EnvWrapper]
- __init__(initial: InitialStateType, **kwargs: Any) None
- step(action: ActType) None
-
Receives an action of ActType.
Simulator should update its internal state, and return None. The updated state can be retrieved with
simulator.get_state().
- done() bool
-
Check whether the simulator is in a “done” state. When simulator is in a “done” state, it should no longer receives any
steprequest. As simulators are ephemeral, to reset the simulator, the old one should be destroyed and a new simulator can be created.
-
Strategy
- classqlib.rl.strategy.SingleOrderStrategy(order: Order, trade_range: TradeRange | None = None)
-
Strategy used to generate a trade decision with exactly one order.
- __init__(order: Order, trade_range: TradeRange | None = None) None
-
- Parameters:
-
-
outer_trade_decision (BaseTradeDecision, optional) –
the trade decision of outer strategy which this strategy relies, and it will be traded in [start_time, end_time], by default None
-
If the strategy is used to split trade decision, it will be used
-
If the strategy is used for portfolio management, it can be ignored
-
-
level_infra (LevelInfrastructure, optional) – level shared infrastructure for backtesting, including trade calendar
-
common_infra (CommonInfrastructure, optional) – common infrastructure for backtesting, including trade_account, trade_exchange, .etc
-
trade_exchange (Exchange) –
exchange that provides market info, used to deal order and generate report
-
If trade_exchange is None, self.trade_exchange will be set with common_infra
-
It allows different trade_exchanges is used in different executions.
-
For example:
-
In daily execution, both daily exchange and minutely are usable, but the daily exchange is recommended because it run faster.
-
In minutely execution, the daily exchange is not usable, only the minutely exchange is recommended.
-
-
-
- generate_trade_decision(execute_result: list | None = None) TradeDecisionWO
-
Generate trade decision in each trading bar
- Parameters:
-
execute_result (List[object], optional) –
the executed result for trade decision, by default None
-
When call the generate_trade_decision firstly, execute_result could be None
-
Trainer
Train, test, inference utilities.
- classqlib.rl.trainer.Trainer(*, max_iters: int | None = None, val_every_n_iters: int | None = None, loggers: LogWriter | List[LogWriter] | None = None, callbacks: List[Callback] | None = None, finite_env_type: FiniteEnvType = 'subproc', concurrency: int = 2, fast_dev_run: int | None = None)
-
Utility to train a policy on a particular task.
Different from traditional DL trainer, the iteration of this trainer is “collect”, rather than “epoch”, or “mini-batch”. In each collect,
Collectorcollects a number of policy-env interactions, and accumulates them into a replay buffer. This buffer is used as the “data” to train the policy. At the end of each collect, the policy is updated several times.The API has some resemblence with PyTorch Lightning, but it’s essentially different because this trainer is built for RL applications, and thus most configurations are under RL context. We are still looking for ways to incorporate existing trainer libraries, because it looks like big efforts to build a trainer as powerful as those libraries, and also, that’s not our primary goal.
It’s essentially different tianshou’s built-in trainers, as it’s far much more complicated than that.
- Parameters:
-
-
max_iters – Maximum iterations before stopping.
-
val_every_n_iters – Perform validation every n iterations (i.e., training collects).
-
logger – Logger to record the backtest results. Logger must be present because without logger, all information will be lost.
-
finite_env_type – Type of finite env implementation.
-
concurrency – Parallel workers.
-
fast_dev_run – Create a subset for debugging. How this is implemented depends on the implementation of training vessel. For
TrainingVessel, if greater than zero, a random subset sizedfast_dev_runwill be used instead oftrain_initial_statesandval_initial_states.
-
- should_stop: bool
-
Set to stop the training.
- metrics: dict
-
Numeric metrics of produced in train/val/test. In the middle of training / validation, metrics will be of the latest episode. When each iteration of training / validation finishes, metrics will be the aggregation of all episodes encountered in this iteration.
Cleared on every new iteration of training.
In fit, validation metrics will be prefixed with
val/.
- current_iter: int
-
Current iteration (collect) of training.
- __init__(*, max_iters: int | None = None, val_every_n_iters: int | None = None, loggers: LogWriter | List[LogWriter] | None = None, callbacks: List[Callback] | None = None, finite_env_type: FiniteEnvType = 'subproc', concurrency: int = 2, fast_dev_run: int | None = None)
- loggers: List[LogWriter]
-
A list of log writers.
- initialize()
-
Initialize the whole training process.
The states here should be synchronized with state_dict.
- initialize_iter()
-
Initialize one iteration / collect.
- state_dict() dict
-
Putting every states of current training into a dict, at best effort.
It doesn’t try to handle all the possible kinds of states in the middle of one training collect. For most cases at the end of each iteration, things should be usually correct.
Note that it’s also intended behavior that replay buffer data in the collector will be lost.
- load_state_dict(state_dict: dict) None
-
Load all states into current trainer.
- named_callbacks() Dict[str, Callback]
-
Retrieve a collection of callbacks where each one has a name. Useful when saving checkpoints.
- named_loggers() Dict[str, LogWriter]
-
Retrieve a collection of loggers where each one has a name. Useful when saving checkpoints.
- fit(vessel: TrainingVesselBase, ckpt_path: Path | None = None) None
-
Train the RL policy upon the defined simulator.
- Parameters:
-
-
vessel – A bundle of all elements used in training.
-
ckpt_path – Load a pre-trained / paused training checkpoint.
-
- test(vessel: TrainingVesselBase) None
-
Test the RL policy against the simulator.
The simulator will be fed with data generated in
test_seed_iterator.- Parameters:
-
vessel – A bundle of all related elements.
- venv_from_iterator(iterator: Iterable[InitialStateType]) FiniteVectorEnv
-
Create a vectorized environment from iterator and the training vessel.
- classqlib.rl.trainer.TrainingVessel(*, simulator_fn: Callable[[InitialStateType], Simulator[InitialStateType, StateType, ActType]], state_interpreter: StateInterpreter[StateType, ObsType], action_interpreter: ActionInterpreter[StateType, PolicyActType, ActType], policy: BasePolicy, reward: Reward, train_initial_states: Sequence[InitialStateType] | None = None, val_initial_states: Sequence[InitialStateType] | None = None, test_initial_states: Sequence[InitialStateType] | None = None, buffer_size: int = 20000, episode_per_iter: int = 1000, update_kwargs: Dict[str, Any] = None)
-
The default implementation of training vessel.
__init__accepts a sequence of initial states so that iterator can be created.train,validate,testeach do one collect (and also update in train). By default, the train initial states will be repeated infinitely during training, and collector will control the number of episodes for each iteration. In validation and testing, the val / test initial states will be used exactly once.Extra hyper-parameters (only used in train) include:
-
buffer_size: Size of replay buffer. -
episode_per_iter: Episodes per collect at training. Can be overridden by fast dev run. -
update_kwargs: Keyword arguments appearing inpolicy.update. For example,dict(repeat=10, batch_size=64).
- __init__(*, simulator_fn: Callable[[InitialStateType], Simulator[InitialStateType, StateType, ActType]], state_interpreter: StateInterpreter[StateType, ObsType], action_interpreter: ActionInterpreter[StateType, PolicyActType, ActType], policy: BasePolicy, reward: Reward, train_initial_states: Sequence[InitialStateType] | None = None, val_initial_states: Sequence[InitialStateType] | None = None, test_initial_states: Sequence[InitialStateType] | None = None, buffer_size: int = 20000, episode_per_iter: int = 1000, update_kwargs: Dict[str, Any] = None)
- train_seed_iterator() ContextManager[Iterable[InitialStateType]] | Iterable[InitialStateType]
-
Override this to create a seed iterator for training. If the iterable is a context manager, the whole training will be invoked in the with-block, and the iterator will be automatically closed after the training is done.
- val_seed_iterator() ContextManager[Iterable[InitialStateType]] | Iterable[InitialStateType]
-
Override this to create a seed iterator for validation.
- test_seed_iterator() ContextManager[Iterable[InitialStateType]] | Iterable[InitialStateType]
-
Override this to create a seed iterator for testing.
- train(vector_env: FiniteVectorEnv) Dict[str, Any]
-
Create a collector and collects
episode_per_iterepisodes. Update the policy on the collected replay buffer.
- validate(vector_env: FiniteVectorEnv) Dict[str, Any]
-
Implement this to validate the policy once.
- test(vector_env: FiniteVectorEnv) Dict[str, Any]
-
Implement this to evaluate the policy on test environment once.
-
- classqlib.rl.trainer.TrainingVesselBase(*args, **kwds)
-
A ship that contains simulator, interpreter, and policy, will be sent to trainer. This class controls algorithm-related parts of training, while trainer is responsible for runtime part.
The ship also defines the most important logic of the core training part, and (optionally) some callbacks to insert customized logics at specific events.
- train_seed_iterator() ContextManager[Iterable[InitialStateType]] | Iterable[InitialStateType]
-
Override this to create a seed iterator for training. If the iterable is a context manager, the whole training will be invoked in the with-block, and the iterator will be automatically closed after the training is done.
- val_seed_iterator() ContextManager[Iterable[InitialStateType]] | Iterable[InitialStateType]
-
Override this to create a seed iterator for validation.
- test_seed_iterator() ContextManager[Iterable[InitialStateType]] | Iterable[InitialStateType]
-
Override this to create a seed iterator for testing.
- train(vector_env: BaseVectorEnv) Dict[str, Any]
-
Implement this to train one iteration. In RL, one iteration usually refers to one collect.
- validate(vector_env: FiniteVectorEnv) Dict[str, Any]
-
Implement this to validate the policy once.
- test(vector_env: FiniteVectorEnv) Dict[str, Any]
-
Implement this to evaluate the policy on test environment once.
- state_dict() Dict
-
Return a checkpoint of current vessel state.
- load_state_dict(state_dict: Dict) None
-
Restore a checkpoint from a previously saved state dict.
- classqlib.rl.trainer.Checkpoint(dirpath: Path, filename: str = '{iter:03d}.pth', save_latest: Literal['link', 'copy'] | None = 'link', every_n_iters: int | None = None, time_interval: int | None = None, save_on_fit_end: bool = True)
-
Save checkpoints periodically for persistence and recovery.
- Parameters:
-
-
dirpath – Directory to save the checkpoint file.
-
filename –
Checkpoint filename. Can contain named formatting options to be auto-filled. For example:
{iter:03d}-{reward:.2f}.pth. Supported argument names are:-
iter (int)
-
metrics in
trainer.metrics -
time string, in the format of
%Y%m%d%H%M%S
-
-
save_latest – Save the latest checkpoint in
latest.pth. Iflink,latest.pthwill be created as a softlink. Ifcopy,latest.pthwill be stored as an individual copy. Set to none to disable this. -
every_n_iters – Checkpoints are saved at the end of every n iterations of training, after validation if applicable.
-
time_interval – Maximum time (seconds) before checkpoints save again.
-
save_on_fit_end – Save one last checkpoint at the end to fit. Do nothing if a checkpoint is already saved there.
-
- __init__(dirpath: Path, filename: str = '{iter:03d}.pth', save_latest: Literal['link', 'copy'] | None = 'link', every_n_iters: int | None = None, time_interval: int | None = None, save_on_fit_end: bool = True)
- on_fit_end(trainer: Trainer, vessel: TrainingVesselBase) None
-
Called after the whole fit process ends.
- on_iter_end(trainer: Trainer, vessel: TrainingVesselBase) None
-
Called upon every end of iteration. This is called after the bump of
current_iter, when the previous iteration is considered complete.
- classqlib.rl.trainer.EarlyStopping(monitor: str = 'reward', min_delta: float = 0.0, patience: int = 0, mode: Literal['min', 'max'] = 'max', baseline: float | None = None, restore_best_weights: bool = False)
-
Stop training when a monitored metric has stopped improving.
The earlystopping callback will be triggered each time validation ends. It will examine the metrics produced in validation, and get the metric with name
monitor` (``monitorisrewardby default), to check whether it’s no longer increasing / decreasing. It takesmin_deltaandpatienceif applicable. If it’s found to be not increasing / decreasing any more.trainer.should_stopwill be set to true, and the training terminates.Implementation reference: https://github.com/keras-team/keras/blob/v2.9.0/keras/callbacks.py#L1744-L1893
- __init__(monitor: str = 'reward', min_delta: float = 0.0, patience: int = 0, mode: Literal['min', 'max'] = 'max', baseline: float | None = None, restore_best_weights: bool = False)
- state_dict() dict
-
Get a state dict of the callback for pause and resume.
- load_state_dict(state_dict: dict) None
-
Resume the callback from a saved state dict.
- on_fit_start(trainer: Trainer, vessel: TrainingVesselBase) None
-
Called before the whole fit process begins.
- on_validate_end(trainer: Trainer, vessel: TrainingVesselBase) None
-
Called when the validation ends.
- classqlib.rl.trainer.MetricsWriter(dirpath: Path)
-
Dump training metrics to file.
- __init__(dirpath: Path) None
- on_train_end(trainer: Trainer, vessel: TrainingVesselBase) None
-
Called when the training ends. To access all outputs produced during training, cache the data in either trainer and vessel, and post-process them in this hook.
- on_validate_end(trainer: Trainer, vessel: TrainingVesselBase) None
-
Called when the validation ends.
- qlib.rl.trainer.train(simulator_fn: Callable[[InitialStateType], Simulator], state_interpreter: StateInterpreter, action_interpreter: ActionInterpreter, initial_states: Sequence[InitialStateType], policy: BasePolicy, reward: Reward, vessel_kwargs: Dict[str, Any], trainer_kwargs: Dict[str, Any]) None
-
Train a policy with the parallelism provided by RL framework.
Experimental API. Parameters might change shortly.
- Parameters:
-
-
simulator_fn – Callable receiving initial seed, returning a simulator.
-
state_interpreter – Interprets the state of simulators.
-
action_interpreter – Interprets the policy actions.
-
initial_states – Initial states to iterate over. Every state will be run exactly once.
-
policy – Policy to train against.
-
reward – Reward function.
-
vessel_kwargs – Keyword arguments passed to
TrainingVessel, likeepisode_per_iter. -
trainer_kwargs – Keyword arguments passed to
Trainer, likefinite_env_type,concurrency.
-
- qlib.rl.trainer.backtest(simulator_fn: Callable[[InitialStateType], Simulator], state_interpreter: StateInterpreter, action_interpreter: ActionInterpreter, initial_states: Sequence[InitialStateType], policy: BasePolicy, logger: LogWriter | List[LogWriter], reward: Reward | None = None, finite_env_type: FiniteEnvType = 'subproc', concurrency: int = 2) None
-
Backtest with the parallelism provided by RL framework.
Experimental API. Parameters might change shortly.
- Parameters:
-
-
simulator_fn – Callable receiving initial seed, returning a simulator.
-
state_interpreter – Interprets the state of simulators.
-
action_interpreter – Interprets the policy actions.
-
initial_states – Initial states to iterate over. Every state will be run exactly once.
-
policy – Policy to test against.
-
logger – Logger to record the backtest results. Logger must be present because without logger, all information will be lost.
-
reward – Optional reward function. For backtest, this is for testing the rewards and logging them only.
-
finite_env_type – Type of finite env implementation.
-
concurrency – Parallel workers.
-
Order Execution
Currently it supports single-asset order execution. Multi-asset is on the way.
- classqlib.rl.order_execution.FullHistoryStateInterpreter(max_step: int, data_ticks: int, data_dim: int, processed_data_provider: dict | ProcessedDataProvider)
-
The observation of all the history, including today (until this moment), and yesterday.
- Parameters:
-
-
max_step – Total number of steps (an upper-bound estimation). For example, 390min / 30min-per-step = 13 steps.
-
data_ticks – Equal to the total number of records. For example, in SAOE per minute, the total ticks is the length of day in minutes.
-
data_dim – Number of dimensions in data.
-
processed_data_provider – Provider of the processed data.
-
- __init__(max_step: int, data_ticks: int, data_dim: int, processed_data_provider: dict | ProcessedDataProvider) None
- interpret(state: SAOEState) FullHistoryObs
-
Interpret the state of simulator.
- Parameters:
-
simulator_state – Retrieved with
simulator.get_state(). - Return type:
-
State needed by policy. Should conform with the state space defined in
observation_space.
- classqlib.rl.order_execution.CurrentStepStateInterpreter(max_step: int)
-
The observation of current step.
Used when policy only depends on the latest state, but not history. The key list is not full. You can add more if more information is needed by your policy.
- __init__(max_step: int) None
- interpret(state: SAOEState) CurrentStateObs
-
Interpret the state of simulator.
- Parameters:
-
simulator_state – Retrieved with
simulator.get_state(). - Return type:
-
State needed by policy. Should conform with the state space defined in
observation_space.
- classqlib.rl.order_execution.CategoricalActionInterpreter(values: int | List[float], max_step: int | None = None)
-
Convert a discrete policy action to a continuous action, then multiplied by
order.amount.- Parameters:
-
-
values – It can be a list of length $L$: $[a_1, a_2, ldots, a_L]$. Then when policy givens decision $x$, $a_x$ times order amount is the output. It can also be an integer $n$, in which case the list of length $n+1$ is auto-generated, i.e., $[0, 1/n, 2/n, ldots, n/n]$.
-
max_step – Total number of steps (an upper-bound estimation). For example, 390min / 30min-per-step = 13 steps.
-
- __init__(values: int | List[float], max_step: int | None = None) None
- interpret(state: SAOEState, action: int) float
-
Convert the policy action to simulator action.
- Parameters:
-
-
simulator_state – Retrieved with
simulator.get_state(). -
action – Raw action given by policy.
-
- Return type:
-
The action needed by simulator,
- classqlib.rl.order_execution.TwapRelativeActionInterpreter(*args, **kwds)
-
Convert a continuous ratio to deal amount.
The ratio is relative to TWAP on the remainder of the day. For example, there are 5 steps left, and the left position is 300. With TWAP strategy, in each position, 60 should be traded. When this interpreter receives action $a$, its output is $60 cdot a$.
- interpret(state: SAOEState, action: float) float
-
Convert the policy action to simulator action.
- Parameters:
-
-
simulator_state – Retrieved with
simulator.get_state(). -
action – Raw action given by policy.
-
- Return type:
-
The action needed by simulator,
- classqlib.rl.order_execution.Recurrent(obs_space: FullHistoryObs, hidden_dim: int = 64, output_dim: int = 32, rnn_type: Literal['rnn', 'lstm', 'gru'] = 'gru', rnn_num_layers: int = 1)
-
The network architecture proposed in OPD.
At every time step the input of policy network is divided into two parts, the public variables and the private variables. which are handled by
raw_rnnandpri_rnnin this network, respectively.One minor difference is that, in this implementation, we don’t assume the direction to be fixed. Thus, another
dire_fcis added to produce an extra direction-related feature.- __init__(obs_space: FullHistoryObs, hidden_dim: int = 64, output_dim: int = 32, rnn_type: Literal['rnn', 'lstm', 'gru'] = 'gru', rnn_num_layers: int = 1) None
-
Initialize internal Module state, shared by both nn.Module and ScriptModule.
- forward(batch: Batch) Tensor
-
Input should be a dict (at least) containing:
-
data_processed: [N, T, C]
-
cur_step: [N] (int)
-
cur_time: [N] (int)
-
position_history: [N, S] (S is number of steps)
-
target: [N]
-
num_step: [N] (int)
-
acquiring: [N] (0 or 1)
-
- classqlib.rl.order_execution.AllOne(obs_space: gym.Space, action_space: gym.Space, fill_value: float | int = 1.0)
-
Forward returns a batch full of 1.
Useful when implementing some baselines (e.g., TWAP).
- __init__(obs_space: gym.Space, action_space: gym.Space, fill_value: float | int = 1.0) None
- forward(batch: Batch, state: dict | Batch | np.ndarray = None, **kwargs: Any) Batch
-
Compute action over the given batch data.
- Returns:
-
A
Batchwhich MUST have the following keys:-
actan numpy.ndarray or a torch.Tensor, the action over given batch data. -
statea dict, an numpy.ndarray or a torch.Tensor, the internal state of the policy,Noneas default.
-
Other keys are user-defined. It depends on the algorithm. For example,
# some code return Batch(logits=..., act=..., state=None, dist=...)
The keyword
policyis reserved and the corresponding data will be stored into the replay buffer. For instance,# some code return Batch(..., policy=Batch(log_prob=dist.log_prob(act))) # and in the sampled data batch, you can directly use # batch.policy.log_prob to get your data.
Note
In continuous action space, you should do another step “map_action” to get the real action:
act = policy(batch).act # doesn't map to the target action range act = policy.map_action(act, batch)
- classqlib.rl.order_execution.PPO(network: Module, obs_space: Space, action_space: Space, lr: float, weight_decay: float = 0.0, discount_factor: float = 1.0, max_grad_norm: float = 100.0, reward_normalization: bool = True, eps_clip: float = 0.3, value_clip: bool = True, vf_coef: float = 1.0, gae_lambda: float = 1.0, max_batch_size: int = 256, deterministic_eval: bool = True, weight_file: Path | None = None)
-
A wrapper of tianshou PPOPolicy.
Differences:
-
Auto-create actor and critic network. Supports discrete action space only.
-
Dedup common parameters between actor network and critic network (not sure whether this is included in latest tianshou or not).
-
Support a
weight_filethat supports loading checkpoint. -
Some parameters’ default values are different from original.
- __init__(network: Module, obs_space: Space, action_space: Space, lr: float, weight_decay: float = 0.0, discount_factor: float = 1.0, max_grad_norm: float = 100.0, reward_normalization: bool = True, eps_clip: float = 0.3, value_clip: bool = True, vf_coef: float = 1.0, gae_lambda: float = 1.0, max_batch_size: int = 256, deterministic_eval: bool = True, weight_file: Path | None = None) None
-
- classqlib.rl.order_execution.PAPenaltyReward(penalty: float = 100.0, scale: float = 1.0)
-
Encourage higher PAs, but penalize stacking all the amounts within a very short time. Formally, for each time step, the reward is .
- Parameters:
-
-
penalty – The penalty for large volume in a short time.
-
scale – The weight used to scale up or down the reward.
-
- __init__(penalty: float = 100.0, scale: float = 1.0) None
- reward(simulator_state: SAOEState) float
-
Implement this method for your own reward.
- classqlib.rl.order_execution.SingleAssetOrderExecutionSimple(order: Order, data_dir: Path, feature_columns_today: List[str] = [], feature_columns_yesterday: List[str] = [], data_granularity: int = 1, ticks_per_step: int = 30, vol_threshold: float | None = None)
-
Single-asset order execution (SAOE) simulator.
As there’s no “calendar” in the simple simulator, ticks are used to trade. A tick is a record (a line) in the pickle-styled data file. Each tick is considered as a individual trading opportunity. If such fine granularity is not needed, use
ticks_per_stepto lengthen the ticks for each step.In each step, the traded amount are “equally” separated to each tick, then bounded by volume maximum execution volume (i.e.,
vol_threshold), and if it’s the last step, try to ensure all the amount to be executed.- Parameters:
-
-
order – The seed to start an SAOE simulator is an order.
-
data_dir – Path to load backtest data.
-
feature_columns_today – Columns of today’s feature.
-
feature_columns_yesterday – Columns of yesterday’s feature.
-
data_granularity – Number of ticks between consecutive data entries.
-
ticks_per_step – How many ticks per step.
-
vol_threshold – Maximum execution volume (divided by market execution volume).
-
- __init__(order: Order, data_dir: Path, feature_columns_today: List[str] = [], feature_columns_yesterday: List[str] = [], data_granularity: int = 1, ticks_per_step: int = 30, vol_threshold: float | None = None) None
- ticks_index: pd.DatetimeIndex
-
All available ticks for the day (not restricted to order).
- ticks_for_order: pd.DatetimeIndex
-
Ticks that is available for trading (sliced by order).
- twap_price: float
-
This price is used to compute price advantage. It”s defined as the average price in the period from order”s start time to end time.
- history_exec: pd.DataFrame
-
All execution history at every possible time ticks. See
SAOEMetricsfor available columns. Index isdatetime.
- history_steps: pd.DataFrame
-
Positions at each step. The position before first step is also recorded. See
SAOEMetricsfor available columns. Index isdatetime, which is the starting time of each step.
- metrics: SAOEMetrics | None
-
Metrics. Only available when done.
- step(amount: float) None
-
Execute one step or SAOE.
- Parameters:
-
amount – The amount you wish to deal. The simulator doesn’t guarantee all the amount to be successfully dealt.
- done() bool
-
Check whether the simulator is in a “done” state. When simulator is in a “done” state, it should no longer receives any
steprequest. As simulators are ephemeral, to reset the simulator, the old one should be destroyed and a new simulator can be created.
- classqlib.rl.order_execution.SAOEStateAdapter(order: Order, trade_decision: BaseTradeDecision, executor: BaseExecutor, exchange: Exchange, ticks_per_step: int, backtest_data: IntradayBacktestData, data_granularity: int = 1)
-
Maintain states of the environment. SAOEStateAdapter accepts execution results and update its internal state according to the execution results with additional information acquired from executors & exchange. For example, it gets the dealt order amount from execution results, and get the corresponding market price / volume from exchange.
Example usage:
adapter = SAOEStateAdapter(...) adapter.update(...) state = adapter.saoe_state
- __init__(order: Order, trade_decision: BaseTradeDecision, executor: BaseExecutor, exchange: Exchange, ticks_per_step: int, backtest_data: IntradayBacktestData, data_granularity: int = 1) None
- generate_metrics_after_done() None
-
Generate metrics once the upper level execution is done
- classqlib.rl.order_execution.SAOEMetrics(*args, **kwargs)
-
Metrics for SAOE accumulated for a “period”. It could be accumulated for a day, or a period of time (e.g., 30min), or calculated separately for every minute.
Warning
The type hints are for single elements. In lots of times, they can be vectorized. For example,
market_volumecould be a list of float (or ndarray) rather tahn a single float.- stock_id: str
-
Stock ID of this record.
- datetime: pd.Timestamp | pd.DatetimeIndex
-
Datetime of this record (this is index in the dataframe).
- direction: int
-
Direction of the order. 0 for sell, 1 for buy.
- market_volume: np.ndarray | float
-
(total) market volume traded in the period.
- market_price: np.ndarray | float
-
Deal price. If it’s a period of time, this is the average market deal price.
- amount: np.ndarray | float
-
Total amount (volume) strategy intends to trade.
- inner_amount: np.ndarray | float
-
Total amount that the lower-level strategy intends to trade (might be larger than amount, e.g., to ensure ffr).
- deal_amount: np.ndarray | float
-
Amount that successfully takes effect (must be less than inner_amount).
- trade_price: np.ndarray | float
-
The average deal price for this strategy.
- trade_value: np.ndarray | float
-
Total worth of trading. In the simple simulation, trade_value = deal_amount * price.
- position: np.ndarray | float
-
Position left after this “period”.
- ffr: np.ndarray | float
-
Completed how much percent of the daily order.
- pa: np.ndarray | float
-
Price advantage compared to baseline (i.e., trade with baseline market price). The baseline is trade price when using TWAP strategy to execute this order. Please note that there could be data leak here). Unit is BP (basis point, 1/10000).
- classqlib.rl.order_execution.SAOEState(order: Order, cur_time: pd.Timestamp, cur_step: int, position: float, history_exec: pd.DataFrame, history_steps: pd.DataFrame, metrics: SAOEMetrics | None, backtest_data: BaseIntradayBacktestData, ticks_per_step: int, ticks_index: pd.DatetimeIndex, ticks_for_order: pd.DatetimeIndex)
-
Data structure holding a state for SAOE simulator.
- order: Order
-
The order we are dealing with.
- cur_time: pd.Timestamp
-
- Type:
-
Current time, e.g., 9
- cur_step: int
-
Current step, e.g., 0.
- position: float
-
Current remaining volume to execute.
- history_exec: pd.DataFrame
-
See
SingleAssetOrderExecution.history_exec.
- history_steps: pd.DataFrame
-
See
SingleAssetOrderExecution.history_steps.
- metrics: SAOEMetrics | None
-
Daily metric, only available when the trading is in “done” state.
- backtest_data: BaseIntradayBacktestData
-
Backtest data is included in the state. Actually, only the time index of this data is needed, at this moment. I include the full data so that algorithms (e.g., VWAP) that relies on the raw data can be implemented. Interpreter can use this as they wish, but they should be careful not to leak future data.
- ticks_per_step: int
-
How many ticks for each step.
- ticks_index: pd.DatetimeIndex
-
31, …, 14:59].
- Type:
-
Trading ticks in all day, NOT sliced by order (defined in data). e.g., [9
- Type:
-
30, 9
- ticks_for_order: pd.DatetimeIndex
-
46, …, 14:44].
- Type:
-
Trading ticks sliced by order, e.g., [9
- Type:
-
45, 9
- classqlib.rl.order_execution.SAOEStrategy(policy: BasePolicy, outer_trade_decision: BaseTradeDecision | None = None, level_infra: LevelInfrastructure | None = None, common_infra: CommonInfrastructure | None = None, data_granularity: int = 1, **kwargs: Any)
-
RL-based strategies that use SAOEState as state.
- __init__(policy: BasePolicy, outer_trade_decision: BaseTradeDecision | None = None, level_infra: LevelInfrastructure | None = None, common_infra: CommonInfrastructure | None = None, data_granularity: int = 1, **kwargs: Any) None
-
- Parameters:
-
policy – RL policy for generate action
- reset(outer_trade_decision: BaseTradeDecision | None = None, **kwargs: Any) None
-
-
reset level_infra, used to reset trade calendar, .etc
-
reset common_infra, used to reset trade_account, trade_exchange, .etc
-
reset outer_trade_decision, used to make split decision
NOTE: split this function into reset and _reset will make following cases more convenient 1. Users want to initialize his strategy by overriding reset, but they don’t want to affect the _reset called when initialization
-
- post_upper_level_exe_step() None
-
A hook for doing sth after the upper level executor finished its execution (for example, finalize the metrics collection).
- post_exe_step(execute_result: list | None) None
-
A hook for doing sth after the corresponding executor finished its execution.
- Parameters:
-
execute_result – the execution result
- generate_trade_decision(execute_result: list | None = None) BaseTradeDecision | Generator[Any, Any, BaseTradeDecision]
-
For SAOEStrategy, we need to update the self._last_step_range every time a decision is generated. This operation should be invisible to developers, so we implement it in generate_trade_decision() The concrete logic to generate decisions should be implemented in _generate_trade_decision(). In other words, all subclass of SAOEStrategy should overwrite _generate_trade_decision() instead of generate_trade_decision().
- classqlib.rl.order_execution.ProxySAOEStrategy(outer_trade_decision: BaseTradeDecision | None = None, level_infra: LevelInfrastructure | None = None, common_infra: CommonInfrastructure | None = None, **kwargs: Any)
-
Proxy strategy that uses SAOEState. It is called a ‘proxy’ strategy because it does not make any decisions by itself. Instead, when the strategy is required to generate a decision, it will yield the environment’s information and let the outside agents to make the decision. Please refer to _generate_trade_decision for more details.
- __init__(outer_trade_decision: BaseTradeDecision | None = None, level_infra: LevelInfrastructure | None = None, common_infra: CommonInfrastructure | None = None, **kwargs: Any) None
-
- Parameters:
-
policy – RL policy for generate action
- reset(outer_trade_decision: BaseTradeDecision | None = None, **kwargs: Any) None
-
-
reset level_infra, used to reset trade calendar, .etc
-
reset common_infra, used to reset trade_account, trade_exchange, .etc
-
reset outer_trade_decision, used to make split decision
NOTE: split this function into reset and _reset will make following cases more convenient 1. Users want to initialize his strategy by overriding reset, but they don’t want to affect the _reset called when initialization
-
- classqlib.rl.order_execution.SAOEIntStrategy(policy: dict | BasePolicy, state_interpreter: dict | StateInterpreter, action_interpreter: dict | ActionInterpreter, network: dict | torch.nn.Module | None = None, outer_trade_decision: BaseTradeDecision | None = None, level_infra: LevelInfrastructure | None = None, common_infra: CommonInfrastructure | None = None, **kwargs: Any)
-
(SAOE)state based strategy with (Int)preters.
- __init__(policy: dict | BasePolicy, state_interpreter: dict | StateInterpreter, action_interpreter: dict | ActionInterpreter, network: dict | torch.nn.Module | None = None, outer_trade_decision: BaseTradeDecision | None = None, level_infra: LevelInfrastructure | None = None, common_infra: CommonInfrastructure | None = None, **kwargs: Any) None
-
- Parameters:
-
policy – RL policy for generate action
- reset(outer_trade_decision: BaseTradeDecision | None = None, **kwargs: Any) None
-
-
reset level_infra, used to reset trade calendar, .etc
-
reset common_infra, used to reset trade_account, trade_exchange, .etc
-
reset outer_trade_decision, used to make split decision
NOTE: split this function into reset and _reset will make following cases more convenient 1. Users want to initialize his strategy by overriding reset, but they don’t want to affect the _reset called when initialization
-
Utils
- classqlib.rl.utils.LogLevel(value)
-
Log-levels for RL training. The behavior of handling each log level depends on the implementation of
LogWriter.- DEBUG= 10
-
If you only want to see the metric in debug mode.
- PERIODIC= 20
-
If you want to see the metric periodically.
- INFO= 30
-
Important log messages.
- CRITICAL= 40
-
LogWriter should always handle CRITICAL messages
- classqlib.rl.utils.DataQueue(dataset: Sequence[T], repeat: int = 1, shuffle: bool = True, producer_num_workers: int = 0, queue_maxsize: int = 0)
-
Main process (producer) produces data and stores them in a queue. Sub-processes (consumers) can retrieve the data-points from the queue. Data-points are generated via reading items from
dataset.DataQueueis ephemeral. You must create a new DataQueue when therepeatis exhausted.See the documents of
qlib.rl.utils.FiniteVectorEnvfor more background.- Parameters:
-
-
dataset – The dataset to read data from. Must implement
__len__and__getitem__. -
repeat – Iterate over the data-points for how many times. Use
-1to iterate forever. -
shuffle – If
shuffleis true, the items will be read in random order. -
producer_num_workers – Concurrent workers for data-loading.
-
queue_maxsize – Maximum items to put into queue before it jams.
-
Examples
data_queue = DataQueue(my_dataset) with data_queue: ...
In worker:
for data in data_queue: print(data)
- __init__(dataset: Sequence[T], repeat: int = 1, shuffle: bool = True, producer_num_workers: int = 0, queue_maxsize: int = 0) None
- classqlib.rl.utils.EnvWrapper(simulator_fn: Callable[..., Simulator[InitialStateType, StateType, ActType]], state_interpreter: StateInterpreter[StateType, ObsType], action_interpreter: ActionInterpreter[StateType, PolicyActType, ActType], seed_iterator: Iterable[InitialStateType] | None, reward_fn: Reward | None = None, aux_info_collector: AuxiliaryInfoCollector[StateType, Any] | None = None, logger: LogCollector | None = None)
-
Qlib-based RL environment, subclassing
gym.Env. A wrapper of components, including simulator, state-interpreter, action-interpreter, reward.This is what the framework of simulator - interpreter - policy looks like in RL training. All the components other than policy needs to be assembled into a single object called “environment”. The “environment” are replicated into multiple workers, and (at least in tianshou’s implementation), one single policy (agent) plays against a batch of environments.
- Parameters:
-
-
simulator_fn – A callable that is the simulator factory. When
seed_iteratoris present, the factory should take one argument, that is the seed (aka initial state). Otherwise, it should take zero argument. -
state_interpreter – State-observation converter.
-
action_interpreter – Policy-simulator action converter.
-
seed_iterator (str | Iterator[InitialStateType] | None) – An iterable of seed. With the help of
qlib.rl.utils.DataQueue, environment workers in different processes can share oneseed_iterator. -
reward_fn – A callable that accepts the StateType and returns a float (at least in single-agent case).
-
aux_info_collector – Collect auxiliary information. Could be useful in MARL.
-
logger – Log collector that collects the logs. The collected logs are sent back to main process, via the return value of
env.step().
-
- status
-
Status indicator. All terms are in RL language. It can be used if users care about data on the RL side. Can be none when no trajectory is available.
- Type:
- __init__(simulator_fn: Callable[..., Simulator[InitialStateType, StateType, ActType]], state_interpreter: StateInterpreter[StateType, ObsType], action_interpreter: ActionInterpreter[StateType, PolicyActType, ActType], seed_iterator: Iterable[InitialStateType] | None, reward_fn: Reward | None = None, aux_info_collector: AuxiliaryInfoCollector[StateType, Any] | None = None, logger: LogCollector | None = None) None
- reset(**kwargs: Any) ObsType
-
Try to get a state from state queue, and init the simulator with this state. If the queue is exhausted, generate an invalid (nan) observation.
- step(policy_action: PolicyActType, **kwargs: Any) Tuple[ObsType, float, bool, InfoDict]
-
Environment step.
See the code along with comments to get a sequence of things happening here.
- render(mode: str = 'human') None
-
Compute the render frames as specified by render_mode attribute during initialization of the environment.
The set of supported modes varies per environment. (And some third-party environments may not support rendering at all.) By convention, if render_mode is:
-
None (default): no render is computed.
-
human: render return None. The environment is continuously rendered in the current display or terminal. Usually for human consumption.
-
rgb_array: return a single frame representing the current state of the environment. A frame is a numpy.ndarray with shape (x, y, 3) representing RGB values for an x-by-y pixel image.
-
rgb_array_list: return a list of frames representing the states of the environment since the last reset. Each frame is a numpy.ndarray with shape (x, y, 3), as with rgb_array.
-
ansi: Return a strings (str) or StringIO.StringIO containing a terminal-style text representation for each time step. The text can include newlines and ANSI escape sequences (e.g. for colors).
Note
Make sure that your class’s metadata ‘render_modes’ key includes the list of supported modes. It’s recommended to call super() in implementations to use the functionality of this method.
-
- classqlib.rl.utils.LogCollector(min_loglevel: int | LogLevel = LogLevel.PERIODIC)
-
Logs are first collected in each environment worker, and then aggregated to stream at the central thread in vector env.
In
LogCollector, every metric is added to a dict, which needs to bereset()at each step. The dict is sent via theinfoinenv.step(), and decoded by theLogWriterat vector env.min_loglevelis for optimization purposes: to avoid too much traffic on networks / in pipe.- __init__(min_loglevel: int | LogLevel = LogLevel.PERIODIC) None
- reset() None
-
Clear all collected contents.
- add_string(name: str, string: str, loglevel: int | LogLevel = LogLevel.PERIODIC) None
-
Add a string with name into logged contents.
- add_scalar(name: str, scalar: Any, loglevel: int | LogLevel = LogLevel.PERIODIC) None
-
Add a scalar with name into logged contents. Scalar will be converted into a float.
- add_array(name: str, array: np.ndarray | pd.DataFrame | pd.Series, loglevel: int | LogLevel = LogLevel.PERIODIC) None
-
Add an array with name into logging.
- add_any(name: str, obj: Any, loglevel: int | LogLevel = LogLevel.PERIODIC) None
-
Log something with any type.
As it’s an “any” object, the only LogWriter accepting it is pickle. Therefore, pickle must be able to serialize it.
- classqlib.rl.utils.LogWriter(loglevel: int | LogLevel = LogLevel.PERIODIC)
-
Base class for log writers, triggered at every reset and step by finite env.
What to do with a specific log depends on the implementation of subclassing
LogWriter. The general principle is that, it should handle logs above its loglevel (inclusive), and discard logs that are not acceptable. For instance, console loggers obviously can’t handle an image.- episode_count: int
-
Counter of episodes.
- step_count: int
-
Counter of steps.
- active_env_ids: Set[int]
-
Active environment ids in vector env.
- __init__(loglevel: int | LogLevel = LogLevel.PERIODIC) None
- global_step: int
-
Counter of steps. Won”t be cleared in
clear.
- global_episode: int
-
Counter of episodes. Won”t be cleared in
clear.
- episode_lengths: Dict[int, int]
-
Map from environment id to episode length.
- episode_rewards: Dict[int, List[float]]
-
Map from environment id to episode total reward.
- episode_logs: Dict[int, list]
-
Map from environment id to episode logs.
- clear()
-
Clear all the metrics for a fresh start. To make the logger instance reusable.
- state_dict() dict
-
Save the states of the logger to a dict.
- load_state_dict(state_dict: dict) None
-
Load the states of current logger from a dict.
- staticaggregation(array: Sequence[Any], name: str | None = None) Any
-
Aggregation function from step-wise to episode-wise.
If it’s a sequence of float, take the mean. Otherwise, take the first element.
If a name is specified and,
-
if it’s
reward, the reduction will be sum.
-
- log_episode(length: int, rewards: List[float], contents: List[Dict[str, Any]]) None
-
This is triggered at the end of each trajectory.
- Parameters:
-
-
length – Length of this trajectory.
-
rewards – A list of rewards at each step of this episode.
-
contents – Logged contents for every step.
-
- log_step(reward: float, contents: Dict[str, Any]) None
-
This is triggered at each step.
- Parameters:
-
-
reward – Reward for this step.
-
contents – Logged contents for this step.
-
- on_env_step(env_id: int, obs: ObsType, rew: float, done: bool, info: InfoDict) None
-
Callback for finite env, on each step.
- on_env_reset(env_id: int, _: ObsType) None
-
Callback for finite env.
Reset episode statistics. Nothing task-specific is logged here because of a limitation of tianshou.
- on_env_all_ready() None
-
When all environments are ready to run. Usually, loggers should be reset here.
- on_env_all_done() None
-
All done. Time for cleanup.
- qlib.rl.utils.vectorize_env(env_factory: Callable[..., gym.Env], env_type: FiniteEnvType, concurrency: int, logger: LogWriter | List[LogWriter]) FiniteVectorEnv
-
Helper function to create a vector env. Can be used to replace usual VectorEnv.
For example, once you wrote:
DummyVectorEnv([lambda: gym.make(task) for _ in range(env_num)])
Now you can replace it with:
finite_env_factory(lambda: gym.make(task), "dummy", env_num, my_logger)
By doing such replacement, you have two additional features enabled (compared to normal VectorEnv):
-
The vector env will check for NaN observation and kill the worker when its found. See
FiniteVectorEnvfor why we need this. -
A logger to explicit collect logs from environment workers.
- Parameters:
-
-
env_factory – Callable to instantiate one single
gym.Env. All concurrent workers will have the sameenv_factory. -
env_type – dummy or subproc or shmem. Corresponding to parallelism in tianshou.
-
concurrency – Concurrent environment workers.
-
logger – Log writers.
-
Warning
Please do not use lambda expression here for
env_factoryas it may create incorrectly-shared instances.Don’t do:
vectorize_env(lambda: EnvWrapper(...), ...)
Please do:
def env_factory(): ... vectorize_env(env_factory, ...)
-
- classqlib.rl.utils.ConsoleWriter(log_every_n_episode: int = 20, total_episodes: int | None = None, float_format: str = ':.4f', counter_format: str = ':4d', loglevel: int | LogLevel = LogLevel.PERIODIC)
-
Write log messages to console periodically.
It tracks an average meter for each metric, which is the average value since last
clear()till now. The display format for each metric is<name> <latest_value> (<average_value>).Non-single-number metrics are auto skipped.
- __init__(log_every_n_episode: int = 20, total_episodes: int | None = None, float_format: str = ':.4f', counter_format: str = ':4d', loglevel: int | LogLevel = LogLevel.PERIODIC) None
- prefix: str
-
Prefix can be set via
writer.prefix.
- clear() None
-
Clear all the metrics for a fresh start. To make the logger instance reusable.
- log_episode(length: int, rewards: List[float], contents: List[Dict[str, Any]]) None
-
This is triggered at the end of each trajectory.
- Parameters:
-
-
length – Length of this trajectory.
-
rewards – A list of rewards at each step of this episode.
-
contents – Logged contents for every step.
-
- classqlib.rl.utils.CsvWriter(output_dir: Path, loglevel: int | LogLevel = LogLevel.PERIODIC)
-
Dump all episode metrics to a
result.csv.This is not the correct implementation. It’s only used for first iteration.
- __init__(output_dir: Path, loglevel: int | LogLevel = LogLevel.PERIODIC) None
- clear() None
-
Clear all the metrics for a fresh start. To make the logger instance reusable.
- log_episode(length: int, rewards: List[float], contents: List[Dict[str, Any]]) None
-
This is triggered at the end of each trajectory.
- Parameters:
-
-
length – Length of this trajectory.
-
rewards – A list of rewards at each step of this episode.
-
contents – Logged contents for every step.
-
- on_env_all_done() None
-
All done. Time for cleanup.
- classqlib.rl.utils.EnvWrapperStatus(*args, **kwargs)
-
This is the status data structure used in EnvWrapper. The fields here are in the semantics of RL. For example,
obsmeans the observation fed into policy.actionmeans the raw action returned by policy.
- classqlib.rl.utils.LogBuffer(callback: Callable[[bool, bool, LogBuffer], None], loglevel: int | LogLevel = LogLevel.PERIODIC)
-
Keep all numbers in memory.
Objects that can’t be aggregated like strings, tensors, images can’t be stored in the buffer. To persist them, please use
PickleWriter.Every time, Log buffer receives a new metric, the callback is triggered, which is useful when tracking metrics inside a trainer.
- Parameters:
-
callback –
A callback receiving three arguments:
-
on_episode: Whether it’s called at the end of an episode
-
on_collect: Whether it’s called at the end of a collect
-
log_buffer: the
LogBbufferobject
No return value is expected.
-
- __init__(callback: Callable[[bool, bool, LogBuffer], None], loglevel: int | LogLevel = LogLevel.PERIODIC)
- state_dict() dict
-
Save the states of the logger to a dict.
- load_state_dict(state_dict: dict) None
-
Load the states of current logger from a dict.
- clear()
-
Clear all the metrics for a fresh start. To make the logger instance reusable.
- log_episode(length: int, rewards: list[float], contents: list[dict[str, Any]]) None
-
This is triggered at the end of each trajectory.
- Parameters:
-
-
length – Length of this trajectory.
-
rewards – A list of rewards at each step of this episode.
-
contents – Logged contents for every step.
-
- on_env_all_done() None
-
All done. Time for cleanup.
- episode_metrics() dict[str, float]
-
Retrieve the numeric metrics of the latest episode.
- collect_metrics() dict[str, float]
-
Retrieve the aggregated metrics of the latest collect.
- episode_count: int
-
Counter of episodes.
- step_count: int
-
Counter of steps.
- global_step: int
-
Counter of steps. Won”t be cleared in
clear.
- global_episode: int
-
Counter of episodes. Won”t be cleared in
clear.
- active_env_ids: Set[int]
-
Active environment ids in vector env.
- episode_lengths: Dict[int, int]
-
Map from environment id to episode length.
- episode_rewards: Dict[int, List[float]]
-
Map from environment id to episode total reward.
- episode_logs: Dict[int, list]
-
Map from environment id to episode logs.
活动:0