RDAgent
章节大纲
-
简介
在现代工业中,研发(R&D)对于提升工业生产力至关重要,尤其是在人工智能时代,研发的核心主要集中在数据和模型上。我们致力于通过开源的研发自动化工具 RDAgent 来自动化这些高价值的通用研发流程,让 AI 驱动数据驱动的 AI。
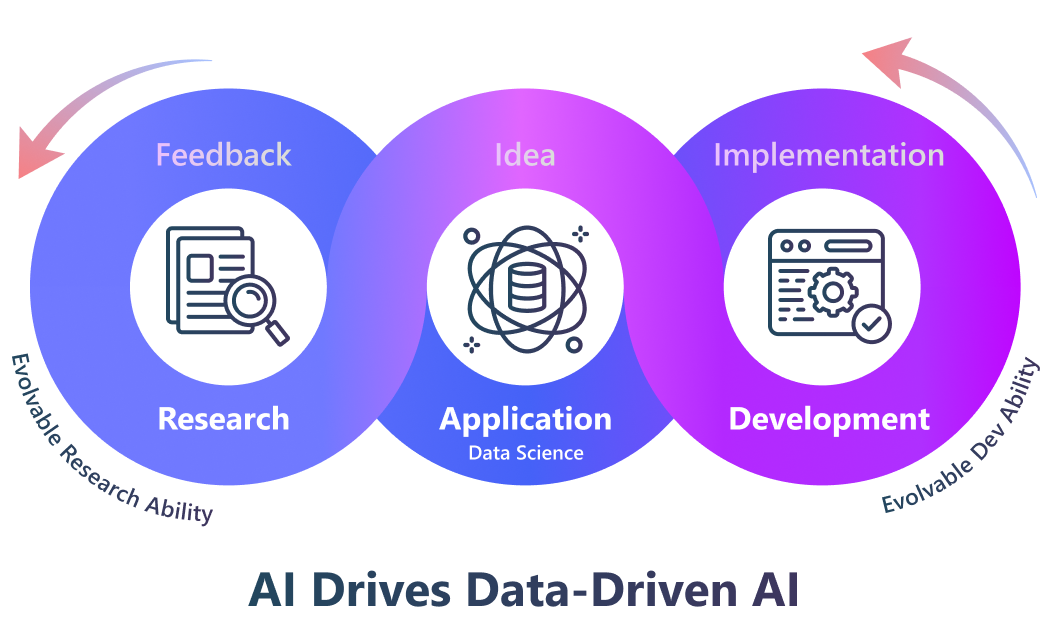
我们的 RDAgent 旨在自动化最关键的工业研发流程,首先聚焦于数据驱动的场景,以大幅提升模型和数据的开发效率。
在方法论上,我们提出了一个由两个关键部分组成的自主智能体框架:(R)esearch 代表通过提出新想法来积极探索,而 (D)evelopment 代表实现这些想法。这两个组成部分的有效性最终将通过实践获得反馈,并且研究和开发能力都可以在此过程中持续学习和成长。
要快速上手,请访问我们的 GitHub 主页 ⚡。如果您已经查看过并想了解更多细节,请继续阅读。
-
安装
安装 RDAgent:针对不同场景
安装 Docker:
RDAgent 旨在进行研究和开发,其作用类似于人类研究员和开发者。它可以在各种环境中编写和运行代码,主要使用 Docker 进行代码执行。这种设计使依赖关系保持简单。在尝试大多数场景之前,用户必须确保已安装 Docker。请参阅 官方 🐳 Docker 页面 获取安装说明。请确保当前用户无需使用
sudo即可运行 Docker 命令。您可以通过执行docker run hello-world来验证。
LiteLLM 后端配置(默认)
注意
🔥 注意: 我们现在提供对 DeepSeek 模型的实验性支持!您可以使用 DeepSeek 的官方 API 来实现经济高效且性能卓越的推理。请参阅下面的配置示例来设置 DeepSeek。
选项 1:统一 API 基础地址(Base URL),同时用于两种模型
# 设置为 LiteLLM 支持的任何模型。 CHAT_MODEL=gpt-4o EMBEDDING_MODEL=text-embedding-3-small # 配置统一的 API 基础地址 # 后端 api_key 完全遵循 litellm 的约定。 OPENAI_API_BASE=<your_unified_api_base> OPENAI_API_KEY=<replace_with_your_openai_api_key>选项 2:为聊天模型和嵌入模型分别设置 API 基础地址
# 设置为 LiteLLM 支持的任何模型。 # 聊天模型: CHAT_MODEL=gpt-4o OPENAI_API_BASE=<your_chat_api_base> OPENAI_API_KEY=<replace_with_your_openai_api_key> # 嵌入模型: # 以 siliconflow 为例,您可以使用其他提供商。 # 注意:嵌入模型需要 litellm_proxy 前缀 EMBEDDING_MODEL=litellm_proxy/BAAI/bge-large-en-v1.5 LITELLM_PROXY_API_KEY=<replace_with_your_siliconflow_api_key> LITELLM_PROXY_API_BASE=https://api.siliconflow.cn/v1
配置示例:DeepSeek 设置
许多用户在设置 DeepSeek 时遇到配置错误。以下是一个完整的可工作示例:
# 聊天模型:使用 DeepSeek 官方 API CHAT_MODEL=deepseek/deepseek-chat DEEPSEEK_API_KEY=<replace_with_your_deepseek_api_key> # 嵌入模型:由于 DeepSeek 没有嵌入模型,因此使用 SiliconFlow。 # 注意:嵌入模型需要 litellm_proxy 前缀 EMBEDDING_MODEL=litellm_proxy/BAAI/bge-m3 LITELLM_PROXY_API_KEY=<replace_with_your_siliconflow_api_key> LITELLM_PROXY_API_BASE=https://api.siliconflow.cn/v1必要的参数包括:
-
CHAT_MODEL:聊天模型的模型名称。 -
EMBEDDING_MODEL:嵌入模型的模型名称。 -
OPENAI_API_BASE:API 的基础 URL。如果EMBEDDING_MODEL不是以litellm_proxy/开头,则此参数同时用于聊天和嵌入模型;否则,仅用于CHAT_MODEL。
可选参数(如果您的嵌入模型由与 CHAT_MODEL 不同的提供商提供,则需要):
-
LITELLM_PROXY_API_KEY:嵌入模型的 API 密钥,如果EMBEDDING_MODEL以litellm_proxy/开头,则需要。 -
LITELLM_PROXY_API_BASE:嵌入模型的 API 基础 URL,如果EMBEDDING_MODEL以litellm_proxy/开头,则需要。
注意: 如果您使用的嵌入模型与聊天模型来自不同的提供商,请记住在
EMBEDDING_MODEL名称前添加litellm_proxy/前缀。CHAT_MODEL和EMBEDDING_MODEL参数将被传递到 LiteLLM 的完成函数中。因此,当使用由不同提供商提供的模型时,首先检查 LiteLLM 的接口配置。模型名称必须与 LiteLLM 允许的名称匹配。
此外,您需要为您各自的模型提供商设置附加参数,并且参数名称必须与 LiteLLM 所要求的对齐。
例如,如果您使用 DeepSeek 模型,需要进行如下设置:
# 对于某些模型,LiteLLM 要求在模型名称前添加前缀。 CHAT_MODEL=deepseek/deepseek-chat DEEPSEEK_API_KEY=<replace_with_your_deepseek_api_key>此外,当您使用推理模型时,响应可能包含思维过程。在这种情况下,您需要设置以下环境变量:
REASONING_THINK_RM=True有关 LiteLLM 要求的更多详细信息,请参阅 官方 LiteLLM 文档。
配置示例 2:Azure OpenAI 设置
以下是基于 官方 LiteLLM 文档 专门针对 Azure OpenAI 的示例配置:
如果您正在使用 Azure OpenAI,以下是基于 LiteLLM Azure OpenAI 文档的使用 Python SDK 的工作示例:
Pythonfrom litellm import completion import os # 设置 Azure OpenAI 环境变量 os.environ["AZURE_API_KEY"] = "<your_azure_api_key>" os.environ["AZURE_API_BASE"] = "<your_azure_api_base>" os.environ["AZURE_API_VERSION"] = "<version>" # 向您的 Azure 部署发起请求 response = completion( "azure/<your_deployment_name>", messages = [{ "content": "Hello, how are you?", "role": "user" }] )为了与上面的 Python SDK 示例对齐,您可以根据
response模型设置配置CHAT_MODEL,并通过将其写入本地.env文件来使用相应的os.environ变量,如下所示:cat << EOF > .env # 聊天模型:通过 LiteLLM 使用 Azure OpenAI CHAT_MODEL=azure/<your_deployment_name> AZURE_API_BASE=https://<your_azure_base>.openai.azure.com/ AZURE_API_KEY=<your_azure_api_key> AZURE_API_VERSION=<version> # 嵌入模型:通过 litellm_proxy 使用 SiliconFlow EMBEDDING_MODEL=litellm_proxy/BAAI/bge-large-en-v1.5 LITELLM_PROXY_API_KEY=<your_siliconflow_api_key> LITELLM_PROXY_API_BASE=https://api.siliconflow.cn/v1 EOF此配置使您可以通过 LiteLLM 调用 Azure OpenAI,同时使用外部提供商(例如 SiliconFlow)进行嵌入。
如果您的 Azure OpenAI API 密钥支持嵌入模型,您可以参考以下配置示例。
cat << EOF > .env EMBEDDING_MODEL=azure/<Model deployment supporting embedding> CHAT_MODEL=azure/<your deployment name> AZURE_API_KEY=<replace_with_your_openai_api_key> AZURE_API_BASE=<your_unified_api_base> AZURE_API_VERSION=<azure api version>
配置(已弃用)
要运行应用程序,请在项目的根目录中创建一个
.env文件,并根据您的要求添加环境变量。如果您正在使用此已弃用版本,则应将
BACKEND设置为rdagent.oai.backend.DeprecBackend。BACKEND=rdagent.oai.backend.DeprecBackend以下是您可以使用的其他配置选项:
OpenAI API
这是用户使用 OpenAI API 的标准配置。
OPENAI_API_KEY=<your_api_key> EMBEDDING_MODEL=text-embedding-3-small CHAT_MODEL=gpt-4-turboAzure OpenAI
以下是用户使用 OpenAI API 的标准配置选项。
USE_AZURE=True EMBEDDING_OPENAI_API_KEY=<replace_with_your_azure_openai_api_key> EMBEDDING_AZURE_API_BASE= # Azure OpenAI API 的端点。 EMBEDDING_AZURE_API_VERSION= # Azure OpenAI API 的版本。 EMBEDDING_MODEL=text-embedding-3-small CHAT_OPENAI_API_KEY=<replace_with_your_azure_openai_api_key> CHAT_AZURE_API_BASE= # Azure OpenAI API 的端点。 CHAT_AZURE_API_VERSION= # Azure OpenAI API 的版本。 CHAT_MODEL= # Azure OpenAI API 的模型名称。使用 Azure 令牌提供商(Token Provider)
如果您正在使用 Azure 令牌提供商,则需要将
CHAT_USE_AZURE_TOKEN_PROVIDER和EMBEDDING_USE_AZURE_TOKEN_PROVIDER环境变量设置为True。然后使用 Azure 配置 部分中提供的环境变量。☁️ Azure 配置 - 安装 Azure CLI:
sh curl -L https://aka.ms/InstallAzureCli | bash登录 Azure:
sh az login --use-device-code退出并重新登录到您的环境(此步骤可能不是必需的)。
配置列表
OpenAI API 设置
配置选项 含义 默认值 OPENAI_API_KEY聊天和嵌入模型的 API 密钥 None EMBEDDING_OPENAI_API_KEY为嵌入模型使用不同的 API 密钥 None CHAT_OPENAI_API_KEY为聊天模型设置不同的 API 密钥 None EMBEDDING_MODEL嵌入模型的名称 text-embedding-3-small CHAT_MODEL聊天模型的名称 gpt-4-turbo EMBEDDING_AZURE_API_BASEAzure OpenAI API 的基础 URL None EMBEDDING_AZURE_API_VERSIONAzure OpenAI API 的版本 None CHAT_AZURE_API_BASEAzure OpenAI API 的基础 URL None CHAT_AZURE_API_VERSIONAzure OpenAI API 的版本 None USE_AZURE如果您使用 Azure OpenAI,则为 True False CHAT_USE_AZURE_TOKEN_PROVIDER如果您在聊天模型中使用 Azure 令牌提供商,则为 True False EMBEDDING_USE_AZURE_TOKEN_PROVIDER如果您在嵌入模型中使用 Azure 令牌提供商,则为 True False 全局设置
配置选项 含义 默认值 max_retry最大重试次数 10 retry_wait_seconds每次重试前等待的秒数 1 log_trace_path日志跟踪文件的路径 None log_llm_chat_content标志,指示是否记录聊天内容 True 缓存设置
配置选项 含义 默认值 dump_chat_cache标志,指示是否转储聊天缓存 False dump_embedding_cache标志,指示是否转储嵌入缓存 False use_chat_cache标志,指示是否使用聊天缓存 False use_embedding_cache标志,指示是否使用嵌入缓存 False prompt_cache_path提示缓存的路径 ./prompt_cache.db max_past_message_include要包含的过去消息的最大数量 10
加载配置
为了方便用户,我们提供了一个名为
rdagent的 CLI 接口,它会自动运行load_dotenv()从.env文件中加载环境变量。但是,此功能默认情况下对其他脚本未启用。我们建议用户通过以下步骤加载环境:⚙️ 环境配置
-
将
.env文件放在与.env.example文件相同的目录中。 -
.env.example文件包含使用 OpenAI API 的用户所需的环境变量(请注意,.env.example是一个示例文件,.env才是最终使用的文件)。 -
导出
.env文件中的每个变量:
export $(grep -v '^#' .env | xargs)如果您想更改默认环境变量,可以参考上面的配置并编辑
.env文件。 -
-
场景列表
在数据驱动场景的两个核心领域——模型实现和数据构建中,我们的系统旨在扮演两个主要角色:🦾 协作助手(copilot) 和 🤖 智能代理(agent)。
-
🦾 协作助手:遵循人类指令,以自动化重复性任务。
-
🤖 智能代理:自主性更高,主动提出想法,旨在未来获得更好的结果。
以下是支持的场景列表:
场景/目标
模型实现 数据构建 💹 金融 🥇 第一个以数据为中心的多智能体量化框架<br>🤖 迭代提出想法与演进 🦾 自动阅读报告与实施<br>🤖 迭代提出想法与演进 🏭 通用 🦾 自动论文阅读与实施 🤖 数据科学
示例:
泡沫破裂(Bubble Bursting)
OpenAI_et_al.pivot( "peace", "war" )
if unit_economics < 0: funds += pentagon
(以上为代码示例)
阅读更多...
-
-
框架与组件
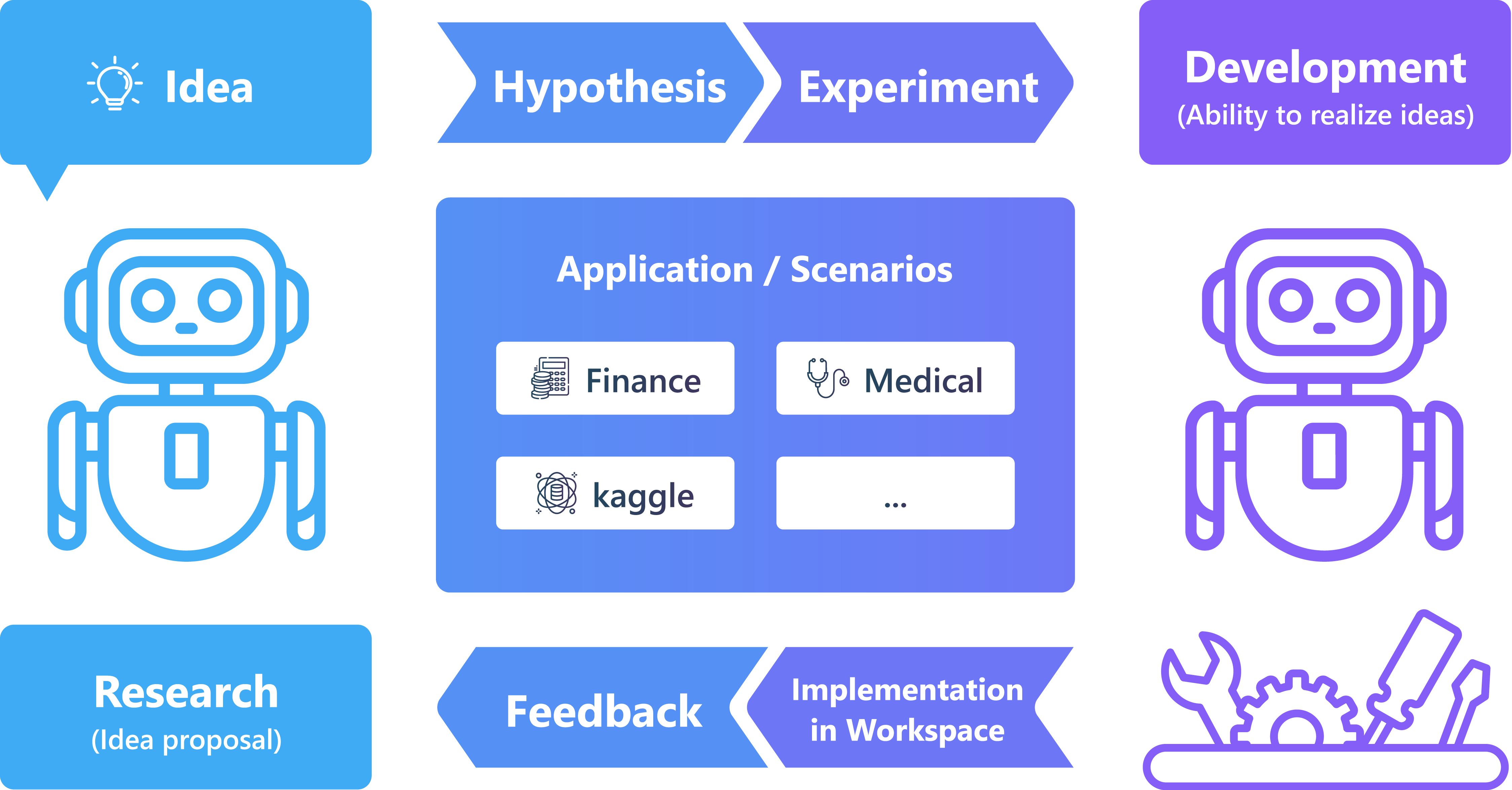
上图展示了 RDAgent 的总体框架。
在数据挖掘专家的日常研发过程中,他们会提出假设(例如,RNN 这样的模型结构可以捕获时间序列数据中的模式),设计实验(例如,金融数据包含时间序列,我们可以在这个场景中验证假设),将实验实现为代码(例如,PyTorch 模型结构),然后执行代码以获取反馈(例如,指标、损失曲线等)。专家们从反馈中学习,并在下一次迭代中进行改进。
我们建立了一个基本的方法框架,它能持续提出假设、验证假设并从现实世界中获取反馈。这是第一个支持与现实世界验证相连接的科学研究自动化框架。
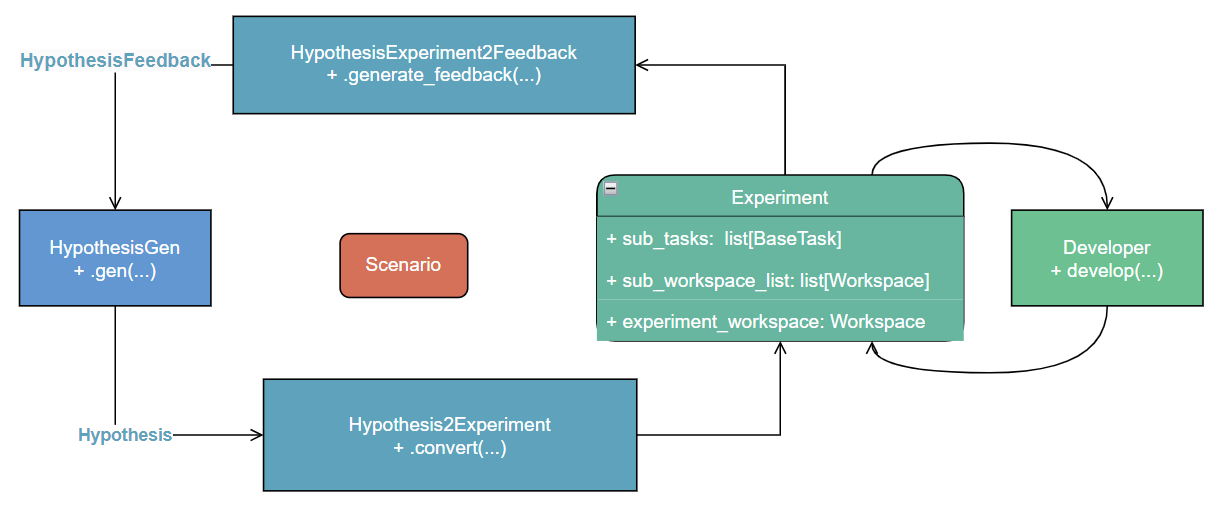
上图显示了主要类及其在工作流中的位置,供那些对详细代码感兴趣的人参考。
-
简介
在研发过程中,RD-Agent 会生成一些日志,这些日志对于调试和理解研发过程非常有用。然而,仅凭终端日志还不够直观。因此,RD-Agent 提供了一个 Web 应用程序作为用户界面,用于可视化研发过程。您可以轻松查看并更好地理解整个研发流程。
快速演示
启动 Web 应用
在
RD-Agent/文件夹中,运行以下命令:rdagent ui --port <port> --log_dir <log_dir like "log/"> [--debug]这将在
http://localhost:<port>上启动一个 Web 应用。注意:
-
log_dir参数不是必需的,您可以在 Web 应用中手动输入日志路径。如果您设置了log_dir参数,则可以在 Web 应用的下拉列表中轻松选择不同的日志路径。 -
--debug是可选的,启用后,侧边栏会显示一个“单步运行”按钮,Web 应用中也会显示已保存的对象信息。
使用 Web 应用
-
打开侧边栏。
-
选择您想要展示的场景。有一些预定义的场景可供选择:
-
Qlib Model(Qlib 模型)
-
Qlib Factor(Qlib 因子)
-
Data Mining(数据挖掘)
-
Model from Paper(论文模型)
-
Kaggle
-
-
点击 Config⚙️ 按钮并输入日志路径(如果您设置了
log_dir参数,可以在下拉列表中选择一个日志路径)。 -
点击 Config⚙️ 下方的按钮来展示场景执行过程。按钮功能如下:
-
All Loops:显示完整的场景执行过程。
-
Next Loop:显示一个成功的研发循环。
-
One Evolving:显示“开发”部分的一个演进步骤。
-
refresh logs:清除已显示的日志。
-
-
-
为了取得良好效果并提升研发能力,我们面临着多重挑战,其中最重要的是持续演进能力。现有的大型语言模型(LLMs)在训练完成后,其能力很难继续增长。此外,LLM 的训练过程更侧重于通用知识,而在更专业的知识方面缺乏深度,这成为了解决行业内专业研发问题的障碍。这些专业知识需要通过深入的行业实践来学习和获取。
我们的 RD-Agent 则可以在研发阶段通过深入探索,持续获取深度的领域知识,使其研发能力不断增长。
为了应对这些关键挑战并实现工业价值,需要完成一系列研究工作。
研究领域与描述
研究领域 描述 基准测试 对研发能力进行基准测试 研究 想法提出:探索新想法或优化现有想法 开发 想法实现:实施并执行想法 仅限高级开发人员。学习如何改进和修复电子商务架构。参加免费研讨会,限 16 个名额。
-
用于开发
如果您想尝试最新版本或为 RD-Agent 贡献代码,可以从源代码安装并按照本页的命令操作。
git clone https://github.com/microsoft/RD-Agent🔧 准备开发环境
设置开发环境:
make dev
运行代码检查(linting):
make lint
部分 linting 问题可以自动修复。我们已在 Makefile 中添加了相应的命令,方便使用:
make auto-lint
代码结构
📂 src
➥ 📂 <项目名称>:避免命名空间冲突
➥ 📁 core
➥ 📁 components/A
➥ 📁 components/B
➥ 📁 components/C
➥ 📁 scenarios/X
➥ 📁 scenarios/Y
➥ 📂 app
➥ 📁 scripts
文件夹名称 描述 📁 core系统的核心框架。所有类都应该是抽象的,通常不能直接使用。 📁 component/A可供其他部分(如场景)使用的有用组件。许多核心类的子类位于此文件夹中。 📁 scenarios/X针对特定场景的具体功能(通常基于组件或核心构建)。这些模块通常不可跨场景重用。 📁 app针对特定场景的应用程序(通常基于组件或场景构建)。移除任何一个都不会影响系统的完整性或其它场景。 📁 scripts临时且未优化的代码。这些是核心、组件、场景和应用程序的候选代码。
命名规范
名称 描述 conf.py模块、应用和项目的配置文件。 -
这是所有 RDAgent 接口的概览。
RD 循环
研究
-
rdagent.core.proposal.Hypothesis
这是一个假设类,包含假设内容(hypothesis)、原因(reason)、简洁的原因(concise_reason)、简洁的观察结果(concise_observation)、简洁的论证(concise_justification)和简洁的知识(concise_knowledge)。
-
rdagent.core.proposal.ExperimentFeedback
这个类用于提供实验反馈,包含原因(reason)、代码更改摘要(code_change_summary)、决定(decision)、EDA(探索性数据分析)改进(eda_improvement)和异常(exception)。
-
classmethod from_exception(e: Exception) → ExperimentFeedback
一个便捷的方法,可以从异常中创建反馈。
-
-
rdagent.core.proposal.HypothesisFeedback
此接口包含对假设的反馈,包括观察结果(observations)、假设评估(hypothesis_evaluation)、新假设(new_hypothesis)、原因(reason)、代码更改摘要(code_change_summary)、决定(decision)、EDA 改进(eda_improvement)和可接受性(acceptable)。
-
rdagent.core.proposal.Trace
此接口用于跟踪实验流程,包含场景(scen)和知识库(knowledge_base)。
-
NodeType
是 tuple[Experiment, ExperimentFeedback] 的别名。
-
get_sota_hypothesis_and_experiment() → tuple[Hypothesis | None, Experiment | None]
访问最新的实验结果、子任务和相应的假设。
-
is_selection_new_tree(selection: tuple[int, ...] | None = None) → bool
检查当前跟踪是否是一个新的决策树。
-
get_parent_exps(selection: tuple[int, ...] | None = None) → list[tuple[Experiment, ExperimentFeedback]]
收集给定选择的所有祖先节点。返回列表的顺序为 [root -> … -> parent -> current_node]。
-
-
rdagent.core.proposal.CheckpointSelector
在跟踪中,我们可以从任何检查点开始(我们将其表示为变量 from_checkpoint_idx)。
-
abstract get_selection(trace: Trace) → tuple[int, ...] | None
checkpoint_idx 代表我们想要创建新节点的位置。返回值应该是目标节点的索引(新生成节点的父节点)。
-
(-1, )表示从跟踪中的最新试验开始。 -
(idx, )表示从跟踪中的第idx个试验开始。 -
None表示从头开始(开始一个新的跟踪)。
-
-
-
rdagent.core.proposal.SOTAexpSelector
从跟踪中选择 SOTA(State-of-the-Art)实验进行提交。
-
abstract get_sota_exp_to_submit(trace: Trace) → Experiment | None
从跟踪中选择 SOTA 实验进行提交。
-
-
rdagent.core.proposal.ExpPlanner
一个用于规划实验的抽象类。规划器应根据跟踪生成实验计划。
-
abstract plan(trace: Trace) → ASpecificPlan
根据跟踪生成实验计划。该计划应是一个包含每个阶段计划的字典。
-
-
rdagent.core.proposal.ExpGen-
abstract gen(trace: Trace, plan: ExperimentPlan | None = None) → Experiment
根据跟踪生成实验。规划是生成的一部分,但由于我们可能支持多阶段规划,因此需要将 plan 作为可选参数传入。
-
async async_gen(trace: Trace, loop: LoopBase) → Experiment
生成实验,并决定是否停止生成并将控制权交给其他例程。
-
-
rdagent.core.proposal.HypothesisGen-
abstract gen(trace: Trace, plan: ExperimentPlan | None = None) → Hypothesis-
scenario_desc 变量的动机:
模拟一个数据科学家正在观察场景。
-
scenario_desc可能包括:-
数据观察:原始或衍生数据。
-
任务信息。
-
-
-
-
rdagent.core.proposal.Hypothesis2Experiment
将抽象描述转换为具体描述,然后生成代码实现卡片。
-
abstract convert(hypothesis: Hypothesis, trace: Trace) → ASpecificExp
将想法提案连接到实现。
-
-
rdagent.core.proposal.Experiment2Feedback
根据已执行的不同任务的实现及其与先前性能的比较,生成关于假设的反馈。
-
abstract generate_feedback(exp: Experiment, trace: Trace) → ExperimentFeedback
exp 应该已执行,其结果以及与先前结果的比较应被包含在内(由 LLM 完成)。例如,Qlib 的 mlflow 将被包含在内。
-
-
-
政策
本项目欢迎您的贡献和建议。大多数贡献要求您同意《贡献者许可协议》(CLA),声明您有权授予我们使用您贡献的权利,并且您确实这样做了。详情请访问 https://cla.opensource.microsoft.com。
当您提交拉取请求(Pull Request)时,一个 CLA 机器人会自动判断您是否需要提供 CLA,并对 PR 进行相应的标注(例如,状态检查、评论)。您只需按照机器人提供的说明操作即可。对于所有使用我们 CLA 的代码库,您只需执行一次此操作。
本项目已采纳 Microsoft 开源行为准则。欲了解更多信息,请参阅 行为准则常见问题,或通过 opencode@microsoft.com 联系我们。
商标
本项目可能包含项目、产品或服务的商标或徽标。经授权使用 Microsoft 商标或徽标须遵守并遵循 Microsoft 商标与品牌指南。在修改后的项目中,使用 Microsoft 商标或徽标不得引起混淆,或暗示 Microsoft 的赞助。任何第三方商标或徽标的使用均须遵守该第三方的政策。