RDAgent
简介
对研发能力进行基准测试是该领域的一个重要研究课题。我们正在不断探索评估这些能力的方法。此页面列出了当前的基准测试方法。
开发能力基准测试
基准测试用于评估在固定数据下各种方法的有效性。它主要包括以下步骤:
-
读取并准备评估数据。
-
声明要测试的方法并传入参数。
-
声明评估方法并传入参数。
-
运行评估。
-
保存并展示结果。
配置
pydantic 设置 rdagent.components.benchmark.conf.BenchmarkSettings
显示 JSON 模式
Config:
env_prefix: str = BENCHMARK_
Fields:
bench_data_path (pathlib.Path)
bench_method_cls (str)
bench_method_extra_kwargs (dict)
bench_result_path (pathlib.Path)
bench_test_case_n (int | None)
bench_test_round (int)
field bench_data_path: Path = PosixPath('example.json')
用于基准测试的数据
field bench_method_cls: str = 'rdagent.components.coder.factor_coder.FactorCoSTEER'
用于测试用例的方法
field bench_method_extra_kwargs: dict [Optional]
除了任务列表之外,用于测试方法的额外 kwargs
field bench_result_path: Path = PosixPath('result')
结果保存路径
field bench_test_case_n: int | None = None
要运行的测试用例数量;如果未给出,将运行所有测试用例
field bench_test_round: int = 10
要运行的回合数,每回合可能耗时 10 分钟
class Config
env_prefix = 'BENCHMARK_'
使用 BENCHMARK_ 作为环境变量的前缀
示例
bench_test_round 的默认值为 10,运行大约需要 2 小时。要将其从 10 修改为 2,请按如下所示调整 .env 文件中的环境变量。
BENCHMARK_BENCH_TEST_ROUND=2
数据格式
bench_data_path 中的样本数据是一个字典,其中每个键代表一个因子名称。与每个键关联的值是包含以下信息的因子数据:
-
description:因子的文本描述。
-
formulation:表示模型公式的 LaTeX 公式。
-
variables:因子中涉及的变量字典。
-
Category:因子的类别或分类。
-
Difficulty:实现或理解因子的难度级别。
-
gt_code:与因子相关的代码片段。
这是此数据格式的一个示例:
{
"Turnover_Rate_Factor": {
"description": "基于 20 日平均换手率的传统因子,根据市值进行调整,并通过应用信息分布理论进一步改进。",
"formulation": "\\text{Adjusted Turnover Rate} = \\frac{\\text{mean}(20\\text{-day turnover rate})}{\\text{Market Capitalization}}",
"variables": {
"20-day turnover rate": "过去 20 天的平均换手率。",
"Market Capitalization": "公司已发行股票的总市值。"
},
"Category": "Fundamentals",
"Difficulty": "Easy",
"gt_code": "import pandas as pd\n\ndata_f = pd.read_hdf('daily_f.h5')\n\ndata = data_f.reset_index()\nwindow_size = 20\n\nnominator=data.groupby('instrument')[['TurnoverRate_30D']].rolling(window=window_size).mean().reset_index(0, drop=True)\n# transfer to series\nnew=nominator['TurnoverRate_30D']\ndata['Turnover_Rate_Factor']=new/data['TradableACapital']\n\n# set the datetime and instrument as index and drop the original index\nresult=pd.DataFrame(data['Turnover_Rate_Factor']).set_index(data_f.index)\n\n# transfer the result to series\nresult=result['Turnover_Rate_Factor']\nresult.to_hdf(\"result.h5\", key=\"data\")"
},
"PctTurn20": {
"description": "一个代表过去 20 个交易日换手率百分比变化的因子,已进行市值中性化。",
"formulation": "\\text{PctTurn20} = \\frac{1}{N} \\sum_{i=1}^{N} \\left( \\frac{\\text{Turnover}_{i, t} - \\text{Turnover}_{i, t-20}}{\\text{Turnover}_{i, t-20}} \\right)",
"variables": {
"N": "市场中股票数量。",
"Turnover_{i, t}": "股票 i 在 t 日的换手率。",
"Turnover_{i, t-20}": "股票 i 在 t-20 日的换手率。"
},
"Category": "Volume&Price",
"Difficulty": "Medium",
"gt_code": "import pandas as pd\nfrom statsmodels import api as sm\n\ndef fill_mean(s: pd.Series) -> pd.Series:\n return s.fillna(s.mean()).fillna(0.0)\n\ndef market_value_neutralize(s: pd.Series, mv: pd.Series) -> pd.Series:\n s = s.groupby(\"datetime\", group_keys=False).apply(fill_mean)\n mv = mv.groupby(\"datetime\", group_keys=False).apply(fill_mean)\n\n df_f = mv.to_frame(\"MarketValue\")\n df_f[\"const\"] = 1\n X = df_f[[\"MarketValue\", \"const\"]]\n\n # Perform the Ordinary Least Squares (OLS) regression\n model = sm.OLS(s, X)\n results = model.fit()\n\n # Calculate the residuals\n df_f[\"residual\"] = results.resid\n df_f[\"norm_resi\"] = df_f.groupby(level=\"datetime\", group_keys=False)[\"residual\"].apply(\n lambda x: (x - x.mean()) / x.std(),\n )\n return df_f[\"norm_resi\"]\n\n\n# get_turnover\ndf_pv = pd.read_hdf(\"daily_pv.h5\", key=\"data\")\ndf_f = pd.read_hdf(\"daily_f.h5\", key=\"data\")\nturnover = df_pv[\"$money\"] / df_f[\"TradableMarketValue\"]\n\nf = turnover.groupby(\"instrument\").pct_change(periods=20)\n\nf_neutralized = market_value_neutralize(f, df_f[\"TradableMarketValue\"])\n\nf_neutralized.to_hdf(\"result.h5\", key=\"data\")"
},
"PB_ROE": {
"description": "使用 PB 和 ROE 之间的排名差异构建,用 PB 和 ROE 替换原始 PB 和 ROE 以获得重构的因子值。",
"formulation": "\\text{rank}(PB\\_t) - rank(ROE_t)",
"variables": {
"\\text{rank}(PB_t)": "在 t 时刻对横截面上的 PB 进行排名。",
"\\text{rank}(ROE_t)": "在 t 时刻对横截面上的单季度 ROE 进行排名。"
},
"Category": "High-Frequency",
"Difficulty": "Hard",
"gt_code": "#!/usr/bin/env python\n\nimport pandas as pd\n\ndata_f = pd.read_hdf('daily_f.h5')\n\ndata = data_f.reset_index()\n\n# Calculate the rank of PB and ROE\ndata['PB_rank'] = data.groupby('datetime')['B/P'].rank()\ndata['ROE_rank'] = data.groupby('datetime')['ROE'].rank()\n\n# Calculate the difference between the ranks\ndata['PB_ROE'] = data['PB_rank'] - data['ROE_rank']\n\n# set the datetime and instrument as index and drop the original index\nresult=pd.DataFrame(data['PB_ROE']).set_index(data_f.index)\n\n# transfer the result to series\nresult=result['PB_ROE']\nresult.to_hdf(\"result.h5\", key=\"data\")"
}
}
确保数据放置在 FACTOR_COSTEER_SETTINGS.data_folder_debug 中。数据文件应为 .h5 或 .md 格式,并且不得存储在任何子文件夹中。LLM 代理将审查文件内容并执行任务。
运行基准测试
完成安装和配置后,启动基准测试。
dotenv run -- python rdagent/app/benchmark/factor/eval.py
完成后,将生成一个 pkl 文件,其路径将在控制台的最后一行打印。
显示结果
analysis.py 脚本从 pkl 文件中读取数据并将其转换为图像。修改 rdagent/app/quant_factor_benchmark/analysis.py 中的 Python 代码,以指定 pkl 文件的路径和 png 文件的输出路径。
dotenv run -- python rdagent/app/benchmark/factor/analysis.py <log/path to.pkl>
png 文件将保存到指定路径,如下所示。
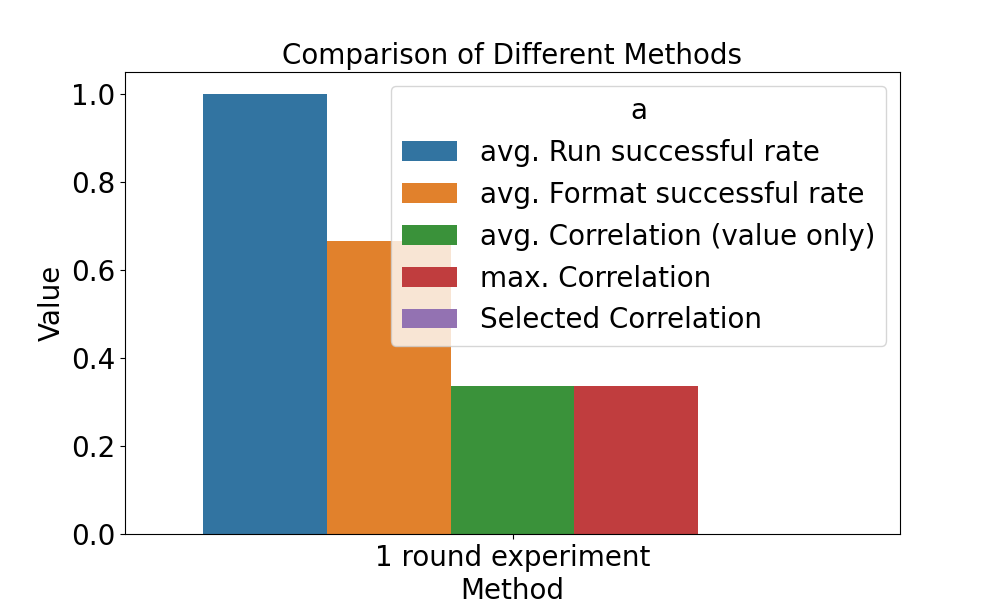
相关论文
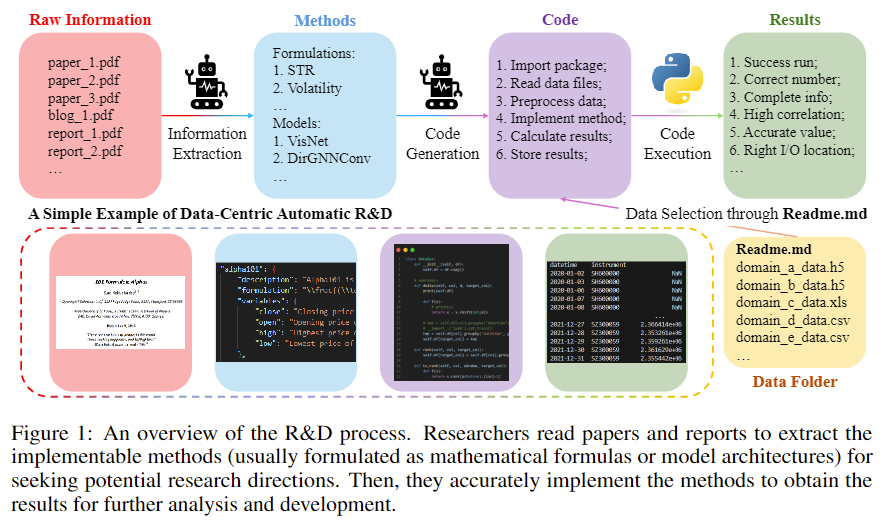
《迈向以数据为中心的自动研发》:我们开发了一个名为 RD2Bench 的综合基准测试,用于评估数据和模型研发能力。该基准测试包含一系列任务,概述了特征或模型的结构。这些任务用于评估 LLM 代理实现它们的能力。
@misc{chen2024datacentric,
title={Towards Data-Centric Automatic R&D},
author={Haotian Chen and Xinjie Shen and Zeqi Ye and Wenjun Feng and Haoxue Wang and Xiao Yang and Xu Yang and Weiqing Liu and Jiang Bian},
year={2024},
eprint={2404.11276},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
要复现论文中详述的基准测试,请查阅 RD2bench.json 文件中列出的因子。请注意,在评估结果时使用 only_correct_format=False。
AI 云 GPU 几分钟内即可就绪,在 Lambda 上训练、微调和部署模型和代理。立即启动。