机器学习
顾名思义,无监督学习是一种机器学习技术,其中模型不使用训练数据集进行监督。相反,模型本身从给定数据中发现隐藏的模式和见解。它可以与人类大脑在学习新事物时的学习过程相提并论。它可以定义为:
“无监督学习是一种机器学习类型,其中模型使用未标记数据集进行训练,并被允许在没有任何监督的情况下对数据进行操作。”
无监督学习不能直接应用于回归或分类问题,因为与监督学习不同,我们有输入数据但没有相应的输出数据。无监督学习的目标是发现数据集的底层结构,根据相似性对数据进行分组,并以压缩格式表示该数据集。
示例:假设无监督学习算法被赋予一个包含不同类型猫和狗图像的输入数据集。该算法从未在给定数据集上进行训练,这意味着它对数据集的特征一无所知。无监督学习算法的任务是自行识别图像特征。无监督学习算法将通过根据图像之间的相似性将图像数据集聚类成组来执行此任务。

为什么要使用无监督学习?
以下是描述无监督学习重要性的一些主要原因:
- 无监督学习有助于从数据中发现有用的见解。
- 无监督学习与人类通过自身经验学习思考的方式非常相似,这使其更接近于真正的人工智能。
- 无监督学习处理未标记和未分类的数据,这使得无监督学习更加重要。
- 在现实世界中,我们并非总是有带有相应输出的输入数据,因此为了解决这种情况,我们需要无监督学习。
无监督学习的工作原理
无监督学习的工作原理可以通过下图来理解:
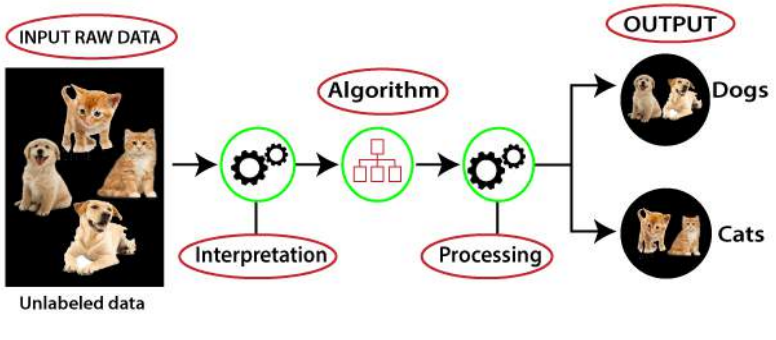
在这里,我们采用了未标记的输入数据,这意味着它没有分类,也没有给出相应的输出。现在,这些未标记的输入数据被输入到机器学习模型中进行训练。首先,它将解释原始数据以从中发现隐藏的模式,然后将应用合适的算法,例如 k-均值聚类、决策树等。
一旦它应用了合适的算法,该算法就会根据对象之间的相似性和差异性将数据对象分成组。
无监督学习算法的类型:
无监督学习算法可以进一步分为两类问题:
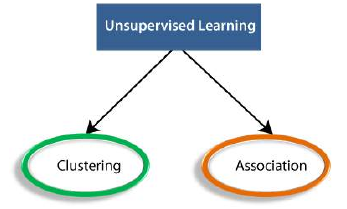
- 聚类(Clustering):聚类是一种将对象分组到簇中的方法,使得具有最大相似性的对象保留在一个组中,并且与另一组的对象相似性很小或没有相似性。聚类分析发现数据对象之间的共性,并根据这些共性的存在和缺失对它们进行分类。
- 关联(Association):关联规则是一种无监督学习方法,用于在大规模数据库中查找变量之间的关系。它确定数据集中同时出现的项目集。关联规则使营销策略更有效。例如,购买 X 商品(假设是面包)的人也倾向于购买 Y 商品(黄油/果酱)。关联规则的典型例子是市场购物篮分析。
无监督学习算法:
以下是一些流行的无监督学习算法列表:
- K-均值聚类
- KNN (k-近邻)
- 层次聚类
- 异常检测
- 神经网络
- 主成分分析
- 独立成分分析
- Apriori 算法
- 奇异值分解
无监督学习的优点
- 与监督学习相比,无监督学习用于更复杂的任务,因为在无监督学习中,我们没有标记的输入数据。
- 无监督学习更受欢迎,因为与标记数据相比,获取未标记数据更容易。
无监督学习的缺点
- 无监督学习本质上比监督学习更困难,因为它没有相应的输出。
- 无监督学习算法的结果可能不那么准确,因为输入数据没有标记,并且算法事先不知道确切的输出。
| 监督学习 | 无监督学习 |
| 监督学习算法使用标记数据进行训练。 | 无监督学习算法使用未标记数据进行训练。 |
| 监督学习模型接收直接反馈以检查是否预测正确输出。 | 无监督学习模型不接收任何反馈。 |
| 监督学习模型预测输出。 | 无监督学习模型在数据中发现隐藏模式。 |
| 在监督学习中,模型接收输入数据以及输出。 | 在无监督学习中,模型只接收输入数据。 |
| 监督学习的目标是训练模型,使其在接收新数据时能够预测输出。 | 无监督学习的目标是从未知数据集中发现隐藏模式和有用的见解。 |
| 监督学习需要监督来训练模型。 | 无监督学习不需要任何监督来训练模型。 |
| 监督学习可分为分类和回归问题。 | 无监督学习可分为聚类和关联问题。 |
| 监督学习可用于我们既知道输入也知道相应输出的情况。 | 无监督学习可用于我们只有输入数据而没有相应输出数据的情况。 |
| 监督学习模型产生准确的结果。 | 与监督学习相比,无监督学习模型可能给出不太准确的结果。 |
| 监督学习不接近真正的人工智能,因为在这种情况下,我们首先为每个数据训练模型,然后才能预测正确的输出。 | 无监督学习更接近真正的人工智能,因为它类似于孩子通过经验学习日常生活中的事物。 |
| 它包括各种算法,如线性回归、逻辑回归、支持向量机、多类别分类、决策树、贝叶斯逻辑等。 | 它包括各种算法,如聚类、KNN 和 Apriori 算法。 |
As the name suggests, unsupervised learning is a machine learning technique in which models
are not supervised using training dataset. Instead, models itself find the hidden patterns and insights
from the given data. It can be compared to learning which takes place in the human brain while learning
new things. It can be defined as:
“Unsupervised learning is a type of machine learning in which models are trained using
unlabeled dataset and are allowed to act on that data without any supervision.”
Unsupervised learning cannot be directly applied to a regression or classification problem
because unlike supervised learning, we have the input data but no corresponding output data. The goal
of unsupervised learning is to find the underlying structure of dataset, group that data according to
similarities, and represent that dataset in a compressed format
Example: Suppose the unsupervised learning algorithm is given an input dataset containing images of
different types of cats and dogs. The algorithm is never trained upon the given dataset, which means it
does not have any idea about the features of the dataset. The task of the unsupervised learning
algorithm is to identify the image features on their own. Unsupervised learning algorithm will perform
this task by clustering the image dataset into the groups according to similarities between images.
Why use Unsupervised Learning?
Below are some main reasons which describe the importance of Unsupervised Learning:
o Unsupervised learning is helpful for finding useful insights from the data.
o
Unsupervised learning is much similar as a human learns to think by their own experiences,
which makes it closer to the real AI.
o
Unsupervised learning works on unlabeled and uncategorized data which make unsupervised
learning more important.
o
In real-world, we do not always have input data with the corresponding output so to solve such
cases, we need unsupervised learning.
Working of Unsupervised Learning
Working of unsupervised learning can be understood by the below diagram:
Here, we have taken an unlabeled input data, which means it is not categorized and
corresponding outputs are also not given. Now, this unlabeled input data is fed to the machine learning
model in order to train it. Firstly, it will interpret the raw data to find the hidden patterns from the data
and then will apply suitable algorithms such as k-means clustering, Decision tree, etc.
Once it applies the suitable algorithm, the algorithm divides the data objects into groups according to
the similarities and difference between the objects.
Types of Unsupervised Learning Algorithm:
The unsupervised learning algorithm can be further categorized into two types of problems:
54
o
Clustering: Clustering is a method of grouping the objects into clusters such that objects with
most similarities remains into a group and has less or no similarities with the objects of another
group. Cluster analysis finds the commonalities between the data objects and categorizes them
as per the presence and absence of those commonalities.
o
Association: An association rule is an unsupervised learning method which is used for finding
the relationships between variables in the large database. It determines the set of items that
occurs together in the dataset. Association rule makes marketing strategy more effective. Such
as people who buy X item (suppose a bread) are also tend to purchase Y (Butter/Jam) item. A
typical example of Association rule is Market Basket Analysis.
Unsupervised Learning algorithms:
Below is the list of some popular unsupervised learning algorithms:
o K-means clustering
o
KNN (k-nearest neighbors)
o
Hierarchal clustering
o
Anomaly detection
o
Neural Networks
o
Principle Component Analysis
o
Independent Component Analysis
o
Apriori algorithm
o
Singular value decomposition
Advantages of Unsupervised Learning
o Unsupervised learning is used for more complex tasks as compared to supervised learning
because, in unsupervised learning, we don't have labeled input data.
o
Unsupervised learning is preferable as it is easy to get unlabeled data in comparison to labeled
data.
Disadvantages of Unsupervised Learning
o Unsupervised learning is intrinsically more difficult than supervised learning as it does not have
corresponding output.
o
The result of the unsupervised learning algorithm might be less accurate as input data is not
labeled, and algorithms do not know the exact output in advance.
55
Supervised Learning
Unsupervised Learning
Supervised learning algorithms are trained using labeled data.
Unsupervised learning algorithms are trained using unlabeled data.
Supervised learning model takes direct feedback to check if it is predicting
Unsupervised learning model does not take any feedback.
correct output or not.
Supervised learning model predicts the output.
Unsupervised learning model finds the hidden patterns in data.
In supervised learning, input data is provided to the model along with the
In unsupervised learning, only input data is provided to the model.
output.
The goal of supervised learning is to train the model so that it can predict
The goal of unsupervised learning is to find the hidden patterns and
the output when it is given new data.
useful insights from the unknown dataset.
Supervised learning needs supervision to train the model.
Unsupervised learning does not need any supervision to train the
model.
Supervised learning can be categorized
Unsupervised Learning can be classified
in Classification and Regression problems.
in Clustering and Associations problems.
Supervised learning can be used for those cases where we know the input
Unsupervised learning can be used for those cases where we have
as well as corresponding outputs.
only input data and no corresponding output data.
Supervised learning model produces an accurate result.
Unsupervised learning model may give less accurate result as
compared to supervised learning.
Supervised learning is not close to true Artificial intelligence as in this, we
Unsupervised learning is more close to the true Artificial
first train the model for each data, and then only it can predict the correct
Intelligence as it learns similarly as a child learns daily routine
output.
things by his experiences.
It includes various algorithms such as Linear Regression, Logistic
It includes various algorithms such as Clustering, KNN, and Apriori
Regression, Support Vector Machine, Multi-class Classification, Decision
algorithm.
tree, Bayesian Logic, etc.